




性能调优
目标
虎啸欲归山,玉兔探头来。 He3Proxy年内规划的功能性开发任务已接近尾声,目前重要任务是提升性能,性能目标也很明确,通过中间件能将读性能扩展至百万QPS,同时写性能达到10WTPS。
性能分析工具
因为He3DB是一主多从的架构,只有主节点能执行写操作,因此通过中间件写性能势必下降,中间件要尽量减少损耗量;读操作同样要控制损耗,并做好负载均衡;性能分析还需从实际出发,理论分析代码很难找到瓶颈点,首先介绍几款GO语言常用的监控工具:
这是一款不错的开源监控平台,代码集成很方便,支持pull、push两种模式,能统计cpu、锁、协程等耗时情况,并有UI页面展示火焰图等,方便发现性能瓶颈点,详细使用介绍可以参看产品文档;
- go pprof
原生的GO语言分析工具,再配上Graphviz分析工具,可以很容易的生成cpu调用耗时图;
借助以上两款工具(其实两种的数据源是一样的,只是展示形式不同,用好一种就可以了),可以很容易的找到性能瓶颈点。
测试环境
环境准备,为完成测试协调了几台高性能的物理机,机器配置如下,可以看到机器配置真的很高^_^;压测工具使用sysbench,数据量为50张表,每张1000W数据,
| IP | 角色 | Cpu | Mem(G) |
| 101 | Master | 96 | 754 |
| 123 | Slave | 96 | 377 |
| 124 | Slave | 96 | 377 |
| 125 | Proxy/Sysbench | 96 | 377 |
主节点性能测试
| 脚本 | QPS | TPS | 并发(threads) |
| oltp_point_select.lua | 766467.40 | 766467.40 | 256 |
| oltp_read_only.lua | 459933.33 | 28745.83 | 256 |
| oltp_update_index.lua | 245152.26 | 245152.26 | 256 |
| oltp_update_non_index.lua | 262541.35 | 262541.35 | 256 |
| oltp_write_only.lua | 558844.79 | 93128.40 | 256 |
He3Proxy配置一主两从,初次测试,测试场景为oltp_read_only,QPS仅仅18W左右,还不到单机的一半,这么大的损耗耗在哪里了?带着震惊与心慌通过性能工具进行分析,当时忘记截图了,总之通过火焰图发现一些函数执行耗时较多,可以将这些耗时问题归为三类。
一是代码规范性问题:比如Log日志输出时大量使用fmt.Sprintf,并且没做日志级别判断,导致虽然设置日志输出级别,但日志语句仍会执行耗时;再如字符串对比时使用strings.ToUpper/ToLower等,通过日志输出前进行级别判断、减少strings工具类的使用等,将这部分耗时优化,QPS约提升2-3W。
if golog.GetLevel() <= golog.LevelDebug {
golog.Debug(moduleName, "xx", fmt.Sprintf("%d", c.configVer), c.connectionId)
}二是gc频繁及锁机制,因为He3Proxy需要接收后端数据库返回的数据,Proxy需要按条解析数据包长度,循环读取所有的消息,循环内每次读取消息时会存在make slice的操作,因压测消息量较大,导致slice频繁创建、扩容、回收等,gc频繁,耗时较多;通过预创建公共slice,并预留较大cap,以解决频繁创建、扩容的问题,从而降低gc频率,也算是一种空间换时间的思想;另外关于锁的优化尽量去除不必要的锁或者减少锁的范围,并将锁的类型分为读锁、写锁等,减少锁对读性能的影响;通过上述两种优化,QPS提升至33W左右,依然很低,目前的耗时主要集中在网络io的操作上,我把这个问题归结为第三类。
三是系统调用类耗时,如epollwait路径耗时以及syscall;这部分困扰我较长时间,也是最难优化的一部分。众所周知,go语言在网络通信上做了大量优化,net包采用epoll方式处理请求,能使用户像使用阻塞IO的方式一样使用非阻塞方式,编程更简单、更符合逻辑,加上轻量级的协程能够轻松支持百万级并发,我测试并发还不到千级为什么epollwait耗时如此之多?起初我误认为pprof中epollwait是cpu阻塞时间,怀疑是否为等待数据库操作的返回耗时,后来研究发现epollwait时间应该指整个请求链路执行的时间(这里思路偏差耗费不少时间)。
进一步聚焦,发现耗时主要在proxy与数据库通信方面,最初为减少开发量proxy使用了pgx作为与后端数据库建立链接的桥梁,并使用pgx建立的TCP链接通道进行数据通信;并且在通信包读取和发送时已经采取预读,并且写操作进行了合并处理,网络io次数已经尽肯能的减少,并且流量远没达到网卡带宽的上限,那会不会tcp通信本身的瓶颈呢?随后想到零拷贝,通过减少内核态与用户态的数据拷贝,大幅提升性能,搜索发现字节开源的netpoll库相对net库实现了网络通信的零拷贝API操作,举手无措之际决定放手一搏,将proxy与数据库这部分链接通信方式由pgx改为netpoll链接,相当于对proxy做了一次大手术,改造完成后测试结果很惊喜:
| 脚本 | QPS | TPS | 并发(threads) |
| oltp_point_select.lua | 968556.57 | 968556.57 | 1024 |
| oltp_read_only.lua | 455039.90 | 28439.99 | 768 |
| oltp_update_index.lua | 242938.26 | 242938.26 | 256 |
| oltp_update_non_index.lua | 259854.04 | 259854.04 | 256 |
| oltp_write_only.lua | 463095.33 | 77172.24 | 256 |
点查结果近百万,写操作损耗控制在17%左右,相对之前已有较大提升,但是离单节点叠加的结果还是有不少差距,并不能通过中间件实现翻倍的效果,此时分析cpu耗时,基本集中在proxy向客户端的写操作,系统调用的cpu消耗较多,目前也在想这部分是否也能进行零拷贝操作, 还没有较好方案;
同时中间件部署节点配置与数据库节点相同,中间件内部还有一些处理逻辑,已经达到了机器资源瓶颈;另外也使用nginx对三台节点进行负载转发,测试点查,QPS能达到115W左右,nginx性能确实优秀,但也没能实现翻倍,也受限于机器资源及网络损耗,不过C语言编程性能确实优于GO不少。
后又经过反复测试,在机器节点状态较好的情况下勉强能达到百万 ,另外机器配置较高,数据库处理读数据操作基本属于内存操作,延时相对较低。
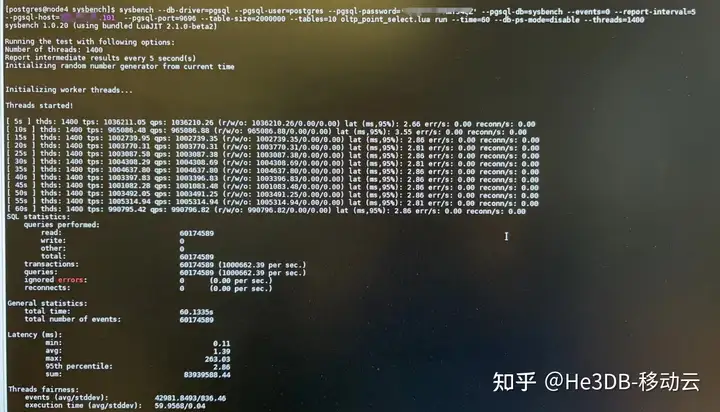
高可用下进一步测试:将集群调整为1主三从四台机器,部署两个proxy,每个proxy转发至两个读节点,同时通过nginx转发两个中间件,拓扑如下:
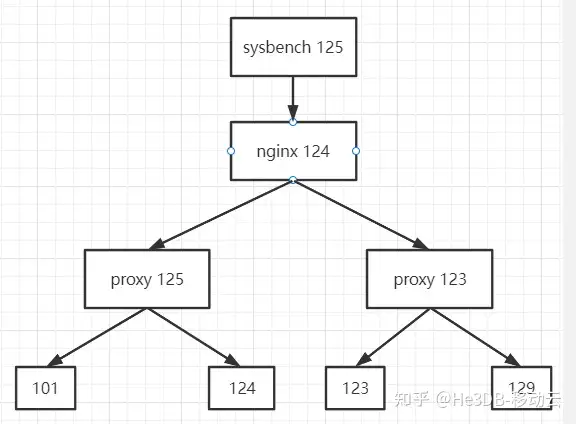
因为节点复用等因素,这种模式下测试点查QPS能达到105W左右,机器资源已经达到瓶颈。
综上可知,He3Proxy性能瓶颈点主要在网络通信中,高并发下建议部署多台proxy进行压力分摊,同时建议He3Proxy部署节点使用cpu密集型机器,cpu资源配置应大于数据库部署节点,以达到理想性能,性能优化是个长久的过程,未来仍需要持续跟进优化。
目标
虎啸欲归山,玉兔探头来。 He3Proxy年内规划的功能性开发任务已接近尾声,目前重要任务是提升性能,性能目标也很明确,通过中间件能将读性能扩展至百万QPS,同时写性能达到10WTPS。
性能分析工具
因为He3DB是一主多从的架构,只有主节点能执行写操作,因此通过中间件写性能势必下降,中间件要尽量减少损耗量;读操作同样要控制损耗,并做好负载均衡;性能分析还需从实际出发,理论分析代码很难找到瓶颈点,首先介绍几款GO语言常用的监控工具:
这是一款不错的开源监控平台,代码集成很方便,支持pull、push两种模式,能统计cpu、锁、协程等耗时情况,并有UI页面展示火焰图等,方便发现性能瓶颈点,详细使用介绍可以参看产品文档;
- go pprof
原生的GO语言分析工具,再配上Graphviz分析工具,可以很容易的生成cpu调用耗时图;
借助以上两款工具(其实两种的数据源是一样的,只是展示形式不同,用好一种就可以了),可以很容易的找到性能瓶颈点。
测试环境
环境准备,为完成测试协调了几台高性能的物理机,机器配置如下,可以看到机器配置真的很高^_^;压测工具使用sysbench,数据量为50张表,每张1000W数据,
| IP | 角色 | Cpu | Mem(G) |
| 101 | Master | 96 | 754 |
| 123 | Slave | 96 | 377 |
| 124 | Slave | 96 | 377 |
| 125 | Proxy/Sysbench | 96 | 377 |
主节点性能测试
| 脚本 | QPS | TPS | 并发(threads) |
| oltp_point_select.lua | 766467.40 | 766467.40 | 256 |
| oltp_read_only.lua | 459933.33 | 28745.83 | 256 |
| oltp_update_index.lua | 245152.26 | 245152.26 | 256 |
| oltp_update_non_index.lua | 262541.35 | 262541.35 | 256 |
| oltp_write_only.lua | 558844.79 | 93128.40 | 256 |
He3Proxy配置一主两从,初次测试,测试场景为oltp_read_only,QPS仅仅18W左右,还不到单机的一半,这么大的损耗耗在哪里了?带着震惊与心慌通过性能工具进行分析,当时忘记截图了,总之通过火焰图发现一些函数执行耗时较多,可以将这些耗时问题归为三类。
一是代码规范性问题:比如Log日志输出时大量使用fmt.Sprintf,并且没做日志级别判断,导致虽然设置日志输出级别,但日志语句仍会执行耗时;再如字符串对比时使用strings.ToUpper/ToLower等,通过日志输出前进行级别判断、减少strings工具类的使用等,将这部分耗时优化,QPS约提升2-3W。
if golog.GetLevel() <= golog.LevelDebug {
golog.Debug(moduleName, "xx", fmt.Sprintf("%d", c.configVer), c.connectionId)
}二是gc频繁及锁机制,因为He3Proxy需要接收后端数据库返回的数据,Proxy需要按条解析数据包长度,循环读取所有的消息,循环内每次读取消息时会存在make slice的操作,因压测消息量较大,导致slice频繁创建、扩容、回收等,gc频繁,耗时较多;通过预创建公共slice,并预留较大cap,以解决频繁创建、扩容的问题,从而降低gc频率,也算是一种空间换时间的思想;另外关于锁的优化尽量去除不必要的锁或者减少锁的范围,并将锁的类型分为读锁、写锁等,减少锁对读性能的影响;通过上述两种优化,QPS提升至33W左右,依然很低,目前的耗时主要集中在网络io的操作上,我把这个问题归结为第三类。
三是系统调用类耗时,如epollwait路径耗时以及syscall;这部分困扰我较长时间,也是最难优化的一部分。众所周知,go语言在网络通信上做了大量优化,net包采用epoll方式处理请求,能使用户像使用阻塞IO的方式一样使用非阻塞方式,编程更简单、更符合逻辑,加上轻量级的协程能够轻松支持百万级并发,我测试并发还不到千级为什么epollwait耗时如此之多?起初我误认为pprof中epollwait是cpu阻塞时间,怀疑是否为等待数据库操作的返回耗时,后来研究发现epollwait时间应该指整个请求链路执行的时间(这里思路偏差耗费不少时间)。
进一步聚焦,发现耗时主要在proxy与数据库通信方面,最初为减少开发量proxy使用了pgx作为与后端数据库建立链接的桥梁,并使用pgx建立的TCP链接通道进行数据通信;并且在通信包读取和发送时已经采取预读,并且写操作进行了合并处理,网络io次数已经尽肯能的减少,并且流量远没达到网卡带宽的上限,那会不会tcp通信本身的瓶颈呢?随后想到零拷贝,通过减少内核态与用户态的数据拷贝,大幅提升性能,搜索发现字节开源的netpoll库相对net库实现了网络通信的零拷贝API操作,举手无措之际决定放手一搏,将proxy与数据库这部分链接通信方式由pgx改为netpoll链接,相当于对proxy做了一次大手术,改造完成后测试结果很惊喜:
| 脚本 | QPS | TPS | 并发(threads) |
| oltp_point_select.lua | 968556.57 | 968556.57 | 1024 |
| oltp_read_only.lua | 455039.90 | 28439.99 | 768 |
| oltp_update_index.lua | 242938.26 | 242938.26 | 256 |
| oltp_update_non_index.lua | 259854.04 | 259854.04 | 256 |
| oltp_write_only.lua | 463095.33 | 77172.24 | 256 |
点查结果近百万,写操作损耗控制在17%左右,相对之前已有较大提升,但是离单节点叠加的结果还是有不少差距,并不能通过中间件实现翻倍的效果,此时分析cpu耗时,基本集中在proxy向客户端的写操作,系统调用的cpu消耗较多,目前也在想这部分是否也能进行零拷贝操作, 还没有较好方案;
同时中间件部署节点配置与数据库节点相同,中间件内部还有一些处理逻辑,已经达到了机器资源瓶颈;另外也使用nginx对三台节点进行负载转发,测试点查,QPS能达到115W左右,nginx性能确实优秀,但也没能实现翻倍,也受限于机器资源及网络损耗,不过C语言编程性能确实优于GO不少。
后又经过反复测试,在机器节点状态较好的情况下勉强能达到百万 ,另外机器配置较高,数据库处理读数据操作基本属于内存操作,延时相对较低。
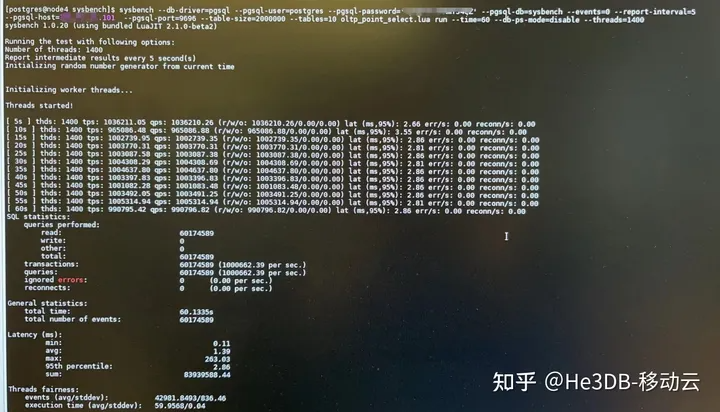
高可用下进一步测试:将集群调整为1主三从四台机器,部署两个proxy,每个proxy转发至两个读节点,同时通过nginx转发两个中间件,拓扑如下:
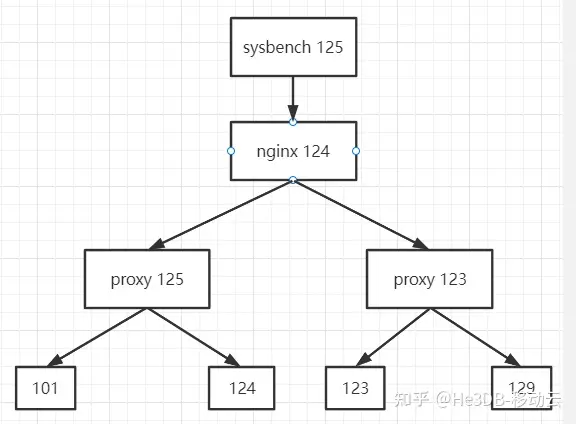
因为节点复用等因素,这种模式下测试点查QPS能达到105W左右,机器资源已经达到瓶颈。
综上可知,He3Proxy性能瓶颈点主要在网络通信中,高并发下建议部署多台proxy进行压力分摊,同时建议He3Proxy部署节点使用cpu密集型机器,cpu资源配置应大于数据库部署节点,以达到理想性能,性能优化是个长久的过程,未来仍需要持续跟进优化。
