




2.1谓词ANY(SOME)
2.2谓词ALL
2.3谓词EXISTS
一.引言
在SQL中,有三个十分重要的谓词:ANY(SOME)、ALL、EXISTS。三个谓词之间存在什么区别,如何使用,是一个值得我们关注的问题。
GROUP BY是一个我们经常用到的一个SQL子句,其作用相当于Excel中的数据透视表。但是,与Excel中的数据透视表相比,SQL中的GROUP BY子句有个明显的缺陷,那就是无法得到合计结果,同时SQL中的结果是以一维表的形式展示的,这种展示不是很直观。我们如何才能改进GROUP BY的这些缺陷呢?
因此,此文的内容如下:
ANY(SOME)、ALL、EXISTS三个谓词的含义与使用技巧 GROUPING 运算符(如何实现Excel透视表的汇总功能) PIVOT(如何让结果以二维表的形式呈现)
二.三个谓词的使用方法
2.1谓词ANY(SOME)
ANY和SOME关键字是同义词,表示满足其中任一条件。它们允许创建一个表达式对子查询的返回值列表进行比较,只要满足内层子查询的任一一个比较条件,就返回一个结果作为外层查询的条件。
简单一点来说,这一个谓词的作用和聚合函数min一致!
举个例子说明一下。
-- 创建两张表
create table tb1(num1 int not null);
create table tb2(num2 int not null);
-- 插入数据
insert into tb1 values(1),(5),(13),(27);
insert into tb2 values(6),(14),(11),(20);
-- 返回tb2表的所有num2列,然后将tb1中的num1的值与之比较,只要num1大于num2的值就为符合查询条件的结果
-- 实现方法1
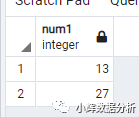
select num1 from tb1 where num1>any(select num2 from tb2);
-- 实现方法2
select num1 from tb1 where num1>(select min(num2) from tb2);
2.2谓词ALL
ALL关键字与ANY和SOME不同,使用ALL时需要同时满足所有内层查询的条件。
以前面的数据集为例,我们举个例子来说明一下。
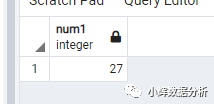
-- 返回tb1表中比tb2表中num2列所有值都大的值
-- 方法1
select num1 from tb1 where num1>all(select num2 from tb2);
-- 方法2
select num1 from tb1 where num1>(select max(num2) from tb2);
简单总结一下:
谓词any相当于min 谓词all相当于max
2.3谓词EXISTS
EXISTS关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,那么EXISTS的结果为True,此时外层查询语句将进行查询;如果子查询没有返回任何行,那么EXISTS返回的结果是FALSE,此时外层语句将不再进行查询。
这么说,显得比较抽象,我们举例说明一下。
我们查询所用的表是我们在SQL练习题中,所用的那四张表:学生表,课程表,教师表与成绩表。
需求1:查找是否有姓李的学生,如果存在姓李的学生,显示其相关信息
select * from Student as t1
where exists (select * from Student as t2 where t2.sname like '李%' and t1.sname like '李%');
结果如下:

注意,这代代码不能写成如下的形式:
select * from Student as t1
where exists (select * from Student as t2 where sname like '李%');
这样写,虽然不会报错,但是返回的结果是错误的!
也就是说在PostgreSQL中使用EXISTS语句,必须要使用关联子查询的方式来实现。
现在,我们来讲第二个需求:
需求2:查找姓黄的学生,如果存在则返回相应的生信息。
select * from Student s1
where exists
(select 1 from Student s2 where s1.sname like '黄%' and s2.sname like '黄%');
结果如下:

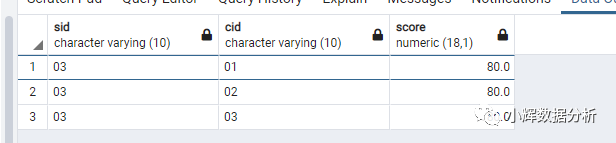
在本人公众号所发布的文章,文章《SQL练习题(9)》中的第七道题,就可以使用EXISTS语句来进行解答,其具体的写法是:
-- 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
select * from SC t1
where exists(select * from SC t2 where t1.cid!=t2.cid and t1.score=t2.score and t1.sid=t2.sid);
结果如下:
三.GROUPING运算符
Excel中拥有一个极其强大的功能:数据透视表。数据透视表的效果如下:
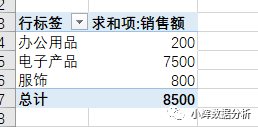
Excel的数据透视表与SQL相比,有一个最大的特点,那就是有一个汇总功能。这意味着我们不仅能查看每一个组成部分的情况,而且意味着我们查看总体的情况。SQL中默认的group by是没有整体汇总的功能的。那么,SQL中如何才能实现这一功能呢?
一种方法是使用UNION ALL子句,将两次查询的结果合并起来,具体如下:
-- 创建数据集
create table items(product_name varchar(10) not null,
product_type varchar(10) not null,
product_price int not null);
-- 插入数据
insert into items values('computer','ele_prod',7000);
insert into items values('earphone','ele_prod',500);
insert into items values('pants','clothing',400);
insert into items values('high-heels','clothing',300);
insert into items values('coat','clothing',100);
insert into items values('paper','office',200);
-- 实现
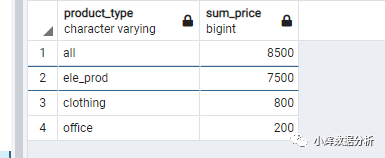
select 'all' as product_type,sum(product_price) as sum_price
from items
union all
select product_type,sum(product_price) as sum_price
from items
group by product_type
order by sum_price desc;
结果如下:
但是,这种操作方式是比较麻烦的。那么,我们有没有比较简单的方式呢?
在MySQL当中,这个需求可以使用rollup来实现,具体代码如下:
select product_type,sum(product_price) as sum_price
from items
group by product_type with rollup;
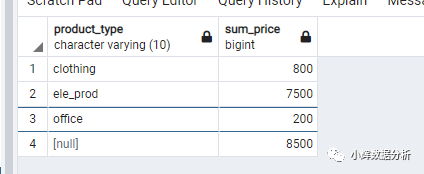
在其他的SQL数据库软件中,这一功能的实现方式则是:
select product_type,sum(product_price) as sum_price
from items
group by rollup(product_type);
效果如下:
其实,ROLLUP命令是标准SQL中GROUPING运算符中的一种。标准SQL总共支持三种GROUPING运算符,分别是:
ROLLUP CUBE GROUPING SETS
为了更好的讲解,我们建立一张新的表。
create table products(
product_id varchar(4) primary key,
product_name varchar(10) not null,
product_type varchar(10) not null,
sale_price int not null,
purchase_price int,
redis_date date);
insert into products values('0001','t-shirt','garment',1000,500,'2009-09-20');
insert into products values('0002','punch','office',500,320,'2009-09-11');
insert into products values('0003','sport-t','garment',4000,2800,null);
insert into products values('0004','knife','kitchen',3000,2800,'2009-09-20');
insert into products values('0005','pot','kitchen',6800,5000,'2009-01-15');
insert into products values('0006','fork','kitchen',500,null,'2009-09-20');
insert into products values('0007','board','kitchen',880,790,'2008-04-28');
insert into products values('0008','pen','office',100,null,'2009-11-11');
我们先来使用一下rollup语句:
-- 一个字段的名称有错误,我们先更改一下
alter table products rename redis_date to regis_date;
-- 按日期(年份)和种类进行汇总
select extract(year from regis_date) as year,product_type,sum(sale_price) as sum_price
from products
group by rollup(extract(year from regis_date),product_type);
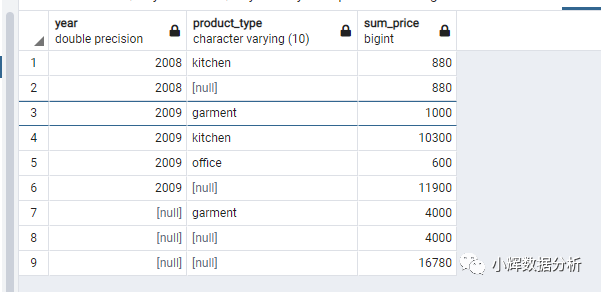
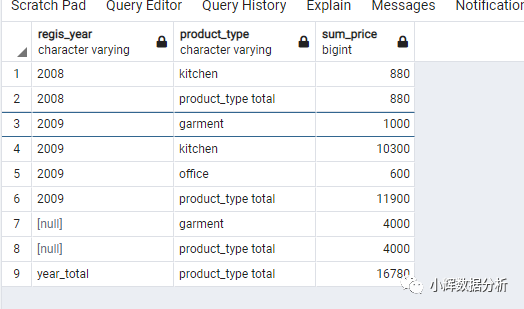
从结果中,我们可以发现如下信息:
2008年的销售额为880,只销售出厨房用具一个种类的产品,其价值为880元 2009年总共销售出11900元的商品。其中, 服装的销售额是1000 厨房用具的销售额为10300 办公用品的销售额为600 还有4000元的服装销售额,其销售年份是不确定的 总共的销售额是16780
ROLLUP语句,确实功能十分强大,但还是有一些不足的:例如查询结果中有两个4000,但这两个4000的含义是不同的。一个是说有4000元的服装销售额,其销售日期是不确定的;另外一个4000,则是汇总的结果。
为了解决这一个缺陷,我们可以使用GROUPING来解决。
select grouping(extract(year from regis_date)) as year,
grouping(product_type) as product_type,
sum(sale_price) as sum_price
from products
group by rollup(extract(year from regis_date),product_type);
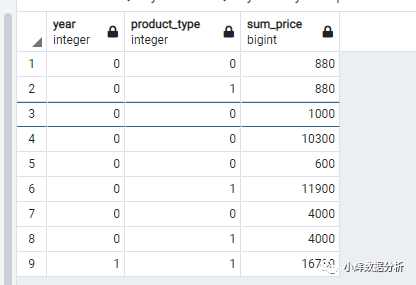
展示出来的结果,可能有点奇怪,我们来解释一下:
0表示数据表中实际的结果。例如第一个880表示某一年的某一类产品的销售额是880元。 1表示汇总的结果或者是原先的数据为null的结果。例如,第二个880表示某一年总的销售额是880元。
GROUPING的显示结果不够直观,不易理解,为了解决这个问题,我们可以使用CASE WHEN 语句。
select case when
grouping(extract(year from regis_date))=1 then 'year_total'
else cast(extract(year from regis_date) as varchar(10)) end as regis_year,
case when
grouping(product_type)=1 then 'product_type total'
else product_type end as product_type,
sum(sale_price) as sum_price
from products
group by rollup(extract(year from regis_date),product_type);
我们还可以进一步地改造:
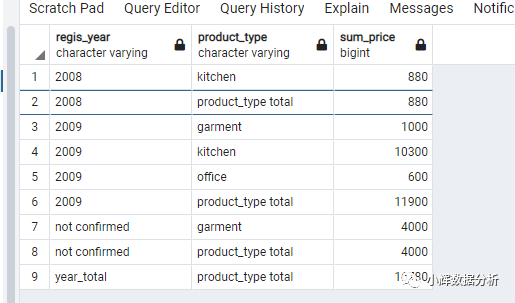
select coalesce(case when grouping(extract(year from regis_date))=1 then 'year_total'
else cast(extract(year from regis_date) as varchar(10)) end,'not confirmed') as regis_year,
coalesce(case when grouping(product_type)=1 then 'product_type total'
else product_type end,'not confirmed') as product_type,
coalesce(sum(sale_price),0) as sum_price
from products
group by rollup(extract(year from regis_date),product_type);
我们对代码做一个简短的说明:
coalesce函数用于将null转换成你想指定的数值。 cast用于数据类型的转换。case when 的输出结果,其类型要保持一致。
接下来,我们接触一个新的函数cube。废话不多说,直接上例题:
select coalesce(case when
grouping(regis_date)=1 then 'regis_date total' else cast(regis_date as varchar(30)) end,'not confirmed') as regis_date,
coalesce(
case when grouping(product_type)=1 then 'product_type total' else product_type end,'not confirmed')
as product_type,
sum(sale_price) as sum_price
from products
group by cube(regis_date,product_type);
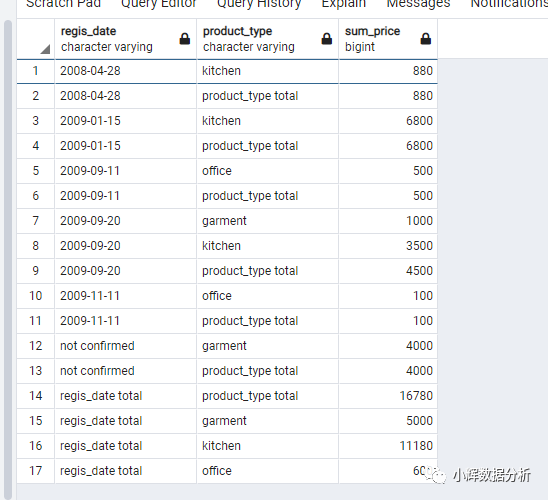
我们如何理解这cube呢?
我们再将cube换成rollup,观看一下效果:
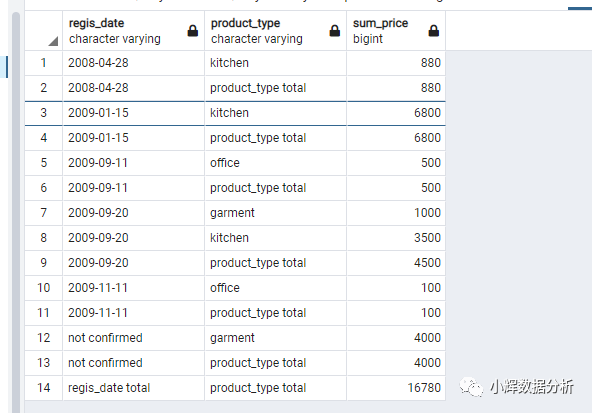
select coalesce(case when
grouping(regis_date)=1 then 'regis_date total' else cast(regis_date as varchar(30)) end,'not confirmed') as regis_date,
coalesce(
case when grouping(product_type)=1 then 'product_type total' else product_type end,'not confirmed')
as product_type,
sum(sale_price) as sum_price
from products
group by rollup(regis_date,product_type);
我们可以发现cube的结果相比rollup多了三行:
第15行,不限时间,服装类产品的销售额是5000 第16行,不限时间,厨房用品的总销售额是11800 第17行,不限时间,办公用品的总销售额是600
我们现在来总结一下,两个命令在汇总结果上的不同:
rollup: group by():不限时间和种类,总的产品销售额(16800) group by(regis_date):以时间为聚合键,不限商品种类的产品销售额,总共返回6条记录(记录序号是2,4,6,9,11,13) group by(regis_date,product_type):同时以时间和种类为聚合键,返回的商品销售额,总共返回7条记录(记录序号是1,3,5,7,8,10,12) cube: 在rollup的基础上,多了一个group by(product_type),即以商品种类为聚合键,不限时间,返回商品的销售额(对应的记录序号是15,16,17)
我们可以看出:cube返回的结果要比rollup多。如果聚合键的个数(也就是rollup或cube的参数数目)为2,rollup返回三种聚合结果;而cube则可以返回四种聚合结果。
实际上,如果聚合键的个数是n,那么rollup会返回(n+1)种聚合结果;cube会返回2的n次方种聚合结果。
我们可以看到,rollup的结果是包含在cube的结果当中的。但是,我们有的时候,并不想得到cube或rollup中的全部结果,我们只想得到一部分结果,此时,我们可以使用grouping sets来完成这一个需求。
举例如下:
select coalesce(case when
grouping(regis_date)=1 then 'regis_date total' else cast(regis_date as varchar(30)) end,'not confirmed') as regis_date,
coalesce(
case when grouping(product_type)=1 then 'product_type total' else product_type end,'not confirmed')
as product_type,
sum(sale_price) as sum_price
from products
group by grouping sets(regis_date,product_type);
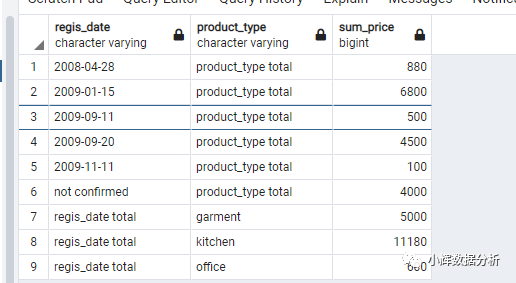
我们可以看到,只取出了9条结果,分别是:
不区分产品种类,按照时间进行汇总得到的结果 不区分时间,按照产品种类汇总得到的结果
在实际的应用中,GROUPING SETS的应用并不是很多!
现在,我们来稍微总结一下group by,group by rollup,group by cube,group by grouping sets四个命令在汇总结果上的不同(以regis_date和product_type为例):
group by:一种汇总结果 group by(regis_date,product_type) group by grouping sets:两种汇总结果 group by(regis_date) group by(product_type) group by rollup:三种汇总结果 group by() group by (regis_date) group by (regis_date,product_type) group by cube:四种汇总结果 group by() group by(regis_date) group by(product_type) group by(regis_date,product_type)
四.PIVOT与UNPIVOT(一维表与二维表之间的转换)
SQL中的group by在功能上,相当于Excel中的数据透视表。不过,两者在结果的展现却存在着不同:SQL是以一维表的形式呈现的,而Excel是以二维表的形式呈现的。在结果的呈现上,二维表更为直观,具有一定的优势,那么,我们如何将一个一维表转换成一个二维表呢?
一维表转换成二维表,我们是可以使用case when 来解决的。
-- 创建视图
create view one_dim as
(select coalesce(cast(regis_date as varchar(30)),'not confirmed') as regis_date,
product_type,
sum(sale_price)
from products
group by regis_date,product_type);
-- 一维表转换为二维表
select regis_date,
sum(case when
product_type='garment' then sum else null end)as garment,
sum(case when
product_type='office' then sum else null end) as office,
sum(case when
product_type='kitchen' then sum else null end) as kitchen
from one_dim
group by regis_date;
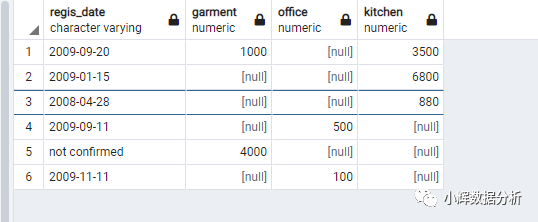
这里稍微注意一个点:为什么要使用sum这一聚合函数(其实,avg、max、min等其他聚合函数也是可以的):为了后面只使用regis_date这一个聚合键!
这种方法,我们明显可以看到是比较麻烦的,有没有简便一些的方法呢?
MS SQL当中PIVOT命令,可以迅速地解决这一问题!这一次,我们使用了新的数据集!
-- 建立一张表
create table data (id varchar(2),
name varchar(10),
season varchar(10),
num int);
-- 插入数据
insert into data values('01','shoe','spring',15);
insert into data values('01','shoe','summer',25);
insert into data values('01','shoe','fall',35);
insert into data values('02','garment','spring',4);
insert into data values('02','garment','summer',5);
insert into data values('02','garment','fall',7);
-- 使用case when
select name,
avg(case when season='spring' then num else null end) as spring,
avg(case when season='summer' then num else null end) as summer,
avg(case when season='fall' then num else null end) as fall
from data
group by name;
-- 使用PIVOT实现
select name,[spring],[summer],[fall]
from
(select name,season,num from data) p
pivot(sum(num) for season in ([spring],[summer],[fall])) as piv;
结果如下图所示:

好了,一维表如何转换成二维表,我们已经知道了。那么,我们如何将二维表转换成一维表呢?
方法有两种:
UNION ALL+SUM等聚合函数方法 UNPIVOT 方法
我们具体讲解如下,
-- 建立数据集
create table data2(city varchar(10),
pop2010 int,
pop2020 int);
insert into data2 values('pek',2187,1878);
insert into data2 values('sha',2487,2177);
insert into data2 values('can',1868,1277);
insert into data2 values('szx',1767,1062);
-- 使用UNION ALL+SUM
select city,'pop2010' as years,
sum(pop2010) as num
from data2
group by city
union all
select city,'pop2020' as years,
sum(pop2020) as num
from data2
group by city;
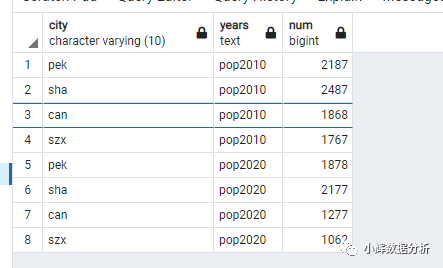
-- 使用UNPIVOT方法
select city,years,num
from
(select city,pop2010,pop2020 from data2) t
unpivot
(num for years in (pop2010,pop2020))p;
结果如下:
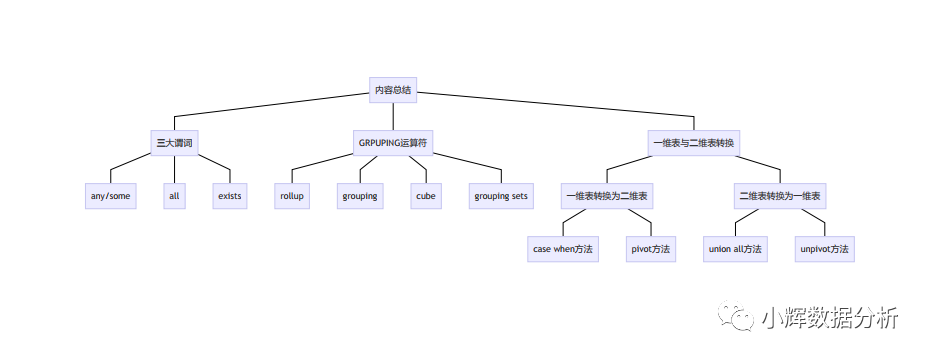
五.内容总结
本文的内容总结如下:
参考文献
《PostgreSQL11从入门到精通》 李小威著 清华大学出版社 《SQL基础教程(第二版)》MICK著 人民邮电出版社 公众号数据分析大本营推文《【SQL常用代码】--SQL实现透视功能》 公众号数据管道推文《面试常考!SQL行转列和列转行》
