




对于MySQL Multi-threaded Replication并行复制都比较熟悉。但实际场景使用中确实各占50%的比例。并行复制是为了缓解复制中的延迟而诞生的。
主库依旧单线程提交事务,同时记录binlog的时标记并行标签,从库回放的时通过这些标签,实现并行回放。从记录的binlog就可以了解到,实现并行复制是通过last_committed + sequence_number的字段内容。
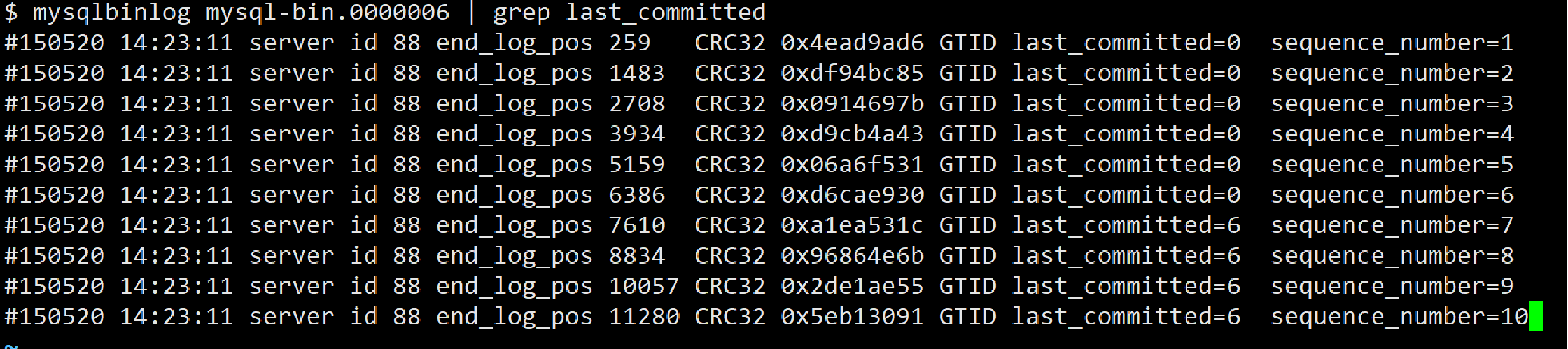
- sequence_number:给定二进制日志中的第一个事务为1,第二个事务为2,依此类推。在每个二进制日志文件中以1重新开始编号。
- last_committed:指最近提交的与当前事务冲突的事务的sequence_number。这个值总是小于sequence_number。
那MySQL中这些并行指标如何实现,参数binlog_transaction_dependency_tracking提供了三个可选值,控制用于计算这些逻辑时间戳的模式的选择。控制事务依赖模式,让从库根据主库写入binlog中的 commit timestamps 或者 writesets 并行回放事务(引入该参数之后,binlog的格式记录的内容中增加了时间戳和writesets信息)
COMMIT_ORDERE
COMMIT_ORDER(默认参数),依赖信息根据源上事务提交的时间顺序产生。
基于逻辑时钟Logical_Clock的并行复制必须是在主上并行提交的事务(last_committed,sequence_number)才能在从上并行回放,如果主上并发压力不大,那么就无法享受到并行复制带来的好处。任然有不尽人意的地方,
虽然为了缓解这个问题,提供了两个控制参数:
| 参数 | 说明 |
|---|---|
| binlog_group_commit_sync_delay | 一组里面有多少事物才提交,单位 (ms) |
| binlog_group_commit_sync_no_delay_count | 等待多少时间后才进行组提交,单位每组事物数量 |
备注:通过让binlog在执行 fsync 前等待一小会来提高Master上组提交的比率。但因为业务模型更细节动作无规律性,参数值更不好控制。还是有不尽人意的地方,上并行回放的速度还是取决于主上并行提交的情况。
WRITESET
使用 WriteSet的方式判定事务的冲突检测,并标记平行指标,如发现冲突则依赖冲突事务,否则按照 COMMIT_ORDERE方式。
WRITESET是一个hash数组,首先提交的事务会构成一个hash链表,事务中的每一行向事务的写集添加一组或多个哈希值,其中一行中的每个唯一键都有一个哈希值。(如果没有唯一的、不可空的键,则使用行散列。)这包括删除和插入的行;对于更新的行,旧行和新行都包括在内。最后对所有组成员进行冲突检测和认证
影响WRITESET的参数如下两个:
| 参数 | 说明 |
|---|---|
| binlog_transaction_dependency_history_size | 设置保存在内存中并用于查找上次修改给定行的事务的行哈希数的上限。一旦达到这个哈希数,就会清除历史记录。 |
| transaction_write_set_extraction | 对事务期间提取的写操作进行散列的算法。默认值是XXHASH64 |
备注:transaction_write_set_extraction自MySQL 8.0.26起已弃用;预计它将在未来的MySQL版本中被删除。因为可以按照主键值可进行对比。主键的重要性又体现了。
WRITESET依赖于那些数据库信息,形成hash值:
从源码实现来看,形成writeset值,需要库名+表名+主键+唯一键+外键等多个值
\sql\rpl_write_set_handler.cc
bool writeset_hashes_added = false;
if (table->key_info && (table->s->primary_key < MAX_KEY)) {
const ptrdiff_t ptrdiff = record - table->record[0];
std::string pke_schema_table;
pke_schema_table.reserve(NAME_LEN * 3);
pke_schema_table.append(HASH_STRING_SEPARATOR);
pke_schema_table.append(table->s->db.str, table->s->db.length);
pke_schema_table.append(HASH_STRING_SEPARATOR);
pke_schema_table.append(std::to_string(table->s->db.length));
pke_schema_table.append(table->s->table_name.str,table->s->table_name.length);
pke_schema_table.append(HASH_STRING_SEPARATOR);
pke_schema_table.append(std::to_string(table->s->table_name.length));
std::string pke;
pke.reserve(NAME_LEN * 5);
#ifndef NDEBUG
std::vector<std::string> write_sets;
std::vector<uint64> hash_list;
#endif
for (uint key_number = 0; key_number < table->s->keys; key_number++) {
// Skip non unique.
if (!((table->key_info[key_number].flags & (HA_NOSAME)) == HA_NOSAME))
continue;
pke.clear();
pke.append(table->key_info[key_number].name);
pke.append(pke_schema_table);
。。。。。。
Prefix the hash keys with the referenced index name.
*/
pke.clear();
pke.append(fk[fk_number].unique_constraint_name.str,
fk[fk_number].unique_constraint_name.length);
pke.append(HASH_STRING_SEPARATOR);
pke.append(fk[fk_number].referenced_table_db.str,
fk[fk_number].referenced_table_db.length);
pke.append(HASH_STRING_SEPARATOR);
pke.append(referenced_schema_name_length);
pke.append(fk[fk_number].referenced_table_name.str,
fk[fk_number].referenced_table_name.length);
pke.append(HASH_STRING_SEPARATOR);
pke.append(referenced_table_name_length);
- 在计算writeset的时,表无主键情况,不会用到隐藏的主键
- 在计算writeset的时,库名+表名+主键+唯一键(有的话),为什么需要加唯一键,排除掉NULL值外,其他值必须保证唯一性。
- 对于没有主键的表 ,或者是有外键约束的表,writeset策略是没法并行的,也会暂时退化为单线程模型。因为wirteset是通过 库名+表名+主键值+(唯一键名字和非空键值)来确定的唯一性的,
如果没有主键,那么不能保证算出来的hash值是唯一的,因为唯一键可以为NULL,所以没有主键是不能用writeset的。又因为如果表上有外键,级联更新的行不会记录到binlog中,这样的冲突检测就不准确。
下面来看下,writeset下不同表结构是否并行。
1. 表存在主键,可以并行
mysql> CREATE DATABASE mtsdb ;
Query OK, 1 row affected (0.01 sec)
mysql> CREATE TABLE mtsdb.t1 ( pid int primary key , name varchar(30) not null );
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO mtsdb.t1(pid,`name`) VALUES (1,"a");
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO mtsdb.t1(pid,`name`) VALUES (2,"b");
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO mtsdb.t1(pid,`name`) VALUES (3,"c");
Query OK, 1 row affected (0.00 sec)
解析记录binlog的组提交情况:
shell> mysqlbinlog --no-defaults --base64-output=decode-rows -vv mysql-bin.000003 | grep last_ | sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#230628 10:33:39 [...] last_committed=0 sequence_number=1 [...] CREATE DATABASE
#230628 10:33:39 [...] last_committed=1 sequence_number=2 [...] CREATE TABLE
#230628 10:33:39 [...] last_committed=2 sequence_number=3 [...] INSERT a
#230628 10:33:39 [...] last_committed=2 sequence_number=4 [...] INSERT b
#230628 10:33:39 [...] last_committed=2 sequence_number=5 [...] INSERT c
WriteSet方式就是通过hash值对比,检测不同事务之间是否存在写冲突,并重规划了事务的并行回放。直接在binlog生成阶段完成。
2. 表不存在主键,无法并行
mysql> CREATE DATABASE mtsdb ;
Query OK, 1 row affected (0.01 sec)
mysql> CREATE TABLE mtsdb.t1 (uid int auto_increment, name varchar(30) not null,key(uid));
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO mtsdb.t1(`name`) VALUES ("a");
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO mtsdb.t1(`name`) VALUES ("b");
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO mtsdb.t1(`name`) VALUES ("c");
Query OK, 1 row affected (0.00 sec)
解析记录binlog的组提交情况:
shell> mysqlbinlog --no-defaults --base64-output=decode-rows -vv mysql-bin.000001 | grep last_ | sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#230628 18:19:14 [...] last_committed=0 sequence_number=1 [...] CREATE DATABASE
#230628 18:19:14 [...] last_committed=1 sequence_number=2 [...] CREATE TABLE
#230628 18:19:14 [...] last_committed=2 sequence_number=3 [...] INSERT a
#230628 18:19:14 [...] last_committed=3 sequence_number=4 [...] INSERT b
#230628 18:19:14 [...] last_committed=4 sequence_number=5 [...] INSERT c
3.表不存在主键,存在唯一键,无法并行
mysql> CREATE DATABASE mtsdb ;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE TABLE mtsdb.t1 ( uid int , name varchar(30) not null,unique key(id));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO mtsdb.t1(uid,`name`) VALUES (1,"a");
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO mtsdb.t1(uid,`name`) VALUES (2,"b");
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO mtsdb.t1(uid,`name`) VALUES (3,"c");
Query OK, 1 row affected (0.00 sec)
shell# mysqlbinlog --no-defaults --base64-output=decode-rows -vv mysql-bin.000001 | grep last_ | sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#230628 18:52:52 [...] last_committed=0 sequence_number=1 [...] CREATE DATABASE
#230628 18:52:52 [...] last_committed=1 sequence_number=2 [...] CREATE TABLE
#230628 18:52:52 [...] last_committed=2 sequence_number=3 [...] INSERT a
#230628 18:52:52 [...] last_committed=3 sequence_number=4 [...] INSERT b
#230628 18:52:52 [...] last_committed=4 sequence_number=5 [...] INSERT c
4.表存在主键,存在唯一键,实现并行
mysql> CREATE DATABASE mtsdb ;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE TABLE mtsdb.t1 ( pid int primary key ,uid int , name varchar(30) not null,unique key(uid));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO mtsdb.t1(pid,uid,`name`) VALUES (1,NULL,"a");
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO mtsdb.t1(pid,uid,`name`) VALUES (2,NULL,"b");
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO mtsdb.t1(pid,uid,`name`) VALUES (3,NULL,"c");
Query OK, 1 row affected (0.00 sec)
shell> mysqlbinlog --no-defaults --base64-output=decode-rows -vv mysql-bin.000001 | grep last_ | sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#230628 19:02:00 [...] last_committed=0 sequence_number=1 [...] CREATE DATABASE
#230628 19:02:00 [...] last_committed=1 sequence_number=2 [...] CREATE TABLE
#230628 19:02:00 [...] last_committed=2 sequence_number=3 [...] INSERT a
#230628 19:02:00 [...] last_committed=2 sequence_number=4 [...] INSERT b
#230628 19:02:01 [...] last_committed=2 sequence_number=5 [...] INSERT c
5.表无主键,但存在自增唯一键,可以并行
mysql> CREATE DATABASE mtsdb ;
Query OK, 1 row affected (0.01 sec)
mysql> CREATE TABLE mtsdb.t1 ( uid int auto_increment, name varchar(30) not null,unique key(uid));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO mtsdb.t1(uid,`name`) VALUES (1,"a");
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO mtsdb.t1(uid,`name`) VALUES (2,"b");
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO mtsdb.t1(uid,`name`) VALUES (3,"c");
shell> mysqlbinlog --no-defaults --base64-output=decode-rows -vv mysql-bin.000001 | grep last_ | sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#230628 18:58:56 [...] last_committed=0 sequence_number=1 [...] CREATE DATABASE
#230628 18:58:56 [...] last_committed=1 sequence_number=2 [...] CREATE TABLE
#230628 18:58:56 [...] last_committed=2 sequence_number=3 [...] INSERT a
#230628 18:58:56 [...] last_committed=2 sequence_number=4 [...] INSERT b
#230628 18:58:56 [...] last_committed=2 sequence_number=5 [...] INSERT c
备注:在库名+表名+主键+唯一键(有的话) 或 库名+表名+自增唯一键 都可实现writeset方式。
除此之外在高版本MGR场景下,必须要开启writeset并行模式,mgr集群会执行自行的并行化,与binlog_transaction_dependency_tracking的任何值设置无关,但是这个变量确实会影响如何将事务写入Group Replication成员上的二进制日志。这些日志中的依赖信息用于提供者的二进制日志进行状态转移的过程。
WRITESET_SESSION
在WRITESET方式的基础上,不同session的事务可以并发执行,同一个session内的事务不可并行。
在WRITESET_SESSION模式下,重复上次过程,在同一个session中,可以看到last_committed不存在同一个值。
shell> mysqlbinlog --no-defaults --base64-output=decode-rows -vv mysql-bin.000001 | grep last_ | sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#230628 11:23:14 [...] last_committed=0 sequence_number=1 [...] CREATE DATABASE
#230628 11:23:14 [...] last_committed=1 sequence_number=2 [...] CREATE TABLE
#230628 11:23:14 [...] last_committed=2 sequence_number=3 [...] INSERT a
#230628 11:23:14 [...] last_committed=3 sequence_number=4 [...] INSERT b
#230628 11:23:14 [...] last_committed=4 sequence_number=5 [...] INSERT c
总结
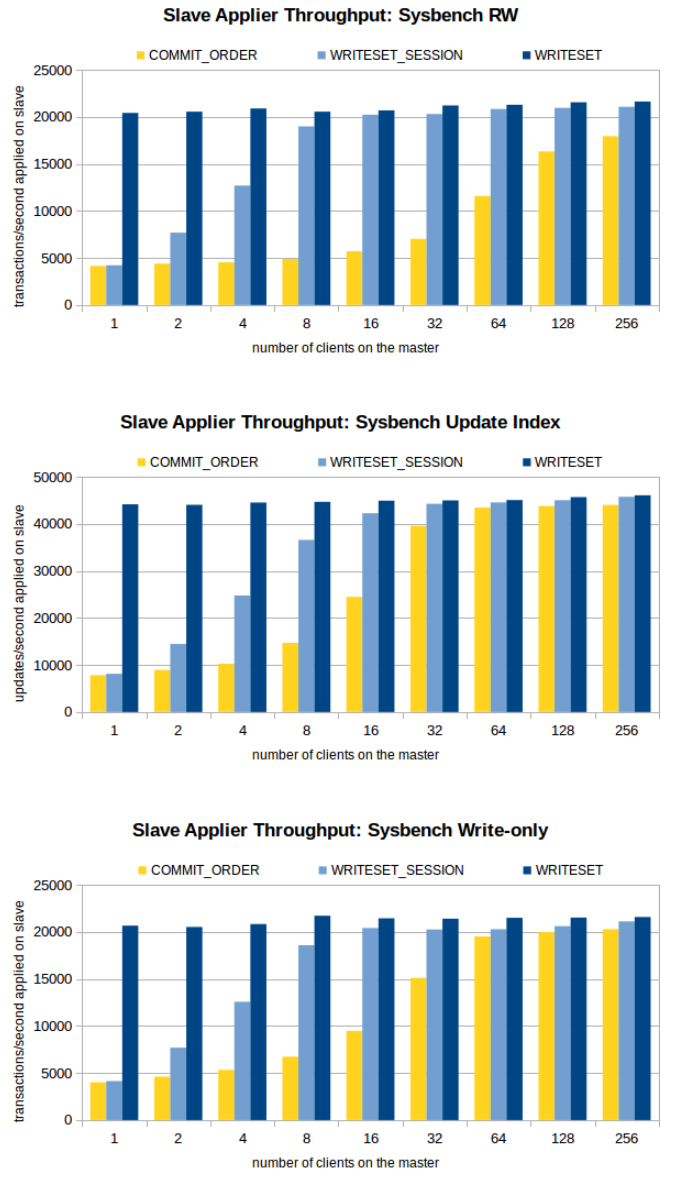
sysbench压测:16核CPU,本地SSD磁盘, 100万个事务,16张表,800万行,16 slave applier线程
-
在开启并行复制之后,对从节点的RelayLog回放速度提升显著。特别是writeset方式RelayLog 回放速度将不再依赖于Master上提交时的并行程度,使得从节点上可以发挥其最大的吞吐能力。
-
但这样的情况下事务的提交顺序可能会在从节点上发生改变。这种情况下可以开启 slave_preserve_commit_order(replica_preserve_commit_order) 可以保证从节点上并行回放的线程按RelayLog中写入的顺序 Commit。
-
复制需要确保显式主键,并行复制也是一样。如没有主键,还不如关闭并行复制。
-
主键+唯一键需要合理设计。比如 varchar(256)这样字段,比消耗很大的性能。
-
因为hash表长度有限,大事务还需避免。
