语义检索 [1](Semantic Search) 是能帮助你的客户或员工找到正确的产品或信息的绝佳工具,它甚至可以检索到一些难以被索引的信息,从而获得更好的结果。即便如此,倘若你所部署的方案没有速度优势,那也无济于事。如果系统响应查询请求的速度非常缓慢,客户或员工可没有耐心干等着,更不用说可能还有其他上千个查询请求在同时发生。如果低效的语义检索难以胜任,那么如何进行高速的语义检索呢?幸运的是,Lucidworks 热衷于解决此类问题。最近,我们测试了一个中等规模的集群(详情请看下文),针对逾百万文档的集合,可达到每秒 1,500 RPS(每秒请求率),平均响应时间约 40 毫秒。这个速度可以说是非常可观了。 执行语义检索
为了让机器学习达到闪电般快的速度,Lucidworks 通过向量搜索的方法执行语义检索,由两个关键部分组成。第一部分:机器学习模型
首先,你需要将文本编码为特征向量。文本可以是产品说明、用户搜索查询指令、问题,甚至是问题的答案。训练语义模型对文本进行编码,语义上相似的文本被编码为数值上彼此“接近”的向量。为了支持每秒可能出现的数千个或更多的客户搜索或用户查询,该编码步骤需要快速完成。
第二部分:向量搜索引擎
其次,你需要一种能快速找到客户搜索或用户查询的最匹配结果的方法。前文中的模型已经将文本编码为特征向量。接着,将这个向量与目录或问答列表中的所有特征向量进行比较,找到与之最匹配的向量,即与查询向量“最接近”的向量。为此,一个能迅速高效地处理所有这些信息的向量引擎必不可少。引擎中可能包含了数百万个向量,而你实际上只需要其中匹配度最高的二十个左右。当然,它每秒需要处理约一千条此类查询。为了解决这些难题,我们在 Fusion 5.3 版本[2]中添加了向量搜索引擎 Milvus[3]。Milvus 是一款开源软件,拥有极高的搜索速度。Milvus 采用的是 Facebook AI Similarity Search[4](FAISS,即 Facebook 人工智能相似性搜索)开源库,Facebook 在其自己的机器学习计划的生产中使用的也是这一技术。如有需要,它甚至可以在 GPU[5]的支持下运行得更快。Fusion 5.3(或更高版本)与机器学习组件一起安装时,Milvus 会作为该组件的一部分自动安装,轻松开启所有这些功能。在创建集合的时候需要指定向量的维度(大小),这个向量的维度取决于生成这些向量的模型。例如,通过模型可以将产品目录中所有产品描述都编码为向量,并存储于一个给定的集合中。如果没有像 Milvus 这样的向量搜索引擎,那么就无法在整个向量空间上进行相似性搜索,而只能局限于从向量空间中预选出的候选项(比如 500 条),且性能低下、质量不佳。Milvus 可以存储多个向量集合的数千亿条向量,保证搜索快速且结果相关。 使用语义检索
在了解了 Milvus 如此重要的原因后,让我们回到语义检索的工作流程。语义检索分为三个阶段:第一阶段是加载和/或训练机器学习模型;接着,将数据导入到 Milvus 和 Solr 中并建立索引;最后是查询阶段,即实际搜索发生的阶段。下面将重点介绍后两个阶段。 导入 Milvus 并建立索引
如上图所示,在建立索引阶段,对给定的数据源中的每个文档执行以下步骤:- 将文档发送到 Smart Answers 数据管道。
- 将所选文档字段(例如,问答系统中的答案或电子商务系统中的产品描述)发送到机器学习模型。
- 机器学习模型返回一个特征向量(对字段编码生成)。向量大小取决于模型类型。
- 向量和其唯一的 ID 存储在 Milvus 集合中。
当然,你也可以做一些调整,例如在 Milvus 中编码并储存多个字段。接下来,让我们进入第二阶段。 使用 Milvus 查询
如上图所示,查询阶段与索引阶段的起始步骤类似,只是将进入管道的文档换成了查询指令。步骤如下:- 发送查询至 Smart Answers[6]数据管道。
- 机器学习模型返回一个特征向量(从查询请求中加密)。同样地,向量大小取决于模型类型。
- 将该向量发送到 Milvus,然后由 Milvus 判断指定集合中哪些向量与提供的向量匹配度最高。
- Milvus 返回与步骤 4 中确定的向量相对应的唯一 ID 和距离列表。
- 将包含这些 ID 和距离的查询指令发送到 Solr。
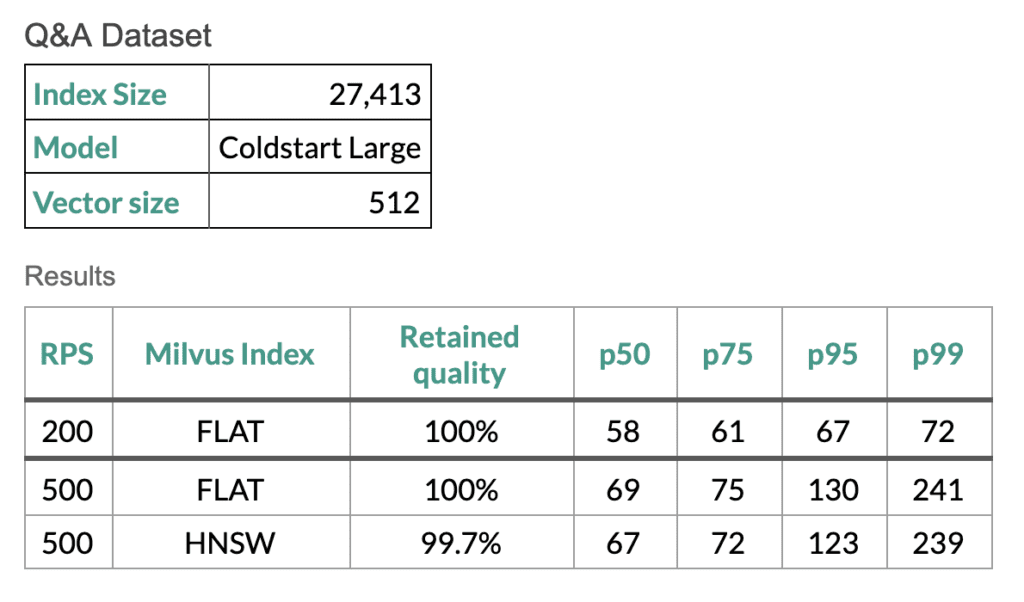
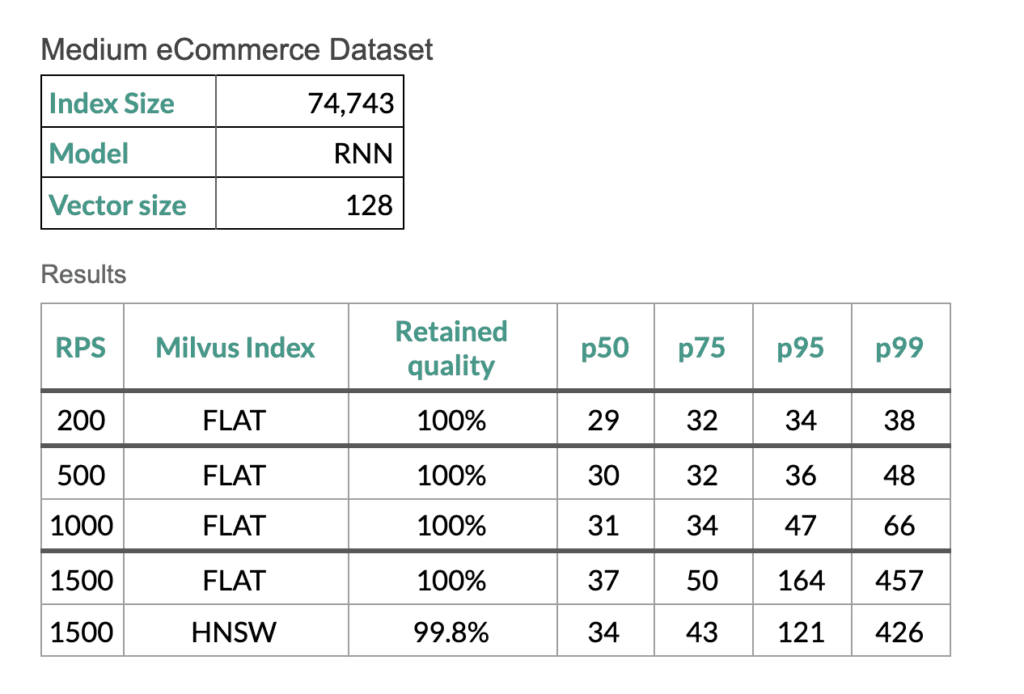
扩展测试
为了证明我们的语义检索流程的效率符合我们的客户服务要求,我们使用 Gatling 脚本在 Google Cloud 平台上进行了扩展测试,启动了 8 个机器学习模型副本、8 个查询服务副本以及一个 Milvus 实例的 Fusion 集群。测试使用 Milvus FLAT 和 HNSW 索引。FLAT 索引的召回率是 100%,但效率较低——除非数据集较小。而 HNSW 索引在保证高质量结果的前提下,针对较大规模的数据集进一步提升了性能。
[1] Lucidworks 原文: https://lucidworks.com/post/what-is-semantic-search/[2] Lucidworks Fusion 5.3 版本: https://lucidworks.com/post/enhance-personalization-efforts-with-new-features-in-fusion/[3] Milvus: https://doc.lucidworks.com/fusion/5.3/8821/milvus[4] FAISS: https://ai.facebook.com/tools/faiss/[5] GPU: https://en.wikipedia.org/wiki/Graphics_processing_unit[6] Lucidworks Smart Answers: https://lucidworks.com/products/smart-answers/
想在线与 Lucidworks 的工程师交流吗?
5/21 北京时间 1:00 AM-2:00 AM, Lucidworks 的两位讲师将线上直播分享他们如何用 Milvus 加速语义检索。报名链接:https://bit.ly/3tmDIdF (或是点击左下方的“阅读原文”跳转报名)

Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量相似度搜索引擎,以加快下一代数据平台的发展。Milvus 目前是 LF AI & Data 基金会的孵化阶段项目,能够管理大量非结构化数据集。我们的技术在新药发现、计算机视觉、推荐引擎、聊天机器人等方面具有广泛的应用。
欢迎加入 Milvus 社区
github.com/milvus-io/milvus | 源码zhihu.com/org/zilliz-11| 知乎zilliz.blog.csdn.net | CSDN 博客
space.bilibili.com/478166626 | Bilibili