







/ 业务场景
/ 数据链路
当触发事件发生时,Airflow通过从AWS S3中检索相关数据文件来启动数据加载过程。它使用适当的凭据和API集成确保与S3存储桶的安全身份验证和连接。一旦数据从AWS S3中获取,Airflow会协调数据的转换和加载到ByteHouse中。它利用ByteHouse的集成能力,根据预定义的模式和数据模型高效地存储和组织数据。
/ 总结

/ 步骤一:先决条件
brew install bytehouse-cli
/ 步骤二:安装Apache Airflow
# airflow需要一个目录,~/airflow是默认目录,# 但如果您喜欢,可以选择其他位置#(可选)export AIRFLOW_HOME=~/airflowAIRFLOW_VERSION=2.1.3PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"# 例如:3.6CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
/ 步骤三:Airflow初始化
# 初始化数据库airflow db initairflow users create \--username admin \--firstname admin \--lastname admin \--role Admin \--email admin# 启动Web服务器,默认端口是8080# 或修改airflow.cfg设置web_server_portairflow webserver --port 8080
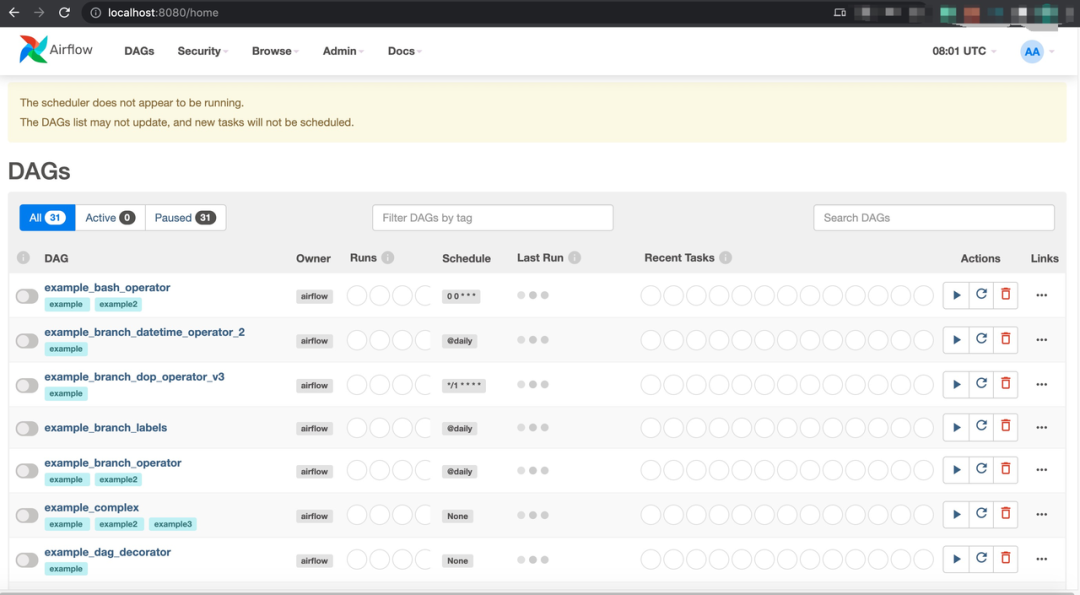
/ 步骤四:YAML配置
# 默认情况下是SQLite,也可以连接到MySQLsql_alchemy_conn = mysql+pymysql://airflow:airflow@xxx.xx.xx.xx:8080/airflow# authenticate = False# 禁用Alchemy连接池以防止设置Airflow调度器时出现故障 https://github.com/apache/airflow/issues/10055sql_alchemy_pool_enabled = False# 存放Airflow流水线的文件夹,通常是代码库中的子文件夹。该路径必须是绝对路径。dags_folder = home/admin/airflow/dags
/ 步骤五:创建有向无环图(DAG)作业
~/airflowmkdir dagscd dagsnano test_bytehouse.py
from datetime import timedeltafrom textwrap import dedentfrom airflow import DAGfrom airflow.operators.bash import BashOperatorfrom airflow.utils.dates import days_agodefault_args = {'owner': 'airflow','depends_on_past': False,'email': ['airflow@example.com'],'email_on_failure': False,'email_on_retry': False,'retries': 1,'retry_delay': timedelta(minutes=5),}with DAG('test_bytehouse',default_args=default_args,description='A simple tutorial DAG',schedule_interval=timedelta(days=1),start_date=days_ago(1),tags=['example'],) as dag:tImport = BashOperator(task_id='ch_import',depends_on_past=False,bash_command='$Bytehouse_HOME/bytehouse-cli -cf root/bytehouse-cli/conf.toml "INSERT INTO korver.cell_towers_1 FORMAT csv INFILE \'/opt/bytehousecli/data.csv\' "',)tSelect = BashOperator(task_id='ch_select',depends_on_past=False,bash_command='$Bytehouse_HOME/bytehouse-cli -cf /root/bytehouse-cli/conf.toml -q "select * from korver.cell_towers_1 limit 10 into outfile \'/opt/bytehousecli/dataout.csv\' format csv "')tSelect >> tImport
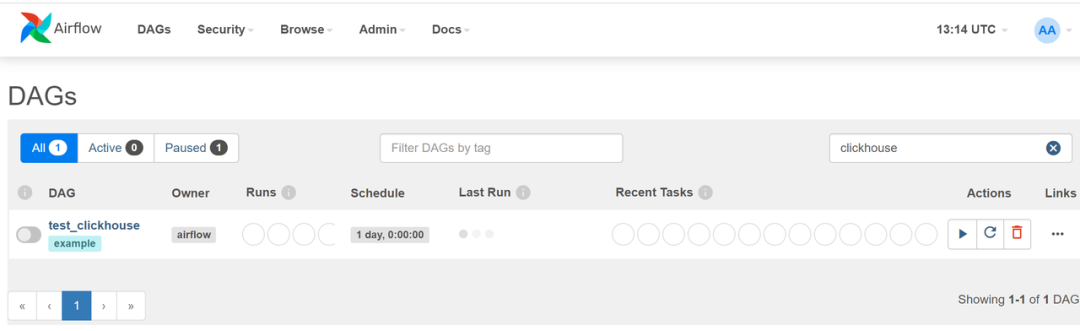
/ 步骤六:执行DAG /
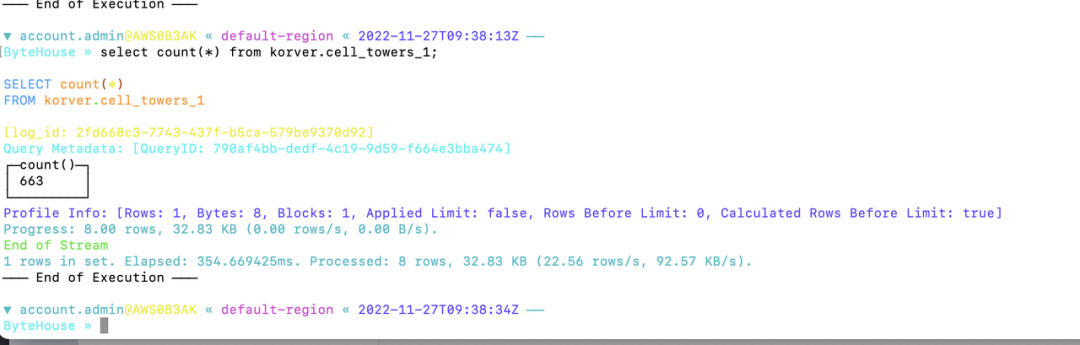
#打印"test_bytehouse" DAG中的任务列表[root@VM-64-47-centos dags]# airflow tasks list test_bytehousech_importch_select#打印"test_bytehouse" DAG中任务的层次结构[root@VM-64-47-centos dags]# airflow tasks list test_bytehouse --tree<Task(BashOperator): ch_select><Task(BashOperator): ch_import>
产品介绍






文章转载自字节跳动数据平台,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
