




利用 DG 单机转RAC - 迁移实操篇
客户需求: 将数据库从单机转为RAC环境,数据库版本11.2.0.4 不变。
方案设计: 数据量较大,为了缩短停机时间,我们利用DG Switchover 功能,将数据库切换为RAC环境。
架构图:
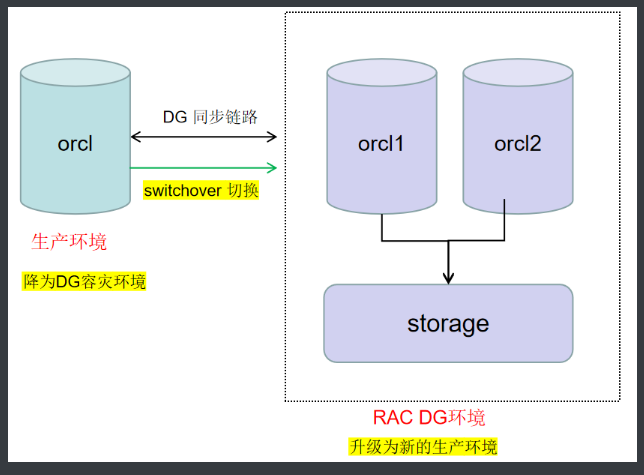
大致实施步骤:
- 搭建DG,从单机生产环境,到RAC 新环境。
- 通过Switchover 切换,将数据库从单机环境切换为RAC环境。
- 注意: 此时数据库仍然是一个单机数据库,需要执行单机转RAC升级脚本。
下面我们看一下具体切换步骤: 部分执行过程篇幅太长、涉及客户信息,省略。。。
1. 切换前检查
1.1 停止Ap server
-- 检查当前数据库是否还有session连接
set line222
col username for a10
col module for a40
select inst_id,username,sid,serial#,module from gv$session where username is not null;
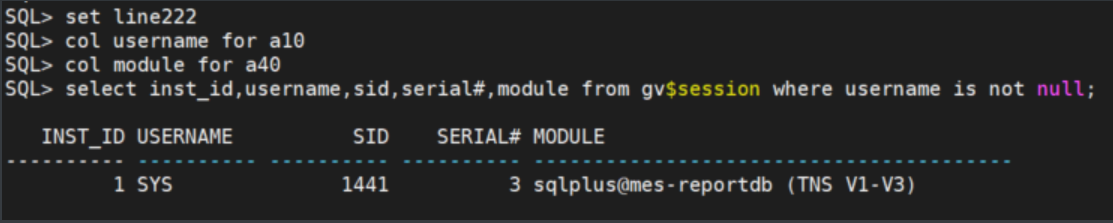
结论:当前数据库无任何连接。
- 如果遇到客户没法停止AP server的话,可以停主库监听,重启DB,或者kill session方式来断开应用连接。
-- 停止listener,重启DB
[oracle@mes-reportdb ~]$ lsnrctl stop
SQL> shutdown immediate
SQL> startup
1.2 主、备库停止job
- 保证数据静止,避免job自动运行,修改数据。
-- 主库:
show parameter job_queue_processes
alter system set job_queue_processes = 0;
select * from dba_jobs_running;
-- 备库:
show parameter job_queue_processes
alter system set job_queue_processes = 0;
select * from dba_jobs_running;
1.3 查看主库、备库日志是否一致
select max(sequence#) from v$archived_log;
主库:

备库:
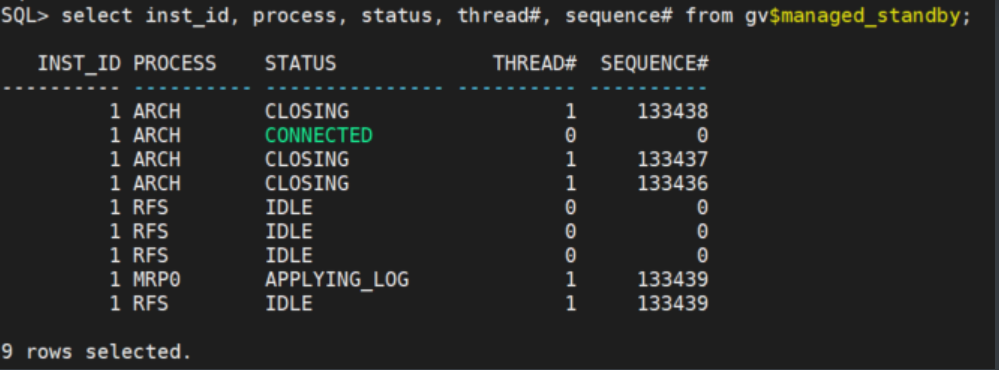
1.4 查看备库同步进程状态
set line222
col PROCESS for a10
col STATUS for a15
select inst_id, process, status, thread#, sequence# from gv$managed_standby;
1.5 检查主备库DG相关参数
- 检查备库是否也配置了log_archive_dest_2等参数。
set line 1000
set pagesize 1000
col name format a25
col VALUE format a100
SELECT a.NAME, a.VALUE FROM v$parameter a WHERE a.name in ('db_name','db_unique_name','log_archive_config','log_archive_dest_1','log_archive_dest_2','log_archive_dest_state_1','log_archive_dest_state_2','remote_login_passwordfile','db_file_name_convert','log_file_name_convert','standby_file_management','fal_server','fal_client');
1.6 主库手动切换日志,检查备库同步情况
主库:
-- 多切几次
alter system archive log current;
alter system checkpoint;
观察备库 alert日志: DG 同步正常。
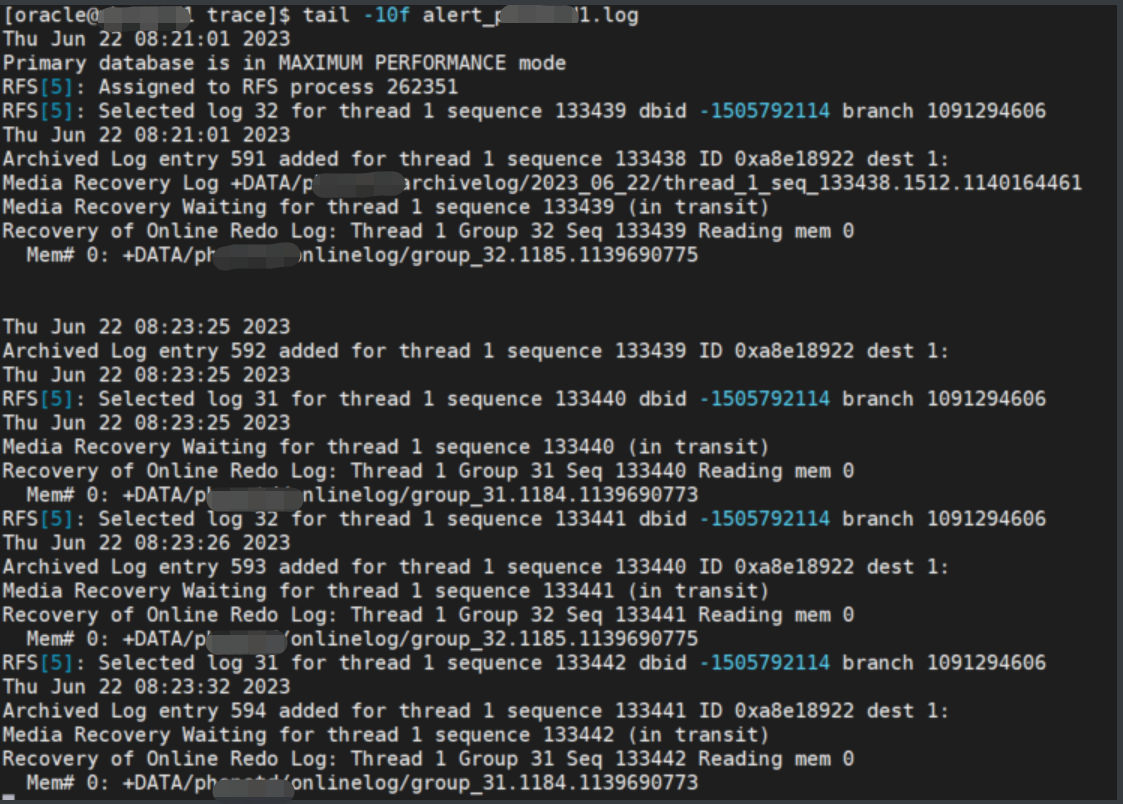
1.7 检查主备库standby logfile
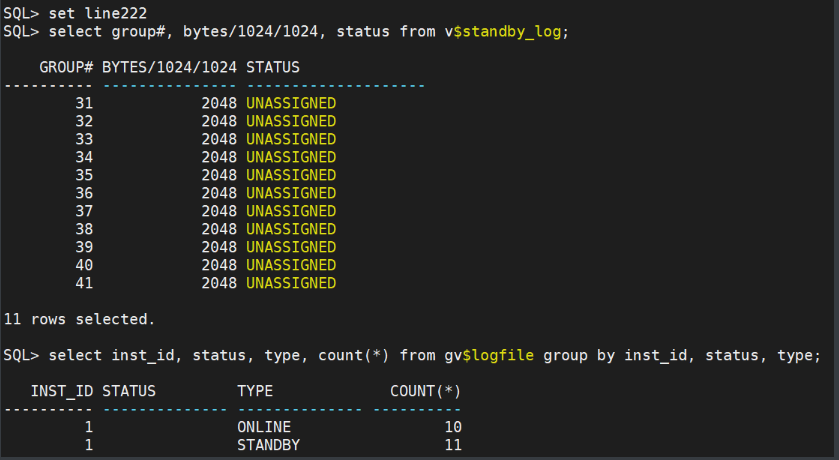
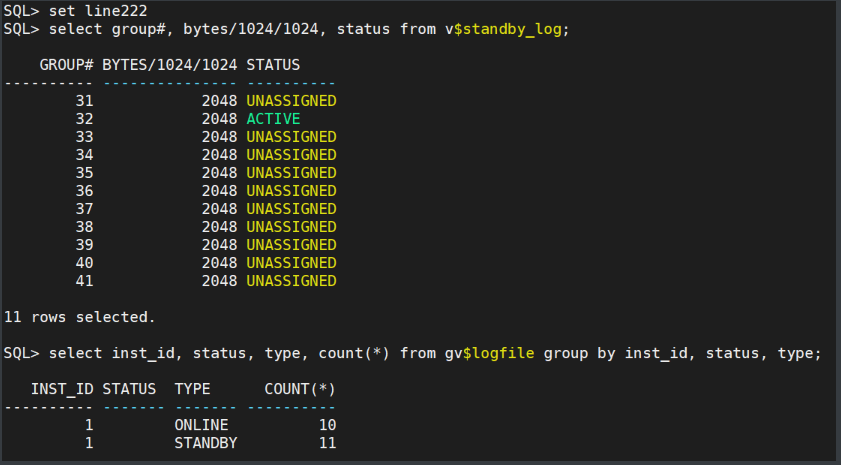
set line222
select group#, bytes/1024/1024, status from v$standby_log;
select inst_id, status, type, count(*) from gv$logfile group by inst_id, status, type;
主库:
备库:
2. 主备正式切换
2.1 主库下检查是否可以切换
set line222
col database_role for a20
col switchover_status for a20
col PROTECTION_MODE for a25
select name,database_role,protection_mode,switchover_status from v$database;
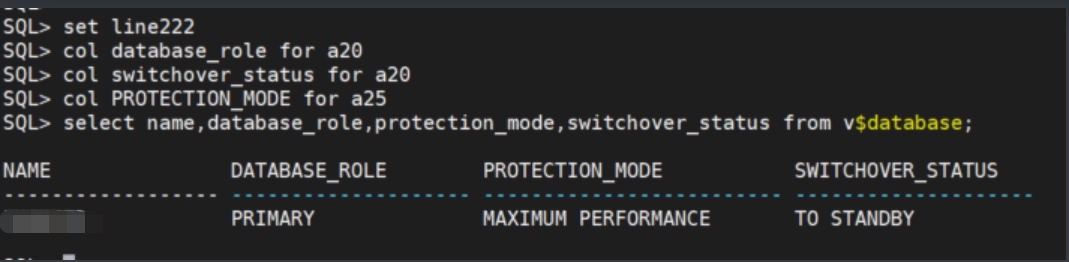
结论:switchover_status 为to standby,说明当前主库可以切换为standby备库。如果状态是session active ,说明当前主库仍然有活动会话,需要kill session 后再切换。
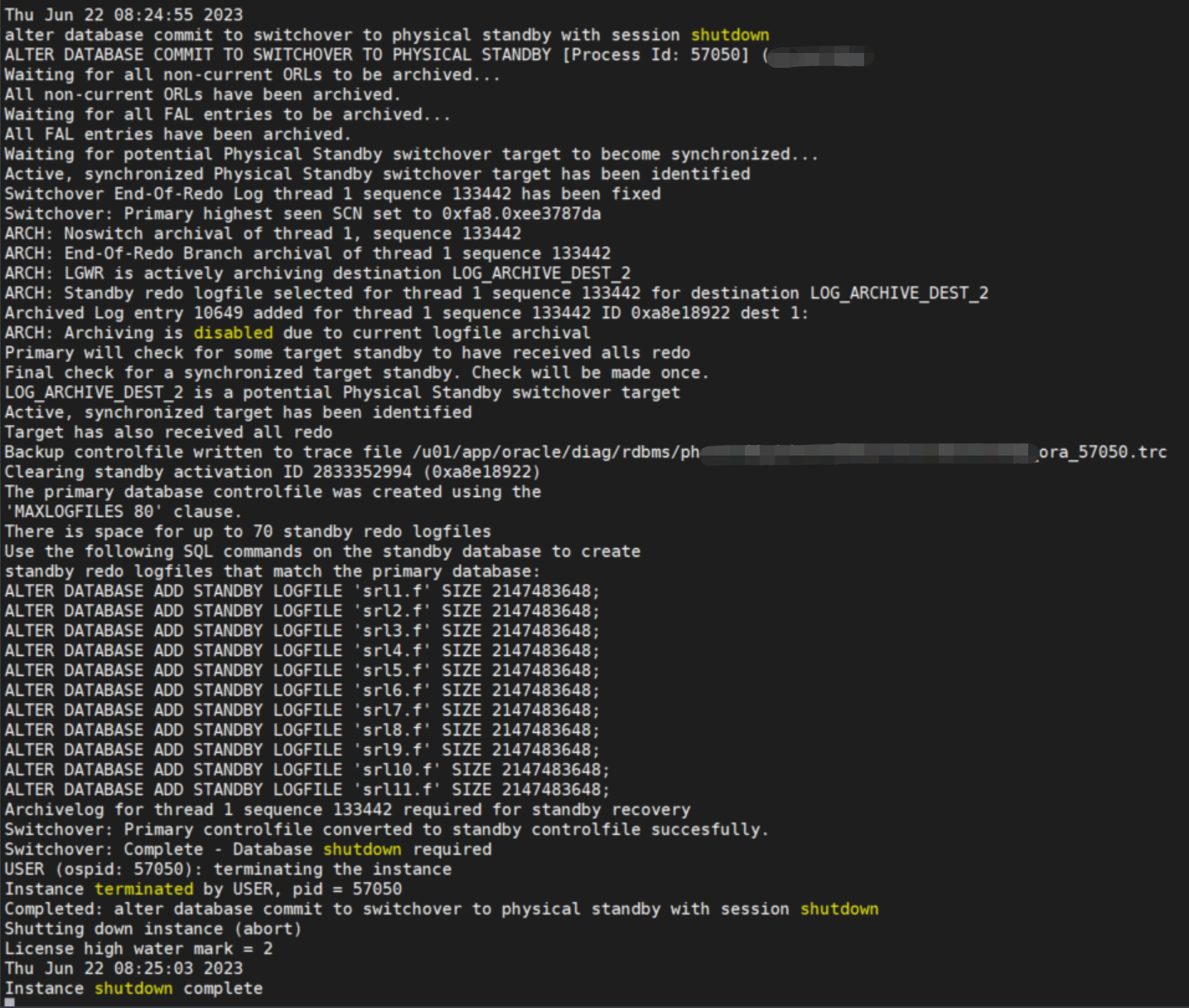
2.2 主库切换为备库 (期间观察主库alert日志)
alter database commit to switchover to physical standby with session shutdown;

期间观察主库 alert日志:
2.3 备库下检查是否可以切换
set line222
col database_role for a20
col switchover_status for a20
col PROTECTION_MODE for a25
select name,database_role,protection_mode,switchover_status from v$database;
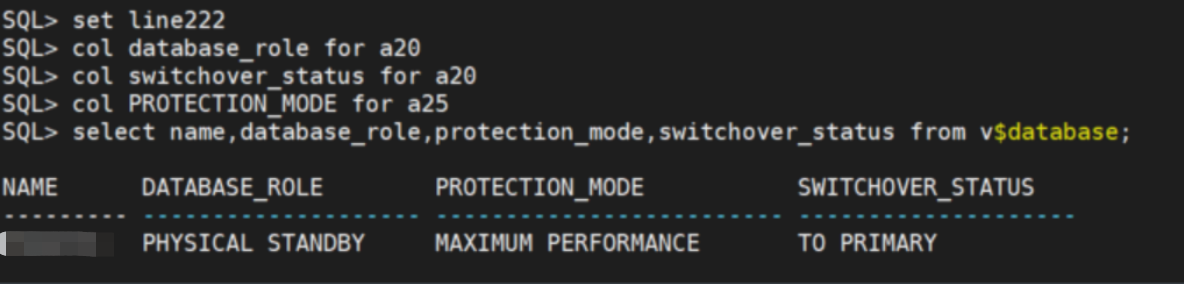
结论:switchover_status 为to primary,说明当前备库可以切换为primary住库。
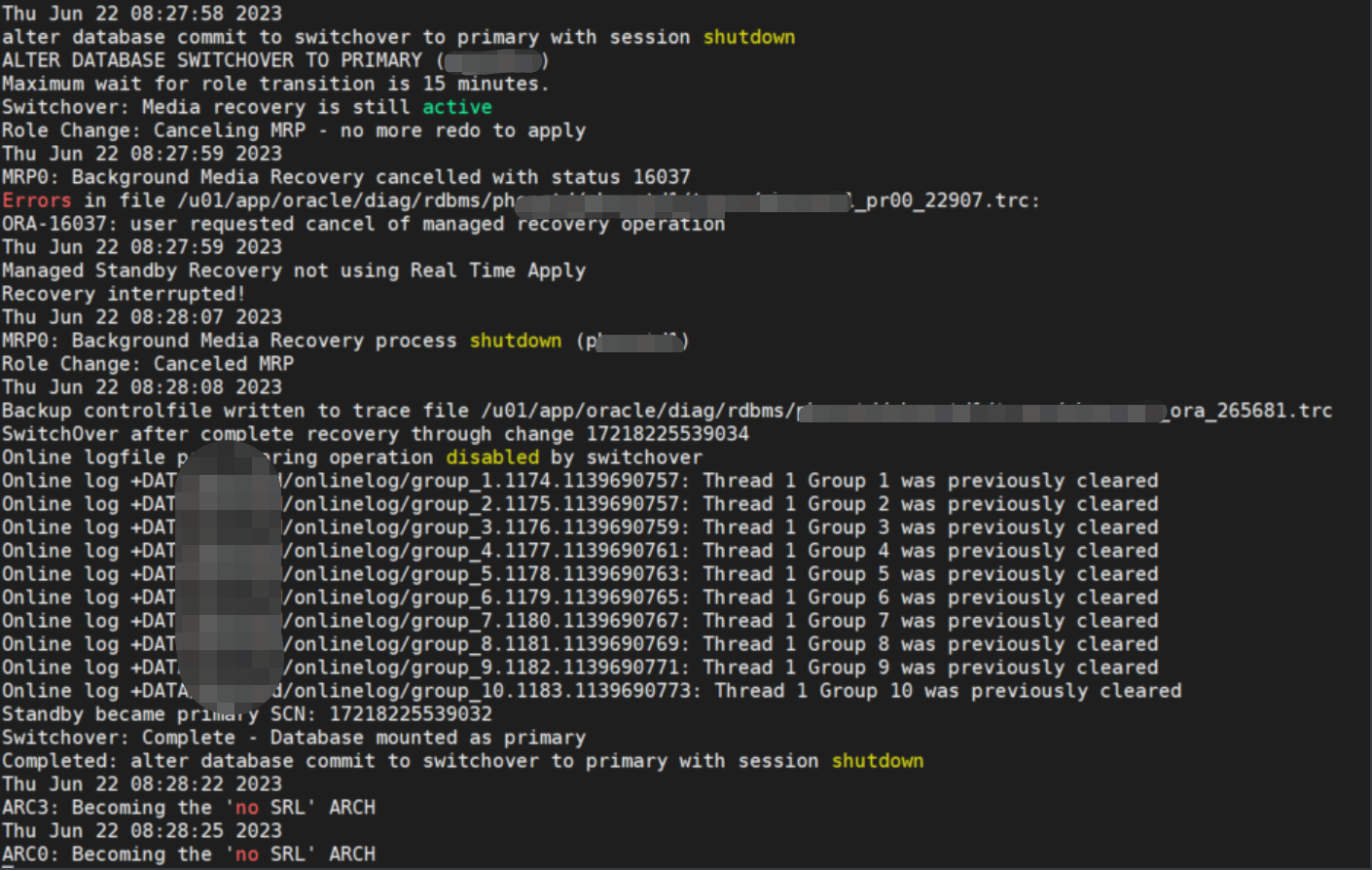
2.4 备库切换主库 (期间观察备库alert日志)
alter database commit to switchover to primary with session shutdown;

期间观察备库 alert日志:
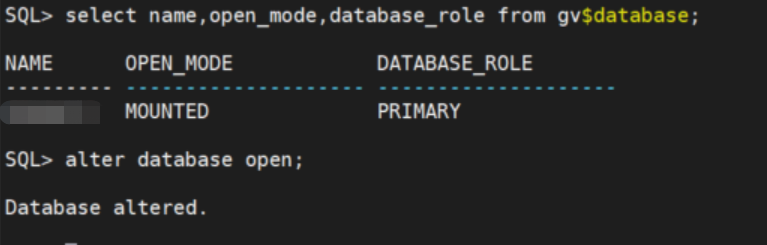
2.5 打开新的主库
select name,open_mode,database_role from gv$database;
alter database open;
2.6 重启新的备库
startup mount
set line222
select inst_id,name,database_role,open_mode from gv$database;
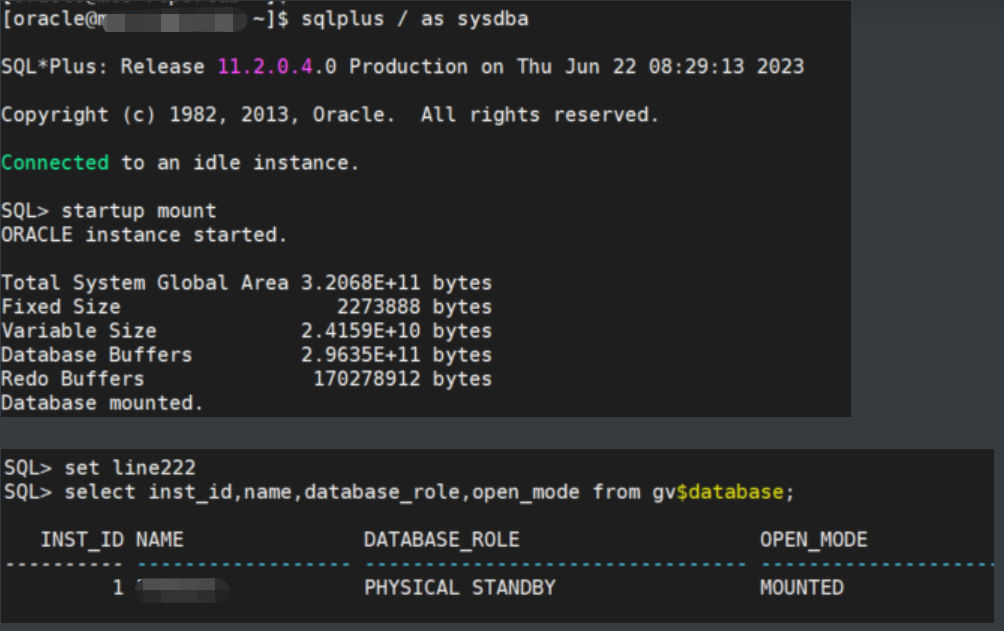
2.7 新的备库启动mrp进程
alter database recover managed standby database using current logfile disconnect;

3. 切换后同步检查
3.1 查看新的备库同步进程状态
set line222
col PROCESS for a10
col STATUS for a15
select inst_id, process, status, thread#, sequence# from gv$managed_standby;
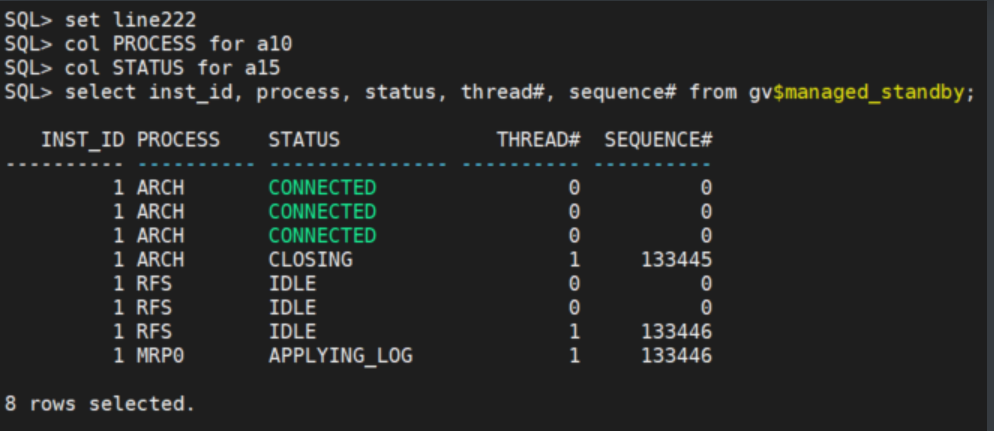
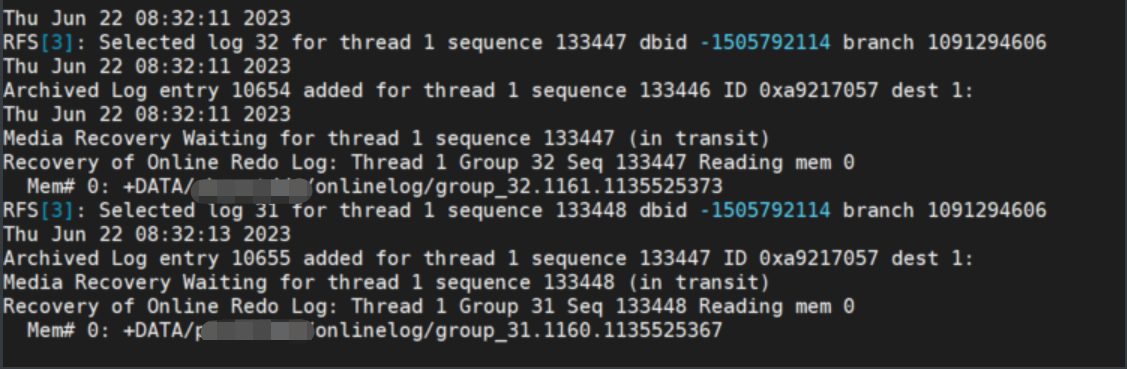
3.2 新的主库手动切换日志,检查备库同步情况
主库
alter system archive log current;
观察备库alert日志: DG同步正常。
4. 执行转RAC脚本
- 注意: 此时switchover操作已完成,RAC环境已经变为primary角色,正式环境,但是数据库仍然是一个单机数据库,需要执行单机转RAC升级脚本。
4.1 执行将单机转换成rac的脚本
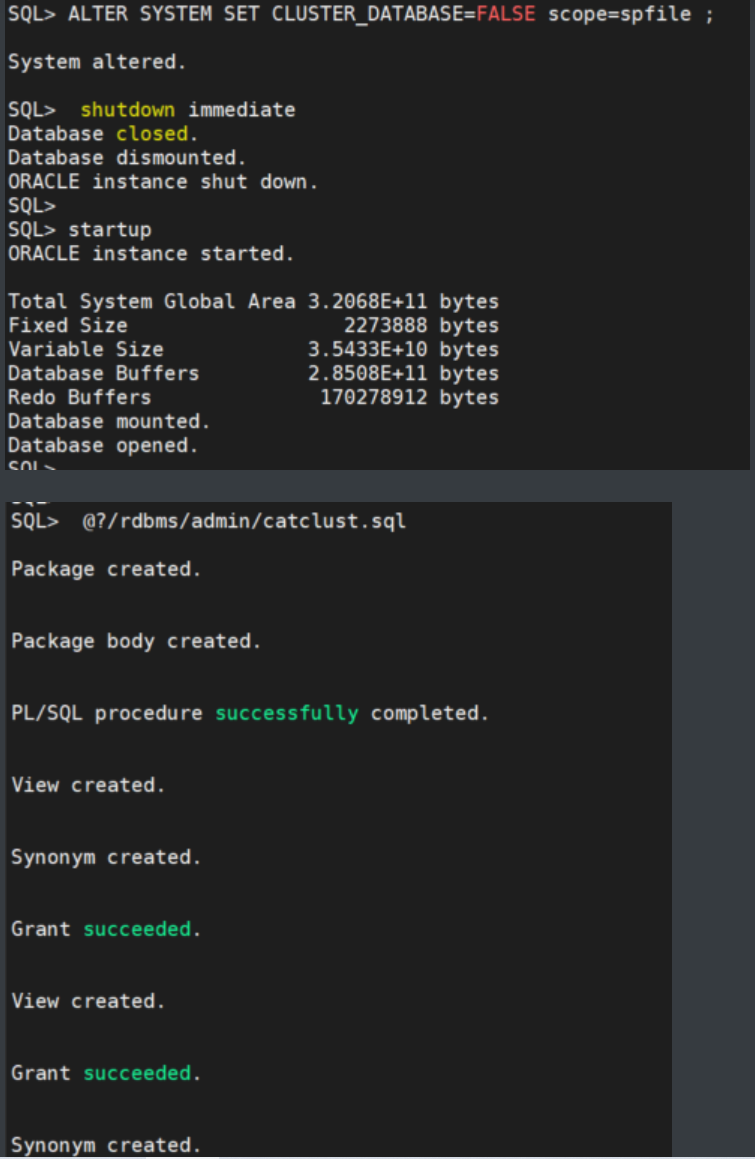
--先将CLUSTER_DATABASE参数改为flase
SQL> ALTER SYSTEM SET CLUSTER_DATABASE=FALSE scope=spfile ;
SQL> shutdown immediate
SQL> startup
--重建集群相关的视图
SQL> @?/rdbms/admin/catclust.sql
--建议(非必须)
@?/rdbms/admin/catalog.sql
@?/rdbms/admin/catproc.sql
@?/rdbms/admin/utlrp.sql
略。。。。
4.2 添加thread2日志组
alter database add logfile thread 2 group 50('+DATA') size 2048M;
alter database add logfile thread 2 group 51('+DATA') size 2048M;
alter database add logfile thread 2 group 52('+DATA') size 2048M;
alter database add logfile thread 2 group 53('+DATA') size 2048M;
alter database add logfile thread 2 group 54('+DATA') size 2048M;
alter database add logfile thread 2 group 55('+DATA') size 2048M;
alter database add logfile thread 2 group 56('+DATA') size 2048M;
alter database add logfile thread 2 group 57('+DATA') size 2048M;
alter database add logfile thread 2 group 58('+DATA') size 2048M;
alter database add logfile thread 2 group 59('+DATA') size 2048M;
set line222
col member for a50
select trim(a.thread#) thread#,trim(a.group#) group#,b.member member,a.status status,a.bytes/1024/1024 "size(M)" from v$log a,v$logfile b where a.group#=b.group# order by 1,2;

4.3 修改RAC相关参数
alter system set thread=1 scope=spfile sid='orcl1';
alter system set thread=2 scope=spfile sid='orcl2';
alter system set instance_number=1 scope=spfile sid='orcl1';
alter system set instance_number=2 scope=spfile sid='orcl2';
alter system set cluster_database=true scope=spfile;
4.4 添加节点2 undo tablespace
create undo tablespace undotbs2 datafile '+DATA' SIZE 30G autoextend on;
alter tablespace undotbs2 add datafile '+DATA' SIZE 30G autoextend on;
alter system set undo_tablespace='undotbs1' scope=spfile sid='orcl1';
alter system set undo_tablespace='undotbs2' scope=spfile sid='orcl2';
4.5 查看当前节点状态
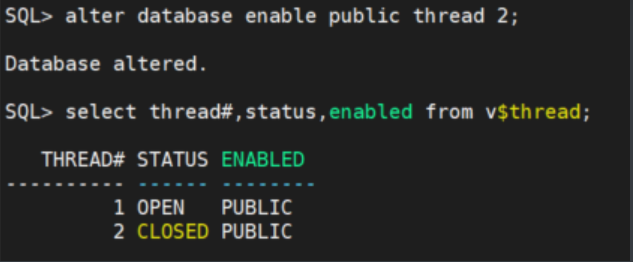
SQL> select thread#,status,enabled from v$thread;
THREAD# STATUS ENABLED
---------- ------ --------
1 OPEN PUBLIC
2 CLOSED DISABLED
4.6 启动其他节点
alter database enable public thread 2;
select thread#,status,enabled from v$thread;
4.7 使用集群命令重启数据库
srvctl add database -d orcl -o /u01/app/oracle/product/11.2.0/db_1 -p +DATA/orcl/spfileorcl.ora
srvctl add instance -d orcl -i orcl1 -n orcl1
srvctl add instance -d orcl -i orcl2 -n orcl2
srvctl stop database -d orcl
srvctl start database -d orcl
srvctl status database -d orcl
5. 再次检查DG同步情况
5.1 新的备库,增加节点2 standby logfile
alter database recover managed standby database cancel;
alter database add standby logfile thread 2 group 60('+DATA') size 2048M;
alter database add standby logfile thread 2 group 61('+DATA') size 2048M;
alter database add standby logfile thread 2 group 62('+DATA') size 2048M;
alter database add standby logfile thread 2 group 63('+DATA') size 2048M;
alter database add standby logfile thread 2 group 64('+DATA') size 2048M;
alter database add standby logfile thread 2 group 65('+DATA') size 2048M;
alter database add standby logfile thread 2 group 66('+DATA') size 2048M;
alter database add standby logfile thread 2 group 67('+DATA') size 2048M;
alter database add standby logfile thread 2 group 68('+DATA') size 2048M;
alter database add standby logfile thread 2 group 69('+DATA') size 2048M;
alter database add standby logfile thread 2 group 70('+DATA') size 2048M;
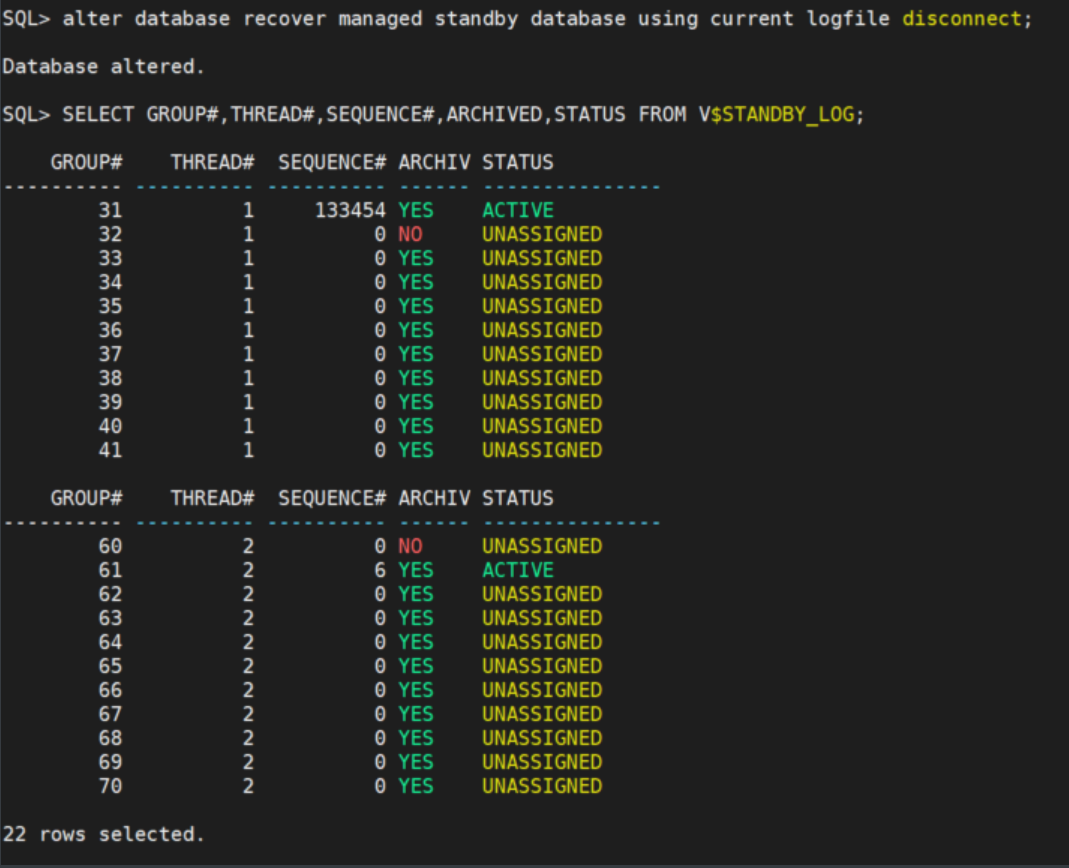
alter database recover managed standby database using current logfile disconnect;
SELECT GROUP#,THREAD#,SEQUENCE#,ARCHIVED,STATUS FROM V$STANDBY_LOG;
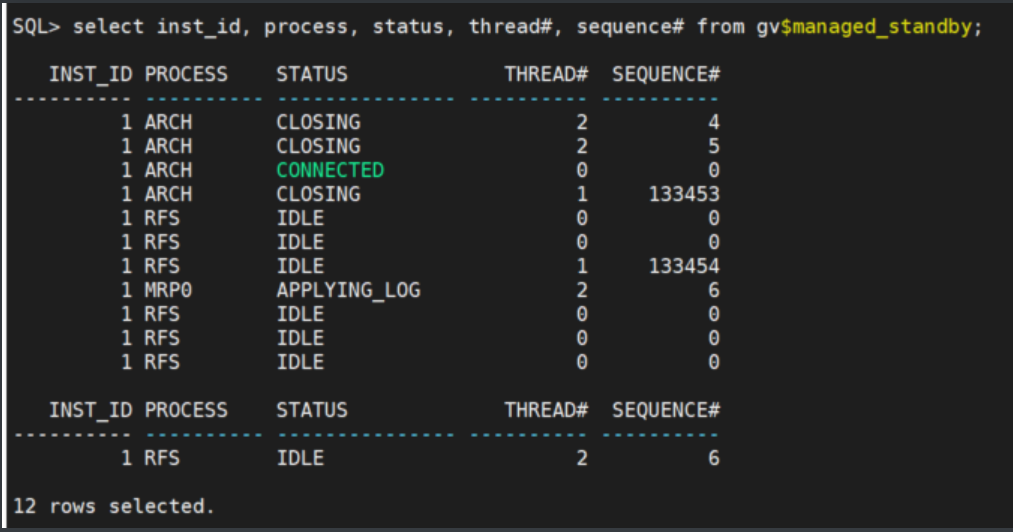
5.2 查看新的备库同步进程状态
select inst_id, process, status, thread#, sequence# from gv$managed_standby;
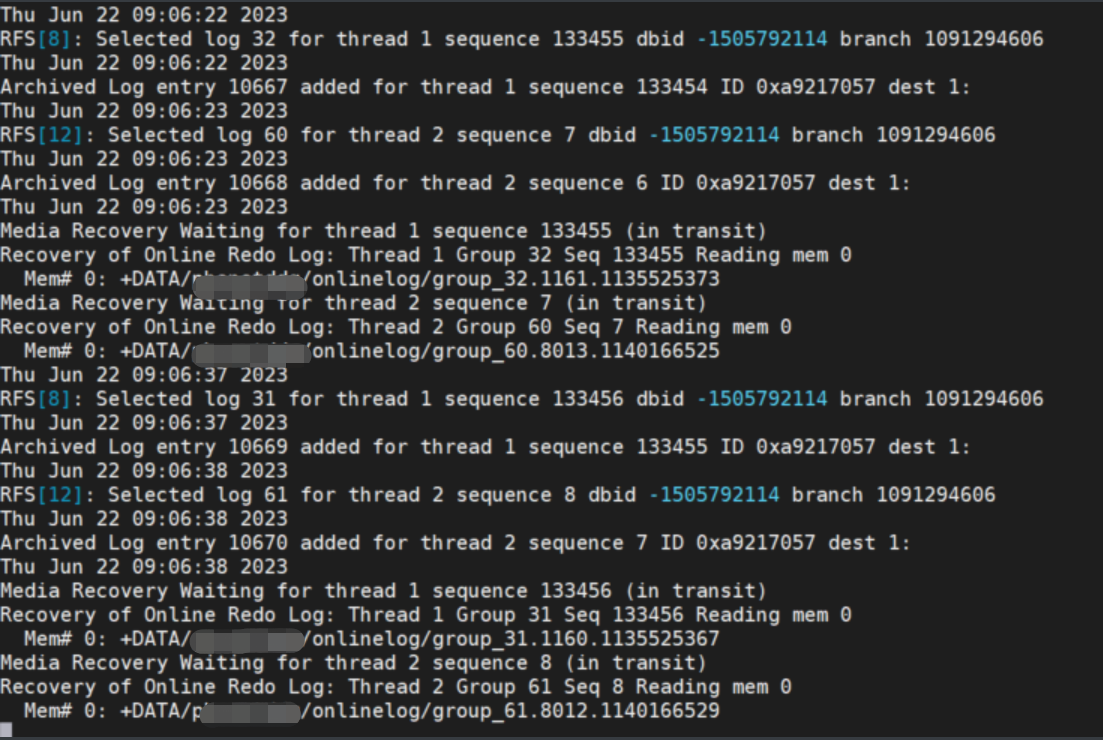
5.3 新的主库手动切换日志,检查备库同步情况
主库:
alter system archive log current;
观察备库alert日志: DG 同步正常。
6. 新的主备库参数调整
6.1 修改新的主库 service name
-- 按需调整
alter system set service_names='ORCL' scope=both;
show parameter service_names
应用程序使用新的tns:
ORCL = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = orcl-scan)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL) ) )
6.2 启动job
--新主库:
alter system set job_queue_processes=1000;
show parameter job_queue_processes
--新备库:
alter system set job_queue_processes=1000;
show parameter job_queue_processes
6.4 检查temp 表空间
select file_name from dba_temp_files;
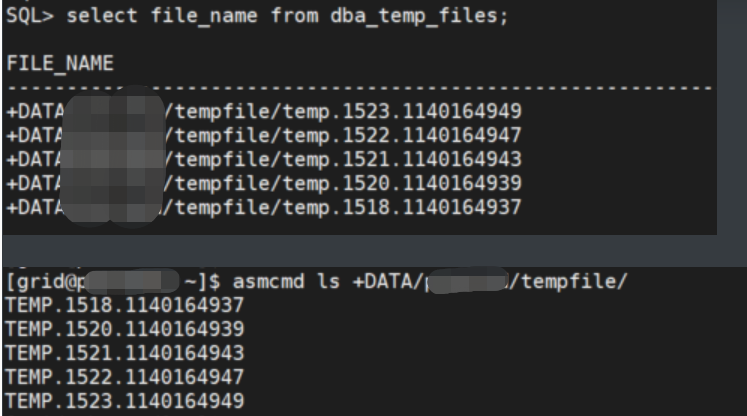
结论:switchover切换后,tempfile都recreate成功,无需重建temp表空间。
6.5 对比参数文件
- 检查新的主库是否有其他需要修改的参数。
略。。。。
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
