




上一篇在学习安装完 GBase 8c 数据库之后,今天跟着 8c 的 GDCA 课程了解一下常见对象及函数。
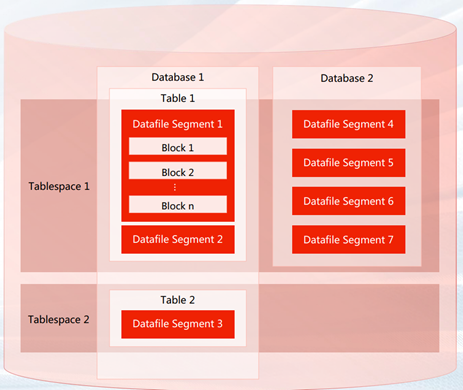
GBase 8c 常见的数据库对象如下图所示:

GBase 8c 逻辑存储结构
- Tablespace,即表空间,是一个目录,可以存在多个,里面存储的是它所包含的数据库的各种物理文件。每个表空间可以对应多个 Database。
- Database,即数据库,用于管理各类数据对象,各数据库间相互隔离。数据库管理的对象可分布在多个 Tablespace上。
- Datafile Segment,即数据文件,通常每张表只对应一个数据文件。如果某张表的数据大于 1GB,则会分为多个数据文件存储。
- Table,即表,每张表只能属于一个数据库,也只能对应到一个Tablespace。每张表对应的数据文件必须在同一个Tablespace中。
- Block,即数据块,是数据库管理的基本单位,默认大小为 8KB。
表空间

GBase 8c 自带两个表空间:
- 默认表空间 pg_default:
用来存储非共享系统表、用户表、用户表 index、临时表、临时表 index、内部临时表的默认表空间。对应存储目录为实例数据目录下的 base 目录。 - 共享表空间 pg_global:
用来存放共享系统表的表空间。对应存储目录为实例数据目录下的 global 目录。
DBCOMPATIBILITY 兼容模式:
可选值:A(默认值)、B、C、PG。分别表示兼容 O、MY、TD 和 POSTGRES。
- A 兼容性下,数据库将空字符串作为NULL处理,数据类型DATE会被替换为TIMESTAMP(0) WITHOUT TIME ZONE。
- B 兼容性下,在将字符串转换成整数类型时,如果输入不合法,B兼容性会将输入转换为0,而其它兼容性则会报错。
- B、PG 兼容性下,CHAR 和 VARCHAR 以字符为计数单位,其它兼容性以字节为计数单位。例如,对于 UTF-8 字符集,CHAR(3)在 B、PG 兼容性下能存放 3 个中文字符,而在其它兼容性下只能存放 1 个中文字符。
Schema 模式
模式是一组数据库对象的集合,主要用于控制对数据库对象的访问。管理模式的语句主要包括:创建模式、修改模式属性,以及删除模式。
- GBase 8c 使用模式 (Schema) 对数据库(database)做逻辑分割。所有的数据库对象都建立在模式下面,用户可以根据自己拥有的权限,访问数据库中一个或多个 schema 的对象。这样就使得多个用户可以使用同一个数据库而不相互干扰。
- 和数据库不同,模式不是严格分离的:只要有权限,一个用户可以访问他所连接的数据库中的任意模式中的对象。
- 相同的对象名称可以被用于不同的模式中而不会发生冲突,例如同一个数据库下名为schema1 和 schema2 的模式下都可以包含名为 table1 的表。


搜索路径
GBase 8c 默认的搜索路径为 “$user”,public。
postgres=# show search_path;
search_path
----------------
"$user",public
(1 row)
用户、角色及权限
- 用户(User):使用数据库管理系统的个体。
- 角色(Role):一组用户的集合,按照数据库系统中承担的责任划分具有不同权限的角色。
- 系统权限:又称为用户属性,包括 SYSADMIN、CREATEDB、CREATEROLE、AUDITADMIN和LOGIN等。
- 对象权限:数据库对象(表和视图、指定字段、数据库、函数、模式、表空间等)的相关权限(创建、删除、修改等)。
初始用户
GBase 8c 安装过程中自动生成的帐户称为初始用户。初始用户拥有系统的最高权限,能够执行所有的操作。该帐户与进行 GBase 8c 安装的操作系统用户同名。在第一次登录数据库后,要及时修改初始用户的密码。
-
角色是用来管理权限的,从数据库安全的角度考虑,可以把所有的管理和操作权限划分到不同的角色上。
-
用户是用来登录数据库的,通过对用户赋予不同的权限,可以方便地管理用户对数据库的访问及操作。
-- 使用 CREATE 语法创建用户并指定用户的有效开始时间和有效结束时间
create user test_1 with password 'GBase!qaz'
valid begin '2023-05-01 11:00:00'
valid until '2025-12-01 11:00:00';
gbase8c=# -- 使用 ALTER 语法重新设置有效期
gbase8c=# alter user test_1 with
valid begin '2022-12-01 07:00:00'
valid until '2025-12-01 07:00:00';
ALTER ROLE
gbase8c=# -- 使用 DROP 语法进行删除。
gbase8c=# drop user test_1;
分布式模式下的数据表分类
-
Replication 表
即复制表,各个 datanode 节点中,写入表的数据完全相同。读数据时,只需要读取任意一个 datanode 节点上的数据。一般小表或者只读表(dimension table,维度表,即描述性或静态数据表 )采用此种方式。 -
Distribute 表(默认创建方式)
即分布式表,基于指定列的 hash 值将数据完全切分到不同的 datanode 节点中,即与Replication 表相反,各个 datanode 节点中,表的数据完全不同。适用于 write-heavy tables,如事实表。
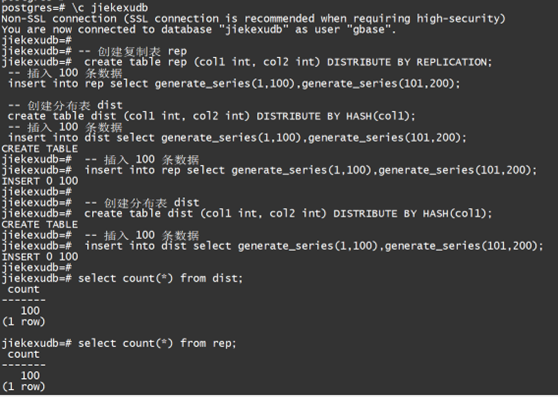
-- 创建复制表 rep
create table rep (col1 int, col2 int) DISTRIBUTE BY REPLICATION;
-- 插入 100 条数据
insert into rep select generate_series(1,100),generate_series(101,200);
-- 创建分布表 dist
create table dist (col1 int, col2 int) DISTRIBUTE BY HASH(col1);
-- 插入 100 条数据
insert into dist select generate_series(1,100),generate_series(101,200);
视图
当用户对数据库中的一张或者多张表的某些字段的组合感兴趣,而又不想每次键入这些查询时,用户就可以定义一个视图(View),以便解决这个问题。
视图与基本表不同,它不是物理上实际存在的。数据库中仅存放视图的定义,而不存放视图对应的数据,这些数据仍存放在原来的基本表中。若基本表中的数据发生变化,从视图中查询出的数据也随之改变。
物化视图是“物化”(Materialized)之后的视图,它将视图查询的结果实际存储在磁盘中,有效提升查询性能。
物化视图以类表的形式保存结果,但无法像普通表那样进行数据更新,需要使用REFRESH 从基表获取更新数据。
-- 创建物化视图
CREATE MATERIALIZED VIEW mv_rep1 AS SELECT * FROM rep;
-- 新增数据
INSERT INTO rep VALUES (2,2);
SELECT * FROM mv_rep1;
-- 刷新物化视图
REFRESH MATERIALIZED VIEW mv_rep1;
SELECT * FROM mv_rep1;
序列
序列(Sequence)是用来产生唯一整数的数据库对象,序列的值是按照一定规则自增的整数,可以看作是存放等差数列的特殊表。因为自增所以不重复,因此说 Sequence 具有唯一标识性。这也是 Sequence 常被用作主键的原因。
创建序列的同时如果指定相应的模式名,则该序列就在给定的模式中创建,否则会在当前模式中创建。序列名必须和同一个模式中的其他序列、表、索引、视图或外表的名称不同。
通过序列使某字段成为唯一标识符的方法有两种:
- 一种是声明字段的类型为序列整型,由数据库在后台自动创建一个对应的 Sequence。
- 一种是使用 CREATE SEQUENCE 自定义一个新的 Sequence,然后将 nextval(‘sequence_name’) 函数读取的序列值,指定为某一字段的默认值,这样该字段就可以作为唯一标识符。
gbase8c=# -- 创建序列
gbase8c=# CREATE SEQUENCE seq1 INCREMENT 1 MINVALUE 1 MAXVALUE 100 START 1 ;
gbase8c=# -- 指定为某一字段的默认值,使该字段具有唯一标识属性。
gbase8c=# CREATE TABLE SEQ_T2
( id
int not null default nextval('seq1'),
name text
);
gbase8c=# -- 插入数据
gbase8c=# insert into SEQ_T2 (name)
values('b1'),('b2'),('b3'),('b4');
gbase8c=# -- 查询表
gbase8c=# select * from SEQ_T2 order by id;
gbase8c=# -- 创建数据表,指定 serial 类型
gbase8c=# CREATE TABLE SEQ_T1
gbase8c-# (
gbase8c(# id serial,
gbase8c(# name text
gbase8c(# );
NOTICE: CREATE TABLE will create implicit
sequence "seq_t1_id_seq" for serial column
"seq_t1.id"
CREATE TABLE
gbase8c=# insert into SEQ_T1 (name)
values('a1'),('a2'),('a3'),('a4'),('a5'),('a6');
INSERT 0 6
gbase8c=# select * from SEQ_T1 order by id;
同义词
同义词(Synonym)是数据库对象的别名,用于记录与其他数据库对象名间的映射关系,用户可以使用同义词访问关联的数据库对象。
注意事项
• 定义同义词的用户成为其所有者。
• 若指定模式名称,则同义词在指定模式中创建。否则,在当前模式创建。
• 支持通过同义词访问的数据库对象包括:表、视图、函数和存储过程。
• 使用同义词时,用户需要具有对关联对象的相应权限。
• 支持使用同义词的DML语句包括:SELECT、INSERT、UPDATE、DELETE、EXPLAIN、CALL。
同义词创建语法:
CREATE [ OR REPLACE ] SYNONYM synonym_name
FOR object_name; -- object_name 可以是不存在的对象名称
数据类型
-
什么是数据
数据是事实或观察的结果,是对客观事物的逻辑归纳,用于表示客观事物的未加工的原始素材。 -
数据库中的数据类型
在 GBase 8c 中,数据类型是数据的一个基本属性,用于区分不同类型的数据。不同的数据类型所占用的存储空间不同,能够进行的操作也不相同。
数据库中的数据存储在数据表中,数据表中的每一列都定义了其数据类型。当用户存储数据时,需要遵循这些数据类型的属性定义,否则可能会出现报错或精度丢失等问题。在 GBase 8c 中,主要的数据类型有:
- 常用的数据类型
包括:数值类型、字符类型、日期类型等。
- 非常用的数据类型
包括:布尔类型、二进制类型、XML类型、几何类型等。
- 自定义数据类型
数值类型–整数类型
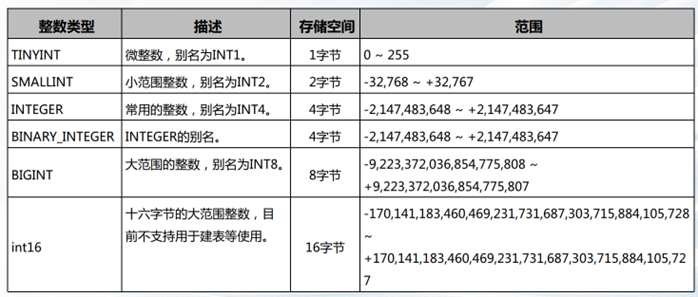
数值类型–任意精度类型
数值类型–序列整数类型
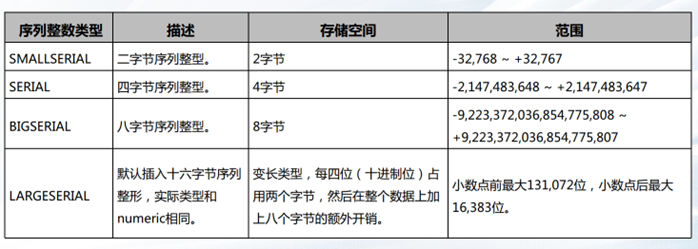
数值类型—浮点类型
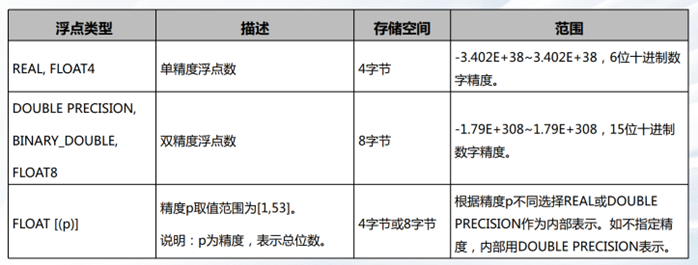
字符类型
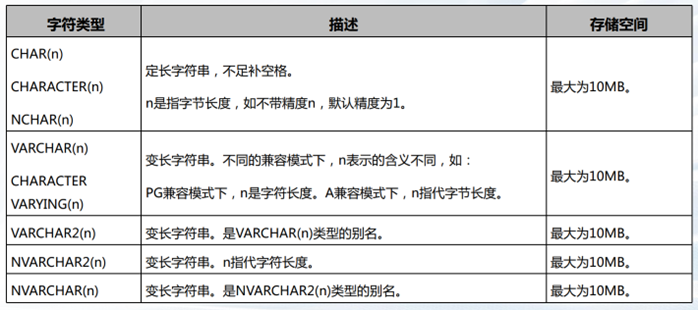
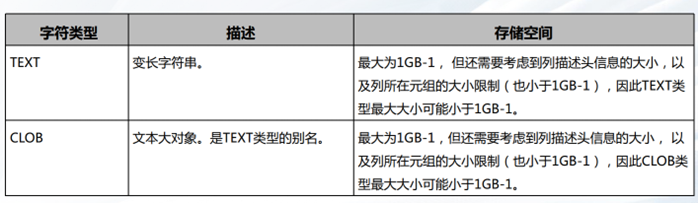
日期时间类型
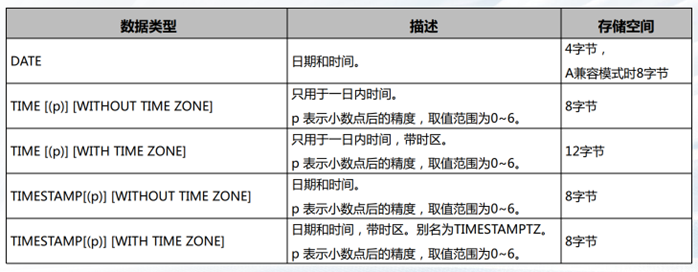

二进制类型

布尔类型
用于表示真假的数据类型。
| 数据类型 | 描述 | 存储空间 |
|---|---|---|
| BOOLEAN | 布尔类型 | 1 字节 |
- “真”值的有效文本值是:
TRUE、‘t’、‘true’、‘y’、‘yes’、‘1’ 、‘TRUE’、true、整数范围内 1~2^63-1、整数范围内 -1~-2^63。 - “假”值的有效文本值是:
FALSE、‘f’、‘false’、‘n’、‘no’、‘0’、0、‘FALSE’、false。
使用TRUE和FALSE是比较规范的用法(也是SQL兼容的用法)。
位串类型

其他数据类型
用户还可以通过 CREATE TYPE 语句创建自定义类型,支持 5 种:
- 复合类型 由一个属性名和数据类型的列表指定。复合类型本质上和表的行类型相同,但是如果只想定义一种类型,使用CREATE TYPE避免了创建一个实际的表。单独的复合类型也是很有用的,例如可以作为函数的参数或者返回类型
- 基本类型 用户可以自定义一种新的基本类型(标量类型)。通常来说这些函数必须是底层语言所编写。
- shell 类型 是一种用于后面要定义的类型的占位符。在创建基本类型时,需要shell类型作为一种向前引用。
- 枚举类型 由若干个标签构成的列表,每一个标签值都是一个非空字符串,且字符串长度不能超过63个字节。
- 集合类型 类似数组,但是没有长度限制,主要在存储过程中使用。
示例:
-- 创建一种复合类型,建表并插入数据以及查询。
CREATE TYPE test_type1 AS ( f1 int, f2 text );
CREATE TABLE t1 ( a int, b test_type1 );
INSERT INTO t1 VALUES ( 1,( 1, 'demo' ) );
SELECT (b).f1 FROM t1 ;
-- 创建一个枚举类型
CREATE TYPE test_type2 AS ENUM ('create', 'modify', 'closed');
-- 创建一个集合类型
CREATE TYPE test_type3 AS TABLE OF t1;
常见函数
SQL函数的主要分类包括:(SQL函数指的是数据库内置函数,可以运用在SQL语句中实现特定的功能)
- 单行函数(本课程主要介绍常用的单行函数)
- 多行函数
单行函数 对于每一行数据进行计算后得到一行输出结果。
-
单行函数的基本特性
- 单行函数对单行操作
- 单行函数可以写在 SELECT、WHERE、ORDER BY 子句中
- 每行返回一个结果
- 有些函数没有参数,有些函数包括一个或多个参数
- 有可能返回值与原参数数据类型不一致
- 函数可以嵌套
-
根据数据类型分为 字符函数、数值函数、日期函数、转换函数 以及其他通用的函数等。
- 字符函数:主要用于字符串与字符串、字符串与非字符串之间的连接,以及字符串的模式匹配操作。
- 数值函数:主要用于数字操纵和数学计算等操作,如绝对值、平方根、随机值等。
- 日期函数:主要用于获取系统时间,日期、时间类型的计算与格式化,如日期差值计算、日期截取等。
- 转换函数:主要用于将一种数据类型转换成另一种数据类型,常见如数值与字符类型、字符与日期类型之间的转换以及转换时的格式化方式等。
常见函数:
- ascii(string)
描述:参数string的第一个字符的ASCII码。返回值类型integer - btrim(string text [, characters text])
描述:从string开头和结尾删除只包含characters中字符(缺省是空白)的最长字符串。返回值类型:text - ltrim(string [, characters])
描述:从字符串string的开头删除只包含characters中字符(缺省是一个空白)的最长的字符串。返回值类型:varchar - rtrim(string [, characters])
描述:从字符串string的结尾删除只包含characters中字符(缺省是个空白)的最长的字符串。返回值类型:varchar - upper(string)
描述:把字符串转化为大写。返回值类型:varchar - lower(string)
描述:把字符串转化为小写。返回值类型:varchar - concat(str1,str2)
描述:将字符串str1和str2连接并返回。返回值:varchar - replace(string, substring)
描述:删除字符串string里出现的所有子字符串substring的内容。string 类型:text substring类型:
text 。返回值类型:text
l reverse(str)
描述:返回颠倒的字符串。返回值:text - substrb(text,int,int)
描述:提取子字符串,第一个int表示提取的起始位置,第二个表示提取几位字符。返回值类型:text
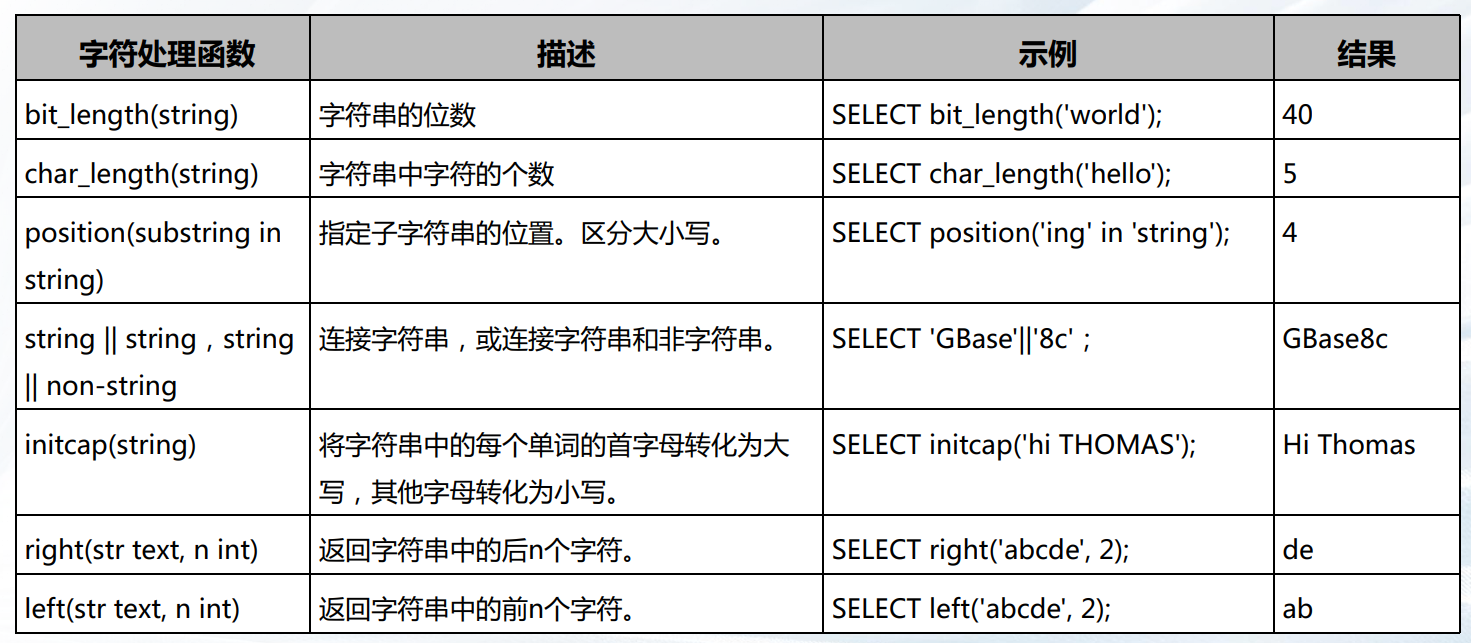
其他常用字符函数
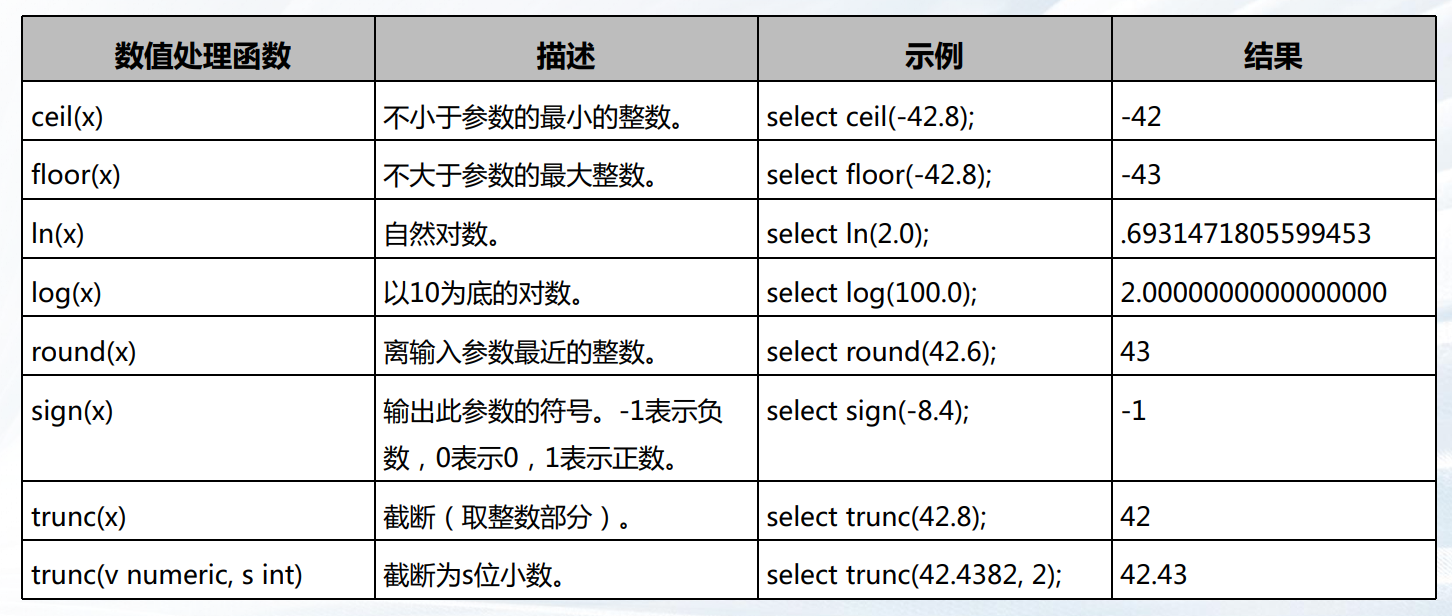
常用数值函数
- abs(exp), cos(exp), sin(exp): 返回表达式的绝对值,余弦值,正弦值。
- bitand(integer, integer)描述:计算两个数字与运算(&)的结果。返回值类型: bigint 类型数字
- acos(exp), asin(exp): 返回表达式的反余弦值和反正弦值。
- random() 描述:0.0 到 1.0 之间的随机数。返回值类型:double precision。
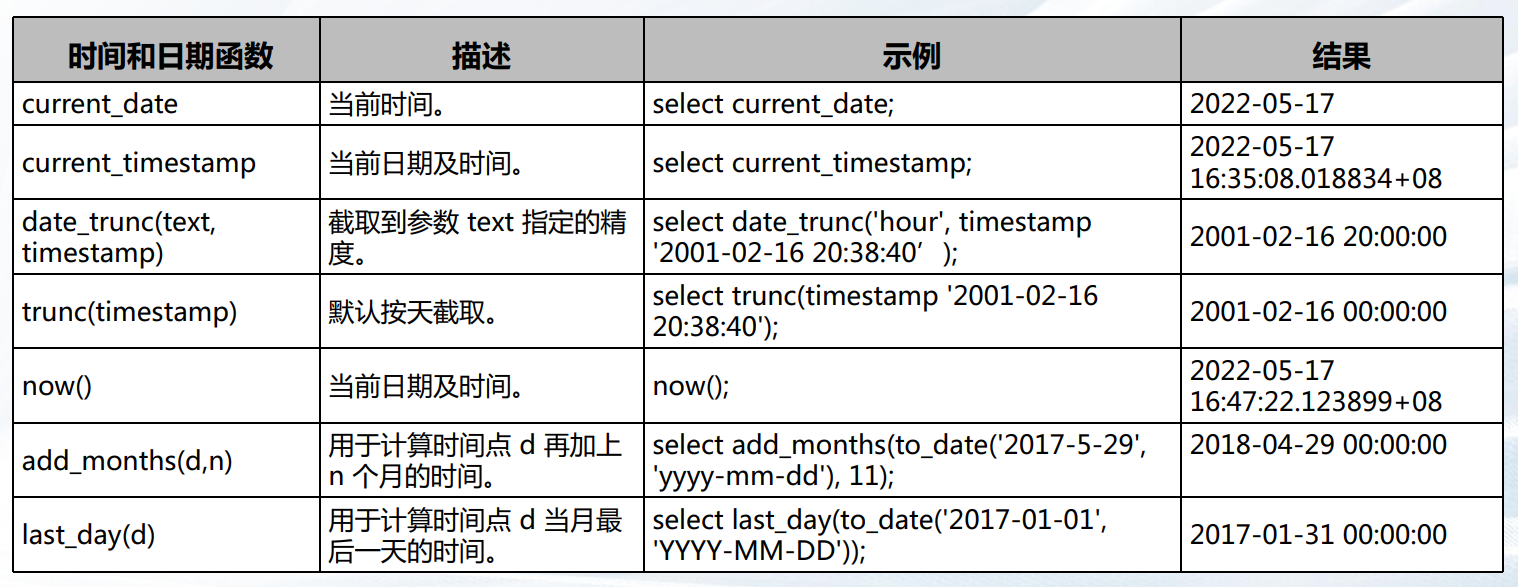
常用日期和时间函数
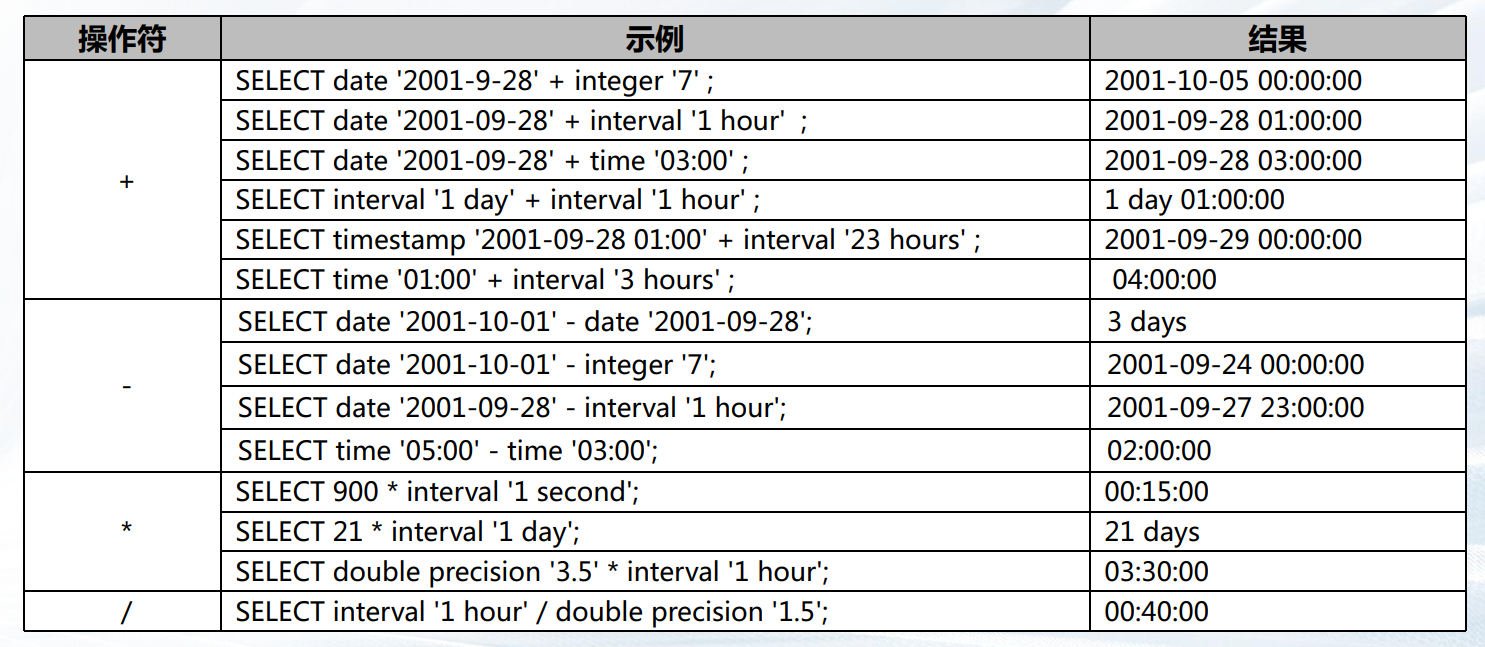
时间日期操作符–(+、-、*、/)
类型转换函数
- cast(x as y)
描述:类型转换函数,将x转换成y指定的类型。
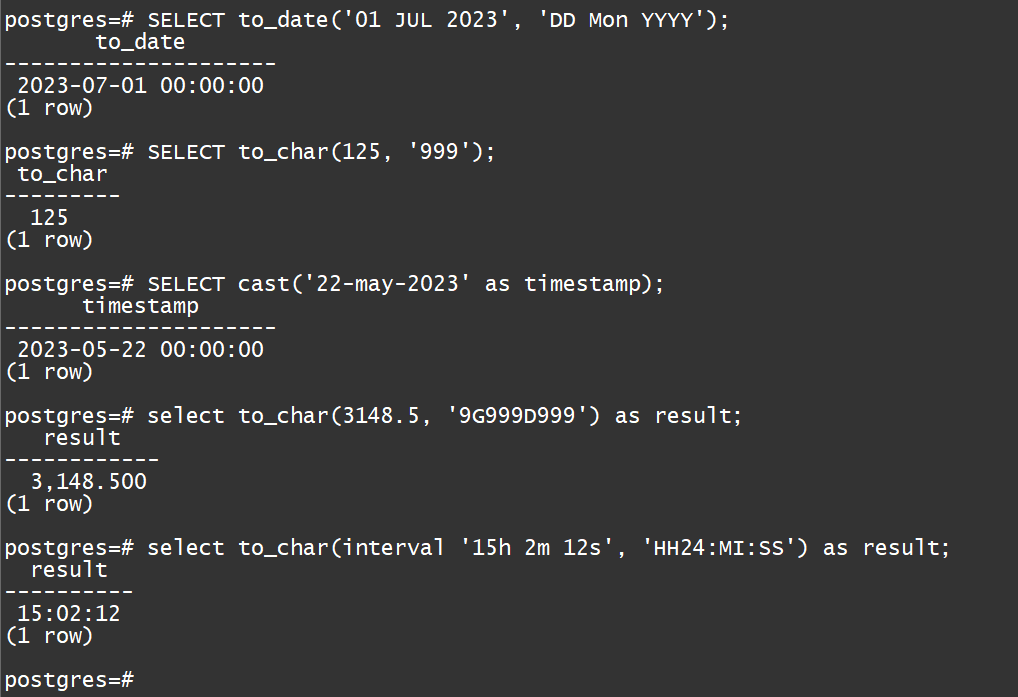
postgres=# SELECT cast('22-may-2023' as timestamp);
timestamp
---------------------
2023-05-22 00:00:00
(1 row)
- to_char(int, fmt)
描述:将整数类型的值转换为指定格式的字符串。fmt表示格式化方式。返回值类型: text
postgres=# SELECT to_char(125, '999');
to_char
---------
125
(1 row)
- to_date(text,fmt)
描述:将字符串类型的值转换为指定格式的日期。 fmt 表示格式化方式。
postgres=# SELECT to_date('01 JUL 2023', 'DD Mon YYYY');
to_date
---------------------
2023-07-01 00:00:00
(1 row)
- to_number ( expr [, fmt])
描述:将expr按指定格式转换为一个NUMBER类型的值。fmt表示格式化方式。
postgres=# SELECT to_number('12,454.8-', '99G999D9S');
to_number
-----------
-12454.8
(1 row)
- to_timestamp(text, fmt)
描述:将字符串类型的值转换为指定格式的时间戳。fmt表示格式化方式。
postgres=# SELECT to_timestamp('01 JULY 2023', 'DD Mon YYYY');
to_timestamp
---------------------
2023-07-01 00:00:00
(1 row)
- to_bigint(varchar)
描述:将字符类型转换为bigint类型。
postgres=# SELECT to_bigint('123364545554455');
to_bigint
-----------------
123364545554455
(1 row)
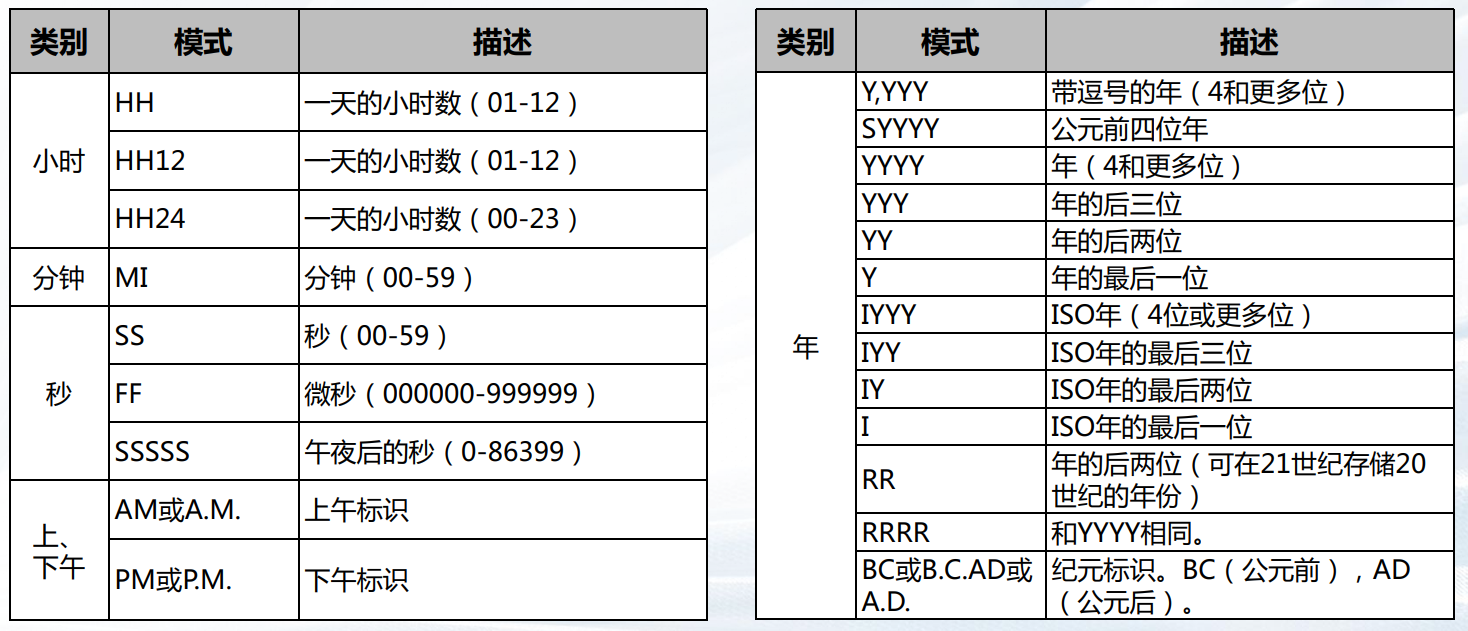
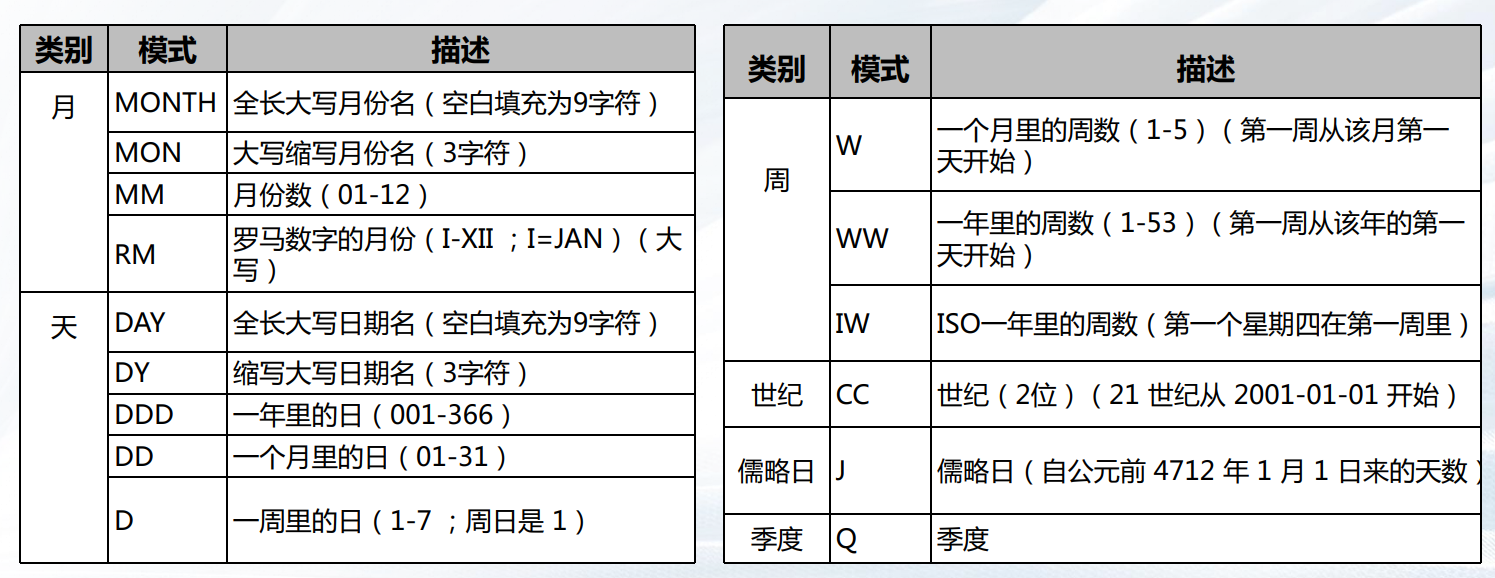
日期/时间格式化模板
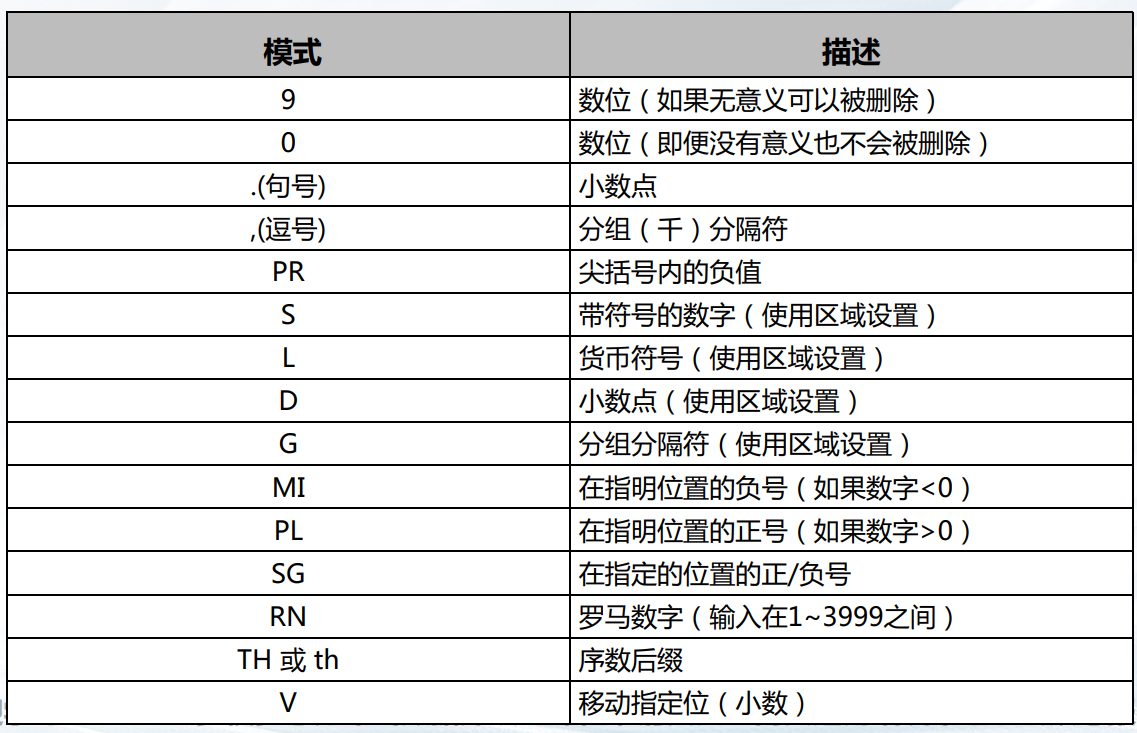
数值格式化模板
思考题:
(1)select to_char(3148.5, ‘9G999D999’) as result; 的执行结果是_______
(2)select to_char(interval ‘15h 2m 12s’, ‘HH24:MI:SS’) as result; 的执行结果是_______
全文完,希望可以帮到正在阅读的你,如果觉得此文对你有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,第一时间一起学习新知识!
————————————————————————————
公众号:JiekeXu DBA之路
CSDN :https://blog.csdn.net/JiekeXu
墨天轮:https://www.modb.pro/u/4347
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

