点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
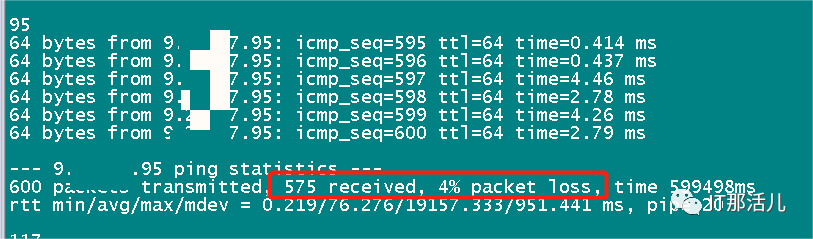
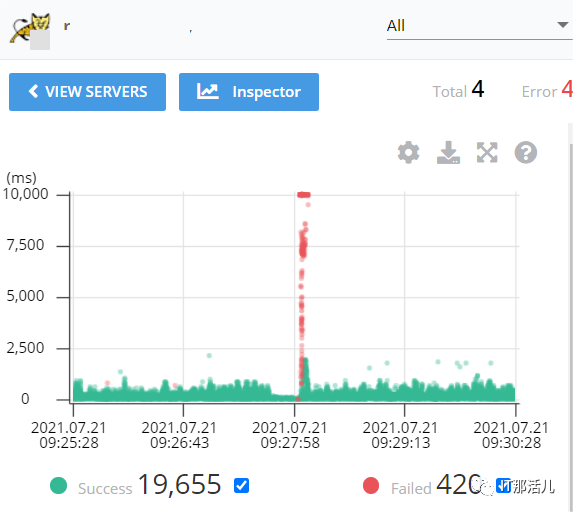
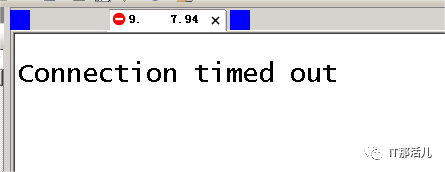
系统平台redis于9:27左右有业务反馈慢问题,同时监控上上存在明显波动。经排查redis日志、ping日志发现存在ping9.*.*.95存在丢包及延迟,发生主从切换,从9.*.*.95:9002切换到9.*.*.94:9001。
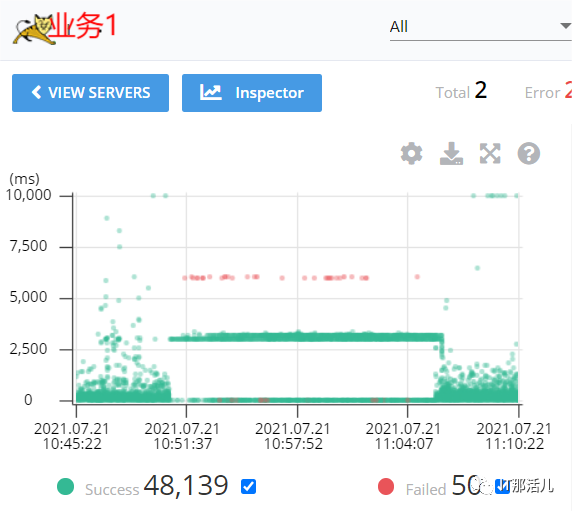
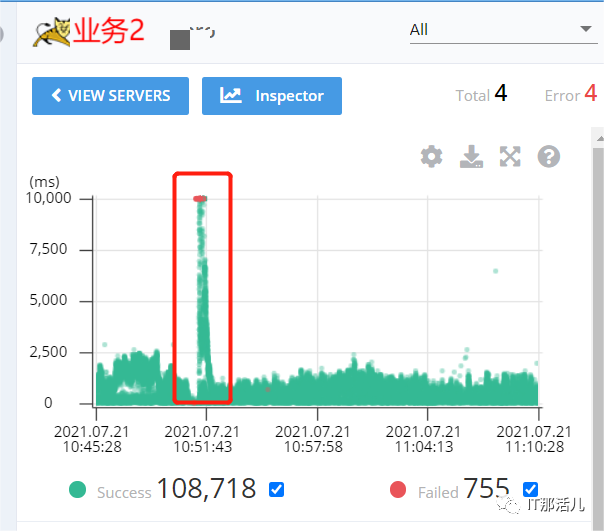
在10:50左右,业务又反馈慢,经排查发现9.*.*.94主机异常,发生主从切换,监控中系统平台业务访问redis在主从切换时存在短暂波动,主从切换完毕后恢复正常,而业务访问redis一直存在异常,持续到9.*.*.94节点恢复。
9.*.*.94:9001 master
9.*.*.94:9002 slave
9.*.*.95:9001 slave
9.*.*.95:9002 slave
9.*.*.117:9001 master
9.*.*.117:9002 master
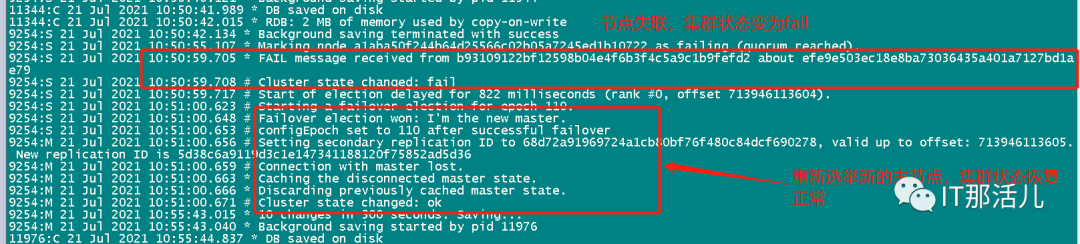
从redis日志查看,在10点50分55秒,redis cluster判断9.*.*.94:9001节点(master)和9.*.*.94:9002(slave)节点发生故障,redis cluster确认后,进行切换,9.*.*.94:9001 master节点变更为9.*.*.95:9002节点。
在10:50:59有主节点失联,重新选举主节点后集群状态在10:51恢复为ok,94节点仍然失联。在11:04:36,9.*.*.94节点恢复,加入集群开始同步数据。3)117:9002节点数据较多,网卡流量大。
通过监控发现业务访问redis只有在主从切换时存在短暂波动,主从切换完毕后恢复正常,而业务访问redis的波动持续到9.*.*.94节点恢复。
通过排查发现业务连接redis的客户端不同,业务2使用jedis方式,而业务1使用Lettuce连接,Lettuce存在RedisCluster集群模式下master宕机主从切换期间Lettuce连接Redis无法使用报错Redis command timed out的问题。Redis集群配置在运行期间可能会改变,可以添加新的节点,为特定插槽的主节点可以发生改变,Lettuce处理Moved和Ask永久重定向,但是由于命令重定向,你必须刷新节点拓扑视图,拓扑是绑定到RedisClusterClient的示例,所有由一个RedisClusterClient实例创建的节点连接共享相同的节点拓扑视图。1)Either by calling RedisClusterClient.reloadPartitions 通过调用RedisClusterClient.reloadPartitions。2)Periodic updates in the background based on an interval3)Adaptive updates in the background based on persistent disconnects and MOVED/ASKredirections总结及建议:
1)拆分大key:大key会造成高并发下网络带宽跑满卡死现象。3)更换更好的硬件,摆脱虚机不稳定因素和资源共享弊端。