




PTRC的核心思想是缓存查询语句中算子的中间结果集来避免某些算子的重复执行,可以被PTRC加速的算子需要满足如下条件:
- 算子执行时依赖相关性参数(Correlated Parameters),并且会被反复执行多次。如NestLoopJoin和相关子查询;
- 算子的相关性参数保持不变,无论执行多少次,算子执行的结果是固定的。比如算子中不能有影响算子重复执行结果的函数Random、NOW和UDF等,否则缓存中的数据会影响最终结果的正确性。
算子执行时依赖的相关性参数(Correlated Parameters),即算子执行时所依赖的外部参数。例如t1 join t2 on t1.a = t2.a,t1表作为驱动表,t1表的每一行都要和t2表完成一次join操作,而 t1.a 则被认为是该NestLoopJoin算子执行时依赖的相关性参数。如果t1.a在t1表中存在较多的重复值,那PTRC将会减少这部分的重复计算。再比如Correlated subquery算子,每执行一次子查询,都依赖于父查询的一次扫描结果作为驱动参数。
此处以TPCH-Q17为例来说明PTRC的基本工作原理。查询语句示例如下:
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#34'
and p_container = 'MED BOX'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);
PTRC以算子的相关性参数作为key,算子的执行结果作为value存储在缓存中。故TPCH-Q17中PTRC的缓存存储格式为:key= p_partkey, value = [true/false] 。
TPCH-Q17中相关子查询的PTRC的主要执行流程如下图所示:
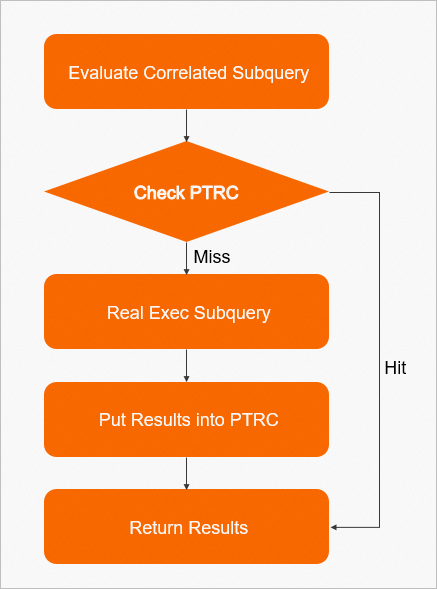
每次对相关子查询求值时,根据p_partkey的值在PTRC的缓存中查找结果:
- 如果未命中,则需要执行子查询进行求值,并将求值结果记录到PTRC的缓存中;
- 如果命中缓存中的结果,则直接将结果返回,从而避免重复执行一次子查询。
因为TPCH-Q17是part表join lineitem表后再执行子查询,join之后的结果中p_partkey重复项非常多,而p_partkey又是子查询的相关性参数,所以TPCH-Q17的PTRC命中率会很高,性能提升会非常显著。
使用EXPLAIN命令可以查看执行计划,在子查询执行前添加了一个Partial Result Cache算子,则说明该子查询中引入了PTRC,如下图所示:

「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
