概述
对于只涉及数据读写的事务,有可能出现“单机事务死锁”和“分布式事务的死锁”。前者MySQL提供死锁检测能力,后者PolarDB-X也提供了死锁检测能力。但哪怕没有分布式死锁检测能力,事务也会在一定时间后超时,默认50秒,危害也没有太大。
但是当分布式读写事务和DDL结合起来之后,可能会出现分布式MDL死锁的问题。MDL的死锁危害巨大,因为它不仅会阻塞当前事务,还会阻塞后续所有事务,默认超时时间是1年。要排查起来也十分麻烦,需要到多个节点拉取MDL锁信息。
总结一下分布式MDL死锁问题:范围大、时间久、排查难。一旦出现,可能导致多个表全部流量长时间跌0的危险情况。
问题背景
关系型数据库的事务一般都要提供ACID的保证,这就意味着DDL的执行不能干扰到其他事务的ACID特性。当DDL和其他读写事务并发执行时,一方面DDL会修改表结构,另一方面我们又希望读写事务能永远看到一致性的表结构。所以,在MySQL的早期版本中(小于5.6),直接禁止DDL和DML并发执行。这种情况一直持续到MySQL引入了MDL锁和Online DDL能力后,才有所改善。
简单来说,MySQL引入Online DDL能力后:
- 读写事务会获取元数据的读锁(后称:MDL的S锁),DDL会获取元数据的写锁(后称:MDL的X锁)。
- MySQL的Online DDL会将一条DDL语句分成很多个阶段,只有在必要的阶段(通常时间会压缩地很短)才会获取MDL的X锁。所以,在DDL的大部分阶段,读写事务都是可以并发执行的,只有在那些必要的阶段,DDL才会阻塞读写事务。
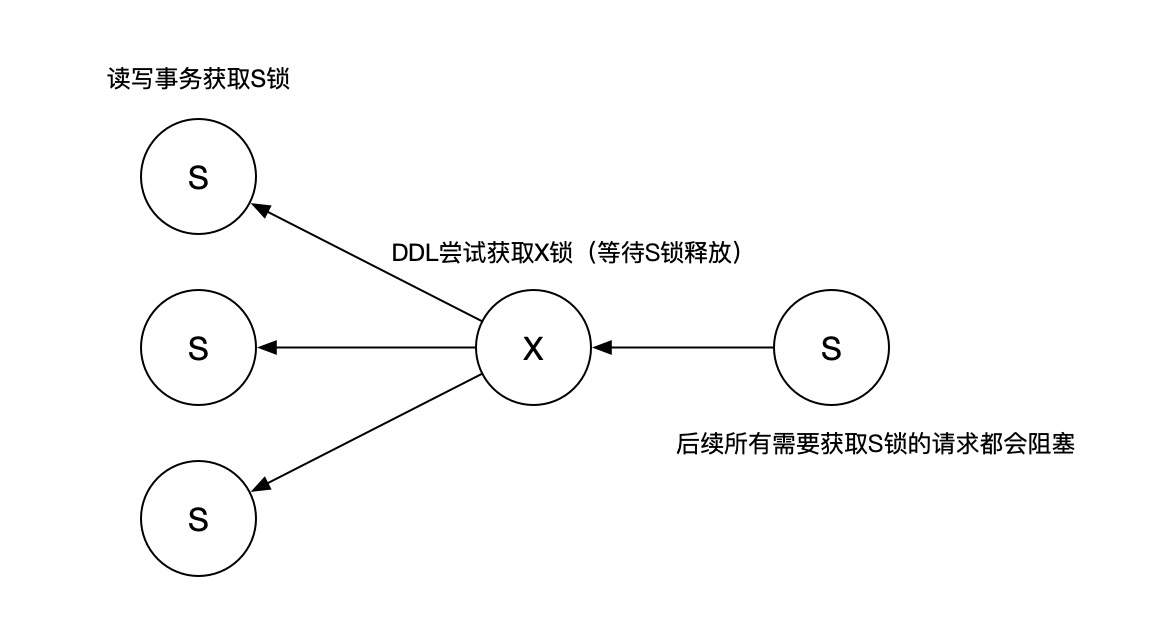
- 为了保证读写事务不会对DDL形成活锁,MDL一般都会被设计成一个“公平锁”。
即便MySQL有了Online DDL,大家还是只敢在半夜进行DDL操作。其中一个重要原因就在于MDL锁的“公平性”。当DDL在等待一个长事务时,它将阻塞后续所有的读写事务,极有可能造成业务的中断,并且MySQL获取MDL锁的超时时间默认长达一年,是一件非常危险的事情。
从锁的视角来看:MDL请求队列中的X锁,阻塞了后续S锁的申请,大家都在排队等待最前面的MDL锁释放。换句话说,MDL请求队列中的X锁,会将它之前的所有S锁升级成X锁。

分布式MDL死锁的形成
以下是形成“分布式MDL死锁”的SQL执行流程。
分布式 Transaction1 | 分布式 Transaction2 | DDL1 | DDL2 |
xa start | xa start | ||
insert into t1 (c2) values (2); -- 获得t1的MDL S锁 | insert into t2 (c2) values (2); -- 获得t2的MDL S锁 | ||
alter table t1 add column c5 bigint; -- 尝试获得t1的MDL X锁,阻塞等待 | alter table t2 add column c5 bigint; -- 尝试获得t2的MDL X锁,阻塞等待 | ||
insert into t2 (c2) values (2); -- 尝试获得t2的MDL S锁。但因为MDL是公平锁,所以被DDL2阻塞 | insert into t1 (c2) values (2); -- MDL DeadLock -- 尝试获得t1的MDL S锁。但因为MDL是公平锁,所以被DDL1阻塞 |
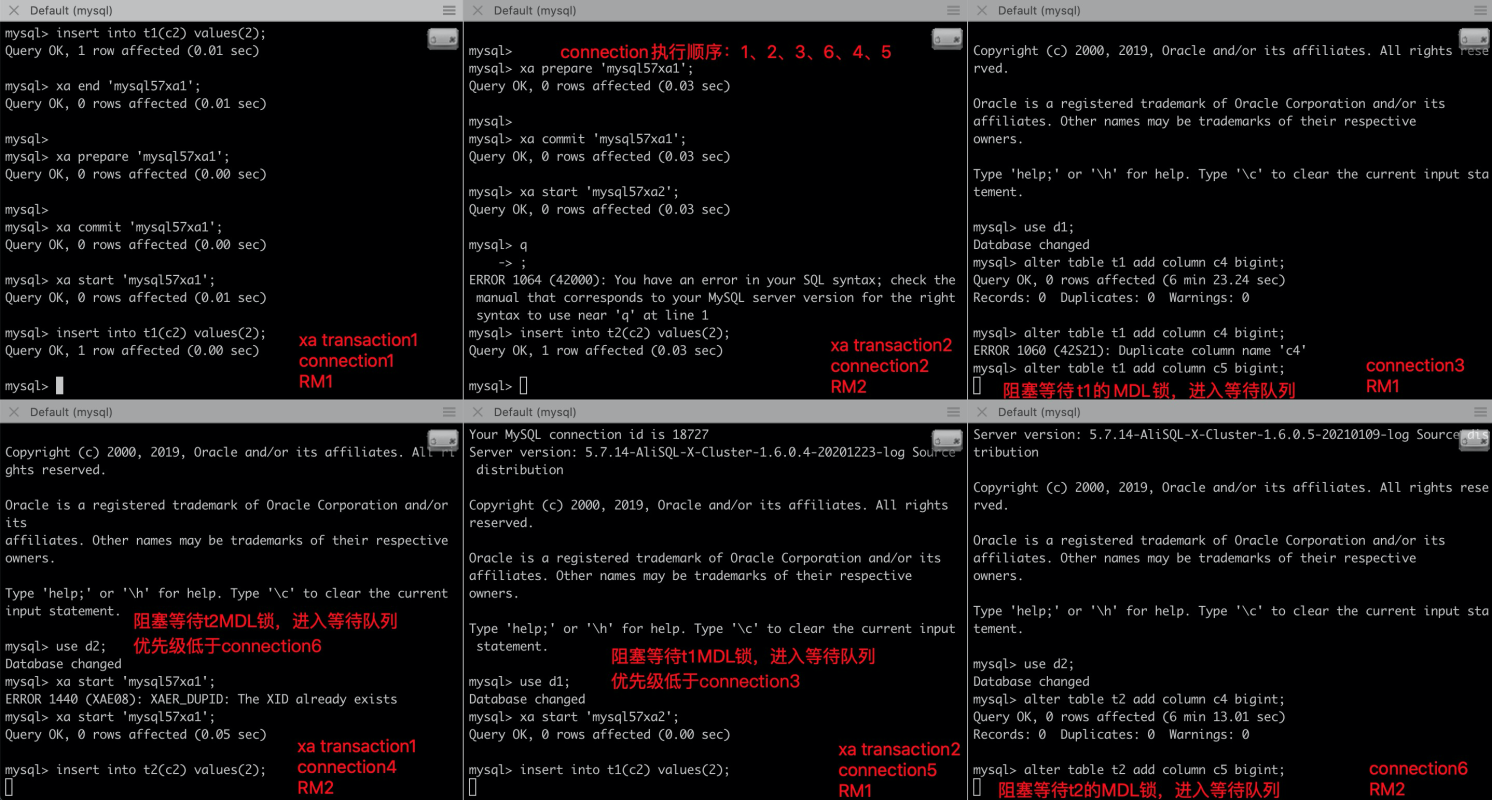
根据上述的流程,我们在MySQL中复现了分布式MDL死锁的情况:
由下图可见,XA1事务、XA2事务、DDL1语句、DDL2语句全部进入阻塞等待状态,形成了死锁。

解决方案
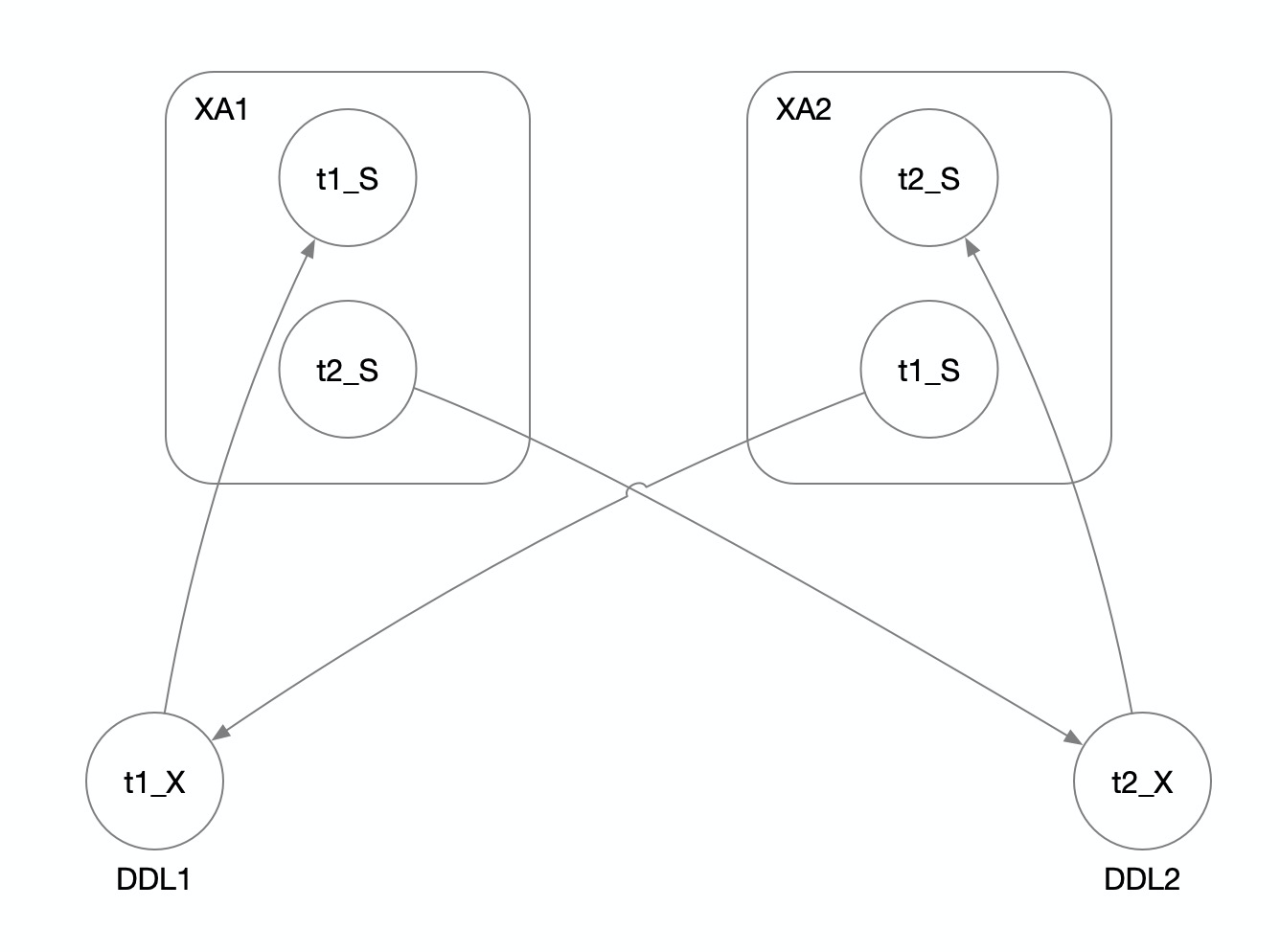
我们可以根据事务的Wait-For关系,构造有向图,然后检测环路的方式来检测是否发生了死锁。一旦发生,则选择其中的一个线程kill掉即可。具体实施过程如下:
- 从所有MySQL节点收集事务信息,将同一个分布式事务中多个ResourceManager(RM)的事务信息合并在一起。形成有向图中的一个节点,比如下图中的XA1、XA2。
- 同时,也构建出所有事务之间的wait-for关系。
- 从所有MySQL节点收集MDL信息,比如下图中的DDL1、DDL2。
- 同时,也构建出所有DDL和事务间的wait-for关系。
- 检测环路。比如下图中XA1->DDL2->XA2->DDL1->XA1形成了环路。
- 根据kill策略,kill掉事务或DDL,解开死锁。

MDL锁超时抢占
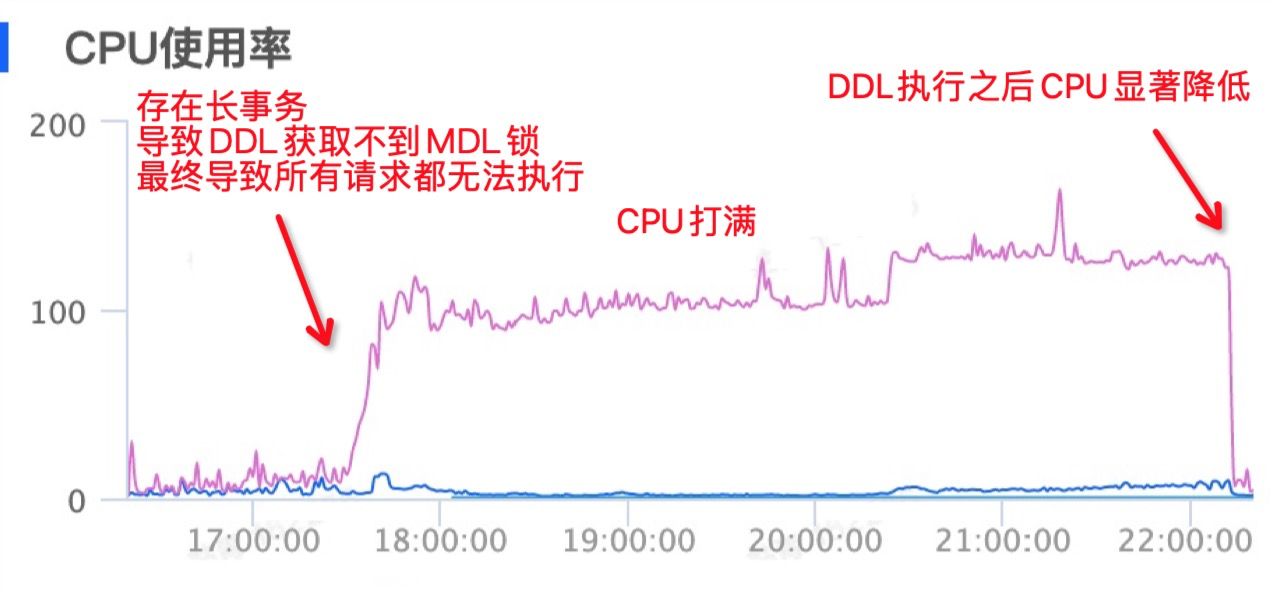
当然,分布式MDL死锁虽然危险,但发生的概率也相对较低。在生产环境更常发生的情况是MDL锁阻塞读写请求。它虽然能自愈,但还是可能导致长时间的读写请求流量跌0。
如前文所论述:
- 如果有一个长事务一直不提交,它就会一直持有MDL的S锁
- 此时执行一个DDL请求,它会尝试请求MDL的X锁
- 后续所有的读写请求都会被DDL阻塞,导致流量跌0,CPU飙升

针对上述场景,PolarDB-X会允许DDL抢占长事务的MDL锁,避免阻塞后续的读写请求。从下图可以看到,DDL在等待了一段时间后执行成功了,而长事务被KILL掉。

总结
分布式MDL死锁相比于普通的数据死锁,危害巨大并且难以排查。一旦出现,哪怕经验丰富的DBA和开发者都难以短时间内解决问题。
作为一款致力于“让用户做DDL的时候能更任性”的数据库,PolarDB-X为DDL的online能力、Crash Safe能力、性能等都做了很多的优化,欢迎持续关注我们的文章。
参考资料
- PolarDB-X 让“Online DDL”更Online
概述
对于只涉及数据读写的事务,有可能出现“单机事务死锁”和“分布式事务的死锁”。前者MySQL提供死锁检测能力,后者PolarDB-X也提供了死锁检测能力。但哪怕没有分布式死锁检测能力,事务也会在一定时间后超时,默认50秒,危害也没有太大。
但是当分布式读写事务和DDL结合起来之后,可能会出现分布式MDL死锁的问题。MDL的死锁危害巨大,因为它不仅会阻塞当前事务,还会阻塞后续所有事务,默认超时时间是1年。要排查起来也十分麻烦,需要到多个节点拉取MDL锁信息。
总结一下分布式MDL死锁问题:范围大、时间久、排查难。一旦出现,可能导致多个表全部流量长时间跌0的危险情况。
问题背景
关系型数据库的事务一般都要提供ACID的保证,这就意味着DDL的执行不能干扰到其他事务的ACID特性。当DDL和其他读写事务并发执行时,一方面DDL会修改表结构,另一方面我们又希望读写事务能永远看到一致性的表结构。所以,在MySQL的早期版本中(小于5.6),直接禁止DDL和DML并发执行。这种情况一直持续到MySQL引入了MDL锁和Online DDL能力后,才有所改善。
简单来说,MySQL引入Online DDL能力后:
- 读写事务会获取元数据的读锁(后称:MDL的S锁),DDL会获取元数据的写锁(后称:MDL的X锁)。
- MySQL的Online DDL会将一条DDL语句分成很多个阶段,只有在必要的阶段(通常时间会压缩地很短)才会获取MDL的X锁。所以,在DDL的大部分阶段,读写事务都是可以并发执行的,只有在那些必要的阶段,DDL才会阻塞读写事务。
- 为了保证读写事务不会对DDL形成活锁,MDL一般都会被设计成一个“公平锁”。
即便MySQL有了Online DDL,大家还是只敢在半夜进行DDL操作。其中一个重要原因就在于MDL锁的“公平性”。当DDL在等待一个长事务时,它将阻塞后续所有的读写事务,极有可能造成业务的中断,并且MySQL获取MDL锁的超时时间默认长达一年,是一件非常危险的事情。
从锁的视角来看:MDL请求队列中的X锁,阻塞了后续S锁的申请,大家都在排队等待最前面的MDL锁释放。换句话说,MDL请求队列中的X锁,会将它之前的所有S锁升级成X锁。
分布式MDL死锁的形成
以下是形成“分布式MDL死锁”的SQL执行流程。
分布式 Transaction1
分布式 Transaction2
DDL1
DDL2
xa start
xa start
insert into t1 (c2) values (2);
-- 获得t1的MDL S锁
insert into t2 (c2) values (2);
-- 获得t2的MDL S锁
alter table t1 add column c5 bigint;
-- 尝试获得t1的MDL X锁,阻塞等待
alter table t2 add column c5 bigint;
-- 尝试获得t2的MDL X锁,阻塞等待
insert into t2 (c2) values (2);
-- 尝试获得t2的MDL S锁。但因为MDL是公平锁,所以被DDL2阻塞
insert into t1 (c2) values (2);
-- MDL DeadLock
-- 尝试获得t1的MDL S锁。但因为MDL是公平锁,所以被DDL1阻塞
根据上述的流程,我们在MySQL中复现了分布式MDL死锁的情况:
由下图可见,XA1事务、XA2事务、DDL1语句、DDL2语句全部进入阻塞等待状态,形成了死锁。
解决方案
我们可以根据事务的Wait-For关系,构造有向图,然后检测环路的方式来检测是否发生了死锁。一旦发生,则选择其中的一个线程kill掉即可。具体实施过程如下:
- 从所有MySQL节点收集事务信息,将同一个分布式事务中多个ResourceManager(RM)的事务信息合并在一起。形成有向图中的一个节点,比如下图中的XA1、XA2。
- 同时,也构建出所有事务之间的wait-for关系。
- 从所有MySQL节点收集MDL信息,比如下图中的DDL1、DDL2。
- 同时,也构建出所有DDL和事务间的wait-for关系。
- 检测环路。比如下图中XA1->DDL2->XA2->DDL1->XA1形成了环路。
- 根据kill策略,kill掉事务或DDL,解开死锁。
MDL锁超时抢占
当然,分布式MDL死锁虽然危险,但发生的概率也相对较低。在生产环境更常发生的情况是MDL锁阻塞读写请求。它虽然能自愈,但还是可能导致长时间的读写请求流量跌0。
如前文所论述:
- 如果有一个长事务一直不提交,它就会一直持有MDL的S锁
- 此时执行一个DDL请求,它会尝试请求MDL的X锁
- 后续所有的读写请求都会被DDL阻塞,导致流量跌0,CPU飙升
针对上述场景,PolarDB-X会允许DDL抢占长事务的MDL锁,避免阻塞后续的读写请求。从下图可以看到,DDL在等待了一段时间后执行成功了,而长事务被KILL掉。
总结
分布式MDL死锁相比于普通的数据死锁,危害巨大并且难以排查。一旦出现,哪怕经验丰富的DBA和开发者都难以短时间内解决问题。
作为一款致力于“让用户做DDL的时候能更任性”的数据库,PolarDB-X为DDL的online能力、Crash Safe能力、性能等都做了很多的优化,欢迎持续关注我们的文章。
参考资料
- PolarDB-X 让“Online DDL”更Online