




点击蓝字 关注我们
大家好,我是范未太,就职于 OPPO 智能推系统算法工程团队,主要负责特征平台方面的工作。今天的分享由我和我的同事王子超共同完成。
文|王子超、范未太
编辑整理| 曾辉
讲师介绍

王子超
OPPO 高级后端研发工程师

范未太
OPPO 高级后端研发工程师
背景概况
我的主要分享内容分为两部分:第一部分是关于背景概述和平台整体架构的介绍;第二部分是关于特征平台的两个核心模块,即特征中心和样本中心,由我的同事子超进行分享。
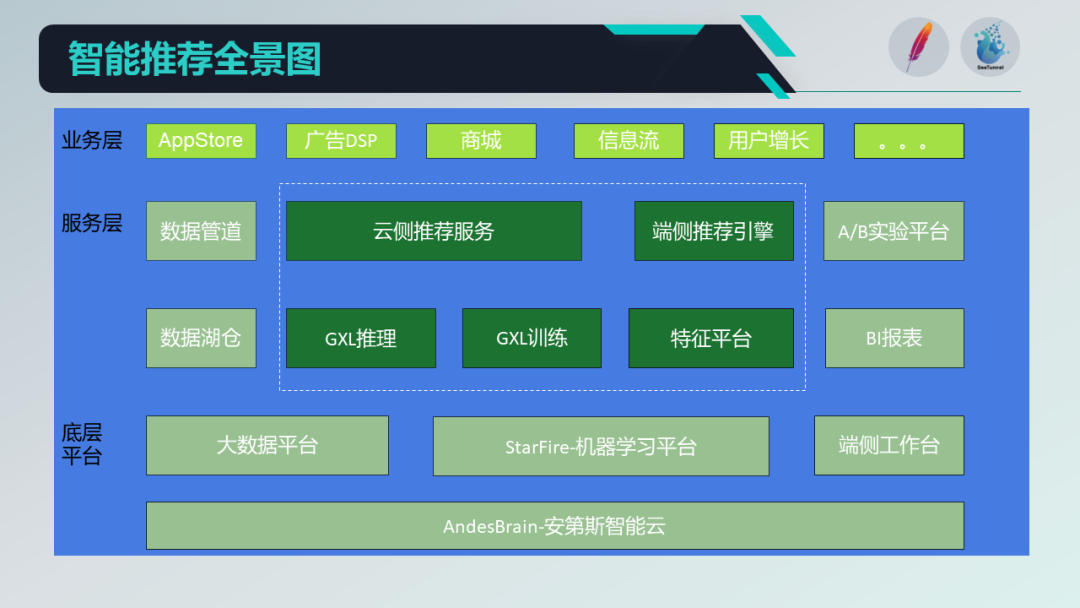
首先,让我们看一下智能推荐系统的业务全景图,它可以分为三个模块。第一个模块是业务层,涉及到 AP P的 APP Store,以及广告业务、商城业务、信息流、用户增长和搜索等等。在业务层下方,有一些服务层,比如数据管道,它的主要目的是采集和上报客户端的埋点日志数据到数据仓库中。
接下来的模块,是我们今天的主题——特征平台,它作为一种基础数据,用于特征的生产和加工,作为智能推荐系统的基础数据,包括用户画像、样本等服务,并提供给业务引擎使用。
此外,作为推荐系统,我们还有两个重要的组成部分,即实验和报表。实验用于进行不同的实验,评估其效果;报表用于展示推荐效果。整个平台以底层的大数据平台、StarFire(机器学习平台)和端侧工作台为支撑,并构建在OPPO的安第斯智能云系统之上。
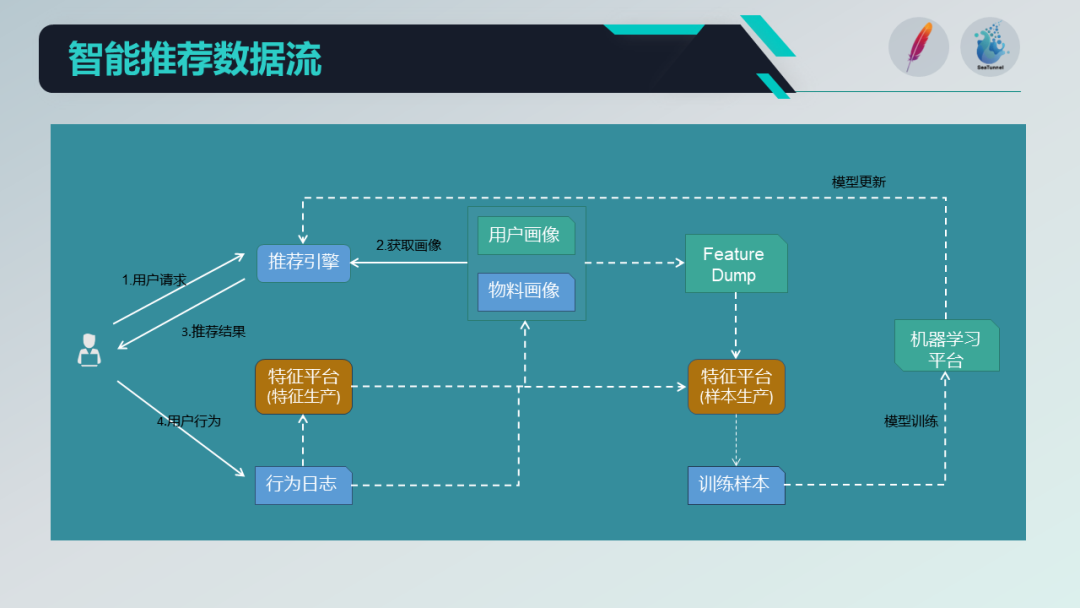
在这个平台下,我们来看一下特征平台在数据流的流转过程,以用户的请求为例。
当用户发起一次数据请求后,请求到达推荐引擎端,引擎会获取用户和物料的画像信息,并结合一些召回信息,最终将结果推送到推理服务中进行推理计算,并返回结果。
在这个过程中,我们会将用户当时的特征快照作为基本样本数据进行特征快照 dump 。此外,用户对推荐结果会做出一定的反馈,即用户行为日志。
我们采集并处理这些日志数据,一部分用作样本快照下的标签,即正反馈或负反馈的标记,另一部分用于计算用户和物料的动态画像特征,供召回或模型训练使用。
这些特征和标签与样本数据结合,作为训练机器学习模型的基础,然后将模型与推理服务结合到整个推荐引擎中,形成一个闭环的数据流。在整个系统中,特征平台数据的时效性和一致性是有一定保障的。

接下来,让我们看一下特征平台的发展历程。在早期的开发中,工具比较混乱,包括基于 MR、Spark 和 Flink 的开发,代码使用 Java 和 Python 等语言。数据格式方面也没有统一的定义,存在重复加工和复用性差的问题,时效性和数据一致性也较低。
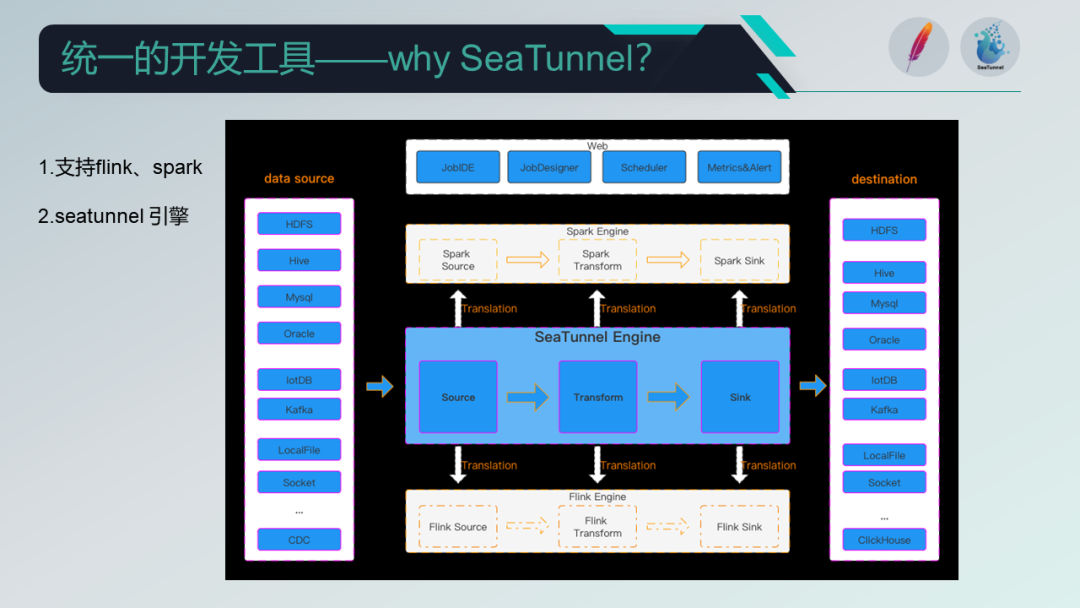
在这个背景下,引入了 Apache SeaTunnel,并结合自身需求,构建了特征平台和样本平台。当前,我们的开发工具统一、数据格式一致,并提高了数据的时效性和一致性。
接下来,让我们来看看 Apache SeaTunnel 的优势以及为什么选择它。
Apache SeaTunnel 早期版本已经支持主流的数据引擎如 Flink 和 Spark ,并在数据处理和计算方面具有较高的优势,而且拥有活跃的社区支持。
此外,Apache SeaTunnel 还推出了自己的引擎,专门用于数据集成。
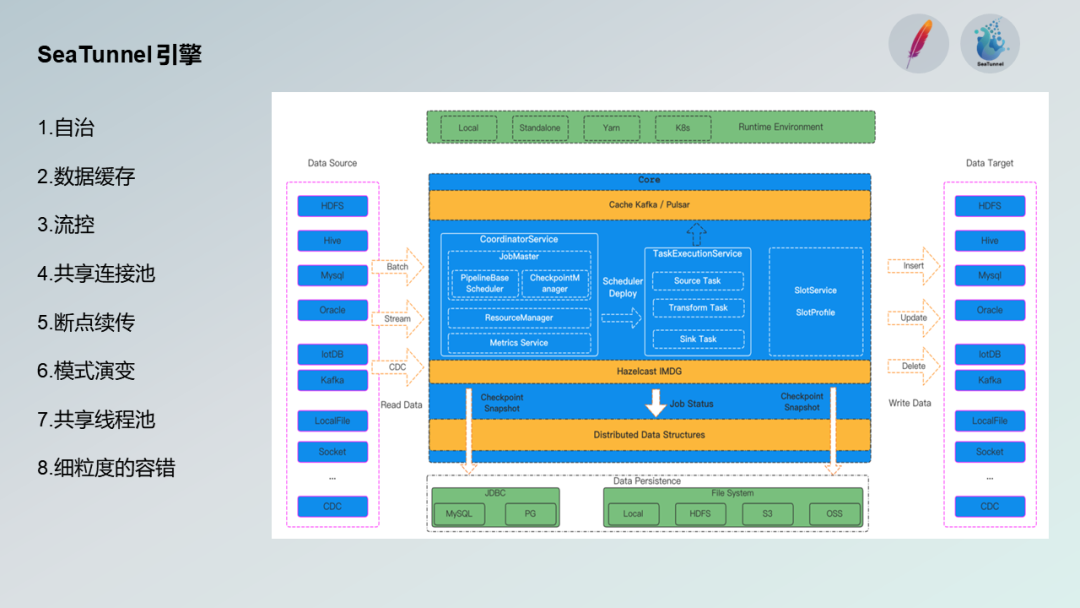
大数据的 Spark 或 Flink 引擎在某些场景下对于数据集成或数据同步存在一定的缺陷,因此 SeaTunnel 设计了自己的引擎,实现解耦。不强依赖于 Spark 或 Flink ,让用户有更多的选择。
另外,通过共享线程池和连接数,减轻了对 Source 和 Sink 服务端的压力,并提高了利用效率。SeaTunnel 还在引擎内部实现了缓存技术,例如提前缓存过期的 Source 数据,供多个 Sink 使用,同时在 Sink 出现问题时,通过细粒度的容错技术确保高效的处理能力。
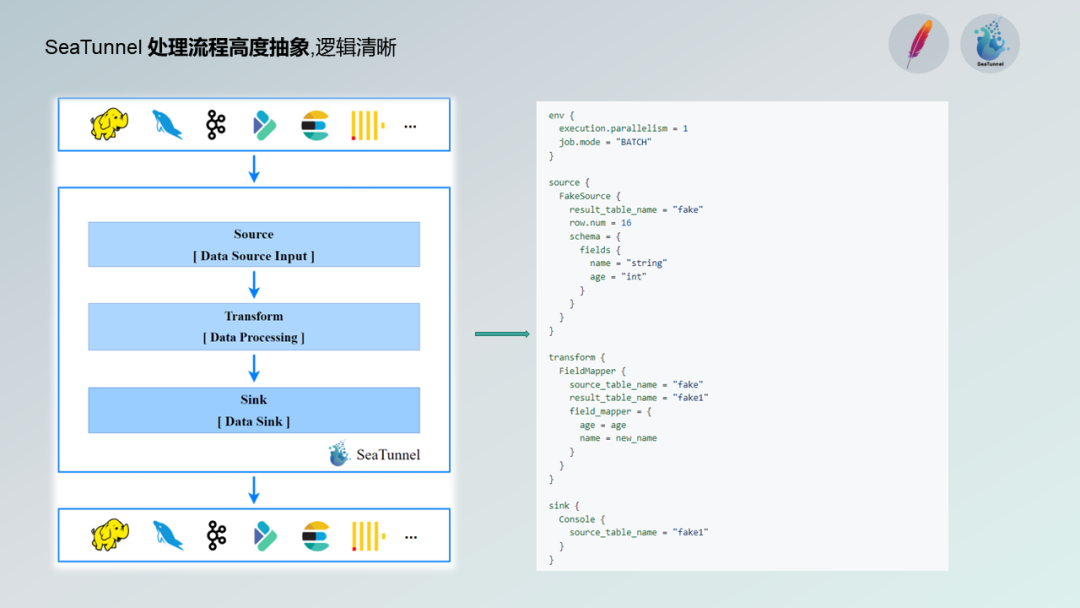
此外,Apache SeaTunnel 的流程抽象度高,逻辑清晰,使得未知人员对其理解成本低,便于上手。通过 Source、Transformer 和 Sink 这三个顶级抽象组件的配置,可以进行任务的开发。
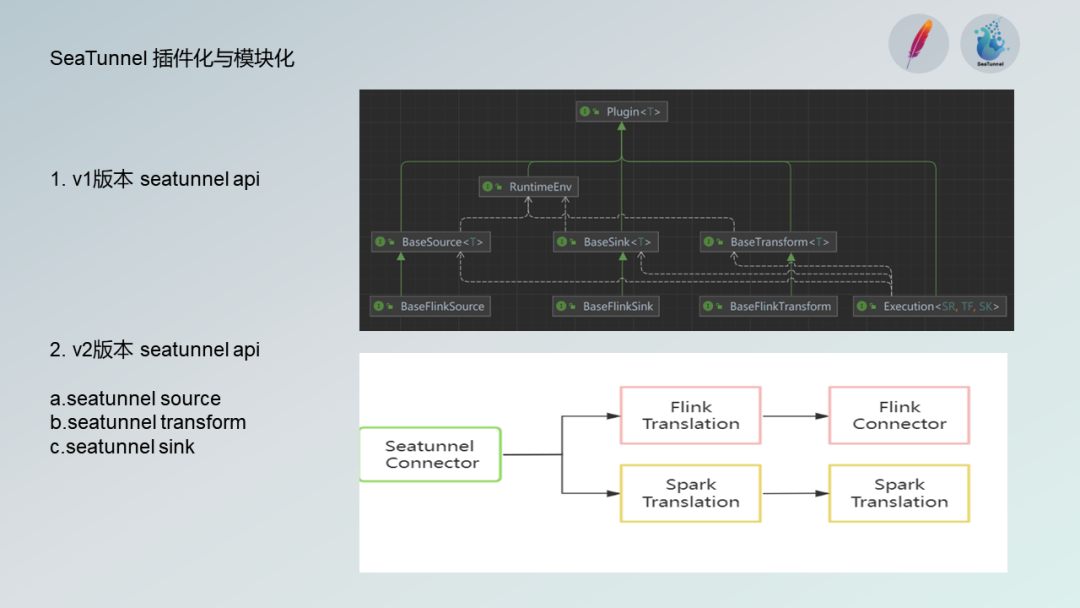
SeaTunnel 还具有模块化和插件化的特点,便于集成和扩展。在V2版本中,SeaTunnel 推出了自己的 Source、Transformer 和 Sink 组件,并解决了插件扩展和引擎版本适配的问题。
当前版本已经适配了Flink和Spark等主流版本。
特征平台-整体架构
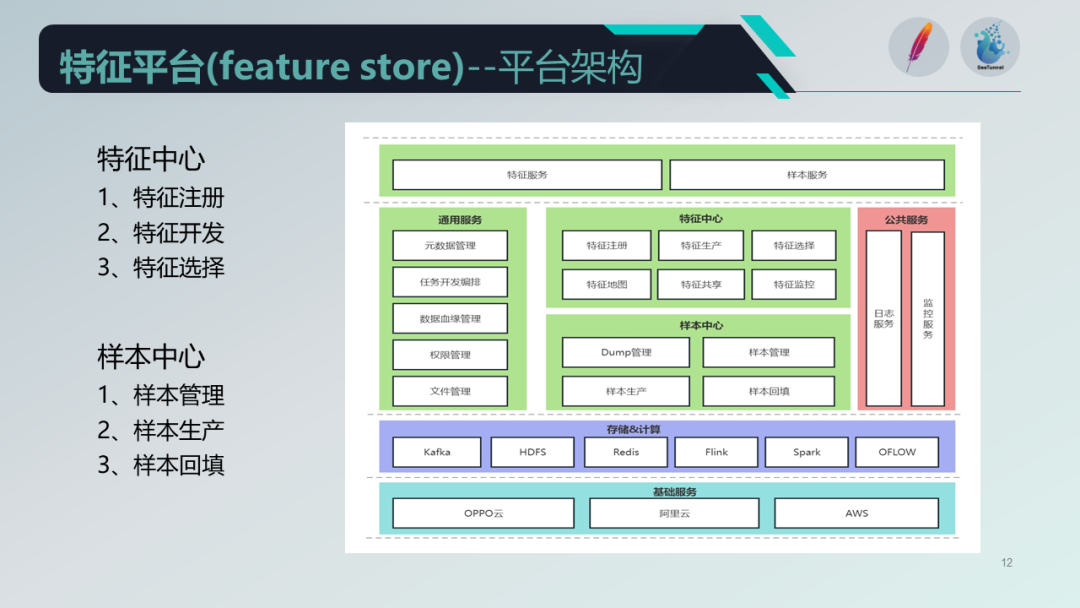
回到我们的特征平台整体架构,以 Apache SeaTunnel 为基础,核心服务分为特征中心和样本中心。另外还有一些通用服务,包括业务 Schema 源数据管理、任务编排的开发模式和任务流之间的血缘管理以及权限管理等。
特征中心主要负责特征的注册、生产、选择(评估特征好坏)、特征地图和特征共享,避免重复生产,用户可以通过特征共享功能复用特征。
样本中心负责样本的存储管理、样本生成和抽取,以及样本回迁,在新增特征或实验时尤为重要。

公共服务包括日志服务和贯穿整个开发中心的监控体系,并依托大数据存储、计算和调度系统构建在以OPPO云为中心的安迪斯智能云之上。
在特征开发方面,我们沿用了之前的 Source 和 Transformer 的高度抽象处理流程,并集成了 Apache SeaTunnel,通过配置的方式进行开发。我们采用 Flink 的 Table SQL 方式,更便于源数据的管理。
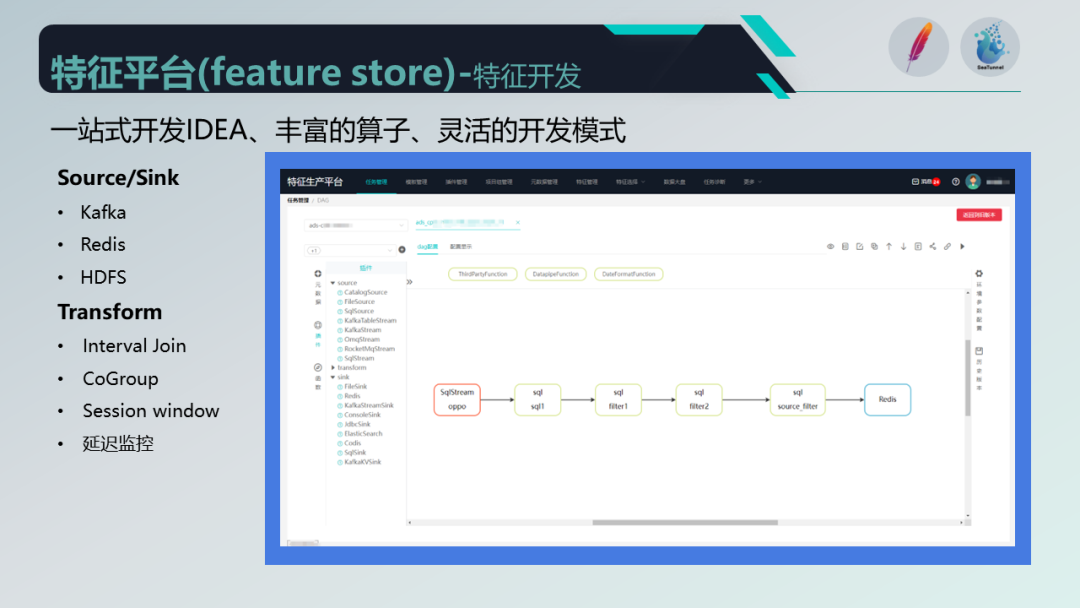
此外,我们提供了前端的配置化和可视化方式,作为一站式的IDE,提供丰富的算子和灵活的分发模式,包括常见的 Kafka、Ranks、HDS 等 Source 和 Sink 算子,以及 Transformer 等适配算法,例如 Interval Join、CoGroup、Session Window 等自定义组件和延迟监控。
此外,我们还提供了插件管理和版本管理的方式,用户可以上传自己的插件,并通过源数据和Transformer结合元数据快速生成任务,以满足特征生产需求。
为了满足特征加工的需求,除了自定义插件外,我们还引入了 Hive 。这主要是因为许多用户对 Hive 较为熟悉,并且已经迁移了一些使用 Hive 的功能。通过改写 Hive 模块并结合白名单方式,我们实现了在 Flink 中使用 Hive 函数的能力,使得用户可以无缝使用 Hive 函数在 Flink 中进行开发,而无需额外设置模式等。
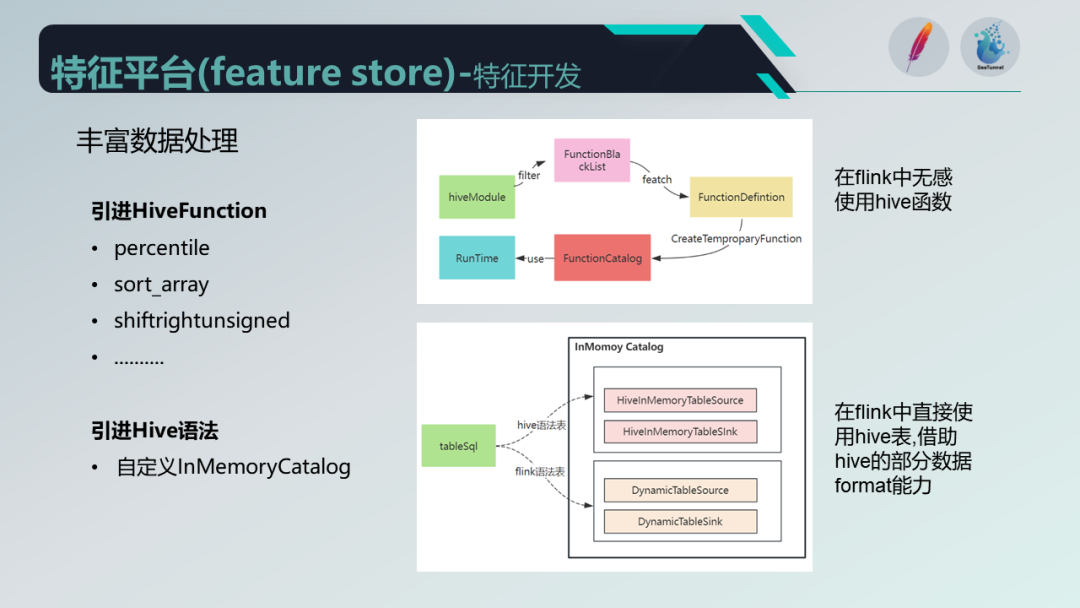
除此之外,我们还引入了 Hive 的语法,对 Source 和 Transformer 中建表的 Cantolog 进行了改写,目的是在其他地方创建的Hive表可以直接使用,并且通过内存化的方式管理表的 Schema ,减少对 Hive Meta Store 的访问。
同时,借助于 Hive 的一些数据 Meta 能力,如 ORC、CSV和Sequence 等,具有较强的压缩和优化能力。
总的来说,我们结合了 Apache SeaTunnel 和 Hive 的优势,提高了特征平台的开发和生产能力,同时实现了配置化和可视化的开发方式,为特征的注册、生产和加工提供了便利。
这就是我们特征平台的整体架构和发展过程。
特征平台-样本中心
各位下午好,我是王子超,与范未太在同一个团队。接下来我将为大家介绍我们特征平台的特征中心。我们的通用平台主要分为两个部分:特征中心和样本中心。特征中心负责特征的注册、生产、选择和共享,而样本中心则负责样本的存储管理、生成和回迁。
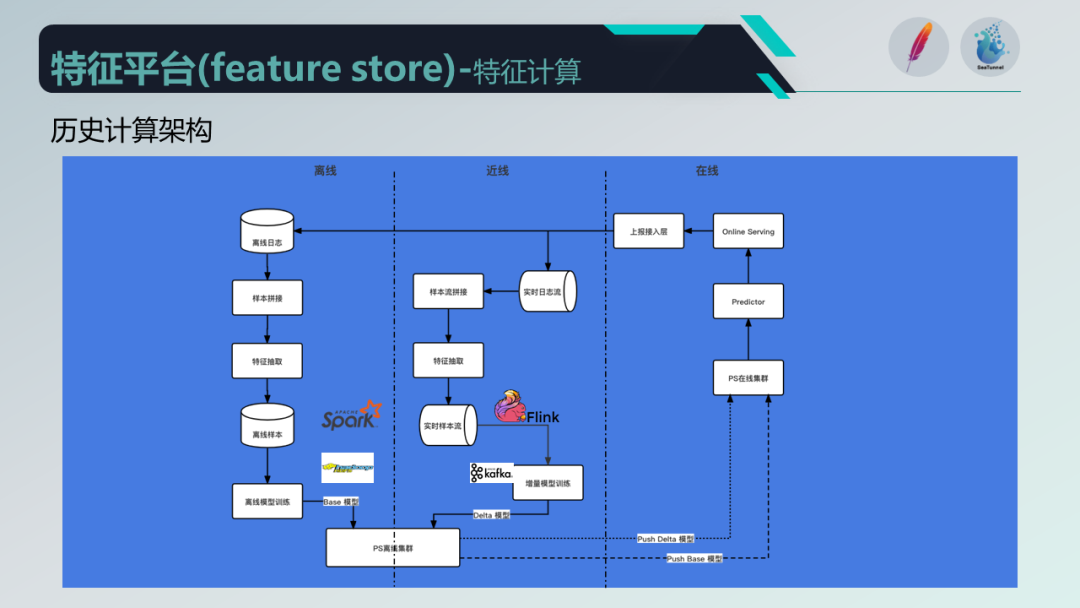
我们先来看一下特征中心的计算架构。该架构分为三部分:在线、近线和离线。在线部分主要是特征推荐引擎的在线服务;近线部分是实时流,使用 Flink 作为计算引擎,Kafka 作为消息组件;离线部分使用 Spark,HDFS 作为数据存储。
然而,这种架构存在两个问题:一是运维上的压力较大,需要维护两套计算逻辑;二是进线和离线存在数据差异的风险,可能影响推荐效果。
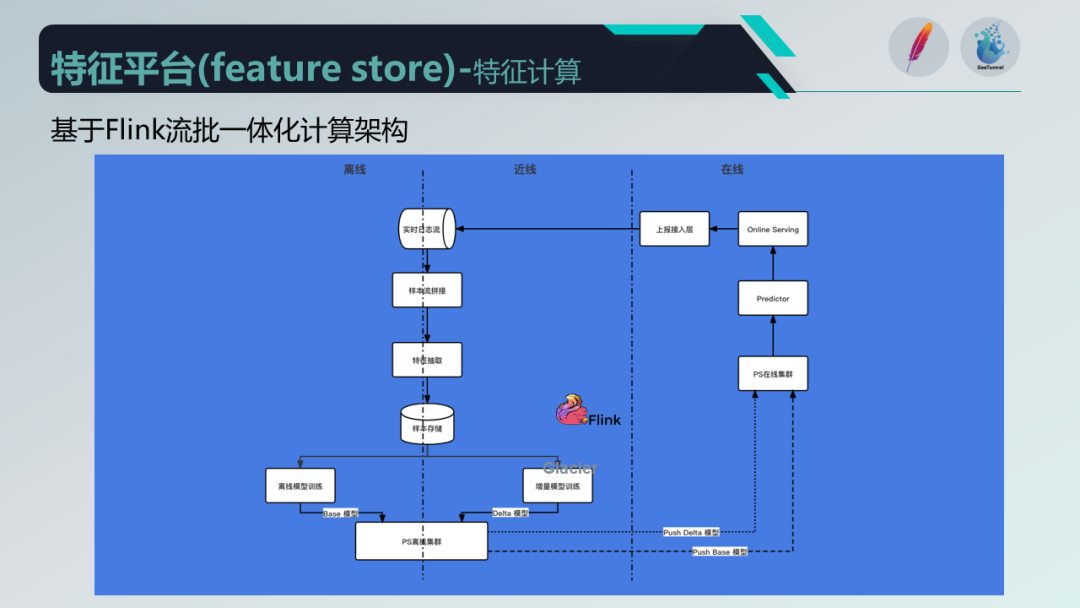
为了解决这些问题,我们选择了使用 Flink 作为技术底座,实现流批一体化的计算架构,统一使用 Flink 处理近线和离线。这样一来,离线和近线的逻辑可以复用同一套代码,运维也更加方便,同时减少了近线和离线数据差异的风险。
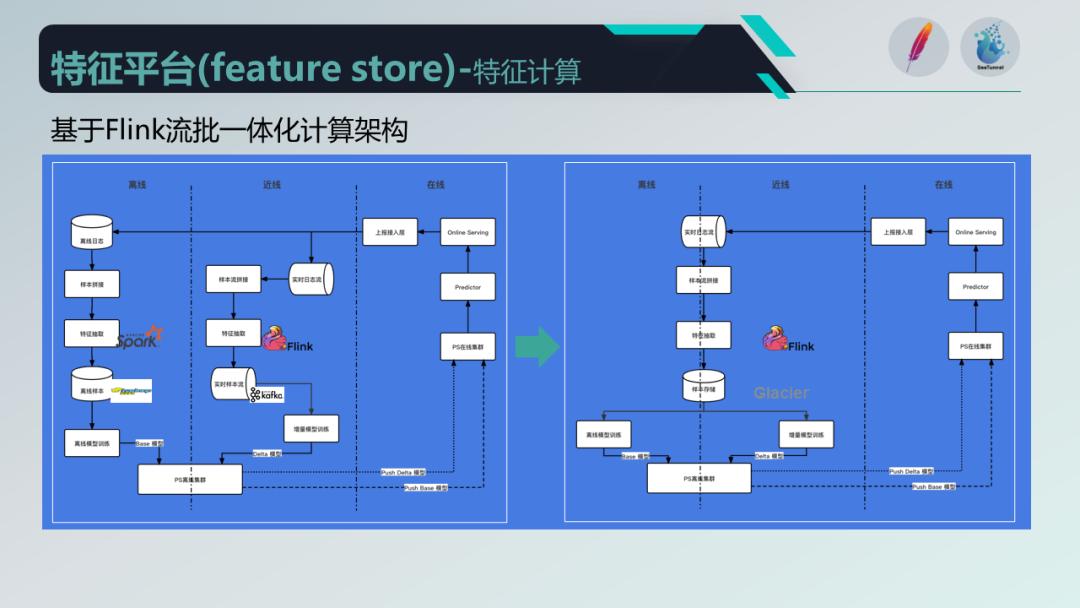
接下来,让我们来讨论特征的存储。
特征经过计算后需要存储到设备或 Redis 中供线上使用。存储分为离线存储和在线存储两部分。离线存储使用 HDFS,而在线存储主要是针对实时特征,我们使用 Redis 作为存储引擎。
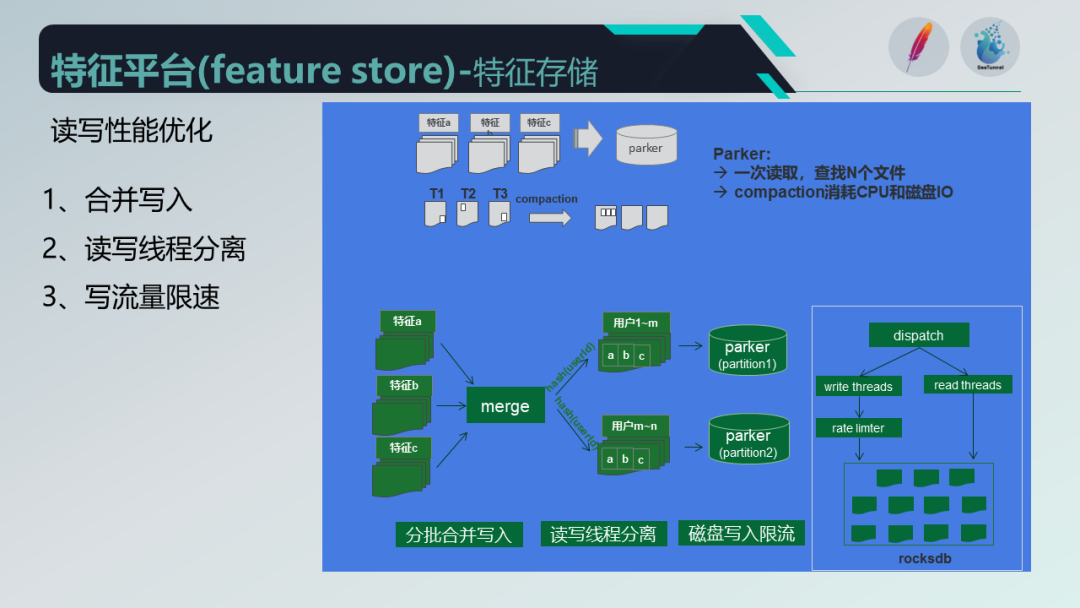
对于离线特征的存储优化,我们采用了合并写入的方式,并采用读写线程分离和限速措施来提高读写性能。此外,我们还自研了一个 Parker 存储引擎,以 RocksDB 作为内存存储和文件系统存储,相比 Redis 存储,成本降低了30%以上。
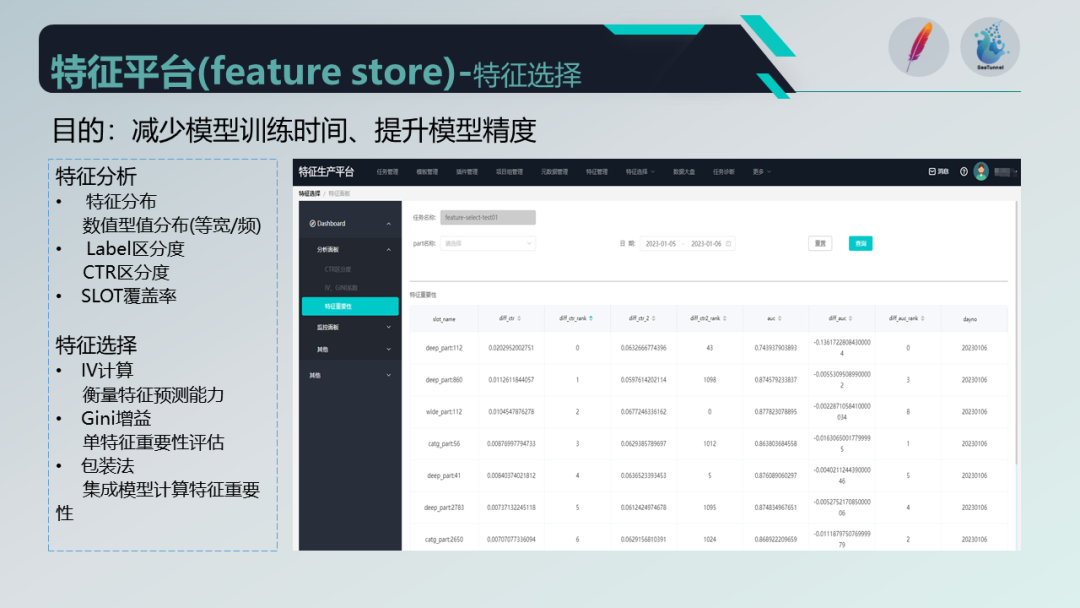
特征生成后,并不会立即投入线上使用,而是需要算法团队对特征进行选择和评估,以确保特征对模型的建模有区分度和贡献度。我们的平台提供了特征选择的功能,可以进行特征的评估和重要性排序,并通过报表或折线图呈现给算法团队。同时,对于线上使用的特征,我们还提供了一些监控和分析手段,如 label 的区分度和覆盖率监控。
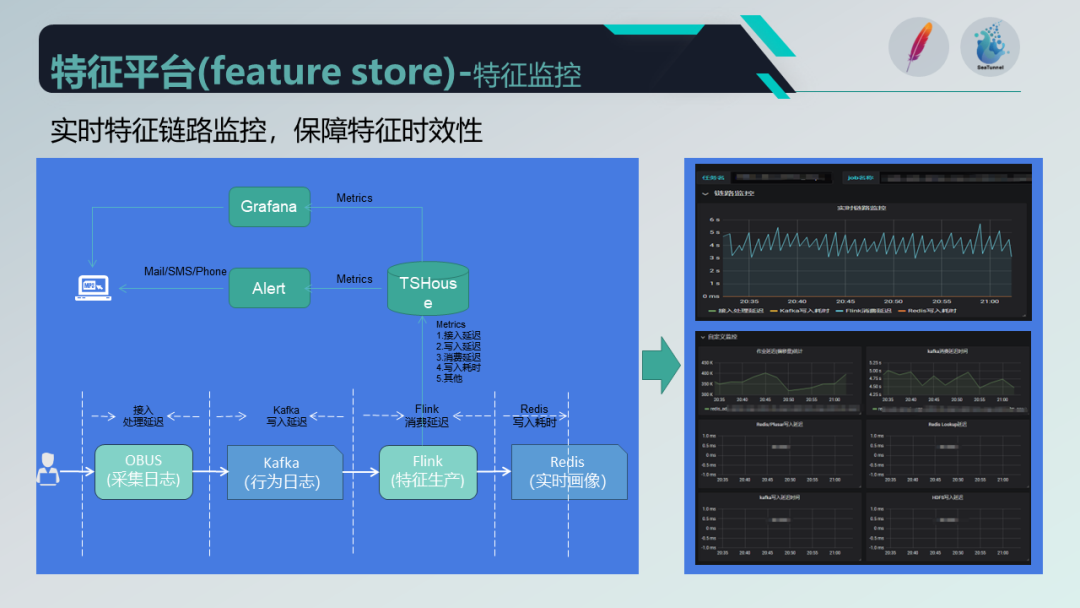
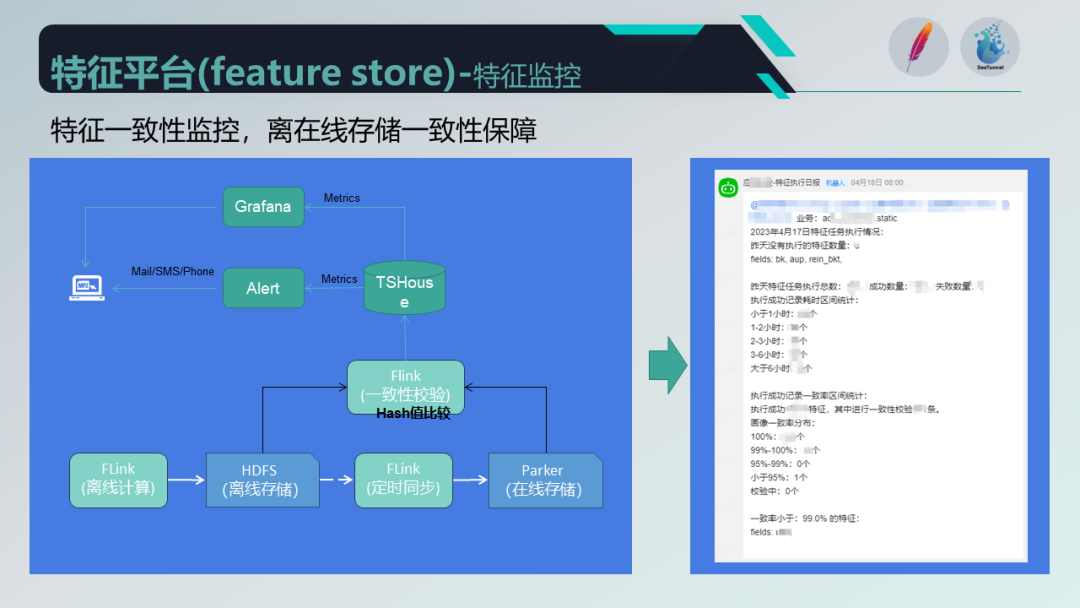
为了保障特征的时效性,我们采取了一系列的监控告警措施。在数据链路中,我们使用 Obus 进行标准化采集,并在任务链路中添加通用的监控埋点,如 Kafka 消费延迟和数据处理消费延迟等。

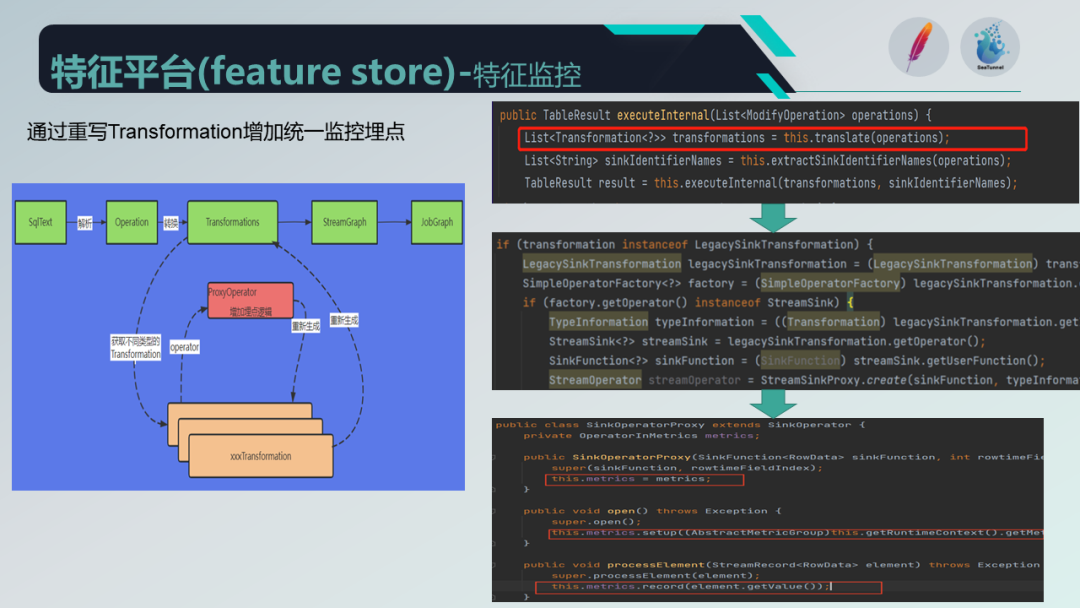
监控指标上报到 TShouse ,并通过 Grafana 形成报表,同时针对关键节点采取告警策略,及时发送给相关人员。特征监控分为通用监控和基于任务的监控,我们通过重写 Flink 架构中生成任务前的 transformation 来添加统一的监控埋点。
另外,针对离线特征的一致性保障,我们提供了一致性校验功能,通过比较哈希值来确保离线和在线存储的一致性,并将校验结果推送给相关人员。
04
特征平台-样本中心

在样本中心方面,样本的生成是将用户的行为日志和画像特征结合,经过一系列处理生成训练样本的过程。
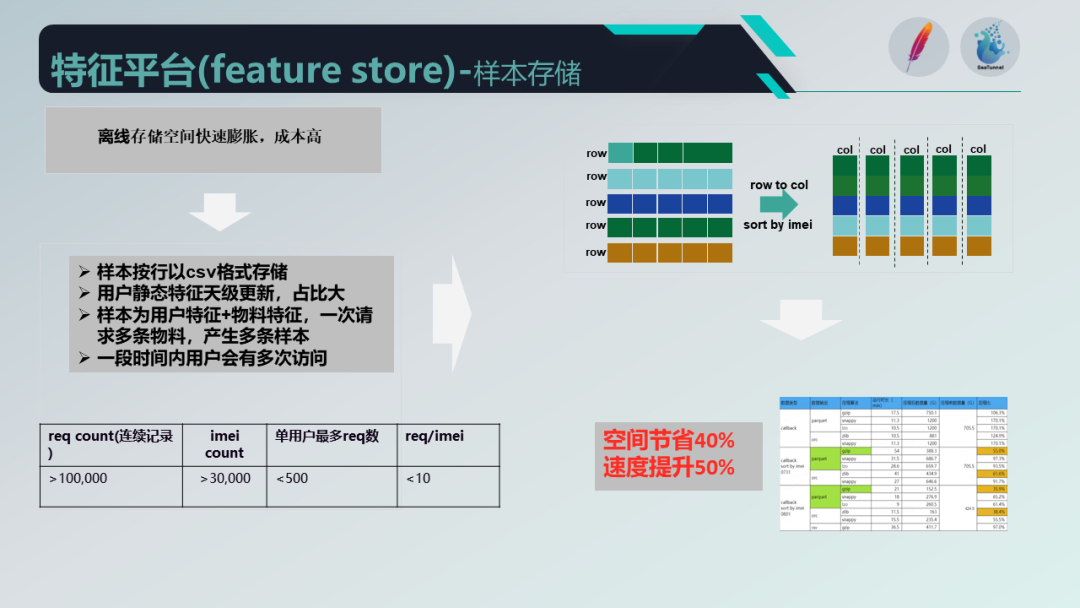
我们优化了样本流程,将存储转为列存并进行压缩和排序,节省了存储空间并提升了读写速度。
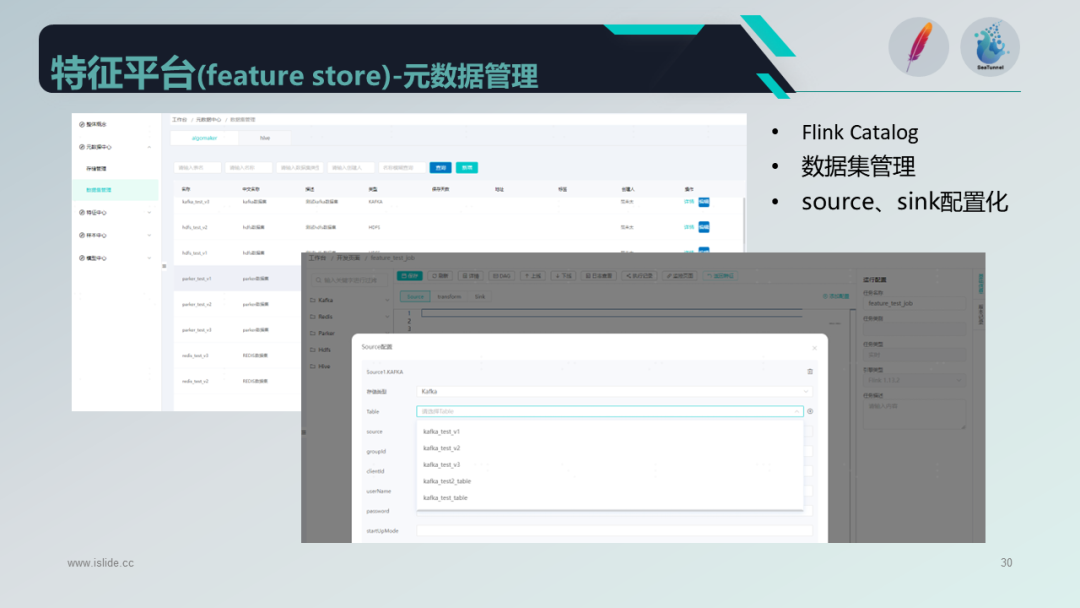
此外,我们还通过 Flink 的 Catalog API 开发了数据集管理功能,用户可以注册数据源并构建数据任务,简化了开发流程。
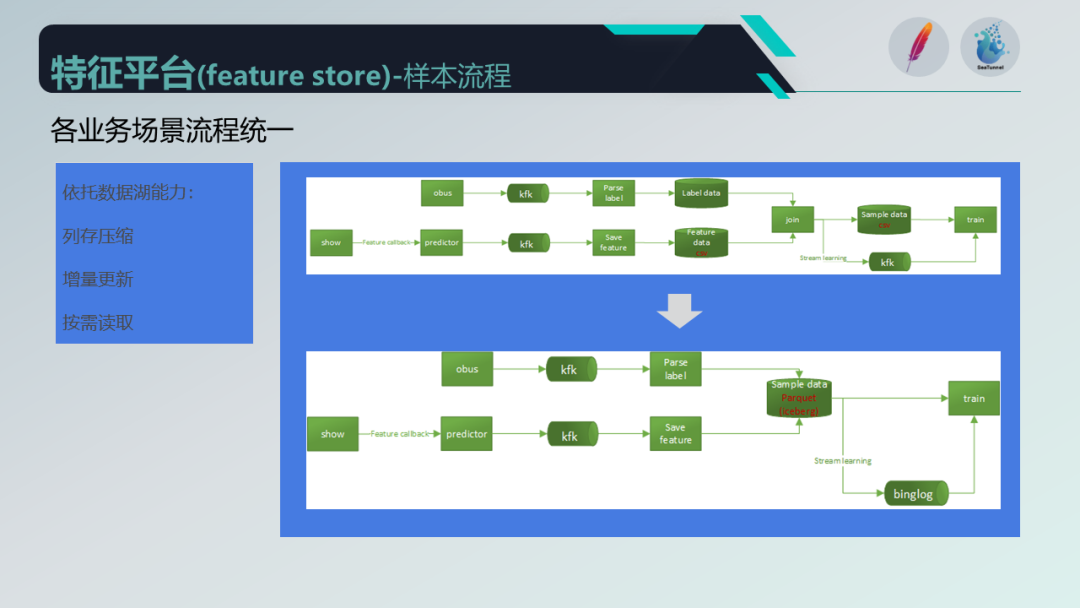
样本数据溯源方面,我们引入了数据湖的能力,优化了样本流程并保证稳定性。
未来规划
最后,我们对特征平台进行了三点规划:
深耕源数据功能,实现细粒度的数据溯源能力;
提供多引擎、多模式的开发体系,满足用户不同的需求;
探索与ChatGPT的结合,通过聊天对话方式实现特征生成和样本生成的整个流程。
以上就是我们的分享内容,谢谢大家!
Apache SeaTunnel
精彩推荐
点击阅读原文,点亮Star⭐️!

