最近AI非常火,相信大家都非常期待这次生成式AI可能带来的变化。作为关系型数据库的从业者,似乎和生成式AI离得比较远:D。但是作为关系型数据库中存储引擎的开发者,能很直观地理解,当这波AI浪潮来势汹汹,这么庞大的数据规模和终端用户群,对底层的数据存储一定是个巨大的挑战。如果底层存储成为瓶颈,那将进一步影响分布式训练系统的训练效率,毕竟对于这波AI大潮而言,分秒必争,时间就是金钱。所以,笔者一直非常好奇AI存储系统的I/O特征。趁着周末,找了找相关论文,发现今年FAST'23上有一篇介绍深度学习IO特征相关的论文:《Shade: Enable Fundamental Cacheability for Distributed Deep Learning Training》,遂展开读了读,本文仅仅做一个阅读笔记。作为AI系统的门外汉,笔者比较关注文章透传出来的系统I/O特征,所以笔记会有一定倾向性,对其它方面感兴趣的读者可以直接阅读全文。另外,笔者也发现了一系列与IO相关的论文,后面也将进一步阅读与总结。
文章一开始就阐明了深度学习训练(DLT)展现了比较独特的IO负载特征,这对存储系统的设计引入了一些新的挑战。一方面,DLT在训练过程中,需要不断从Remote Storage获取数据样本,具备I/O密集型的特征。另一方面,DLT广泛利用GPUs加速训练过程,所以同样具备计算密集型的特征。然而,指数级增长的样本数据集使得这些数据不可能完全存储在内存中,并且GPUs处理能力在持续提升,这导致滞后的I/O性能成为了整个分布式DLT系统中的性能瓶颈。笔者看到这里,会心一笑,想到David John Wheeler的那句名言:“计算机科学中的任何问题都可以通过加上一层间接层来解决”,所以在这个问题背景里一定是需要加cache了:D,我们往后看。
文章提到,尽管目前的DLT框架通常使用随机抽样策略来平等地处理所有样本,但最近的研究表明,不是所有样本都同等重要,不同的数据样本对提高模型精度的贡献是不同的。因此,我们很容易能推断到,可以通过利用那些贡献更高的数据样本的局部性,来优化整个DLT系统里的I/O情况。因此,文章作者们设计和实现了SHADE,这是一种新的DLT感知型的缓存系统。SHADE通过细粒度的样本级的动态重要性检测机制,并通过一种新的Rank方式捕捉不同批次里数据样本的重要性,这为DLT jobs提供了更精确的缓存策略。文章的测试结果表明,计算机视觉(CV)模型的评估显示,即使在更小的缓存情况下,相比于LRU的策略,SHADE将缓存命中率最高提到了4.5倍。
文章概述
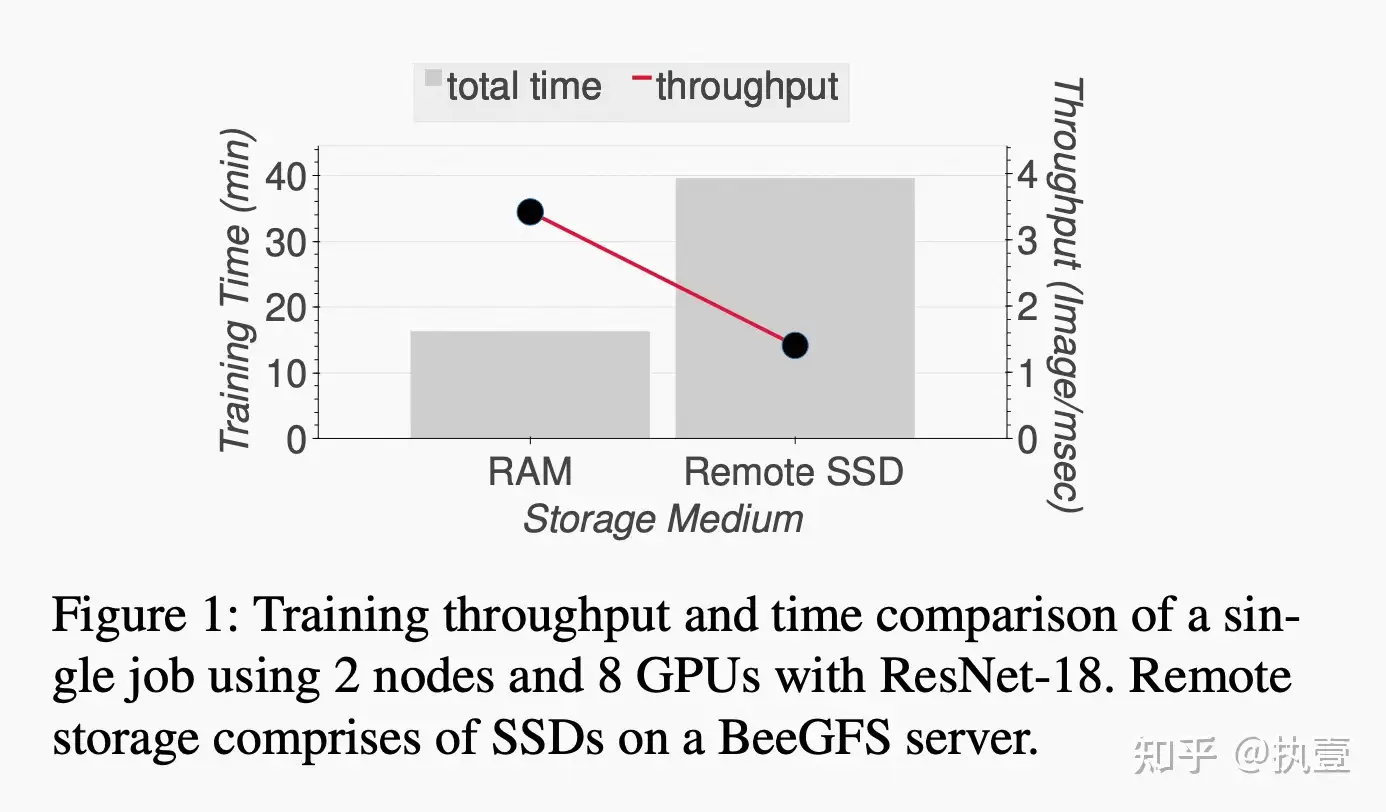
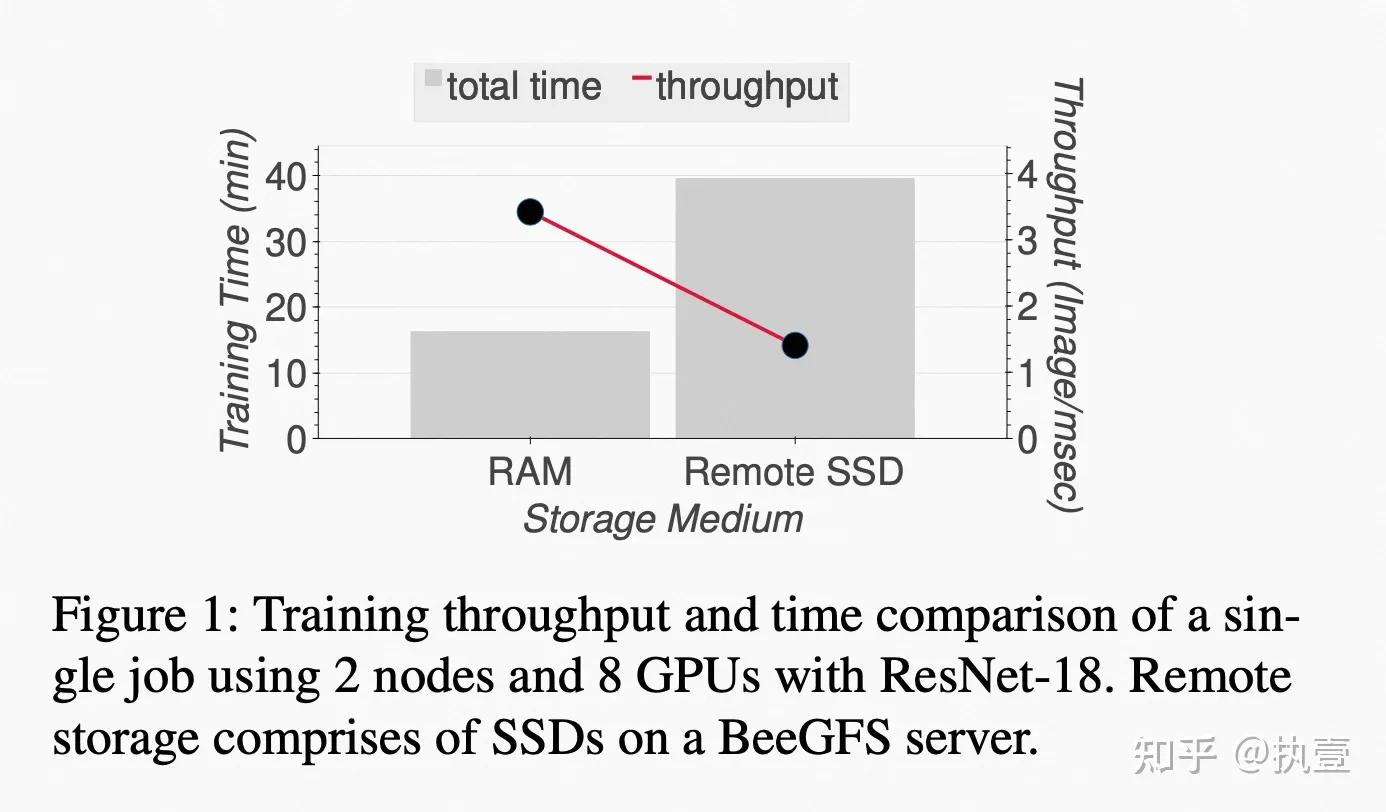
为了分析存储系统对分布式深度学习训练效率的影响,文章做了一个实验,研究当分布式深度学习Job使用本地 vs. 远程存储介质运行时的性能差异。Figure 1显示,即使所有其它训练配置保持相同,相比于更快的存储介质(例如RAM,本地内存),远程存储介质也会显著加大训练时间(大约2.5倍)。更为夸张的,研究表明I/O甚至占据了总训练时间的85-90%。另外,文章也论证了,在日愈膨胀的数据集和抢占式的VM恢复方面,大型数据集必须放在持久化云存储中,而不是本地内存或者本地盘上,这一点比较好理解。因此,如果能有效降低I/O的延迟,就可以显著提升GPU的训练效率。阅读到这里,相信大家很快能get到文章要解决的问题,那直观的解决方案就是缓存来降低I/O延迟。进一步的,缓存的核心原理是挖掘locality,常见的要么是spatial locality,要么是time locality。那么,很自然就会联想到,分布式DLT的访存特征是什么样的?可挖掘的locality是什么?
但是,相比于传统的数据密集型应用(比如我们熟知的大数据分析或者web应用),DL训练过程具备不一样的I/O特征。DL training jobs通常运行多个epoch,每个epoch随机顺序访问整个训练数据集,并且每个epoch进一步分割为多个batch。在开始处理一个batch时,每个GPU进程会随机加载一个大小可配置的、随机采样的bulk(例如mini-batch)。总结一下,对于分布式DLT而言,提高I/O效率仍然是一项具有挑战性的任务,因为它的工作负载呈现出较为独特的特征:(1) 按照每个对象粒度的只读顺序访问;(2) 占大多数的是大量随机的小I/O,并且这部分I/O分散在整个训练样本数据集中;(3) 高并发大压力的I/O。I/O呈现出来的随机性、数据局部性不足和大压力,这导致传统的缓存机制难以发挥出价值,不论是LRU、LFU还是ARC等广泛使用的缓存策略。
因此,作者尝试通过挖掘DL的训练方式,定位其I/O特征。众所周知,深度神经网络(DNN)模型由多个计算单元层组成,其输出是后续单元的输入。DNN模型训练采用前向传播方法,依次将与输入数据相关的信息通过所有模型层传递,并生成预测。为了生成预测,DL定义了一个与前向传播输出和真实标签相关的coss/loss函数,并在训练过程通过增加或减小模型中间层输出的权重来最小化cost函数,从而提高预测率。这一步骤称为反向传播,它通过梯度下降优化技术,从最外层到输入层调整DL模型的参数。SGD是梯度下降优化的随机近似方式:它随机选择训练数据子集来降低计算成本,而不是从整个数据集计算梯度。在典型的基于SGD的data-parallel训练过程中,整个训练数据集通过切分,从而由多个GPU设备并行处理。每个GPU具备相同的DNN模型副本,并通过集中式通信方式(例如参数服务器)或者去中心化的通信方式(例如all-reduce)进行迭代同步。
传统上,基于SGD的深度学习训练对于训练样本的“重要性”毫不关注,因为它们只是在每个训练周期结束时随机排列顺序,从而平等对待所有的训练样本。然而,文章提到在最近的一些研究中,研究人员发现,在基于SGD的深度学习训练中,一组特定的训练样本往往对模型质量产生很小或没有影响,因此可以忽略它们。另一方面,通过找到比其它样本更重要的训练样本集合,即对损失函数最大贡献的样本集合(这个过程被称为重要性采样),这些样本在几个epochs后会导致在反向传播中的隐藏层输出和目标标签之间出现更大的loss。因此,通过优先使用相对更重要的训练样本来训练,可以明显降低整个训练系统的训练时间和减少测试错误。
作者在FAST'23的演讲PPT,更能清楚地说明这个特征。例如下图是识别字母的训练任务,在整个训练过程中,更难学习的样本反而是更加重要的。比如左边三个字母“c e t”非常清晰,很快就能被神经网络所识别。然而右边两个字母“e t”却非常模糊潦草,相对来说需要更多轮的反馈和训练,所以显然更加重要。

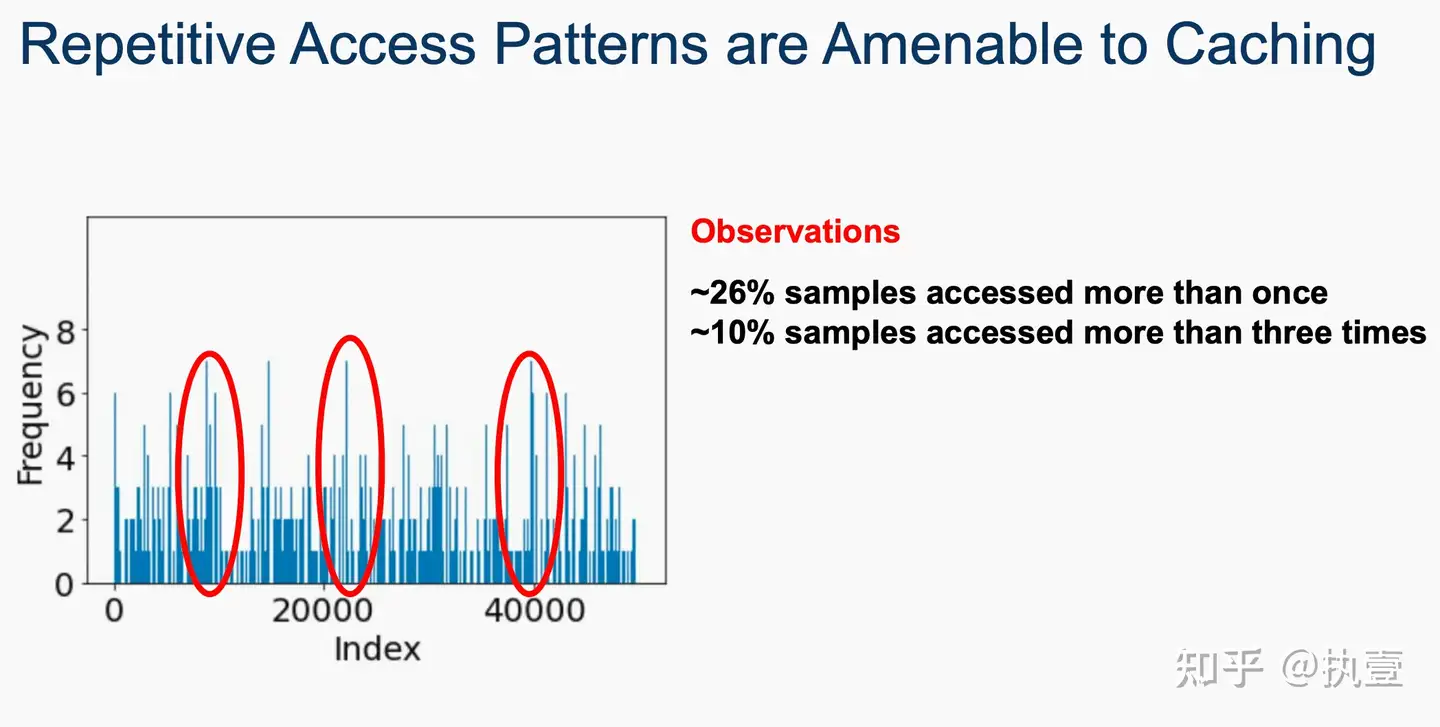
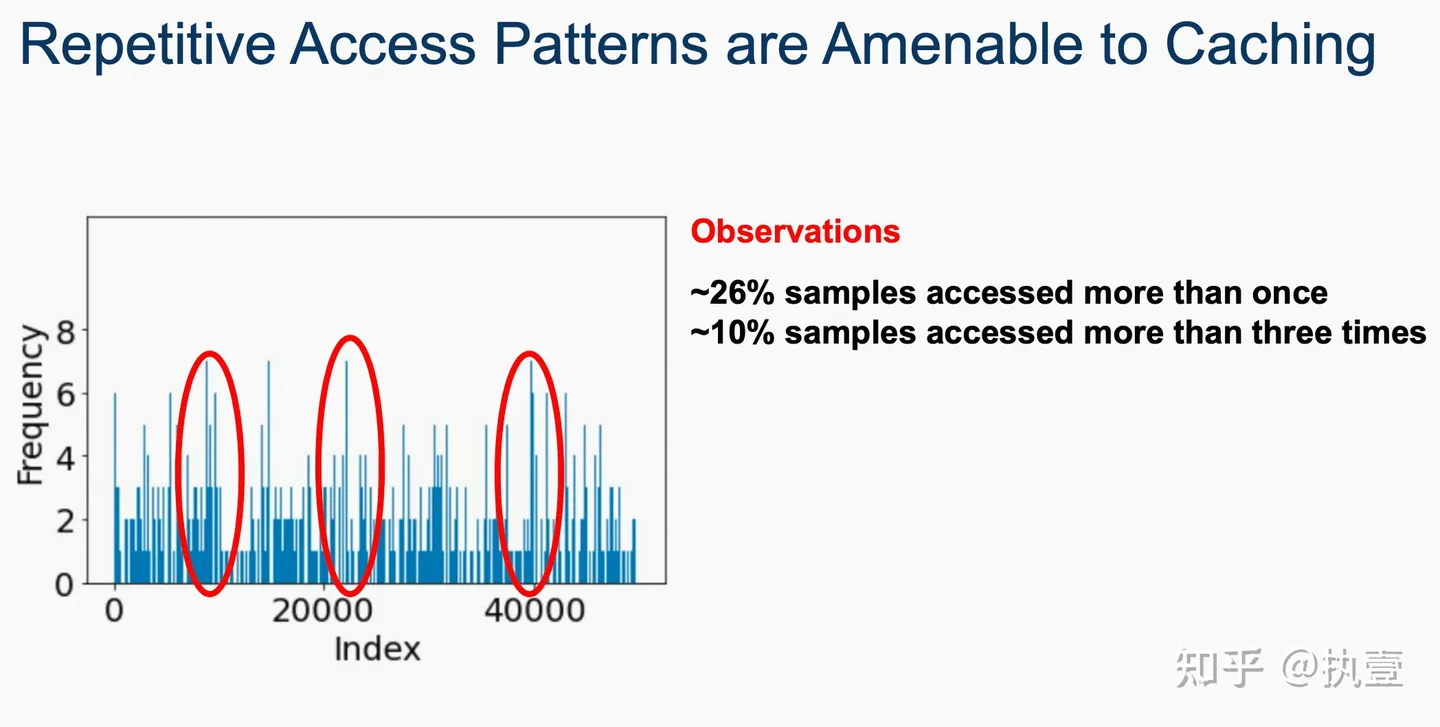
进一步的,作者通过多个benchmark的分析(如下图所示),发现的确有一部分数据在一次epoch或者多次epoch中被访问的频率明显更高。因此,他们尝试从这种重要性差异的角度出发,设计更加有效的机制和策略,提高DL训练的可缓存性。文章将单个数据样本的inter-batch和intra-batch重要性相结合,以检测最重要的样本并将其放置在内存池化缓存中。此外,文章开发了一种新颖的基于排名的重要性技术,它基于样本对提高模型整体准确率的贡献对批次内的训练样本进行排名。基于排名的重要性进一步有助于增加在后续时期识别(预测)最重要样本的概率。利用这种技术,文章进一步设计了一种基于优先级的采样策略,确保在一个时期内多次访问重要样本以更多地训练难以学习的样本,以提高准确率提高率。因此,这种缓存解决方案将更重要的样本保留在缓存中,并避免随机淘汰,从而提高缓存命中率和训练吞吐量。
如上文所述,SHADE的目标就是利用重要性抽样来提高DLT的I/O工作负载的缓存效率。想达到这个目标,需要解决以下的三个问题:1. 简单的重要性采样策略分配了每个mini-batch的得分,但是这种方式过于粗糙,以至于并不准确。也就是说,所有mini-batch里的样本数据默认情况下被分配同样的重要性得分,从而使每个样本的重要性估计并不准确,影响了缓存效率。因此,SHADE希望能够精确评估每个样本数据在mini-batch中所具有的相对重要性;2. 即使正确识别了重要的样本,过度地向DL模型提供重复的样本可能会使模型训练出现偏差。因此在尝试增加样本击中率的同时,必须确保不会影响模型的准确性;3. 重要性得分在动态发生变化,可能很快就会过时。在后续mini-batch中,同一个样本对模型的贡献可能与之前的mini-batch是不同的。因此,获取最新的重要性得分信息是必要的,以做出明智的缓存决策。简单来说,SHADE需要设计细粒度的动态重要性追踪机制,并且不能影响模型的准确性。
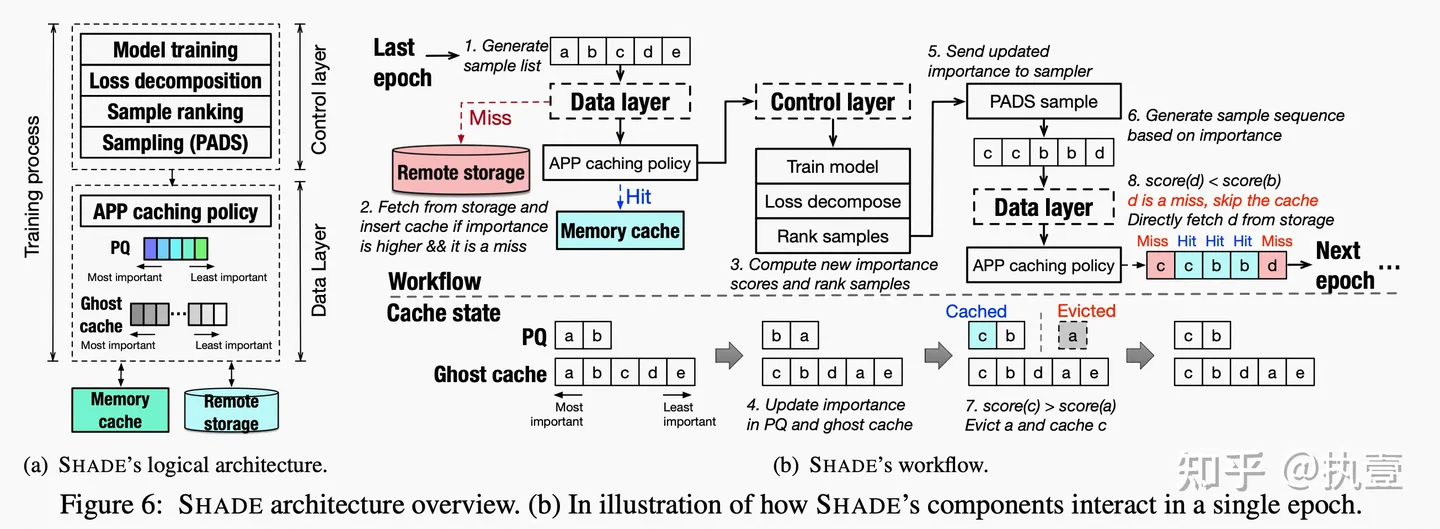
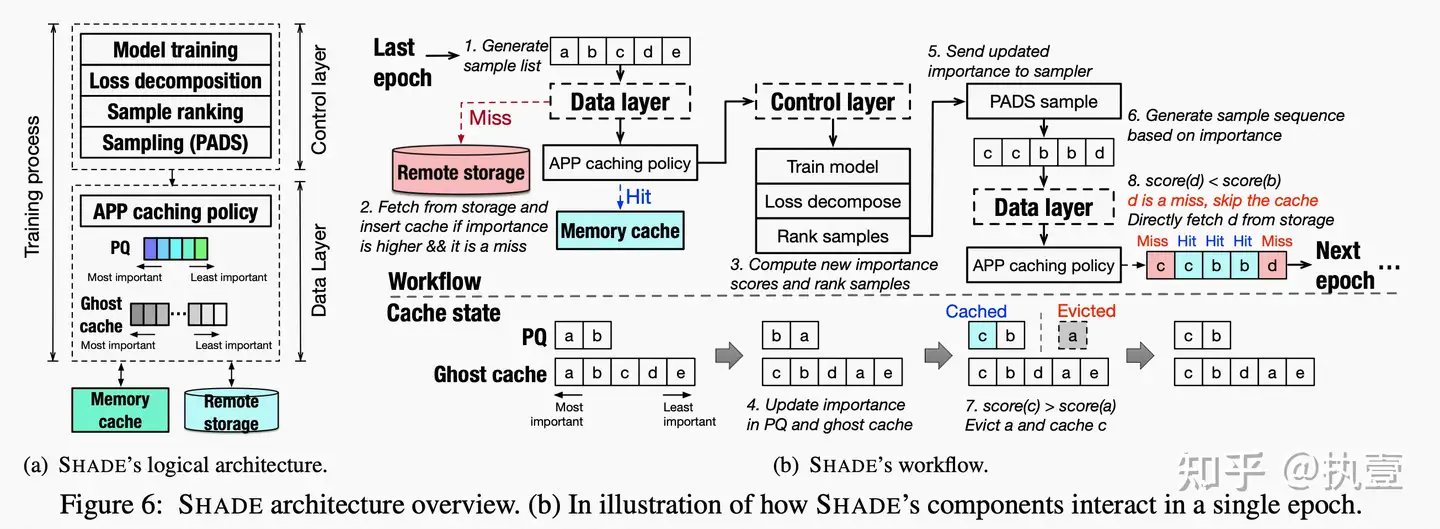
SHADE是由两个部分组成的:控制层和数据层,控制层向数据层提供训练所需要的数据。在第一次迭代中,数据层数据层从远程存储中获取样本,并用要访问的样本填充缓存。在训练过程中,控制层找到与样本相关的重要性(loss分解+排序),并更新优先队列(PQ)和跟踪数据层中样本重要性的ghost缓存。基于更新的重要性,控制层的采样器准备了一个带有相关重复信息的采样列表。当数据层接收到采样列表时,它会检查是否有利于缓存一个新的item,而不是驱逐先前缓存的样本。假设正在访问的样本比min_sample(当前缓存中重要性最低的样本)更重要。在这种情况下,min_sample被驱逐,并且当前样本使用新的自适应优先级感知预测(APP)缓存策略进行缓存。这个过程在整个DL训练过程中重复进行。由于SHADE将最重要的样本保留在分布式缓存中,并反复使用这些难以学习的样本进行训练,因此可以确保提高准确率和良好的缓存命中率。图6显示了SHADE的架构以及其中的组件和相互作用。下图就是SHADE的整体架构图。
最近AI非常火,相信大家都非常期待这次生成式AI可能带来的变化。作为关系型数据库的从业者,似乎和生成式AI离得比较远:D。但是作为关系型数据库中存储引擎的开发者,能很直观地理解,当这波AI浪潮来势汹汹,这么庞大的数据规模和终端用户群,对底层的数据存储一定是个巨大的挑战。如果底层存储成为瓶颈,那将进一步影响分布式训练系统的训练效率,毕竟对于这波AI大潮而言,分秒必争,时间就是金钱。所以,笔者一直非常好奇AI存储系统的I/O特征。趁着周末,找了找相关论文,发现今年FAST'23上有一篇介绍深度学习IO特征相关的论文:《Shade: Enable Fundamental Cacheability for Distributed Deep Learning Training》,遂展开读了读,本文仅仅做一个阅读笔记。作为AI系统的门外汉,笔者比较关注文章透传出来的系统I/O特征,所以笔记会有一定倾向性,对其它方面感兴趣的读者可以直接阅读全文。另外,笔者也发现了一系列与IO相关的论文,后面也将进一步阅读与总结。
文章一开始就阐明了深度学习训练(DLT)展现了比较独特的IO负载特征,这对存储系统的设计引入了一些新的挑战。一方面,DLT在训练过程中,需要不断从Remote Storage获取数据样本,具备I/O密集型的特征。另一方面,DLT广泛利用GPUs加速训练过程,所以同样具备计算密集型的特征。然而,指数级增长的样本数据集使得这些数据不可能完全存储在内存中,并且GPUs处理能力在持续提升,这导致滞后的I/O性能成为了整个分布式DLT系统中的性能瓶颈。笔者看到这里,会心一笑,想到David John Wheeler的那句名言:“计算机科学中的任何问题都可以通过加上一层间接层来解决”,所以在这个问题背景里一定是需要加cache了:D,我们往后看。
文章提到,尽管目前的DLT框架通常使用随机抽样策略来平等地处理所有样本,但最近的研究表明,不是所有样本都同等重要,不同的数据样本对提高模型精度的贡献是不同的。因此,我们很容易能推断到,可以通过利用那些贡献更高的数据样本的局部性,来优化整个DLT系统里的I/O情况。因此,文章作者们设计和实现了SHADE,这是一种新的DLT感知型的缓存系统。SHADE通过细粒度的样本级的动态重要性检测机制,并通过一种新的Rank方式捕捉不同批次里数据样本的重要性,这为DLT jobs提供了更精确的缓存策略。文章的测试结果表明,计算机视觉(CV)模型的评估显示,即使在更小的缓存情况下,相比于LRU的策略,SHADE将缓存命中率最高提到了4.5倍。
文章概述
为了分析存储系统对分布式深度学习训练效率的影响,文章做了一个实验,研究当分布式深度学习Job使用本地 vs. 远程存储介质运行时的性能差异。Figure 1显示,即使所有其它训练配置保持相同,相比于更快的存储介质(例如RAM,本地内存),远程存储介质也会显著加大训练时间(大约2.5倍)。更为夸张的,研究表明I/O甚至占据了总训练时间的85-90%。另外,文章也论证了,在日愈膨胀的数据集和抢占式的VM恢复方面,大型数据集必须放在持久化云存储中,而不是本地内存或者本地盘上,这一点比较好理解。因此,如果能有效降低I/O的延迟,就可以显著提升GPU的训练效率。阅读到这里,相信大家很快能get到文章要解决的问题,那直观的解决方案就是缓存来降低I/O延迟。进一步的,缓存的核心原理是挖掘locality,常见的要么是spatial locality,要么是time locality。那么,很自然就会联想到,分布式DLT的访存特征是什么样的?可挖掘的locality是什么?
但是,相比于传统的数据密集型应用(比如我们熟知的大数据分析或者web应用),DL训练过程具备不一样的I/O特征。DL training jobs通常运行多个epoch,每个epoch随机顺序访问整个训练数据集,并且每个epoch进一步分割为多个batch。在开始处理一个batch时,每个GPU进程会随机加载一个大小可配置的、随机采样的bulk(例如mini-batch)。总结一下,对于分布式DLT而言,提高I/O效率仍然是一项具有挑战性的任务,因为它的工作负载呈现出较为独特的特征:(1) 按照每个对象粒度的只读顺序访问;(2) 占大多数的是大量随机的小I/O,并且这部分I/O分散在整个训练样本数据集中;(3) 高并发大压力的I/O。I/O呈现出来的随机性、数据局部性不足和大压力,这导致传统的缓存机制难以发挥出价值,不论是LRU、LFU还是ARC等广泛使用的缓存策略。
因此,作者尝试通过挖掘DL的训练方式,定位其I/O特征。众所周知,深度神经网络(DNN)模型由多个计算单元层组成,其输出是后续单元的输入。DNN模型训练采用前向传播方法,依次将与输入数据相关的信息通过所有模型层传递,并生成预测。为了生成预测,DL定义了一个与前向传播输出和真实标签相关的coss/loss函数,并在训练过程通过增加或减小模型中间层输出的权重来最小化cost函数,从而提高预测率。这一步骤称为反向传播,它通过梯度下降优化技术,从最外层到输入层调整DL模型的参数。SGD是梯度下降优化的随机近似方式:它随机选择训练数据子集来降低计算成本,而不是从整个数据集计算梯度。在典型的基于SGD的data-parallel训练过程中,整个训练数据集通过切分,从而由多个GPU设备并行处理。每个GPU具备相同的DNN模型副本,并通过集中式通信方式(例如参数服务器)或者去中心化的通信方式(例如all-reduce)进行迭代同步。
传统上,基于SGD的深度学习训练对于训练样本的“重要性”毫不关注,因为它们只是在每个训练周期结束时随机排列顺序,从而平等对待所有的训练样本。然而,文章提到在最近的一些研究中,研究人员发现,在基于SGD的深度学习训练中,一组特定的训练样本往往对模型质量产生很小或没有影响,因此可以忽略它们。另一方面,通过找到比其它样本更重要的训练样本集合,即对损失函数最大贡献的样本集合(这个过程被称为重要性采样),这些样本在几个epochs后会导致在反向传播中的隐藏层输出和目标标签之间出现更大的loss。因此,通过优先使用相对更重要的训练样本来训练,可以明显降低整个训练系统的训练时间和减少测试错误。
作者在FAST'23的演讲PPT,更能清楚地说明这个特征。例如下图是识别字母的训练任务,在整个训练过程中,更难学习的样本反而是更加重要的。比如左边三个字母“c e t”非常清晰,很快就能被神经网络所识别。然而右边两个字母“e t”却非常模糊潦草,相对来说需要更多轮的反馈和训练,所以显然更加重要。

进一步的,作者通过多个benchmark的分析(如下图所示),发现的确有一部分数据在一次epoch或者多次epoch中被访问的频率明显更高。因此,他们尝试从这种重要性差异的角度出发,设计更加有效的机制和策略,提高DL训练的可缓存性。文章将单个数据样本的inter-batch和intra-batch重要性相结合,以检测最重要的样本并将其放置在内存池化缓存中。此外,文章开发了一种新颖的基于排名的重要性技术,它基于样本对提高模型整体准确率的贡献对批次内的训练样本进行排名。基于排名的重要性进一步有助于增加在后续时期识别(预测)最重要样本的概率。利用这种技术,文章进一步设计了一种基于优先级的采样策略,确保在一个时期内多次访问重要样本以更多地训练难以学习的样本,以提高准确率提高率。因此,这种缓存解决方案将更重要的样本保留在缓存中,并避免随机淘汰,从而提高缓存命中率和训练吞吐量。
如上文所述,SHADE的目标就是利用重要性抽样来提高DLT的I/O工作负载的缓存效率。想达到这个目标,需要解决以下的三个问题:1. 简单的重要性采样策略分配了每个mini-batch的得分,但是这种方式过于粗糙,以至于并不准确。也就是说,所有mini-batch里的样本数据默认情况下被分配同样的重要性得分,从而使每个样本的重要性估计并不准确,影响了缓存效率。因此,SHADE希望能够精确评估每个样本数据在mini-batch中所具有的相对重要性;2. 即使正确识别了重要的样本,过度地向DL模型提供重复的样本可能会使模型训练出现偏差。因此在尝试增加样本击中率的同时,必须确保不会影响模型的准确性;3. 重要性得分在动态发生变化,可能很快就会过时。在后续mini-batch中,同一个样本对模型的贡献可能与之前的mini-batch是不同的。因此,获取最新的重要性得分信息是必要的,以做出明智的缓存决策。简单来说,SHADE需要设计细粒度的动态重要性追踪机制,并且不能影响模型的准确性。
SHADE是由两个部分组成的:控制层和数据层,控制层向数据层提供训练所需要的数据。在第一次迭代中,数据层数据层从远程存储中获取样本,并用要访问的样本填充缓存。在训练过程中,控制层找到与样本相关的重要性(loss分解+排序),并更新优先队列(PQ)和跟踪数据层中样本重要性的ghost缓存。基于更新的重要性,控制层的采样器准备了一个带有相关重复信息的采样列表。当数据层接收到采样列表时,它会检查是否有利于缓存一个新的item,而不是驱逐先前缓存的样本。假设正在访问的样本比min_sample(当前缓存中重要性最低的样本)更重要。在这种情况下,min_sample被驱逐,并且当前样本使用新的自适应优先级感知预测(APP)缓存策略进行缓存。这个过程在整个DL训练过程中重复进行。由于SHADE将最重要的样本保留在分布式缓存中,并反复使用这些难以学习的样本进行训练,因此可以确保提高准确率和良好的缓存命中率。图6显示了SHADE的架构以及其中的组件和相互作用。下图就是SHADE的整体架构图。