




MySQL连接查询在8.0之前有这四种
Index Nested-Loop Join (NLJ)
Simple Nested-Loop Join (SNLJ)
Block Nested-Loop Join (BNL)
Batched Key Access (BKA)
8.0.18 版本增加了对Hash Join算法(假设驱动表N行,被驱动表M行,N和M进行连接查询)
Index Nested-Loop Join
嵌套循环连接(NLJ)全称
两个表连接查询,驱动表全表扫描,被驱动表的条件过滤列有索引,
这个过程是先遍历驱动表,表然后根据从驱动表 中取出的每行数据中的值,去被驱动表 中查找满足条件的记录。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引。
注:驱动表只访问一次,但是被驱动表却可能访问多次,且访问次数取决于对驱动表执行单表查询后的结果集中有多少条记录。
被驱动表上的索引可以减少扫描范围,但是可能会出现部分列不包含在索引导致全表扫描的情况,因此尽量避免使用select * from,而是只把真正用到列作为查询列表。
扫描次数N+M
Simple Nested-Loop Join
和NLJ类似,不同的是被驱动表连接条件没有索引,导致被驱动表也全表扫描。
这种扫描方式导致的扫描次数是 N*M次。
对于嵌套循环连接算法来说,每次我们从驱动表中得到一条记录时,就根据这条记录立即到被驱动表中查询一次,如果得到了匹配的记录,就把组合后的记录发送给客户端,再到驱动表中获取下一条记录,重复进行。
Block Nested-Loop Join
基于块的嵌套循环连接(BNLJ) 全称
如果存在索引,那么会使用Index的方式进行Join,如果Join的列没有索引,被驱动表要扫描的次数太多了。每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,再把被驱动表的记录加载到内存匹配,这样周而复始,大大增加了IO次数。为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join的方式。
Block Nested-Loop Join方式不再是逐条获取驱动表的数据,而是一块一块的获取,引入了 join buffer 缓冲区,将驱动表 join 相关的部分数据列(大小受 join buffer 的限制)缓冲到 join buffer 中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和 join buffer 中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。
被驱动表无法走索引,查询范围大,内存不够,且被驱动表被访问多次,会导致从磁盘读数据很多次,IO代价高。
将每一条驱动表的结果集数据放入内存(Join Buffer)中一次性与被驱动表进行匹配,显著减少IO代价。
join buffer 只存放查询列表的列和与被驱动表过滤条件的列,因此,不要使用select * 。
两个表都做一次全表扫描,所以总的扫描行数是 M+N;内存中的判断次数是 M*N。
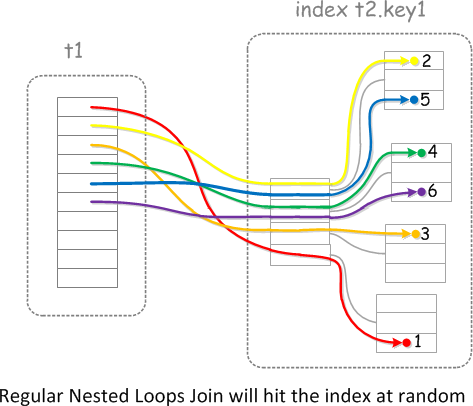
Batched Key Access
BKA
前面说了,不管NLJ还是BNL都可能导致被驱动表却可能访问多次(BNL中如果join buffer不够大也会导致,但是可以考虑增大join_buffer_size 的值,减少对被驱动表的扫描次数)
那么会出现如下问题
1)可能会多次扫描被驱动表,占用磁盘 IO 资源;
2)判断 join 条件需要执行 M*N 次对比(M、N 分别是两张表的行数),如果是大表就会占用非常多的 CPU 资源;
3)可能会导致 Buffer Pool 的热数据被淘汰,影响内存命中率。
BKA解决了这个问题
需要设置SET global optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
当被join的表能够使用索引时,就先排好顺序,然后再去检索被join的表,因为索引是有序的,我们认为对磁盘的读如果是顺序读,能够提升读性能。相当于减少了磁盘随机IO
听起来和MRR类似,实际上MRR也可以想象成二级索引和primary key的join 如果被Join的表上没有索引,则使用老版本的BNL策略。
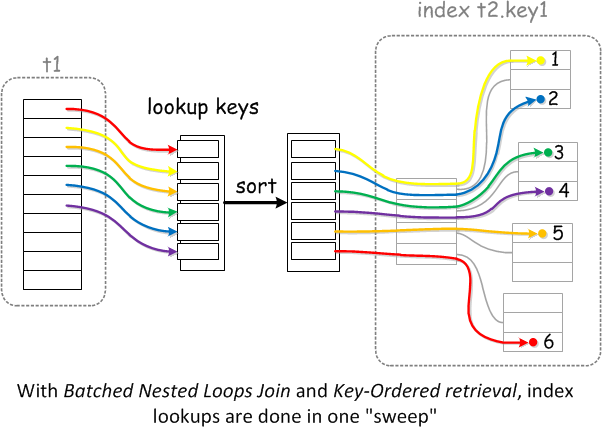
8.0之前连接算法总结
对于嵌套循环连接算法来说,每次我们从驱动表中得到一条记录时,就根据这条记录立即到被驱动表中查询一次,如果得到了匹配的记录,就把组合后的记录发送给客户端,再到驱动表中获取下一条记录,重复进行。
因此,被驱动表的连接条件加上索引,有利于被驱动表快速找到匹配记录。而基于块的嵌套循环连接,则是将驱动表一条一条的匹配,变成多条一起匹配,能显著减少被驱动表被扫描到内存的次数,减少IO,将多条匹配用索引排序后再去与被驱动表匹配,还能减少随机IO的产生。
| 开销统计 | SNLJ | INLJ | BNLJ |
|---|---|---|---|
| 外表(驱动表)扫描次数 | 1 | 1 | 1 |
| 内表(被驱动表)扫描次数 | A表数量 | 0 | A * user_column_size / join_buffer_size + 1 |
| 读取记录数 | A表数量+B表数量* A表数量 | A + B(match) | A + B * (A * user_column_size / join_buffer_size) |
| JOIN比较次数 | B表数量 * A表数量 | A * Index | B * A |
| 回表读取记录次数 | 0 | B(match) | 0 |
HASH JOIN
官方提供的例子https://dev.mysql.com/blog-archiv e/hash-join-in-mysql-8/
SELECT given_name, country_name FROM persons JOIN countries ON persons.country_id = countries.country_id;build 阶段
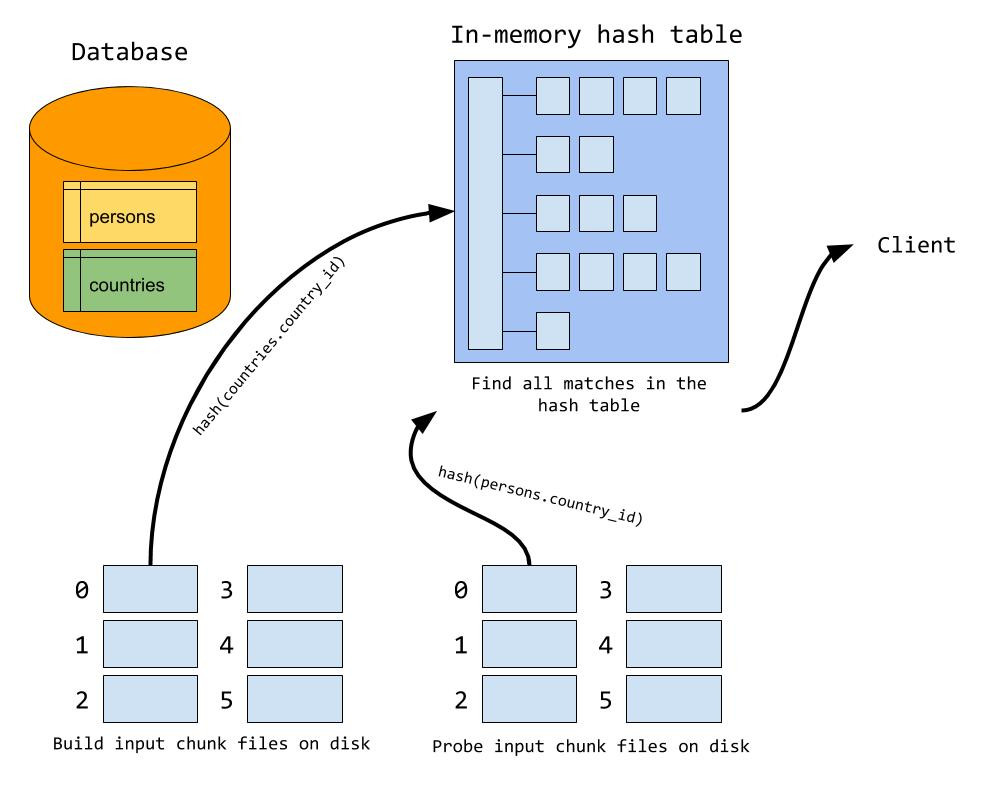
遍历驱动表,以join条件为key,查询需要的列作为value创建hash表。如何选择驱动表呢?标准就是 比较参与join的两个表的结果集的大小,选择结果集小的表作为驱动表。
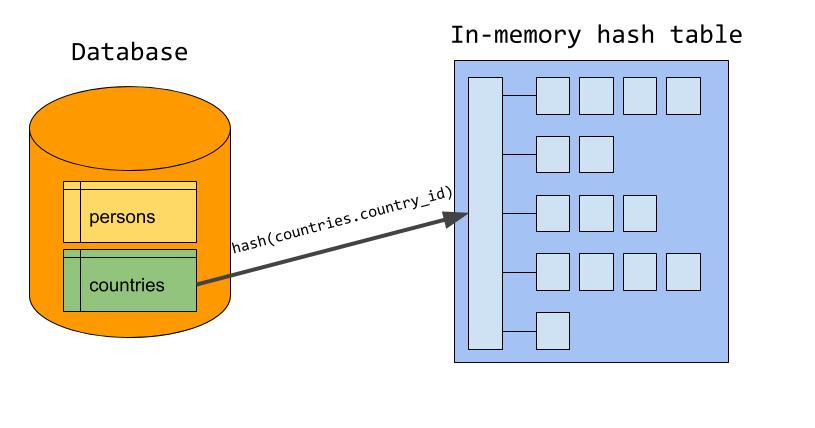
案例中 对 countries.country_id 进行 hash 计算:hash(countries.country_id) 然后将值放入内存中 hash table 的相应位置。countries 表中的所有 country_id 都放入内存的hash 表中。
probe 探测阶段
build阶段完成后,MySQL逐行遍历被驱动表,然后计算 join条件的hash值,并在hash表中查找,如果匹配,则输出给客户端,否则跳过。所有内表记录遍历完,则整个过程就结束了。
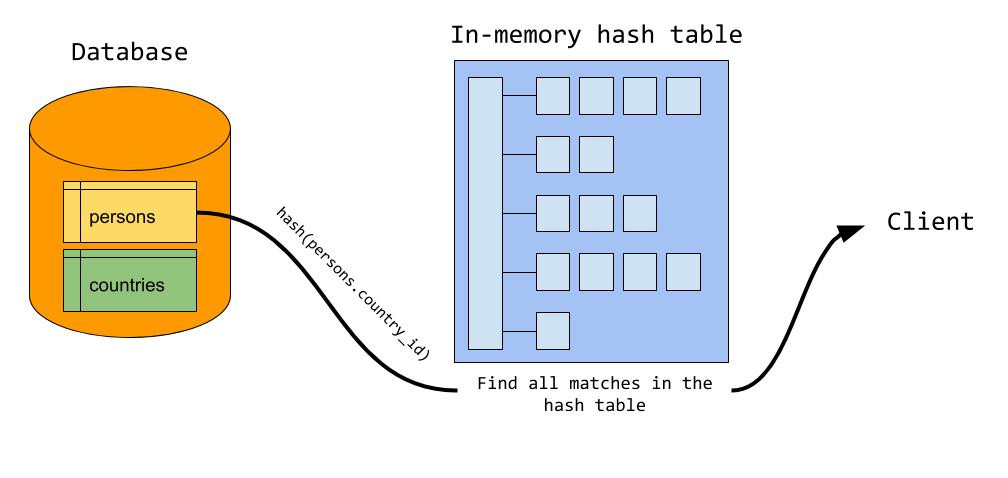
如图所示 ,MySQL 对 persons 表中每行中的 join 字段的值进行 hash 计算;hash(persons.country_id),拿着计算结果到内存 hash table 中进行查找匹配,找到记录就发送给 client。
整体上对驱动表遍历一次,被驱动表遍历1次(被驱动表有N行记录)。
大表处理
hash join 构建hash表的大小是由参数join_buffer_size 控制的,实际生产环境中,如果驱动表的数据记录在内存中存不下怎么办?当然只能利用磁盘文件了。此时MySQL 要构建临时文件做hash join。此时的过程如下:
build阶段会首先利用hash算将外表进行分区,并产生临时分片写到磁盘上;
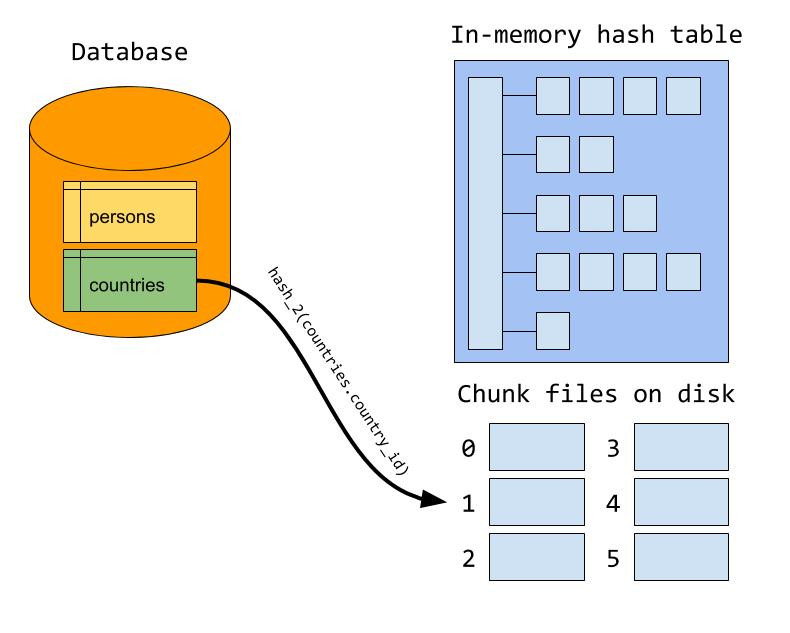
然后在probe阶段,对于内表使用同样的hash算法进行分区。
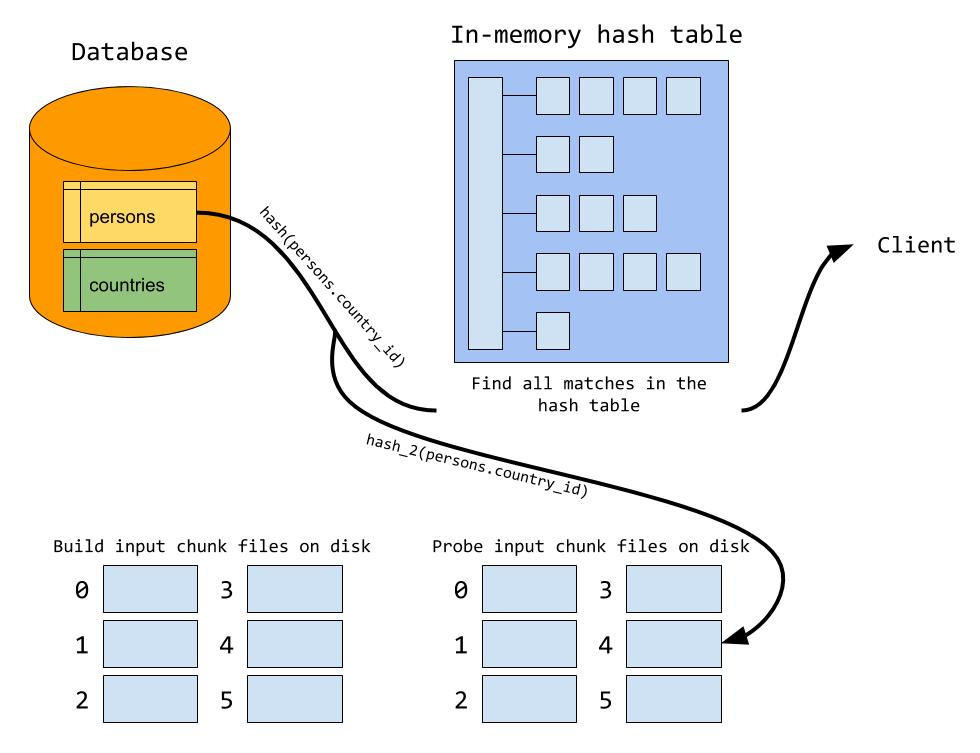
由于使用分片hash函数相同,那么key相同(join条件相同)必然在同一个分片编号中。接下来,再对外表和内表中相同分片编号的数据进行内存hash join的过程,所有分片的内存hash join做完,整个join过程就结束了。
这种算法的代价是,对外表和内表分别进行了两次读IO,一次写IO。另外需要注意的是 需要调大参数 join_buffer_size 和 open_files_limit .
总结
Nest Loop :
对于被连接的数据子集较小的情况是较好的选择。
Hash Join :
Hash Join是做大数据集连接时的常用方式,优化器使用两个表中较小的表利用 Join Key 在内存中建立 散列表 ,然后扫描较大的表探测散列表,找出与 Hash表匹配的行。
这种方式使用于较小的表完全可以放在内存中的情况,这样总成本就是访问两个表的成本之和。
在表很大的情况下并不能完全放在内存,这时优化器会将它分割成 若干个不同的分区 ,不能放入内存的部分就把该分区写入磁盘的临时段,此时要求有较大的临时段从而尽量提高 I/O 的性能。
它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。大多数人都说它是Join的重型升降机。Hash Join 只能应用于等值连接,这是由Hash的特点决定的。
| 类别 | Nested Loop | Hash Join |
|---|---|---|
| 使用条件 | 任何条件 | 等值连接(=) 8.0.18 8.0.20 版本可以支持非等值条件的 |
| 相关资源 | CPU、磁盘I/O | 内存、磁盘临时空间 |
| 特点 | 当有高选择性索引或进行限制性搜索时效率比较高,能够快速返回第一次的搜索结果 | 当缺乏索引或者索引条件模糊时,Hash Join 比 Nested Loop 有效。在数据仓库环境下,如果表的记录数多,效率高 |
| 缺点 | 当索引丢失或者查询条件限制不够时,效率很低;当表记录数多时,效率低。 | 为建立哈希表,需要大量内存。第一次的结果返回较慢 |
