




摘要
DDL是数据库所有SQL操作中最繁重的一种,本文总结介绍了PolarDB中DDL全链路MDL锁治理的经验和进展,持续优化用户的使用体验,为用户打造最佳的云原生关系型数据库。
1. 概述
在日常数据库操作中,用户总是谈DDL色变,原因在于总是担心DDL的执行会影响业务SQL,这里面最核心的因素在于DDL持有的MDL表锁导致的锁堵塞问题。另一方面,由于DDL类型众多,用户难以区分不同类型DDL的锁行为,无法判断执行DDL可能导致的后果,这进一步加剧了该问题的复杂度。通过多年大量线上实例的经验积累, 我们非常理解用户在面对这类MDL锁问题时的困惑。本文整理总结了PolarDB MySQL内核团队在全链路MDL锁治理这块的经验和进展,鞭策我们为“DDL无锁”、为用户可以毫无担忧地执行DDL而持续努力。针对MDL锁相关的背景知识,我们有持续的内核月报在介绍这方面的原理,感兴趣的读者可以自行查询 常用SQL语句的MDL加锁及源码分析和 MDL锁实现分析。在开始全文前,我们首先回顾用户主要关注哪些方面的DDL锁问题:
- 1.什么时候拿锁
很不幸的是,无论是MySQL内核原生的DDL,还是各种第三方插件(gh-ost、pt-osc,以及云厂商们的“无锁变更”),几乎所有的DDL都会申请表级别的MDL互斥锁。这里的核心原因在于:DDL的目标是表结构/表定义变更,它必然会修改元数据/字典信息,因此DDL依赖MDL锁来完成元信息、文件操作和相应缓存信息的正确更新。当DDL修改元数据时,它申请表级别的MDL互斥锁,从而堵塞并发的元数据查询/修改操作,继而可以线程安全地更新元信息缓存,从而保证所有线程用正确版本的元数据解析对应版本的表数据。
说到这里,很多熟悉MySQL的读者一定会问,那为什么gh-ost等第三方插件在做DDL时似乎呈现出一种类似“无锁”的表现呢?其实这里的核心差别在于,MySQL内核和第三方插件,在处理“拿不到锁”这个问题时采用了完全不一样的策略。
- 2.拿不到锁会导致什么问题(雪崩 vs. 饥饿,本文关注的核心问题)
相比于第三方插件,MySQL内核的MDL拿锁机制简单粗暴:当DDL申请MDL-X(互斥锁)时,如果目标表存在未提交的长事务或大查询,DDL将持续等待获取MDL-X锁。由于MDL-X锁具有最高的优先级,DDL在等待MDL-X锁的过程中将阻塞目标表上所有的新事务,这将导致业务连接的堆积和阻塞,继而可能带来整个业务系统「雪崩」的严重后果。
为了避免这个问题,MySQL社区开发了很多外部工具,比如pt-osc和github的gh-ost。它们均采用拷表方式实现,即创建一个空的新表,通过select + insert的方式拷贝存量数据,然后通过触发器或者binlog的方式拷贝增量数据,最后通过rename操作切换新表和旧表。云厂商的各种工具,例如DMS的无锁变更也与这些外部工具原理类似。但很遗憾,这种方式也存在明显的劣势:1. 可能由于大事务/大查询的存在,DDL持续拿不到锁,持续等待直到反复失败(「饥饿」);2. 不管是Instant DDL(例如秒级加列),还是仅增加二级索引,第三方工具都无脑选择了全表重建的方式,通过大幅牺牲性能来追求稳定性。我们之前的测试表明(月报链接),相比于内核原生的DDL执行方式(INSTANT / INPLACE / COPY),gh-ost有着10倍甚至几个数量级的性能下降,这在数据量快速增长的今天是完全无法忍受的。
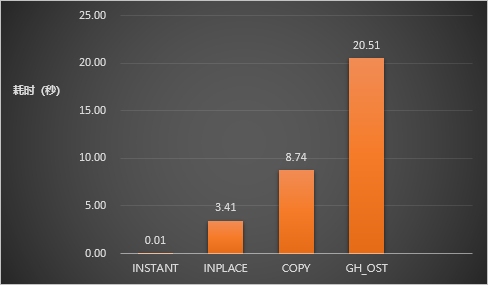
不管是第三方插件,还是MySQL内核,很遗憾,任何一种方式都不能在所有场景里都达到最优。PolarDB-MySQL内核团队尝试在保留最佳性能的前提下,同时解决雪崩和饥饿这两个问题。
- 3.拿到锁又会导致什么问题(持有锁的时间,Fast DDL会在以后的文章中介绍)
在解决了「拿不到锁」的问题后,我们同样要解决「拿到锁后」会有什么问题,即如果互斥锁持有时间过久,同样会导致业务堆积雪崩等问题。熟悉MySQL的用户都知道,MySQL有三种DDL类型,分别是「INSTANT DDL」、「INPLACE DDL」和「COPY DDL」。其中,Online DDL(用户常说的“非锁表”DDL,包括INSTANT DDL和绝大多数INPLACE DDL)在执行DDL期间绝大多数时刻并不锁表,只在修改元数据时短暂持有表的MDL-X锁(持有时间一般秒级),用户体验良好。当前的MySQL 8.0,已经实现了常见高频DDL的Online能力,例如增加索引、秒级加列,加减主键等等。但是,因为涉及一些SQL层的操作,目前依然存在COPY类型的DDL,它在执行DDL期间「全程锁表」(只能读不能写),例如修改表的字符集、修改列类型等操作。针对这类COPY DDL,PolarDB MySQL的解决方案是扩展Online DDL(不锁表)的范围,例如支持Instant Modify Column(秒级修改列类型),例如尝试在SQL层支持所有DDL的Online能力,我们将这类能力统称为「Fast DDL」,笔者后续会统一介绍这方面的工作,本文不再赘述。
相比于MySQL,PolarDB的集群架构使得这一问题变得更加复杂:MDL锁不仅要关注单个节点,更要关注集群多个节点/集群同步链路上的锁问题,需要集群维度的全链路解决方案。熟悉MySQL的用户,对基于Binlog的MySQL主备集群一定非常熟悉。在依赖Binlog的MySQL主备复制集群上,主备节点是逻辑隔离的。也就是说,主节点的MDL锁行为,并不会对备节点的MDL锁有任何影响,因此MySQL只需要考虑单个节点的MDL锁问题。然而,PolarDB MySQL是基于共享存储的架构。以一写多读集群为例,写节点和多个只读节点共享同一个分布式存储,依赖物理复制完成不同节点之间的数据同步。写节点在做DDL操作时,多个只读节点都会看到DDL过程中的实时数据。因此,PolarDB的MDL表锁,是一个集群维度的分布式锁,需要考虑多节点上的锁堵塞问题。
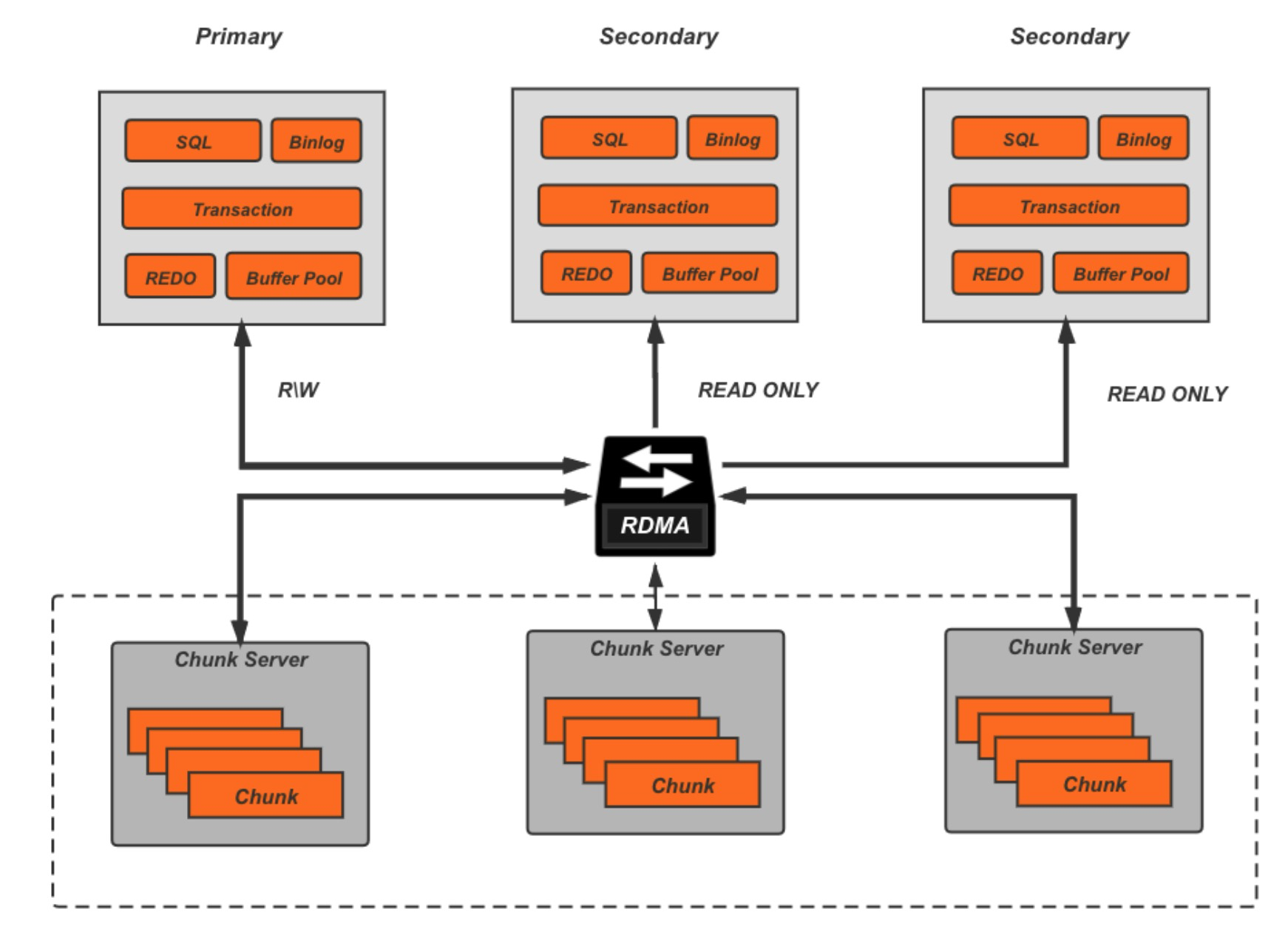
基于PolarDB的架构特征,结合多年的线上运维经验,我们认为从集群维度看,要实现用户体验良好的DDL锁机制,需要达到以下几个目标:
- 解决饥饿问题。Non-Block DDL在拿不到锁时,通过Retry等方式避免DML的堆积和雪崩。然而如果存在大事务或者大查询,DDL可能一直拿不到锁而持续失败。进一步的,随着PolarDB MySQL的大客户越来越多,单实例不乏10+个只读节点的用户,这大大增加了集群维度出现大查询/大事务的概率,导致DDL拿不到锁。针对这类问题,PolarDB MySQL最近推出了Preemptive DDL能力(用户文档),即赋予DDL最高的MDL锁权限,在满足条件的情况下主动kill堵塞它的事务/查询,保证DDL的顺利执行;
- 解决表「数据变更」、「元信息/元信息缓存变更」和「文件操作」 这三者之间的数据一致性和实时性问题。众所周知,TP数据库对事务的要求极高,而DDL过程中涉及的数据变更、表结构变更和文件操作这三者之间需要在任何一个时间点都要满足Consistency的要求。而在基于共享存储的PolarDB MySQL中,这一问题变得更加复杂:不仅在所有阶段(正常数据同步、数据库Recovery、按时间点还原等等)需要满足多节点在数据变更、表结构变更和文件操作这三者的一致性要求,而且需要保证良好的性能,满足强实时性的要求。针对这类问题,PolarDB MySQL做了一系列的优化,由于这部分内容要求的数据库背景和对代码的理解要求过高,并且用户业务无需感知,本文不展开介绍这一部分的工作;
- 解决DDL过程中RW->RO物理复制链路的堵塞问题。上线五年以来,PolarDB MySQL支持了大量行业,不同行业的业务场景对DDL的要求是不同,具体表现在:1. 高频DDL导致的高性能MDL锁需求,例如SAAS等行业场景,DDL是个非常常见和高频的操作。PolarDB需要避免分布式MDL锁和物理复制的耦合性,避免因为锁堵塞等行为影响整个集群的数据同步;2. DDL伴随高负载的业务压力,例如在大压力场景下加索引。这种场景会产生大量的redo日志,PolarDB需要保证DDL过程下物理复制链路的稳定性、低延迟。针对上述问题,PolarDB MySQL在物理复制全链路做了优化(用户文档),采用了异步线程池和反馈机制,解耦了MDL锁同步和物理复制的强耦合性,并优化了DDL过程中redo日志的同步&复制速度(用户文档),满足了大压力DDL场景下的同步要求;
- 持续演进的能力:DDL & DML MVCC。如前文所述,在极限情况下,用户依然需要手动执行Preemptive DDL来解决饥饿问题。我们一直在想,有没有更理想的方式,用户可以完全无感知MDL锁的存在。熟悉InnoDB的读者一定知道,InnoDB提供了行级别的MVCC能力,即使修改某行数据的事务没有提交,这时候另一个事务查询同一行数据时,事务根据它的时间戳,通过undo list构建出对应的版本,无需等待锁的释放。细心的读者一定会问,为什么DDL没有提供DDL和DML互不堵塞这种MVCC的能力?原因在于,DDL操作涉及了文件操作/表数据/元信息/表结构缓存等多种信息的变更,因此为了达到DDL & DML的MVCC能力,涉及大量的模块/代码修改,带来的代码切口过大,稳定性风险较高。但是为了满足客户的诉求,PolarDB内核团队一直在这条路径上试图找到工程上的最优路径。在PolarDB 802的下个版本中,我们将提供给用户这一实验室功能,即满足Instant Add Column这种高频DDL与DML的「MVCC」能力,后续我们会陆续支持Add Index等高频DDL与DML的MVCC能力。
