




tendis存储版简介
tendis存储版 是腾讯互娱CROS DBA团队 & 腾讯云数据库团队自主设计和研发的开源分布式高性能KV存储。tendis存储版完全兼容redis协议,并使用rocksdb作为存储引擎。同时,tendis存储版支持远超内存的磁盘容量。
最开始实现的tendis存储版是单机版本的,只支持主从数据同步复制和故障主从切换, 单机版tendis存储版有以下缺点:
(1) 单机模式具有固有的局限性 单机不支持自动故障转移,扩容能力极为有限,只能本地扩充磁盘
(2) 运维困难 首先是failover 机制不支持,当master故障时需要人工来进行主从切换,增加运维负担, 其次是每个tendis存储版 需要单独管理, 没有整体的状态信息。
(3) tendis存储版和redis 混合使用时上下层无法独立灵活扩容
在混合存储方案中,每个 redis cluster的 master节点下面都会挂一个tendis存储版节点, 按照1:1的比例部署,由于不同业务冷热数据分布不同,缓存层和存储层需要的资源量肯定有不一致的情况, 需要单独进行扩缩容这导致运维的灵活性变差,同时也会出现资源浪费的情况
因此需要将 tendis存储版 同样改造成集群模式, 如下图所示, 在tendis cluster中 分为多个独立的sharding分片,每个分片可以分别配置其负责哪些slots, 所有节点之间能够互相通信,达成分布式一致性。
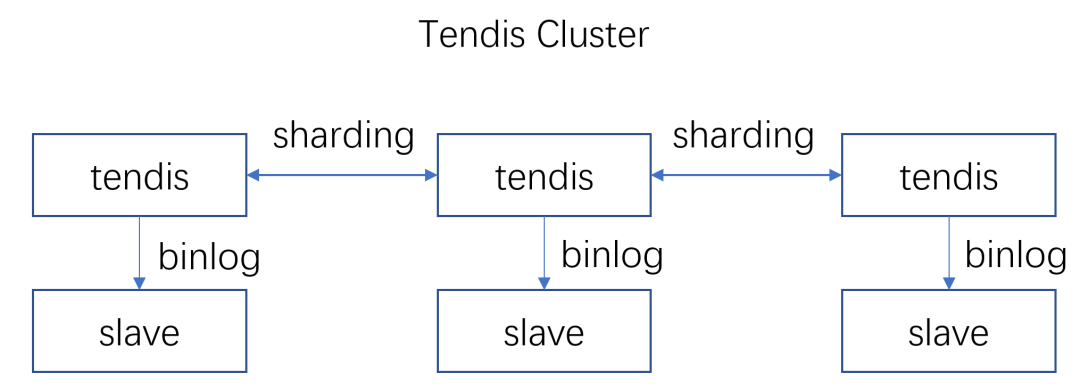
这个方案实现的目标是:(1) tendis存储版 能够像redis cluster一样实现集群自治 (2) 缓存层和存储层能够根据资源使用情况分别独立扩容缩容 (3) tendis存储版更加方便运维管理,能够提供failover的能力 和 更多的元数据信息方便监控
集群方案选择
引入 proxy组件组件
(1) 使用 Twemproxy
Twemproxy是由Twitter开源的集群化方案, 它的功能比较单一,只实现了请求路由转发,没有像Codis那么全面有在线扩容的功能,它解决的重点就是把客户端分片的逻辑统一放到了Proxy层而已,其他功能没有做任何处理。这种方案同样使得IO路径增加一个 proxy 层,另外它的痛点就是无法在线扩容、缩容,这就导致运维非常不方便。
(2) 使用Codis Codis 是一个分布式 Redis 解决方案, 其架构分成proxy集群+redis集群,proxy集群的高可用,可以基于zookper或者l5来做故障转移,对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有显著区别 (不支持的命令列表), 上层应用可以像使用单机的 Redis 一样使用, codis 是一种中心化组件设计,codis使用zookeeper来作为辅助,zookeeper也是一种集中式的管理自己的元数据方式。
codis优点不需要太多的开发量, 提供完整的集群功能框架 , 对于redis 支持度好,能够支持在线数据迁移和扩容,并且能够基于HA 实现故障转移
该方案缺点如下:
(1) 增加了资源和运维工作量
涉及组件多,需要部署多个proxy, 运维复杂,另外codis依赖zookeeper来存放数据路由表和codis-proxy节点的元信息, 对于redis集群来说需要额外的机器搭zookeeper,
(2) 需要额外部署HA组件实现failover
codis不能天然支持故障转移和主节点选举,需要部署HA来实现tendis节点的主备切换
使用p2p的去中心化架构
在一致性方面 该方案一般选择的一致性方式是Gossip协议,Gossip是一种去中心化的分布式协议,数据通过节点像病毒一样逐个传播,因为是指数级传播,整体传播速度非常快,该协议能够保证最终一致性,
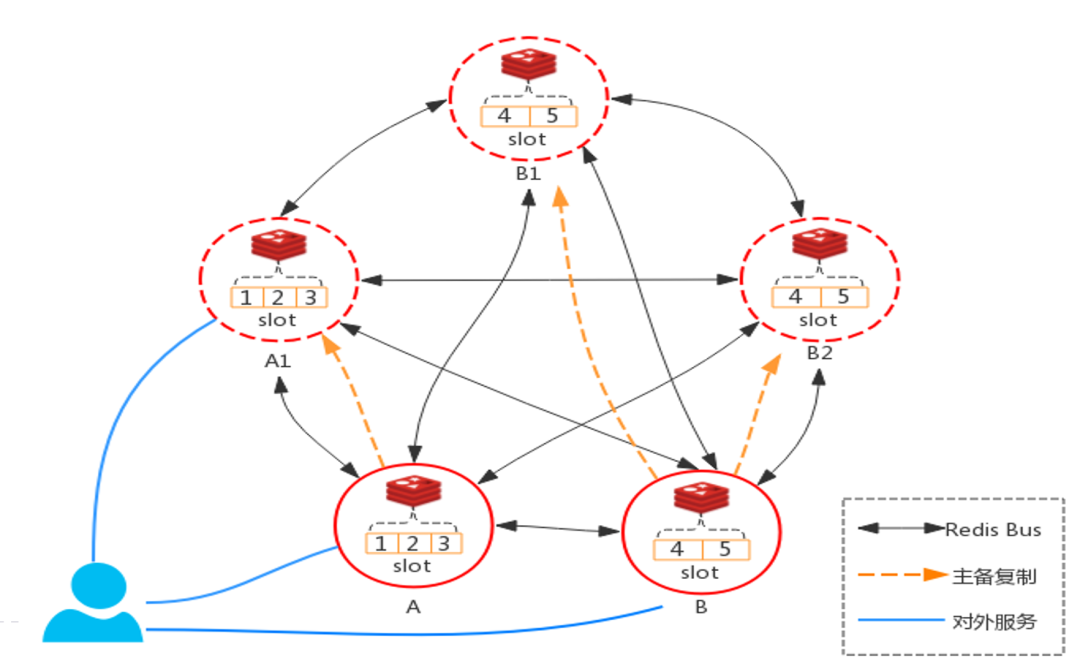
目前官方Redis Cluster 也是走的P2P去中心化的方案 , 如下图所示,cluster 中共有16384个slot , 每个master节点负责一部分slot , 客户端可以连接集群中任何一个节点 都可以访问到正确的数据, 通过 hash 计算 路由到正确的节点。
该方案的优势如下:
(1)去中心化天然的优势
在这种设计中集群中的所有节点都是对等的,没有特殊的节点,所以任何节点出现问题都不会阻止其他节点继续发送消息。任何节点都可以随时加入或离开,而不会影响系统的整体服务质量
(2) 高性能 I/O路径缩短
由于每个节点都保存了一份完整的元数据信息,内部通过简单的hash计算后就能通过move协议自己转发到正确的节点,不需要经过元数据节点读取和计算
(3)较好的可用性,方便运维
能容忍集群中少数节点的出错,在绝大多数的主节点是可达的,并且对于每一个不可达的主节点都至少有一个它的从节点可达的情况下,Redis 集群仍能提供正常访问。通过failover 和 slave migration机制, 在一半master 挂掉的情况下,只要挂掉一半的主仍然有slave,存活 或者 未挂的master 有超过2个存活的slave , 都可以通过选举来恢复集群正常。
该方案缺点是 开发工作量比较大,tendis存储版是基于c++多线程模型开发的,需要重新在tendis存储版上设计元数据和算法实现,另外会有很多并发问题要考虑。最终比较 我们选择了去中心化的方案,原因如下:
(1) tendis存储版 和 redis 集群的设计目标是一样的
Redis Cluster设计的核心目标是高性能、方便水平伸缩,基于去中心化方案能够达到这一目标,随着社区版cluster 设计的不断迭代,基于gossip的去中心化一致性算法已经趋于稳定,而tendis存储版 同样是这个目标 , 因此 选用同样的P2P去中心化方案能够满足分布式系统设计的需求,同时在方案可靠性方面可以基本保障。
(2) 方便对接业务
redis client 天然支持了redis cluster 协议,存储版集群 可以单独提供给用户使用,让用户像访问redis cluster 一样访问tedis cluster , 这大大方便了以后的业务对接。
(3) 方便运维
当前的管控系统很多是针对redis cluster 的特性开发的,后期稍微改动后可以迁移到tendis cluster上。在 tendis 冷热混合存储方案中, 缓存层和tendis中间有一层sync组件,去中心化的方案能够支持sync直接访问底层tendis存储。
集群核心功能实现
在元数据设计和通信方式层面, tendis存储版 和 redis 实现方式类似, 在server启动后都会开启一个bind port+10000作为集群内部通信端口,然后初始化自己的元数据。
数据结构设计
tendis存储版 使用C++ 17实现, 因此集群版虽然在元数据设计层面 和redis cluster 很多地方类似,例如使用current epoch 和 config epoch 来记录集群变化时间的epoch , 但全部改写成立C++ 17 风格,并在网络包使用了自己对应的字节编解码方法, 用智能指针来管理对象的生命周期。
核心类包括:ClusterNode, 表示单个集群节点的信息, 在gossip 实现中, 关注的核心元数据信息如下:
(1) 主从关系 这部分逻辑直接影响了数据复制,在集群发生变化时,主从关系的元数据也需要更新传播。另外failover时也需要进行切换
(2)负责的slots 信息 这部分是最核心的元数据,直接决定了数据路由到哪个节点
(3) epoch信息 这是 集群节点的epoch配置纪元,每个节点在集群中都有独一无二的纪元,当节点在通信时元数据发现有冲突时,总是以epoch高的节点为准,可以认为它反映了节点信息的新旧程度。
(4)failreport信息 用于检测集群中疑似发生故障的节点
关注的主要是两个集群的元数据信息,tendis存储版 中 cluster Node其中核心数据结构如下
std::string _nodeName;
uint64_t _configEpoch;
// TCP/IP session with this node, connect success
std::shared_ptr<ClusterSession> _nodeSession;
// 管理的slot信息
std::bitset<CLUSTER_SLOTS> _mySlots;
// slave 列表
std::vector<std::shared_ptr<ClusterNode>> _slaves;
// master 列表
std::shared_ptr<ClusterNode> _slaveOf;
std::list<std::shared_ptr<ClusterNodeFailReport>> _failReport;
ClusterState 表示集群状态的类 核心成员信息如下:
CNodePtr _myself; // This node
uint64_t _currentEpoch;
uint64_t _lastVoteEpoch; // Epoch of the last vote granted.
std::unordered_map<std::string, CNodePtr> _nodes; // node table
ClusterHealth _state;
uint16_t _size; // cluster size
std::unordered_map<std::string, uint64_t> _nodesBlackList;
mutable myMutex _mutex;
mutable std::mutex _failMutex;
std::condition_variable _cv;
(1)_nodes 集群中所有节点的列表 当添加一个节点或者删除一个节点时,只需要将命令发给集群中的任意一个节点,这个节点会修改本地的 node table,并且这个修改会最终复制到所有的节点上去
(2) current epoch 表示整个集群中的最大版本号,集群信息每变更一次,该版本号都会自增以保证每个信息的版本号唯一
(3)_state 表示集群健康状态 初始化时该状态为fail , cluster会定期检测当前所有slot 对应的master 是不是存活状态,只有16384个slots对应的所有master都存活时,该状态设置为OK
(4) _nodesBlackList 集群黑名单, 用于实现集群中的cluster forget 功能, 防止遗忘 的node再次发生通信时把它错误添加回去。
(5) 相关锁信息
tendis存储版 采用了独立线程来处理集群内部的通信和数据更新, 独立的线程来定期处理集群内部的状态转换。因此类中都持有muterx 锁或者递归锁, 在需要阻塞时还有对应的信号_cv
ClusterMsg 类,用于表示集群中的消息通信信息。
uint32_t _totlen;
ClusterMsg::Type _type;
uint32_t _mflags;
std::shared_ptr<ClusterMsgHeader> _header;
std::shared_ptr<ClusterMsgData> _msgData;
消息类包括 header 包头和 data, 这个设计和redis相似, header 中存放的消息发送者自身的ip,slots等信息
消息体有四种类型
enum class Type {
Gossip = 0,
Update = 1,
FAIL = 2,
PUBLIC = 3,
};
分别处理正常的ping pong 信息, update 信息 和 failover 信息等, 对于每种gossip的消息类, 实现了完整的encode 方法和decode方法来实现基于字节的编码。
gossip实现
在 redis cluster 实现中,心跳发送PING包和检测PONG响应时间都在clusterCron中, 由于redis的单线程,因此需要使用额外的时间片来处理,tendis存储版 是多线程模型,是基于异步网络模块+线程池工作模式工作的。
因此这里cluster manager使用了独立线程 _controller来处理cluster Cron 任务
_controller =
std::make_unique<std::thread>(std::move([this]() { controlRoutine(); }));
crontrolRoutine函数实现了核心的cluster cron功能,流程图如下所示 , 在社区版本的基础上,tendis存储版增加了很多并发锁控制的逻辑(防止发生死锁),另外增加了一个cronCheckReplicate来检测 cluster信息和replication信息不一致的情况,这是由于修改这两部分元数据目前在tendis存储版实现上还没做到原子操作,在极端情况下会出现两者不一致的问题从而导致数据错误。
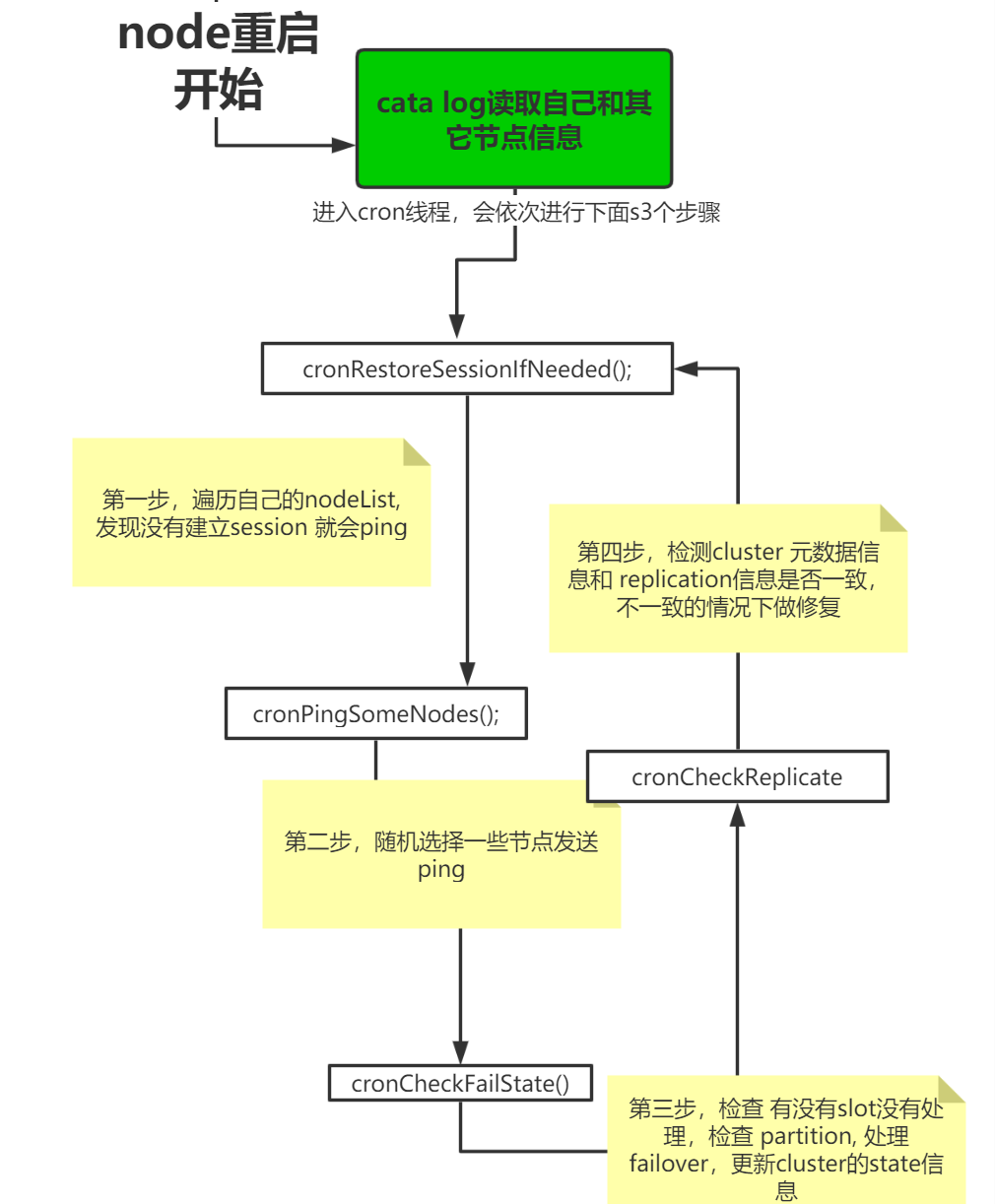
在元数据持久化方面,redis cluster 存放在一个文本文件中,而 tendis存储版直接存放在catalog的(rockdb)中,读写更加快速方便。
底层数据设计
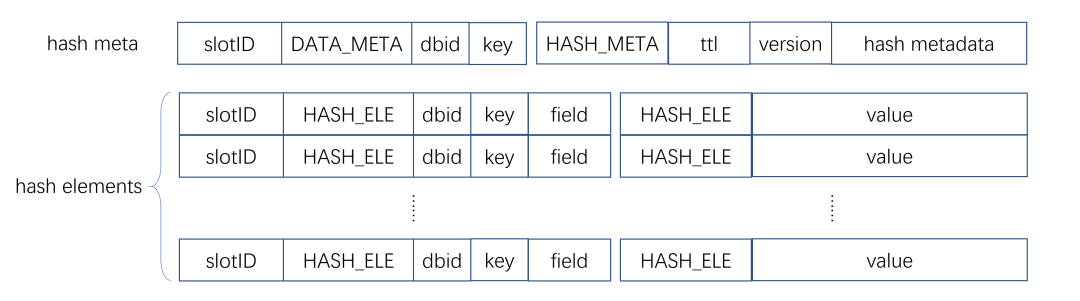
为了实现底层数据能够按照slot 进行管理,数据按slot划分,slot 信息放入key的成员变量集合的第一位,这样slot相同的数据在rockdb的kvstore中对应的chunkid也相同,数据相邻, 如下图所示。
tendis存储版 支持key 级别的并发控制,之前版本的tendis存储版只实现key访问级别访问锁 和 DB级别的锁(DB是基于rockdb的kvstore来设定)
这里将原来的二级锁结构,key锁->DB锁 改成三级锁结构key锁->slot锁->DB锁 。这样实现有两个好处:
(1)chunk锁用于控制slot层面的并发控制,这对tendis存储版 的集群功能非常重要。
最核心的好处是,在集群扩容搬迁数据时,能够基于 slot级别来进行数据搬迁控制 ,这个后面会详细讲解,另外比如在阻塞一个node请求,只要把它负责的slots加上chunk锁
(2)实现了slot cursor 方便遍历一个slot中所有的数据,cluseter的部分命令也需要用到这个功能
基于增量加全量数据的扩缩容 方式
社区版redis的搬迁是以key为单位以同步方式进行搬迁,如果搬迁是遇到大key , 社区版比较难解决,同步搬迁容易卡非常久,超过15秒,甚至自动触发切换,把Master判死,Redis会重新选择新的Master,由于migrating状态是不会同步给slave的,所以slave切换成master后,它身上是没有migrating状态的。一旦migrating状态消除, ASK协议就不能正常工作,导致访问出错。
这种问题是单线程的redis 很难避免的, 但tendis存储版是多线程模式, 因此这里设计tendis存储版 使用独立的线程池进行搬迁,同时tendis存储版的搬迁是以slot为维度,不同slot之间可以并发搬迁, 由于之前实现了slot锁级别控制 因此很容易做到slot 级别数据统一搬迁。
基于这种设计,搬迁任务发送方sender的类实现成员变量如下:
std::bitset<CLUSTER_SLOTS> _slots;
std::atomic<bool> _isRunning;
std::unique_ptr<DbWithLock> _dbWithLock;
std::string _taskid;
std::shared_ptr<ClusterNode> _dstNode;
std::list<std::unique_ptr<ChunkLock>> _slotsLockList;
_slots 是这次搬迁任务负责的slots集合,用一个bitmap表示,默认配置是10个,takid 表示 这次搬迁任务的任务id, 是由接收方的clusternodeid +uuid生成,发送方和接收方有一个相同的父taskid. _dstNode记录了接收方的cluster node信息,_slotsLockList 存放了当前搬迁任务持有的chunk锁集合。
搬迁基于的技术是快照+增量binlog的技术, snapshot快照是rockdb底层引擎天然支持的特性,能够生成某个时间点的全量数据,而binglog是类似于 mysql主从同步使用的binlog , 是用来增量同步主从数据的,tendis存储版 支持这两个特性。
(1) 初始化时,集群会初始化一个搬迁线程池和搬迁线程定期调度线程有以及搬迁任务的类列表, 调度线程会根据任务的状态机来进行不同任务状态机 进行不同操作。
(2) receiver 会接收到搬迁命令,它会做一系列元数据检查,然后发送一个内部命令给 sender ,当sender 检查ok时会进入 sender的搬迁任务进入WAITING状态,
(3) receiver 接收到回包后,会进入REIVESNAPSHOT状态(表示进入ready状态),然后会根据建立的dstNode信息给对方发一个内部命令(加上自己的taskid)
(4)sender 接受到后会再次检查,然后找到匹配的taskid 的任务,将这个taskid 的sender的搬迁任务进入START状态, 进入START 状态;
(5) 调度线程检查到START 状态后, 会依次进入 全量数据同步阶段 和增量数据同步阶段
在全量数据同步阶段 就使用上面提到的slot cursor 扫描这个task 的slots 列表里面涉及的的所有slot数据 ,发送全量数据给接收方(这个过程会通过不断小部分迭代和通信来确保中间不丢数据,具体过程看下面的时序图) 全量数据发送完后,receiver 会 将client 链接变成 接受命令session 进入RECEIVEBINLOG状态 , 开始接受binlog命令
(6)增量同步阶段是为了完成在全量数据发送过程中新产生的数据,设计了如下追加binlog 的算法实现
首先,在发送snapshot的开始瞬间,任务会记录下当前db最新数据的offset (记录为起始位置begin), 当snapshot完成后,这里再取一次db 最新offset得到maxid
这里实现一个Sendbinlog接口,让binlog扫描maxid 和begin之间的数据发送到receiver,当发送完成时再取一次db 最新数据maxid, 由于这个时间段一直有流量写入, 因此maxid 会一直大于上面一次的end 位置
但考虑到写入的速度一定是小于binlog发送的速度,因此这里设计一个迭代收敛的算法,让这个过程循环迭代,没迭代完一次求一个maxid 和begin的差值,直到这个差值小于10000以内 算法描述如下
send_binlogs(bitmap) {
begin = _snapshotStart; end = _highest+1;
retry = 10;
while (retry-- == 1) {
send_binlog_low(bitmap ,begin ,end);
begin = end;
end = _highestID;
if (maxid - begin < 10000) {
finished = true;
break;
}
}
lock_chunks(bitmap);
end = maxid;
send_binlog_low(bitmap ,begin ,end);
unlock_chunks(bitmap);
}
当while循环完成后 这里会给这次任务的slot 上锁(阻塞了这部分slot相关的请求),这样offset就不会增加,这个时候再发送最后一个binlog序列,将这10000条发送过去后 再解锁 这样设计的目的是保证最后上锁的时间很短,通常在ms级别,做到用户无感知
(7)在sender在完成所有binlog发送后 会发送一个命令给receiver , receiver找到对应的takid 后需要修改cluster 元数据(即将slots的归属者设置为自己,然后发送一个gossip广播通知所有其他节点)并将task状态设置其状态为 success,
(8) sender 收到receiver回包后解锁, 将slots归属改为对方,然后清理自身存储的这部分脏数据
搬迁slot方案不需要辅助工具和复杂的命令, 只需要一条命令, 在dst Node目标节点 执行
cluster setslot importing srcNodeid [slotlist]
nodeid 是 srcNode在 cluster nodes 命令中展示的id , slotslist是 需要搬迁的slots
(假设现在需要从node A 搬迁 slot 到node B , 那么 node B 是dst Node , node A 是src Node)
搬迁的时序图如下所示:
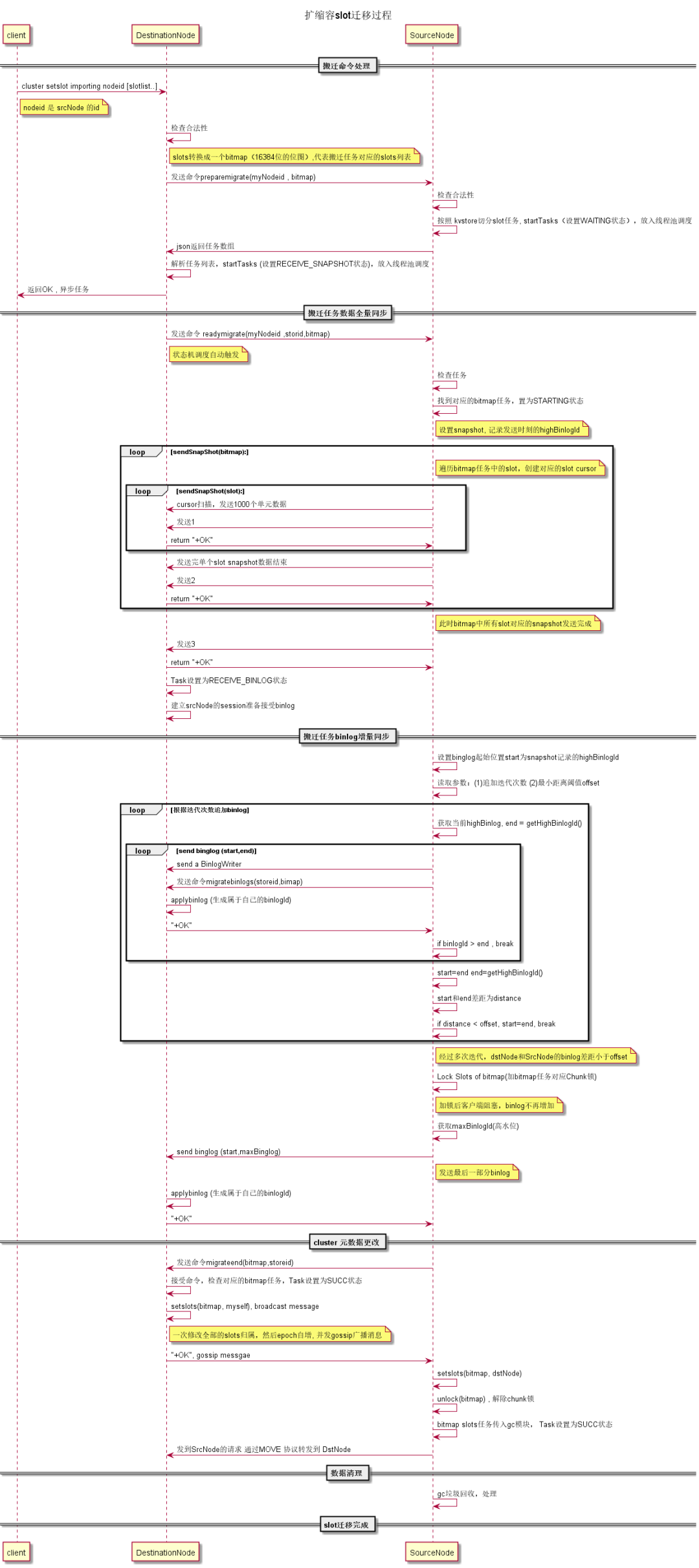
和社区版核心的区别是 ,社区版的搬迁是基于key维度搬迁的, 搬迁过程中是以key为最小子任务, 一个key搬完后可以通过ask 协议在目标节点访问,整个过程是同步的。而tendis存储版是基于 slots搬迁的,这种全量+增量的方式有更好的稳定性和效率,腾讯云上的云redis也采用类似的方案重写了社区版的redis搬迁。
全量+增量方式总结有如下优点:
1.异步处理方式 ,通过发送snapshot和binlog 来全量和增量同步数据,在搬迁过程中不会长时间卡住
2.多线程并发,不同任务之间可以并发搬迁,以bitmap的粒度来调度任务,以及任务大小可以配置,从而比较灵活控制搬迁的压力和速度
缺点:
搬迁时候对请求性能有影响,(搬迁过程需要响应请求的同时做发送snapshot 等操作),但这点在搬迁是无法避免的,tendis存储版支持限流和动态修改线程数等方案来减少搬迁时候对性能的影响。
集群版项目开源
目前集群版tendis存储版开发已经完成,近期会对外开源,欢迎更多人参与进来优化改进tendis。
