






摘要
简介
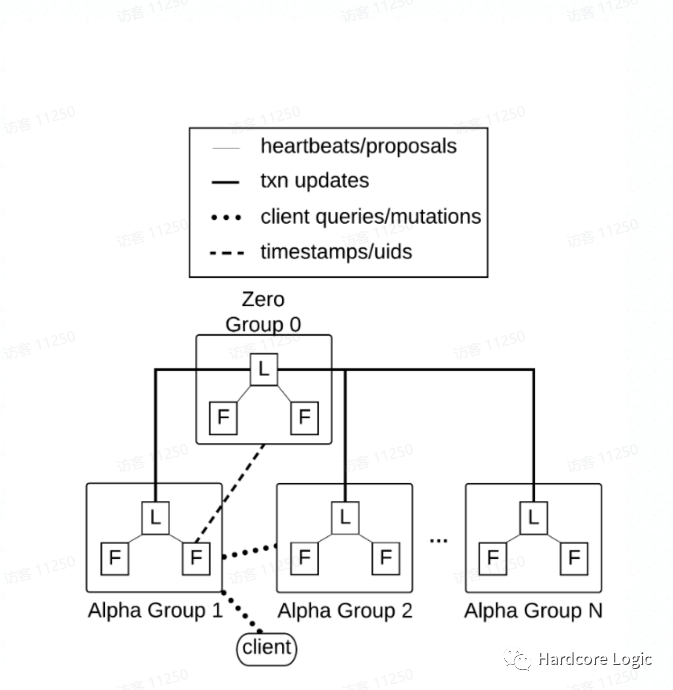
Dgraph体系结构
数据的格式

三元组通常表现为<主-谓-宾>或者<主-谓-值>,主语是一个节点,谓语表示关系,宾语可以是另一个节点或者是某个原始类型的值,谓语表示一种有方向的边,从主语指向宾语或者指向一个值。在上面的例子中name三元组是<主-谓-值>,而follower三元组则是<主-谓-宾>的类型。Dgraph 在处理这两种类型的记录时没有区别,在内部这被认为是一种记录单位,一个典型的json记录将被拆分为多个这样的记录单位。
可以使用GraphQL[7]从Dgraph中检索数据,GraphQL的修改版本称之为GraphQL+-,具有大部分GraphQL相同的属性,并且添加了很多对数据库操作有价值的特性,如查询变量,函数,块,有关查询语言是如何产生的以及GraphQL和GraphQL+之间的区别的更多信息,可以在这篇博客文章中找到[4]
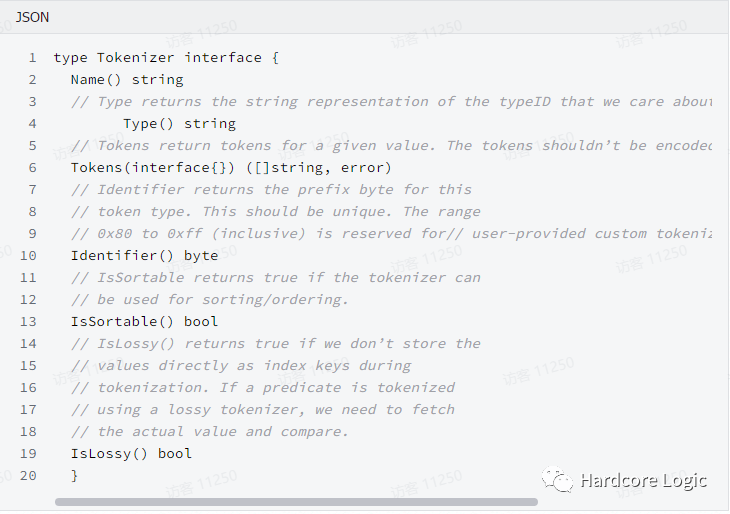
如第2节所述,Dgraph中的所有内部和外部通信都通过GRPC和协议缓冲区运行。Dgraph还公开HTTP端点,支持异构客户端的使用。HTTP端点提供的功能与Dgraph公开的api是等价的。
根据GraphQL的规范,HTTP端口和GRPC端口查询响应的格式都是JSON的。
数据的存储

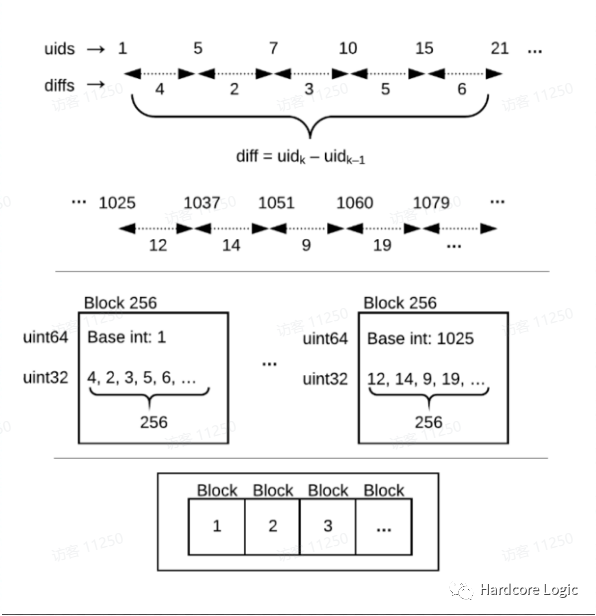
数据的分片


数据的再平衡
当Alpha稍稍落后时,可能会发生错误,服务器会认为它仍在为分片提供服务(尽管分片已移动到另一组),并允许在其自身上运行突变。为了避免这种情况,所有事务状态都会保留写入的分片和组信息(以及它们的冲突键,我们将在第5节中看到)。然后,Zero检查分片组信息,以确保事务观察到的内容(通过它与之对话的Alpha)和Zero 的内容是相同的 如果不匹配将导致事务中止。 另一个错误发生在将分片置于只读模式之后的事务提交-这将导致该提交在分片传输期间被忽略。Zero通过将时间戳分配给移动操作来进行此操作。任何时间戳较高的提交(在此分片上)都将被中止,直到分片移动完成并且分片返回到读写模式。 当目标组接收到低于迁移时间戳的读取,或者源组在删除碎片之后接收到读取时,可能会发生另一次错误。在这两种情况下,都不存在可能导致读取错误地返回空值的数据。Dgraph通过通知目标组移动时间戳来避免这种情况,它可以使用该时间戳来拒绝对分片的任何读取。类似地,zero包括成员资格标记,源Alpha在该组可以删除碎片之前在该成员标记处阻塞,因此,该组的每个Alpha成员在删除它之前将知道它不再服务于数据。
索引
多版本并发控制
事务

无锁的高可用性事务

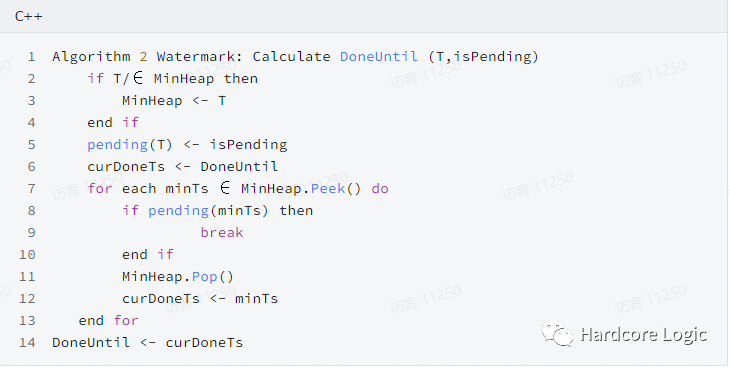
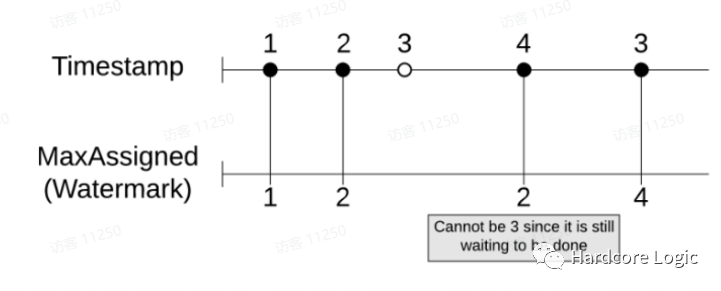
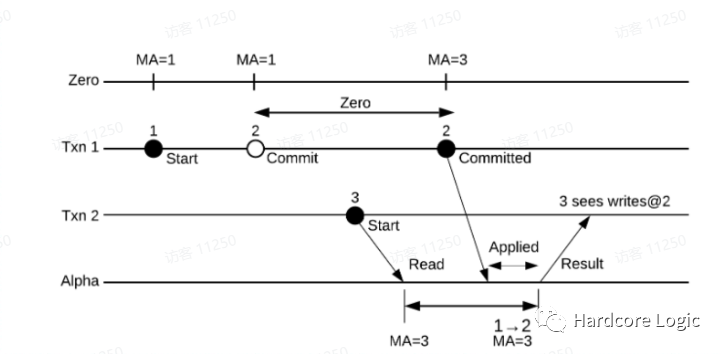
一致性模型
复制
高可用性与扩展性
查询
遍历
函数
过滤器
交集
未来的工作
文章转载自Hardcore Logic,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
