python代码:基于DDPG(深度确定性梯度策略)算法的售电公司竞价策略研究
关键词:DDPG 算法 深度强化学习 电力市场 发电商 竞价
说明文档:完美复现英文文档,可找我看文档
主要内容:
代码主要研究的是多个售电公司的竞标以及报价策略,属于电力市场范畴,目前常用博弈论方法寻求电力市场均衡,但是此类方法局限于信息完备的简单市场环境,难以直观地反映竞争性的市场环境,因此,本代码通过深度确定性梯度策略算法(DDPG)对发电公司的售价进行建模,解决了传统的RL算法局限于低维离散状态空间和行为空间,收敛性不稳的问题,实验表明,该方法比传统的RL算法具有更高的精度,即使在不完全信息环境下也能收敛到完全信息的纳什均衡。
此外,该方法通过定量调整发电商的耐心参数,可以直观地反映不同的默契合谋程度,是分析市场策略的有效手段。
目前深度强化学习非常火热,很容易出成果,非常适合在本代码的基础上稍微加点东西,即可形成自己的成果,非常适合深度强化学习方向的人学习
这段代码包含了三个程序,我们分别来进行详细分析。
YID:77180647355363555
程序一:
import numpy as np
from market.three_bus import market_clearing
from algorithm.VRE import RothErevAgents
import matplotlib.pyplot as plt
n_agents = 2
action_space = np.arange(0, 3.1, 0.2)
n_steps = 10000
a_real = np.array([15.0, 18.0])
strategic_variables = np.zeros((n_steps, n_agents))
multi_agents = RothErevAgents(n_agents, action_space)
for step in range(n_steps):
action = multi_agents.select_action()
alpha = action * a_real
nodal_price, profit = market_clearing(alpha)
strategic_variables[step] = alpha
multi_agents.learn(profit)
if (step + 1) % 1000 == 0:
print('Step:', step + 1, 'a1: %.2f' % alpha[0], 'a2: %.2f' % alpha[1],
'r1: %.3f' % profit[0], 'r2: %.3f' % profit[1])
C = np.array([[0.36, 0.58, 0.75],
[0.92, 0.28, 0.29]])
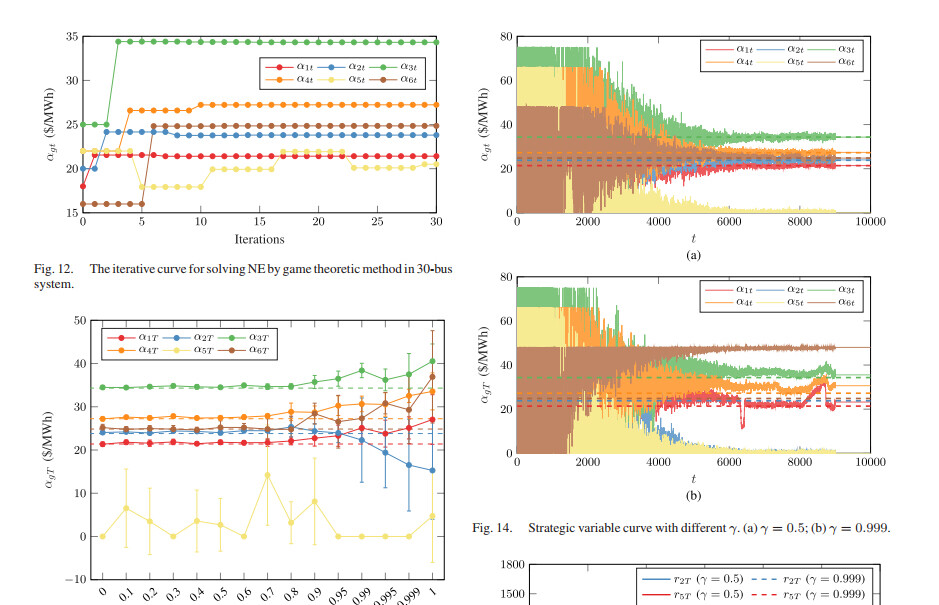
plt.plot(strategic_variables[:, 0], lw=0.5, C=C[0], alpha=0.5, label=r"$\alpha_{1t}$")
plt.plot(strategic_variables[:, 1], lw=0.5, C=C[1], alpha=0.5, label=r"$\alpha_{2t}$")
plt.plot([0, 10000], [20.29, 20.29], '--', C=C[0], label=r"$\alpha_{1t}^\ast$")
plt.plot([0, 10000], [22.98, 22.98], '--', C=C[1], label=r"$\alpha_{2t}^\ast$")
plt.xlabel(r"$t$")
plt.ylabel(r"$\alpha_{gt}$ (\$ MHh)")
plt.title("VRE (3-Bus System)")
plt.legend()
plt.savefig('VRE.png', dpi=600)
plt.show()
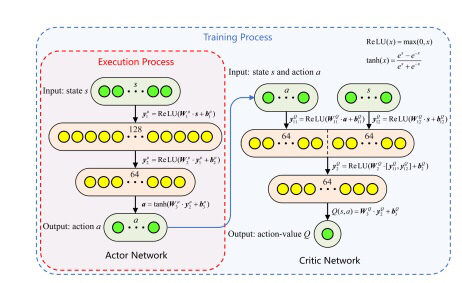
这段代码主要是使用了RothErevAgents算法来进行市场交易的仿真。程序首先导入了一些必要的库,然后定义了一些变量,包括代理数量(n_agents)、动作空间(action_space)、仿真步数(n_steps)和真实的动作值(a_real)。接下来,创建了一个RothErevAgents对象(multi_agents),该对象使用Roth-Erev算法来选择动作。
在每个步骤中,程序通过调用multi_agents.select_action()来选择动作。然后,根据选择的动作和真实的动作值计算alpha值。接着,使用market_clearing函数计算节点价格和利润。将alpha值存储在strategic_variables数组中,并使用multi_agents.learn()函数来更新代理的策略。
在每1000个步骤后,程序会打印出当前步骤数、alpha值和利润。最后,程序使用matplotlib库绘制了两个alpha值随时间变化的图形,并保存为图片。
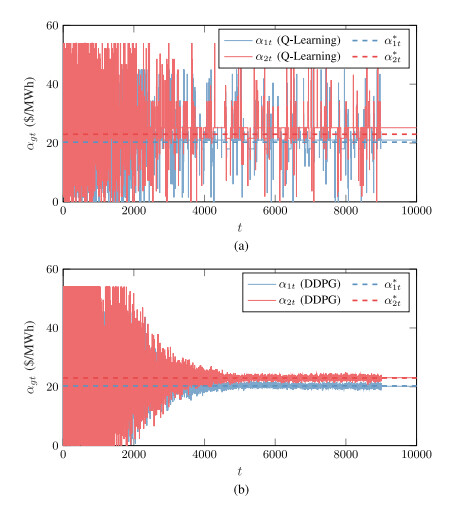
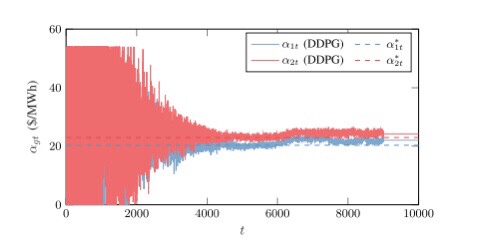
程序二和程序三的结构与程序一类似,只是使用了不同的算法(QLearning和DDPG)和模型(ANet2和CNet2)。它们的功能和工作方式与程序一类似,只是算法和模型的不同。