




SQL解析是数据库中间件开发中绕不开的话题,本文将阐述He3Proxy中如何实现SQL解析。
1. SQL解析器
相信做开发的同学对数据库SQL的执行过程都能说出一二:连接器(协议层)、解析器、优化器、执行计划、执行引擎、存储引擎......
但具体到某个模块时可能就说不清楚了;自己也喜欢各种技术都去蹭蹭,鲜有深入了解,慢慢发现深入了解某个点后才能找到技术的乐趣。今晚我们就一起深入了解下SQL处理过程中的Parser功能。
1.1 词法分析
词法分析主要是把输入转化成若干个tokens,包含key和非key。比如,一个简单的SQL如下所示:
SELECT age FROM user在分析之后,会得到4个Token,其中有2个key,它们分别是SELECT、FROM。
| key | 非key | key | 非key |
| SELECT | age | FROM | user |
1.2 语法分析
语法分析是生成语法树的过程,这是整个解析过程中最核心、最复杂的环节。
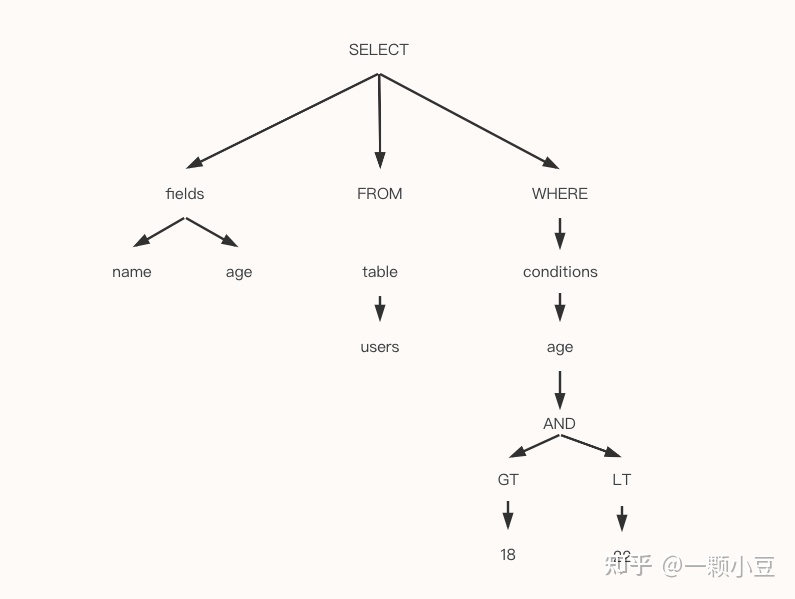
例如,如下SQL语句:
SELECT name, age from users where age > 18 and age < 22解析上述SQL时会生成如下语法数:
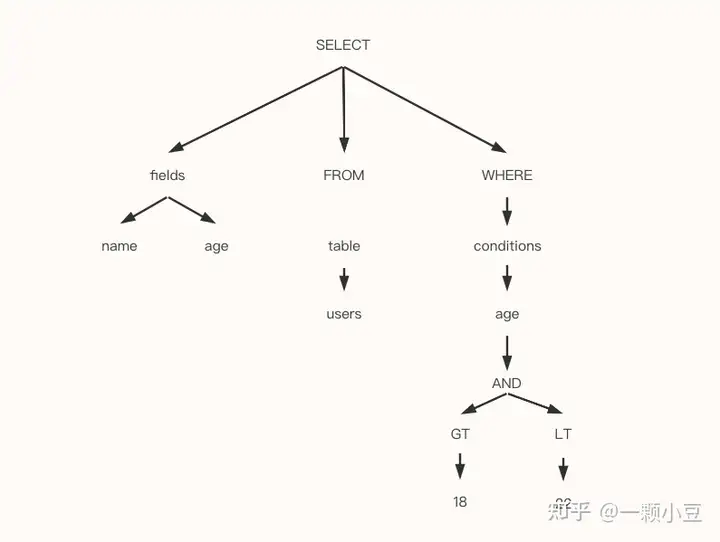
1.3 解析工具
有了上述感性的认识后,那么怎么实现这些功能呢?我们需要了解两个工具 Lex & Yacc 。(本文聚焦GO生态,java生态可以看看 Apache Calcite、antlr)
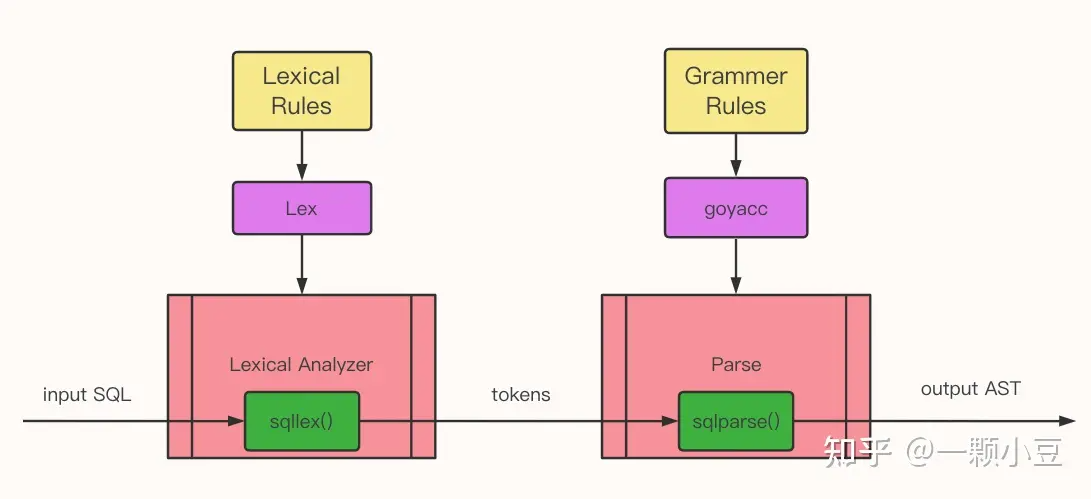
Lex根据用户定义的patterns生成词法分析器。词法分析器读取SQL,根据patterns将SQL转换成tokens输出。Yacc根据用户定义的语法规则生成语法分析器。
语法分析器以词法分析器输出的tokens作为输入,根据语法规则创建出语法树。最后对语法树遍历生成输出结果,结果可以是产生机器代码,或者是边遍历AST边解释执行。
GO语言中实现语法解析不得不提goyacc,goyacc是 golang 版的Yacc,和Yacc的功能一样,对词法解析器接口有一定要求,需要关注 “.y” 文件的格式及内容,文件内容包括三部分definitions、rules、subroutines,一般只需要关注前两部分,后续编码演示我们也可以看出,另外需要了解 .y 文件如何转换为 go 文件,详细的说明可参考官方文档 goyacc,值得注意的是go 1.8版本后默认tools不包含yacc,需要手动编译安装,“合理”上网的前提下安装步骤很简单。
词法分析器多数数据库(如crdb、tidb)选择自己编写,实现了goyacc要求的接口,这部分一般很少需要修改。
整体流程如下:
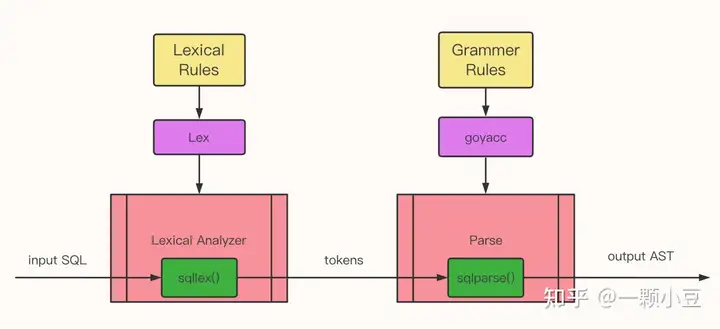
2. Coding
对程序员而言,再华丽的词藻不如两行代码来的实惠,下面我们就试着完成一条新增sql语法的解析工作,但从零开始完全实现,难度还是相当大,日常工作中一般也不会这么做、也没机会或足够时间去从零实现,而且价值也不大,因此我们站在开源大神的肩膀上,在框架上能去扩展、使用就显得更加实惠;语言依然使用 GO语言。
CRDB是GO语言生态中对PG语法兼容性较好的数据库,我们使用 postgresql-parser 项目作为基石,postgresql-parser 是从CRDB项目中抠出的parser模块,可以将sql语句转化为AST,具体参见项目介绍。
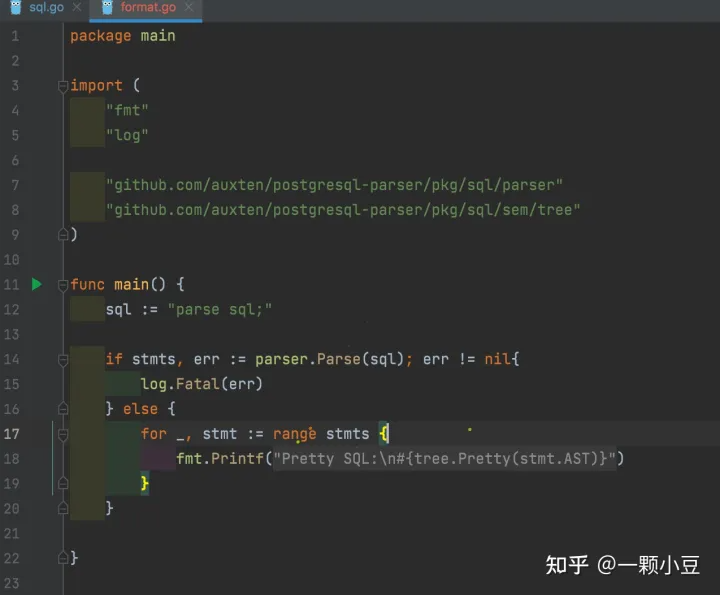
以parse sql为例,演示如何新加入一种sql语法解析,先看看未添加时解析 “parse sql” 语句的报错信息:
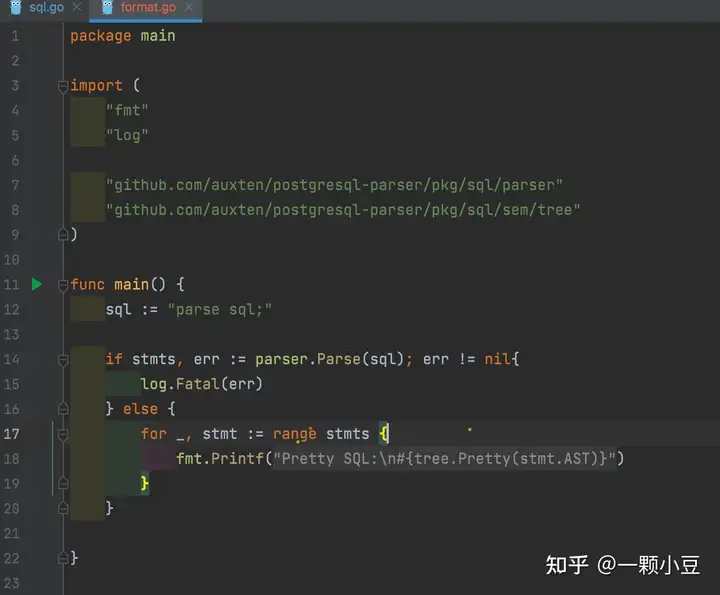
执行报错:
2022/07/13 14:38:51 at or near "parse": syntax error2.1 定义关键字
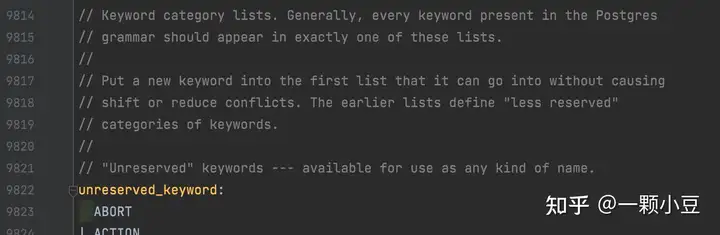
打开pkg/sql/parser/sql.y文件,搜索 “Ordinary key words”,会看到按照字母排序的一系列关键字定义,由于SQL关键字已经被定义,所以我们只需添加关键字 PARSE
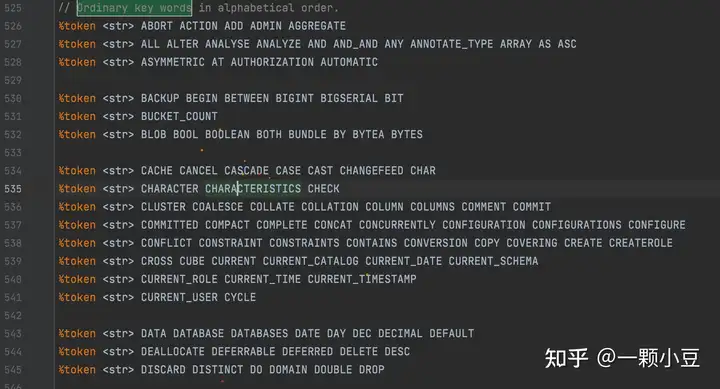

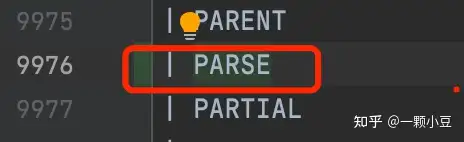
词法分析器可以通过以上定义识别关键字,由于新定义的关键字仍可以用于其他标识符中,因此我们还需要将PARSE添加到unreserved_keyword中,sql.y文件中搜索 "unreserved_keyword:" ,并将PARSE添加进去。
2.2 解析器处理语句
为使解析器可以处理新添加的语句,需要在三个地方添加处理逻辑:类型列表、语句类型列表 、 解析子句。
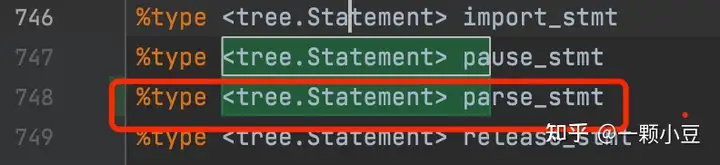
在sql.y中搜索 "<tree.Statement>" 并添加新语句类型,如:
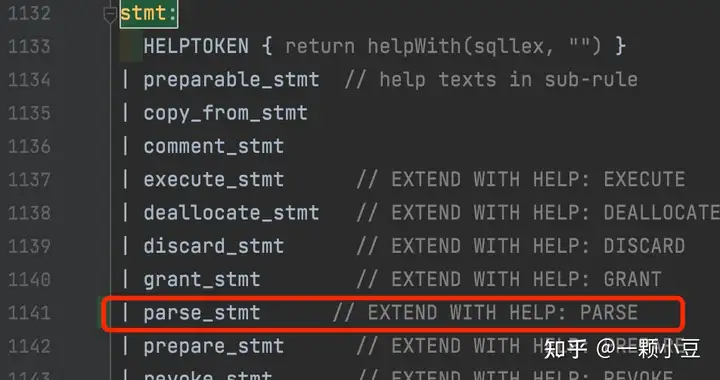
接着搜索"stmt:" ,将语句类型添加进去;
最后,为语句添加一个处理规则,sql.y中搜索 "// %Help: PREPARE" 并添加如下规则:
// %Help: PARSE - test new sql statement
// %Category: Misc
// %Text: PARSE { SQL }
parse_stmt:
PARSE SQL { return unimplemented(sqllex, "parse sql") }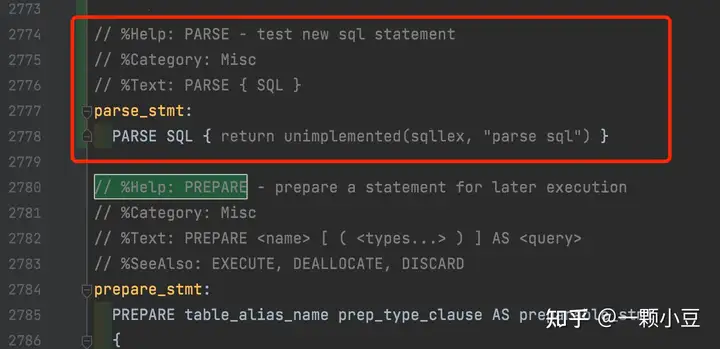
先把处理逻辑省略,直接返回一个未实现错误,具体实现待会再处理,我们先做个测试看解析器是否能够识别新语句;
首先重新生成sql.go文件,即根据定义的 .y 文件生成go文件,这里直接使用项目Makefile定义好的脚本,执行: make generate
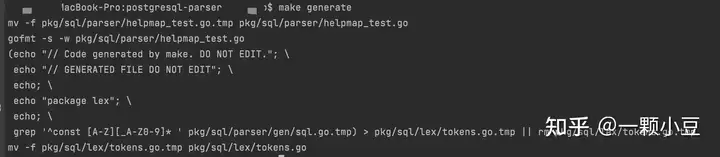
检查sql.go文件是否有新定义的语句生成:
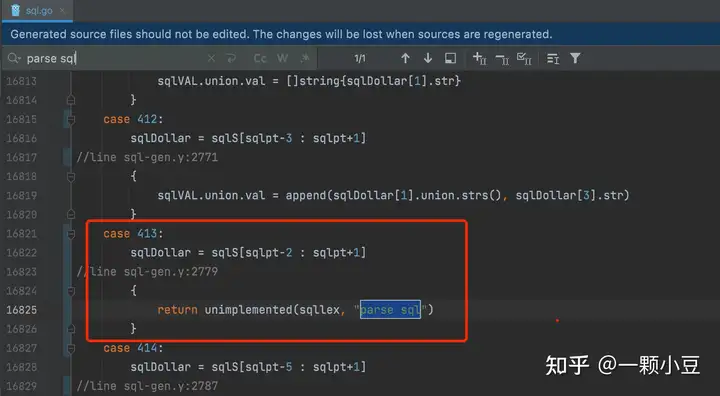
再测试下Parse函数执行的结果:
2022/07/13 15:58:37 at or near "sql": syntax error: unimplemented: this syntax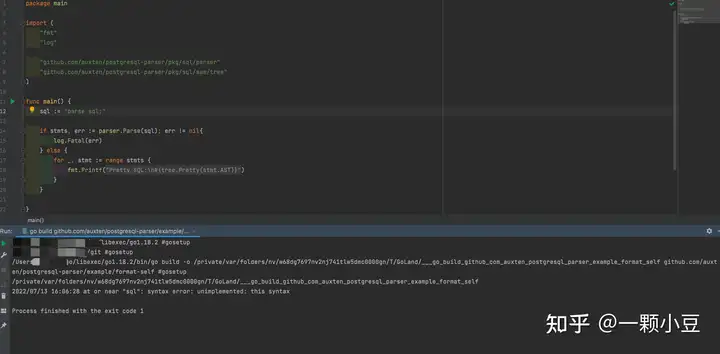
可以看出这次与未添加语句之前的错误有所不同,已经可以识别语句,该错误说明该语句未实现。
注:编译运行过程中可能会遇到一些包引入错误,按照截图添加、删除即可;
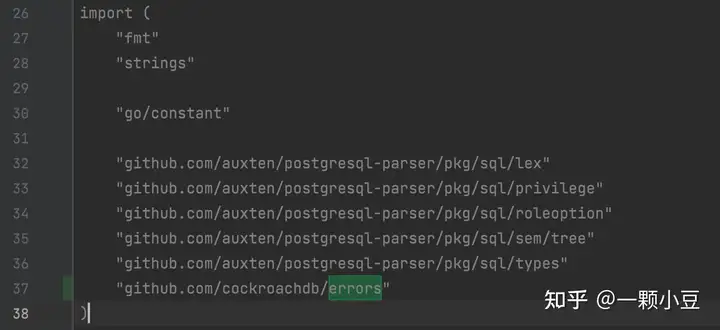
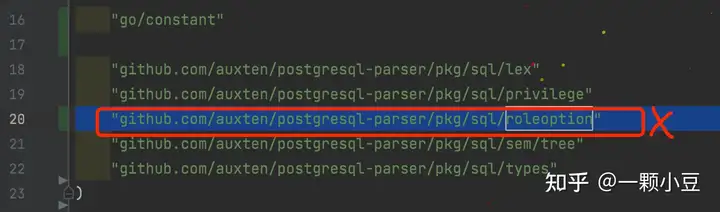
2.3 AST
上面仅处理了语法识别,还需要给新语句提供适当的语义。因此需要一个 AST 节点来将语句的结构从解析器传递到运行时,所以需要实现 tree.Statement接口,需要编写四个函数:三个用于Statement接口本身(StatementReturnType,StatementTypeand StatementTag),一个用于 NodeFormatter(Format)。
创建一个新文件:pkg/sql/sem/tree/parse_sql.go. 在其中,放入 AST 节点的格式和定义,并实现三个方法String()、StatementType() 、StatementTag()(最新的crdb代码还多了其他方法):
package tree
type Parse struct {
Mode ParseMode
}
func (node *Parse) String() string {
return AsString(node)
}
func (node *Parse) StatementType() StatementType {
return Ack
}
func (node *Parse) StatementTag() string {
return "PARSE"
}
var _ Statement = &Parse{}
type ParseMode int
const (
ParseModeSQL ParseMode = iota
)
func (node *Parse) Format(ctx *FmtCtx) {
ctx.WriteString("PARSE ")
switch node.Mode {
case ParseModeSQL:
ctx.WriteString("SQL")
}
}
最后修改解析器处理函数,sql.y文件,$$.val表示此规则生成的node值:
PARSE SQL { $$.val = &tree.Parse{Mode: tree.ParseModeSQL} }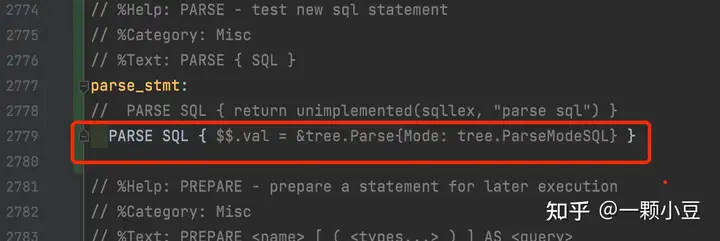
再次 make generate,再次执行 Parse方法,得到结果如下:
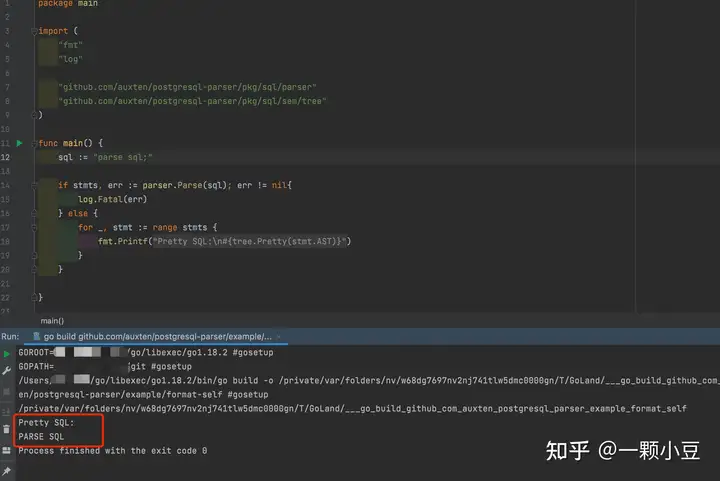
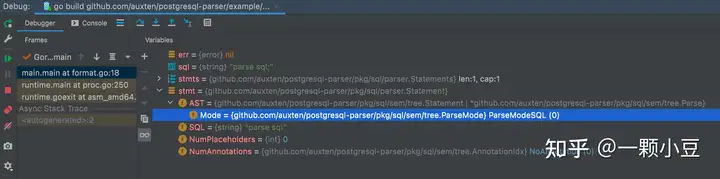
至此,我们就完成了一条新SQL的语法解析并生成了对应的AST,当然这仅仅是语法解析,真正完成整条SQL的执行链路还有很长的路要走。
由于人力、时间等因素,He3Proxy选择直接使用如上包完成SQL解析,主要在负载均衡、读一致性等需要解析SQL语句的功能中使用,当然目前此包还不够完善,有些SQL语法支持度不够,后续还得结合实际需求进行优化。
3. 总结
首先介绍了SQL Parser中的词法、语法解析器的理论知识及相关工具(Lex&Yacc),然后通过一个PG 解析器的开源项目演示了如何新增SQL语法解析,希望对有需要的小伙伴有所帮助。
由于作者能力有限,文中错误不当之处望批评指正,感激不尽!
参考文献:
[1] https://pingcap.com/zh/blog/tidb-source-code-reading-5
[2] cockroach/01-sql-statement.md at master · cockroachdb/cockroach
[3] https://github.com/auxten/postgresql-parser
[4] SQL解析器详解
注:本文以先发布于 一颗小豆:SQL解析器原理及实现剖析SQL解析是数据库中间件开发中绕不开的话题,本文将阐述He3Proxy中如何实现SQL解析。
1. SQL解析器
相信做开发的同学对数据库SQL的执行过程都能说出一二:连接器(协议层)、解析器、优化器、执行计划、执行引擎、存储引擎......
但具体到某个模块时可能就说不清楚了;自己也喜欢各种技术都去蹭蹭,鲜有深入了解,慢慢发现深入了解某个点后才能找到技术的乐趣。今晚我们就一起深入了解下SQL处理过程中的Parser功能。
1.1 词法分析
词法分析主要是把输入转化成若干个tokens,包含key和非key。比如,一个简单的SQL如下所示:
SELECT age FROM user在分析之后,会得到4个Token,其中有2个key,它们分别是SELECT、FROM。
| key | 非key | key | 非key |
| SELECT | age | FROM | user |
1.2 语法分析
语法分析是生成语法树的过程,这是整个解析过程中最核心、最复杂的环节。
例如,如下SQL语句:
SELECT name, age from users where age > 18 and age < 22解析上述SQL时会生成如下语法数:
1.3 解析工具
有了上述感性的认识后,那么怎么实现这些功能呢?我们需要了解两个工具 Lex & Yacc 。(本文聚焦GO生态,java生态可以看看 Apache Calcite、antlr)
Lex根据用户定义的patterns生成词法分析器。词法分析器读取SQL,根据patterns将SQL转换成tokens输出。Yacc根据用户定义的语法规则生成语法分析器。
语法分析器以词法分析器输出的tokens作为输入,根据语法规则创建出语法树。最后对语法树遍历生成输出结果,结果可以是产生机器代码,或者是边遍历AST边解释执行。
GO语言中实现语法解析不得不提goyacc,goyacc是 golang 版的Yacc,和Yacc的功能一样,对词法解析器接口有一定要求,需要关注 “.y” 文件的格式及内容,文件内容包括三部分definitions、rules、subroutines,一般只需要关注前两部分,后续编码演示我们也可以看出,另外需要了解 .y 文件如何转换为 go 文件,详细的说明可参考官方文档 goyacc,值得注意的是go 1.8版本后默认tools不包含yacc,需要手动编译安装,“合理”上网的前提下安装步骤很简单。
词法分析器多数数据库(如crdb、tidb)选择自己编写,实现了goyacc要求的接口,这部分一般很少需要修改。
整体流程如下:
2. Coding
对程序员而言,再华丽的词藻不如两行代码来的实惠,下面我们就试着完成一条新增sql语法的解析工作,但从零开始完全实现,难度还是相当大,日常工作中一般也不会这么做、也没机会或足够时间去从零实现,而且价值也不大,因此我们站在开源大神的肩膀上,在框架上能去扩展、使用就显得更加实惠;语言依然使用 GO语言。
CRDB是GO语言生态中对PG语法兼容性较好的数据库,我们使用 postgresql-parser 项目作为基石,postgresql-parser 是从CRDB项目中抠出的parser模块,可以将sql语句转化为AST,具体参见项目介绍。
以parse sql为例,演示如何新加入一种sql语法解析,先看看未添加时解析 “parse sql” 语句的报错信息:
执行报错:
2022/07/13 14:38:51 at or near "parse": syntax error2.1 定义关键字
打开pkg/sql/parser/sql.y文件,搜索 “Ordinary key words”,会看到按照字母排序的一系列关键字定义,由于SQL关键字已经被定义,所以我们只需添加关键字 PARSE
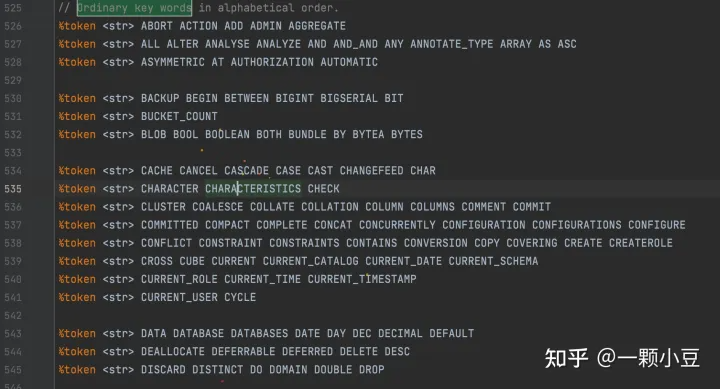

词法分析器可以通过以上定义识别关键字,由于新定义的关键字仍可以用于其他标识符中,因此我们还需要将PARSE添加到unreserved_keyword中,sql.y文件中搜索 "unreserved_keyword:" ,并将PARSE添加进去。
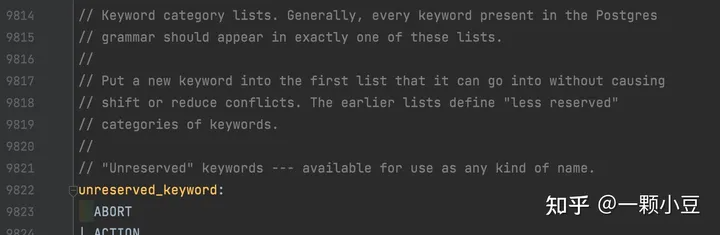
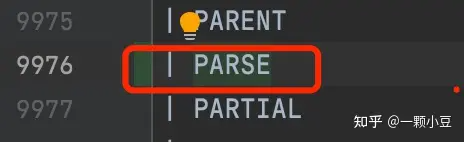
2.2 解析器处理语句
为使解析器可以处理新添加的语句,需要在三个地方添加处理逻辑:类型列表、语句类型列表 、 解析子句。
在sql.y中搜索 "<tree.Statement>" 并添加新语句类型,如:
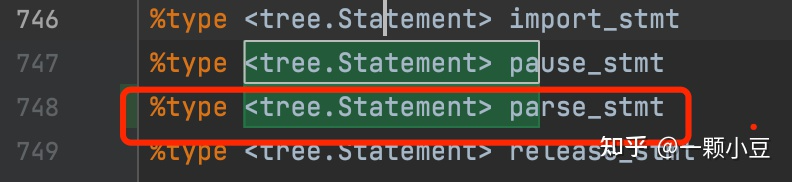
接着搜索"stmt:" ,将语句类型添加进去;
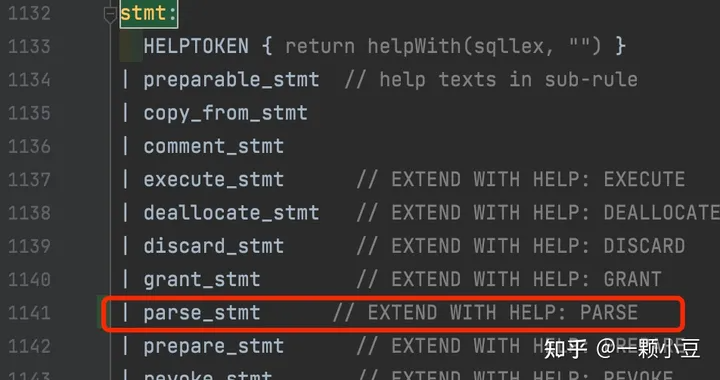
最后,为语句添加一个处理规则,sql.y中搜索 "// %Help: PREPARE" 并添加如下规则:
// %Help: PARSE - test new sql statement
// %Category: Misc
// %Text: PARSE { SQL }
parse_stmt:
PARSE SQL { return unimplemented(sqllex, "parse sql") }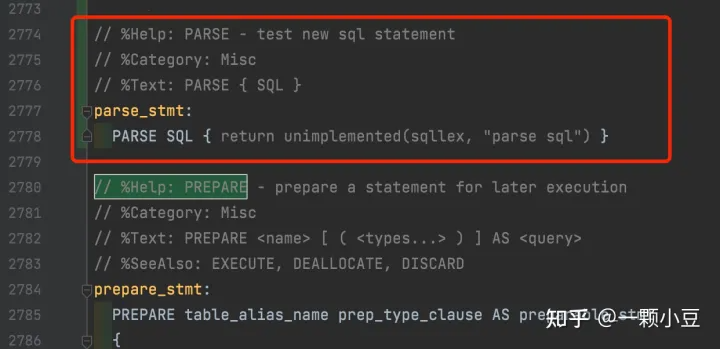
先把处理逻辑省略,直接返回一个未实现错误,具体实现待会再处理,我们先做个测试看解析器是否能够识别新语句;
首先重新生成sql.go文件,即根据定义的 .y 文件生成go文件,这里直接使用项目Makefile定义好的脚本,执行: make generate
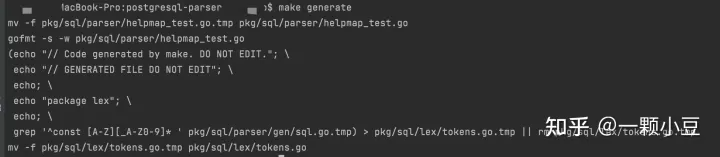
检查sql.go文件是否有新定义的语句生成:
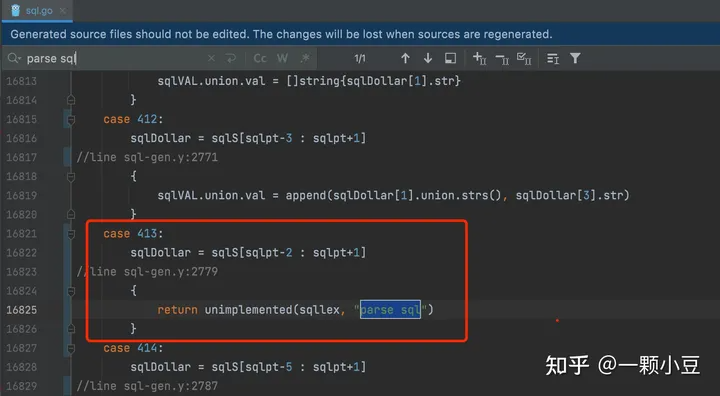
再测试下Parse函数执行的结果:
2022/07/13 15:58:37 at or near "sql": syntax error: unimplemented: this syntax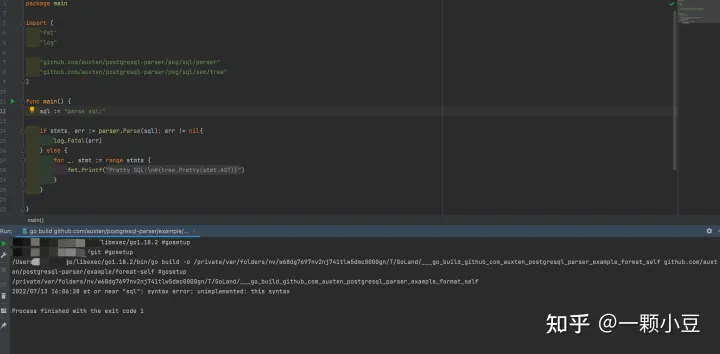
可以看出这次与未添加语句之前的错误有所不同,已经可以识别语句,该错误说明该语句未实现。
注:编译运行过程中可能会遇到一些包引入错误,按照截图添加、删除即可;
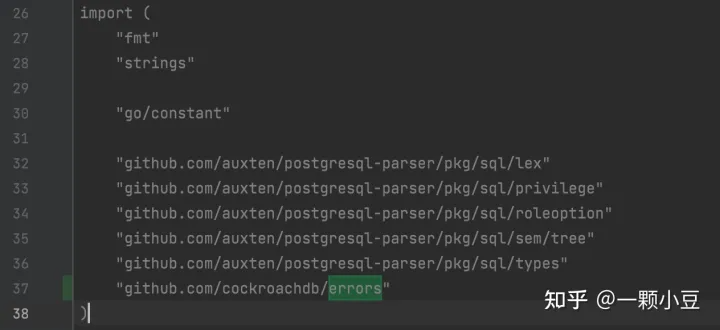
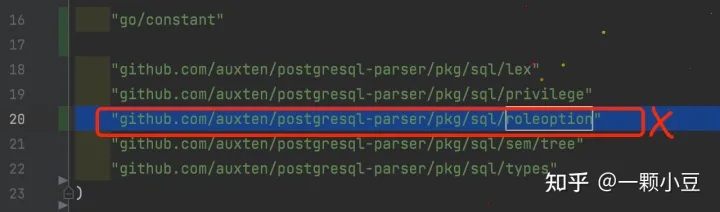
2.3 AST
上面仅处理了语法识别,还需要给新语句提供适当的语义。因此需要一个 AST 节点来将语句的结构从解析器传递到运行时,所以需要实现 tree.Statement接口,需要编写四个函数:三个用于Statement接口本身(StatementReturnType,StatementTypeand StatementTag),一个用于 NodeFormatter(Format)。
创建一个新文件:pkg/sql/sem/tree/parse_sql.go. 在其中,放入 AST 节点的格式和定义,并实现三个方法String()、StatementType() 、StatementTag()(最新的crdb代码还多了其他方法):
package tree
type Parse struct {
Mode ParseMode
}
func (node *Parse) String() string {
return AsString(node)
}
func (node *Parse) StatementType() StatementType {
return Ack
}
func (node *Parse) StatementTag() string {
return "PARSE"
}
var _ Statement = &Parse{}
type ParseMode int
const (
ParseModeSQL ParseMode = iota
)
func (node *Parse) Format(ctx *FmtCtx) {
ctx.WriteString("PARSE ")
switch node.Mode {
case ParseModeSQL:
ctx.WriteString("SQL")
}
}
最后修改解析器处理函数,sql.y文件,$$.val表示此规则生成的node值:
PARSE SQL { $$.val = &tree.Parse{Mode: tree.ParseModeSQL} }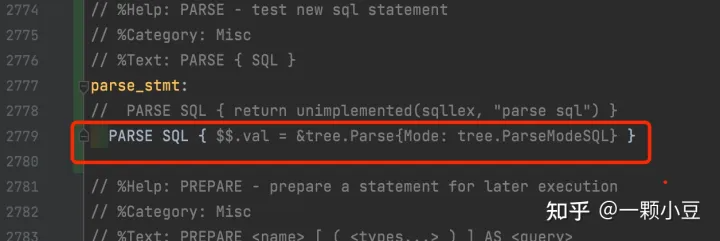
再次 make generate,再次执行 Parse方法,得到结果如下:
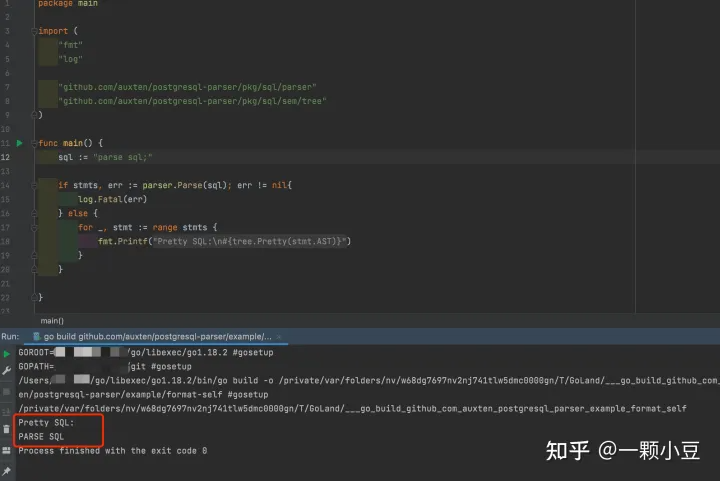
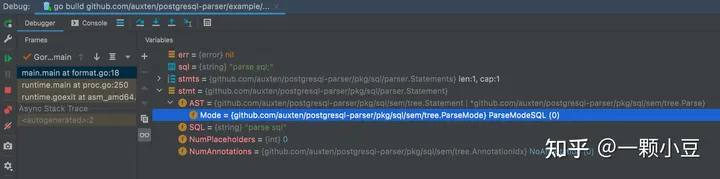
至此,我们就完成了一条新SQL的语法解析并生成了对应的AST,当然这仅仅是语法解析,真正完成整条SQL的执行链路还有很长的路要走。
由于人力、时间等因素,He3Proxy选择直接使用如上包完成SQL解析,主要在负载均衡、读一致性等需要解析SQL语句的功能中使用,当然目前此包还不够完善,有些SQL语法支持度不够,后续还得结合实际需求进行优化。
3. 总结
首先介绍了SQL Parser中的词法、语法解析器的理论知识及相关工具(Lex&Yacc),然后通过一个PG 解析器的开源项目演示了如何新增SQL语法解析,希望对有需要的小伙伴有所帮助。
由于作者能力有限,文中错误不当之处望批评指正,感激不尽!
参考文献:
[1] https://pingcap.com/zh/blog/tidb-source-code-reading-5
[2] cockroach/01-sql-statement.md at master · cockroachdb/cockroach
[3] https://github.com/auxten/postgresql-parser
[4] SQL解析器详解
注:本文以先发布于 一颗小豆:SQL解析器原理及实现剖析
