




导语
本文介绍IEG-技术运营部-存储与计算资源中心开发的tendis存储版项目的性能优化过程,本文仅涉及CPU相关优化,32核机型QPS从18万提升到33万,提升83%。
项目介绍
tendis存储版是一款支持redis协议的存储系统,由IEG-技术运营部-存储与计算资源中心研发。于2019年初开始研发,2020年中在腾讯云上线,2020年底IEG上线,计划2021年初开源。
redis因为自身的优势受到广泛应用,但是因为数据全部在内存,所以成本很高。很多应用希望使用redis丰富的数据类型,丰富的特性,但是希望有较低的成本。tendis存储版的初衷就是提供完整的redis协议,通过将数据由内存存储改为磁盘存储,从而大幅度的降低成本。并使用SSD磁盘存储以减少性能的影响。
tendis存储版支持redis的大部分协议,支持cluster模式,采用多线程实现,底层使用rocksdb存储引擎,利用LSM(日志结构合并树)解决磁盘随机写的问题。框架图如下:
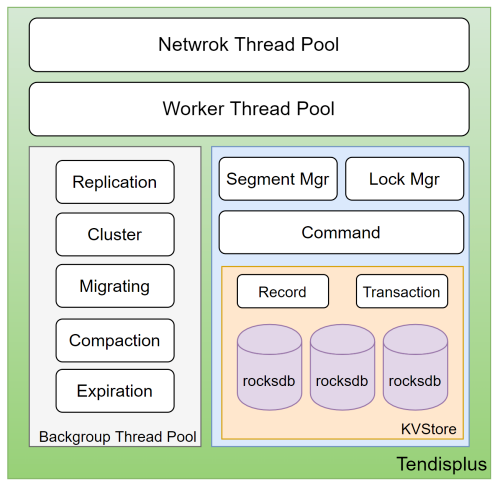
Network Thread Pool:网络读写线程池
Worker Thread Pool:命令处理线程池
Lock Mgr:锁管理模块
Command:redis的命令处理模块
rocksdb:存储引擎
Replication:主从同步模块
Cluster:集群管理模块
Migrating:数据搬迁模块
测试环境:
本文主要讲解的是应用层优化,主要是针对CPU的优化。性能是在数据量为空的情况下,set key(16B) value(20B)在前面一分钟的QPS优化情况。这里的优化对不同的命令和不同大小的value都是同等有效的。
随着不断压测数据量增大后,更多的操作需要直达磁盘,性能会有较大的下降。这个问题更多涉及的是rocksdb引擎层的优化,本文暂时不写入这部分优化内容。
这里因为value=20Byte,所以性能瓶颈往往出现在CPU上面。如果value增大,比如16KByte,性能瓶颈往往会出现磁盘IO上面,优化需要针对磁盘进行,本文暂不写入这方面优化内容。
机型:Z30A,内存128G,磁盘SSD1.8T,CPU 32核Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
工具:redis-benchmark
数据大小:set key 16Byte,value 20Byte
优化结果
优化之前,tendis存储版的set性能大约18万,通过一系列的优化过程,性能达到33万。
优化过程
优化1:
问题:
当前cpu无法跑满,考虑是线程数的分配不合理。
当前网络io线程数是max(4, cpuNum/8),命令处理线程数是:max(4, cpuNum)。两个取值具有一定的合理性,但不一定是最优值。
优化方法:
调整网络io线程数和命令处理线程数,从iothreadnum=4,excecuterthreadnum=32调整为iothreadnum=4,excecuterthreadnum=56.
优化结果:
CPU压满到大约3000%
qps提升:19.4%
优化2:
问题:
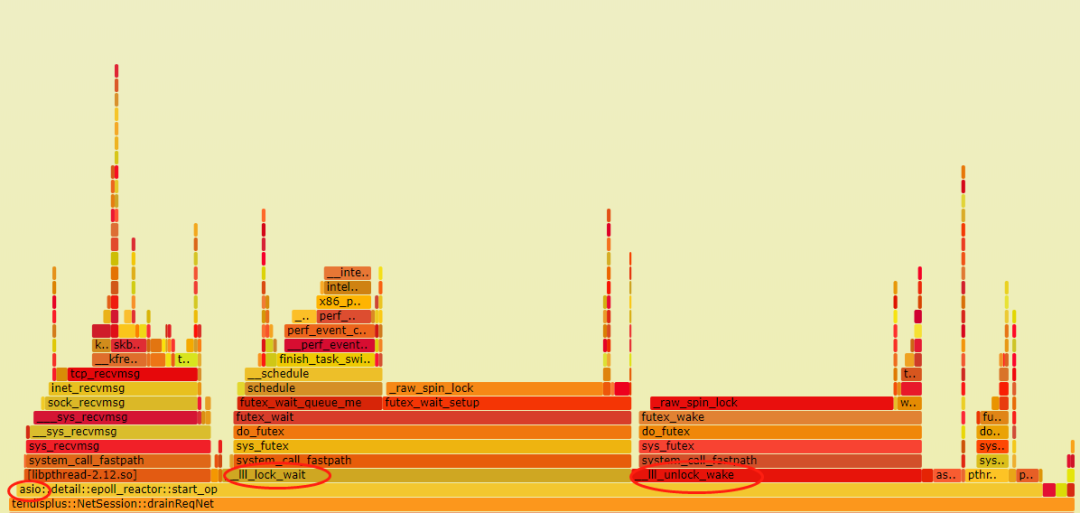
perf火焰图发现,在asio里面有大量的lock_wait和unlock_wake占用cpu。主要原因是因为asio的每个io_context对象,都有一个任务队列asio::io_context::op_queue,多线程处理的时候,无论是往里面扔任务还是从里面取任务,都需要上锁。火焰图如下:
优化前的异步框架如下:
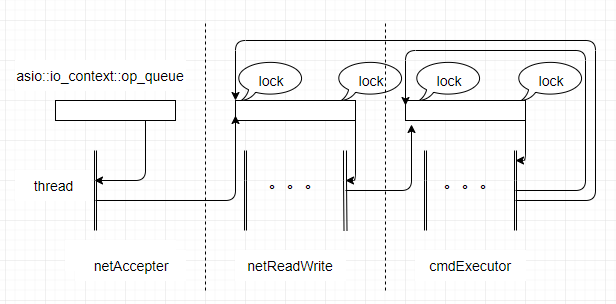
参考此图,以网络读写的事务队列netReadWrite:opQueue为例,看看有哪些锁竞争:
1.网络接受线程收到网络事件,需要往netReadWrite:opQueue添加任务,需要锁竞争。
2.网络读写多线程,需要从netReadWrite:opQueue取任务和添加任务,需要锁竞争,而且是多个线程。
3.命令处理线程池,处理完相关请求需要添加任务到netReadWrite:opQueue,需要锁竞争,而且是多个线程。
同理,命令处理线程池cmdExecutor:opQueue,也有同样的问题。
优化方法:
网络io多线程。优化前:多个线程处理一个io_context。优化后:每个线程处理一个独立的io_context。
命令处理线程池。优化前:单个WorkPool关联一个io_context,这个WorkPool是多线程。优化后:多个WorkPool,每个WorkPool一个线程,同时每个WorkPool关联一个io_context。
优化后的异步框架如下:
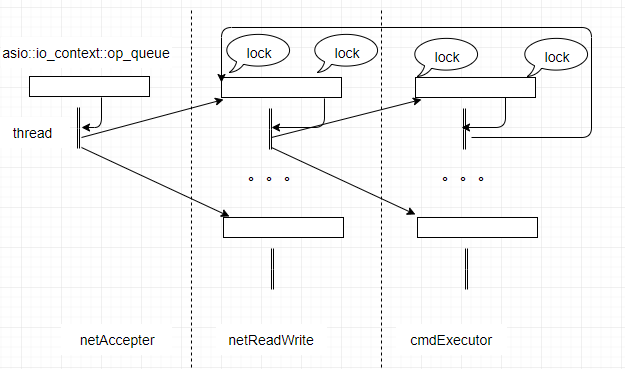
从图中可以看到,这里的锁竞争大大的减少了。
优化结果:
qps提升:7.7%
优化3
问题
ServerEntry::processRequest函数传入参数为sessionId,为了取到Session对象,需要对存储所有Session指针的map对象上互斥锁。由于每个请求都要在这儿进行锁竞争,估计对性能有很大影响。
优化方法
processRequest函数参数由sessionId改为Session指针,从而不再需要对_sessions上锁。
优化结果
qps没有提升,但通过“perf report perf.data“看到__lll_unlock_wake确实减少了CPU占用
优化4
问题
“perf report perf.data“可以看到在数据库锁(S,X,IS,IX)这里有较多的CPU占用。
MGLockMgr里面,利用互斥锁实现。为了减少互斥锁的竞争,进行了分桶,在每个桶内的操作对自己的互斥量上锁。由于分桶数SHARD_NUM的大小决定了冲突的程度,这里增加桶数以减少锁的竞争。
优化方法
从SHARD_NUM=32 改为 SHARD_NUM=32000
优化结果
qps没有提升,但通过“perf report perf.data“看到~ILock()确实减少了CPU占用
说明
qps没有提升,因而没有采用这个改动。
优化5
问题
数据库锁(S,X,IS,IX)是分等级的,当前分三级,分别是KeyLock,StoreLock,StoresLock。其中顶层StoresLock只有一个对象,所以任意层的任意一个对象上锁都会集中在这个对象上面上锁。由于每个set请求都要对key级别获取X锁,从而都会在StoresLock的这个对象上面上一个IX锁,这儿的冲突率是非常的高。
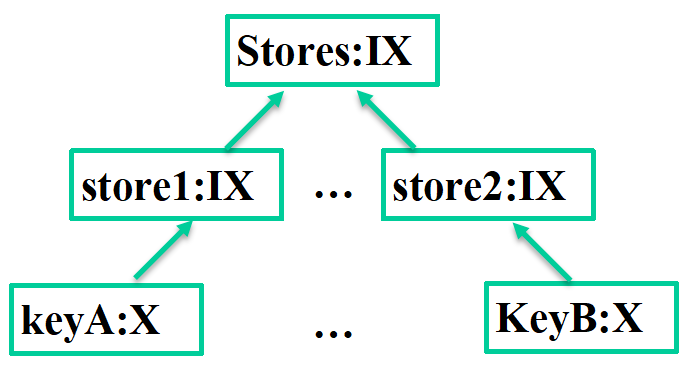

优化方法
去掉StoresLock顶层锁。
常规的数据库锁,都是逐级往上直到顶层的。这里为了性能放弃顶层锁,对于需要对顶层进行上锁的时候,可以用for循环来实现。目前还没有相关需求。
优化结果
qps提升:19.4%
优化6
问题
数据库锁(S,X,IS,IX)里面,KeyLock需要在StoreLock层上锁,为减小锁竞争,考虑增加store的数目。
优化方法
kvstorecount 从 10 改为 300
优化结果
qps提升:5%
优化7
问题
动态库的调用有一定的开销
优化方法
添加静态编译选项-static,将全部动态调用的函数都静态的编到二进制程序里面。
优化结果
qps提升:5.5%
优化8
问题
在代码仓库迁移到工蜂的过程中,切换了编译机。
优化方法
编译机从10.*.*.* 切换到9.*.*.*
优化结果
qps提升:12.2%
说明
这个性能的提升是意料之外的。经过分析发现,编译机9.*.*.*里面不少库的版本比10.*.*.* 要高,除此之外未发现其它原因导致性能的上升。怀疑是某个库在某些方面有相关优化。
要找到具体是哪个差异导致的,可以对有差异的库逐个进行升级排查。这需要反复的折腾编译环境,比较费劲。暂时并未进行准确定位。
优化9
问题
火焰图中有大量的malloc和free相关的cpu占用。其中_init_free,_init_malloc,malloc,malloc_consolidate总共的cpu占用高达14.4%。
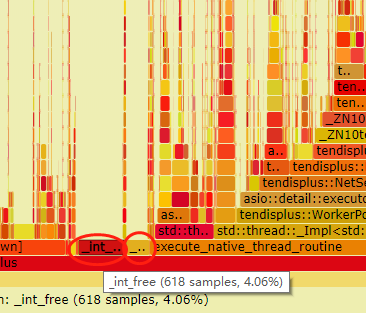
优化方法
glibc自带的ptmalloc2在多线程的情况性能很差,jemalloc在多线程的情况下性能大约比ptmalloc2快20倍。
使用jemalloc替代ptmalloc2
优化结果
qps提升:16.1%
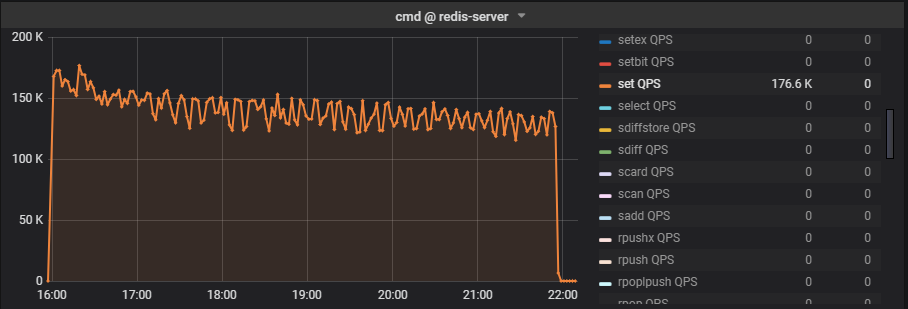
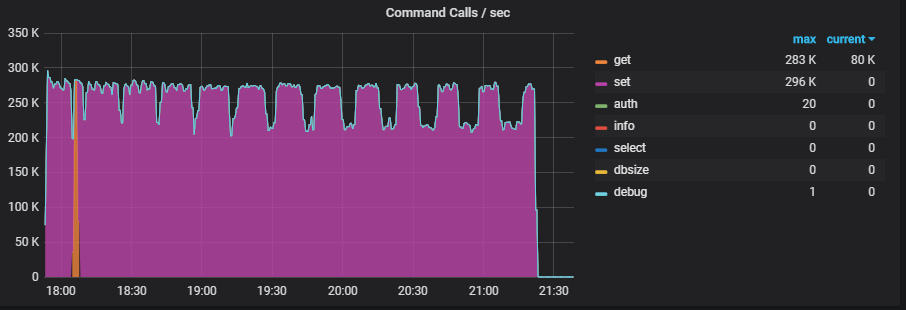
优化前后性能曲线
打开binlog删除,压30亿key,100G磁盘数据,命令为“set key value”。
优化前:
优化后:
注释:
这里的曲线是1分钟统计一次。
优化过程中提到的qps是1秒钟统计一次,而且是取的最高值。
所以这个曲线反应的qps会略低于上面优化过程中提到的qps。
