近期,全球首个金融图数据库基准测试 LDBC Finbench 正式发布,填补了金融图数据库领域测试基准的空白。作为牵头方,蚂蚁集团图平台负责人洪春涛博士应邀出席世界人工智能大会-图技术激活数据要素论坛,分享了 LDBC Finbench 金融图数据库测试国际标准的工作成果,以下为演讲实录(部分内容有调整)。
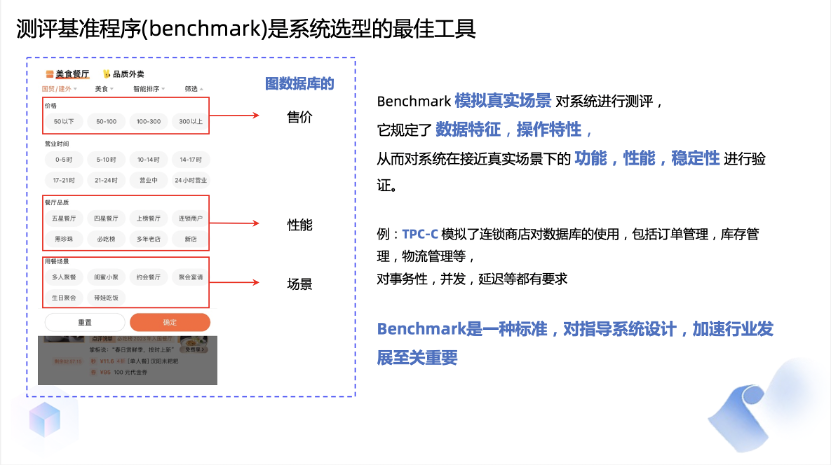
今天想与大家分享的是我们最近进行的一项工作,即LDBC-FinBench,首个金融图数据库测试基准。首先,我想介绍一下测试基准是什么。就像我们购买东西一样,我们需要一些衡量指标来评估其价格是否合理。同样地,在购买数据库时,我们也需要一套标准来进行测试和评估。因此,在关系数据库中,我们有一些著名的测试基准,如TPC-C和TPC-H。然而,在图数据库这个相对较新的数据库领域,缺乏相应的测试基准。而蚂蚁正好在金融图数据库应用方面有着丰富的经验。因此,我们希望通过我们自己的实践经验,提取出一些东西,制定一套可以帮助金融机构评估图数据库性能的标准。这就是我们创建FinBench的初衷。图数据库仍然是相对较新的技术,缺乏统一的标准。与关系数据库不同,图数据库的查询语言目前还没有国际标准。ISO组织正在制定这样一个标准,蚂蚁也参与其中并提出了一些建议。但这个标准预计在今年年底左右才会发布第一个版本。因此,目前在查询语言领域,每个数据库都有自己的一套规则,这给客户带来了很大的困扰。客户今天选择了一种图数据库,明天又选择另一种,就需要学习不同的查询语言,这增加了成本。另外,目前在图数据库领域,我们也面临着图模型的多样性,比如最常用的是RDF和属性图模型。还有管理功能,这些差异更加显著。几乎每个数据库都有自己独特的特点。因此,我们意识到对于外部客户来说,选择图数据库非常困难,因为每个图数据库的差异都太大,缺乏一个客观、准确的比较方式。为了选择一个东西,我们总是需要一些标准,这是一个比较的基础,你可以根据这些指标来评估它的好坏。对于数据库来说,我们也会关注一系列的指标,当然我们可能更关注其中某一部分指标,并根据这些指标来评估数据库。在关系数据库中,我们已经有了一些标准,如TPC-C和TPC-H。这些标准是如何制定的呢?基本上是基于假设的使用场景,模拟在这些场景下用户对数据库的一系列要求,然后看数据库在运行过程中对这些要求的满足程度。以TPC-C为例,它模拟了一个包含多个仓库的零售体系。比如沃尔玛等连锁超市,它们有许多个仓库,需要一个统一的数据库来管理库存、订货和销售等指标。最终评价的指标就是,这个数据库上包括硬件、软件等,花多少钱能达到什么样的性能,然后把性能除以价格,得到了一个性价比。TPC-C基本上模拟了这样一个业务场景。
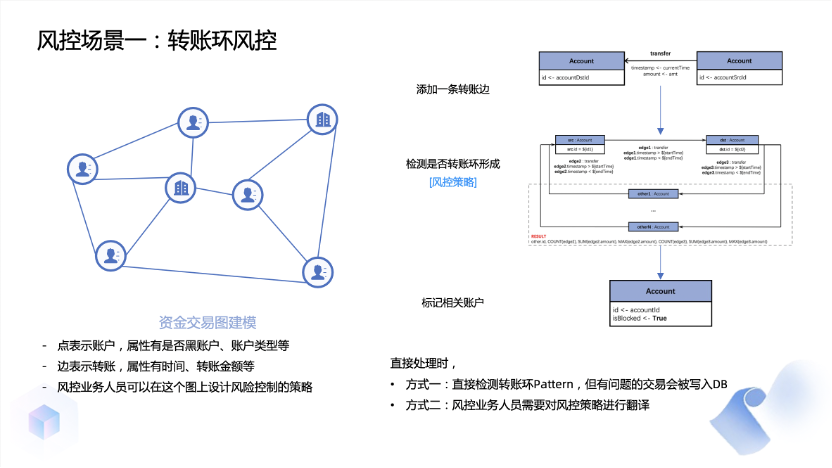
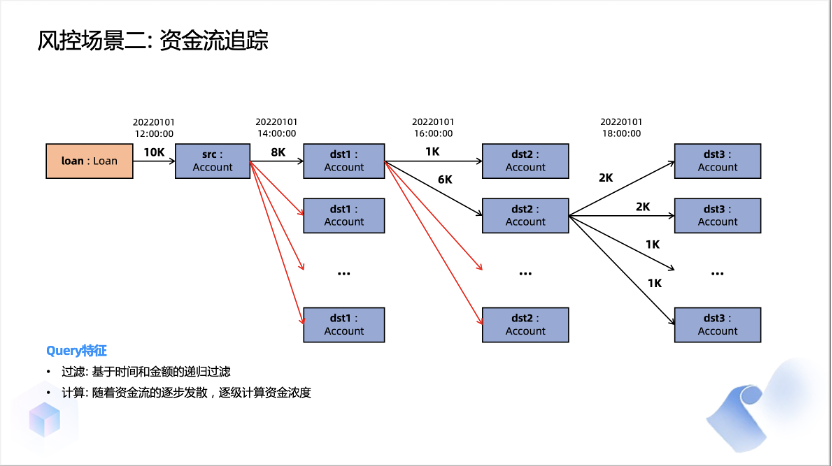
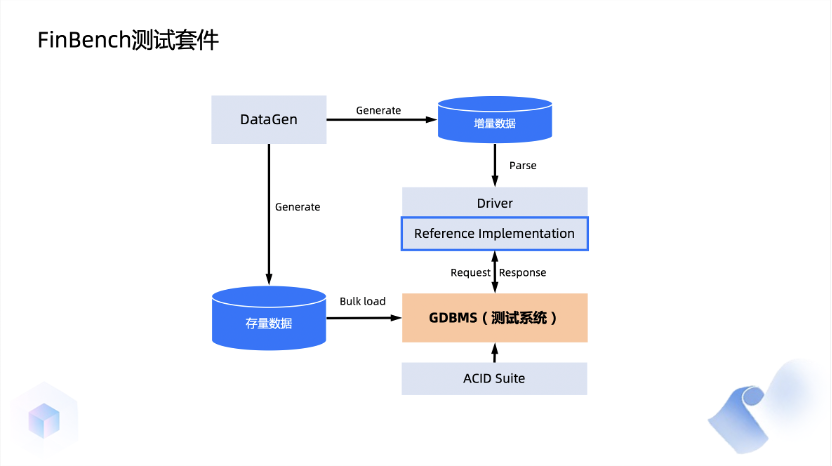
在关系数据库领域,大家通常会提到 TPC这个组织,它制定了包括TPC-C,TPC-H在内的一系列测试基准。而在图数据库领域,LDBC(Linked Data Benchmark Council)是被广泛认可的组织。LDBC的成员包括蚂蚁集团,Oracle、微软、Facebook、Google等大公司,它们都在开发图数据库,并共同制定标准。在LDBC组织中,已有几个测试基准,如SPB (Semantic Publishing Benchmark) ,SNB(Social Network Benchmark)等。其中SNB是目前使用最广的一个测试基准,但它偏向社交场景。我们发现金融领域的数据和模式与社交网络有很大的不同。因此,直接使用社交网络的测试基准来评估数据库无法准确反映金融领域的表现。因此,我们决定带头创建一个新的测试标准,称之为FinBench(Financial Benchmark)。我们在LDBC框架下进行工作,并组建了一个由九家公司组成的工作小组。在最近的数据库大会SIGMOD 2023上,我们发布了这个标准的第一个版本,并将持续迭代和丰富它,以使其更加准确和全面。今天,我简单向大家介绍下这个benchmark设计相关的内容。FinBench模拟了金融风控领域的一些应用场景。目前,我们有几类数据,包括公司、账户、贷款和设备(手机或电脑)。在风控领域,这些信息非常重要。接下来,我将简要介绍两个查询,实际上我们在FinBench中有十几个不同的查询和写入操作。第一个是关于环检测的场景。在这个场景中,我们要找出一笔新增交易是否会使图上构成一个环。当然,并不是所有的环都是不好的,它们需要满足一定的过滤条件。例如,环上的边必须在某个时间段内发生。比如你不能说去年的一笔交易与今年形成了环,然后就认为是黑灰产,因为它还有其他属性上的要求。对于环检测,我们还有一个规定,即当我要转账时,我要决定是否允许这张账户进行转账。如果发现这笔交易会构成一个欺诈环,那么我就不应该让它通过,那么这条新的边也就不应该存在。这就形成了一个所谓的读写查询,先读后写的查询。如果发现是一个环,就不写入这条边;如果不构成环,那么这个边就是好的,我应该将其写入。举个简单的例子,支付平台会向用户发送优惠券,而黑灰产用户会通过虚构交易来将优惠券中的钱套现出来。这就是通过环检测来实现的,所以在金融领域,环检测是非常常见的模式。第二个例子是资金流的追踪,这在金融领域中非常常见。以贷款之后的资金流追踪为例。假如我有一个账户,贷了一笔个人消费贷款。对于银行来说,他们不希望你把这笔贷款用于消费以外的其他用途,因此在贷款时他们会给你一个协议,明确规定这笔钱只能用于消费,不能用于购房、炒股,更不能用于赌博。因此,他们会试图追踪这笔钱的用途。如果这笔钱被用于购房,银行认为你违约,他们会尽早追讨这笔钱,因为这带来风险。所以,像这样的情况下,他们需要进行资金流追踪。最简单的情况当然是你带了钱直接转给恒大去买房子,这只涉及两个节点。但实际情况也可能更复杂一些,例如我贷了30万,转给我妻子,她再去买房。所以在这种情况下,你需要进行多跳的追踪资金流。此外,每一笔交易的时间限制也很重要,每一笔金额也有限制,不能说我今天贷了3万,但我去年买了套房,你就认为我违规。因此,在资金流追踪中有许多限制条件,我们需要追踪符合这些条件的交易。资金流追踪中涉及到图数据库的多项能力。其中第一个是所谓的递归路径。因为资金转账可能不仅限于一跳,往往需要追踪多跳。而其中每一笔交易都需要符合一个模式。例如,一种常见的过滤条件是每一笔转出的金额必须达到上一跳的一定比例才会去追踪,这样我们就只会追踪那些重要的交易。此外,它是逐跳向前的,并不限于一跳。你可能转了100跳,只要触发规则,我们也应该追踪所有这100跳。第二个是时间限制,每一笔交易的时间必须大于上一笔交易的时间。我必须确保这笔钱确实来自上一笔交易,而不是说我昨天转了100万,然后今天贷了30万,就认定我把贷款用在违规用途了。因此,时间限制是必要的。第三个是图中会有一些大点,有些人可能有许多转账,特别是公司账号。转出的交易笔数非常多。如果每一笔都进行追踪,系统将无法承受。因此,引入了所谓的”截断”,即只查看最近的100笔或1000笔交易,这个数量可以调整。这主要是为了处理大规模的情况。现在我们已经发布了0.1的版本,我们仍在不断更新这个版本。它包括一个数据生成器,一个driver,以及一些参考实现。生成器用于生成测试数据。我们不可能使用真实的数据进行测试,因为真实的数据涉及隐私和其他问题。同时,我们希望能够测试不同数据量下的性能。因此,我们不能仅仅依赖一个固定规模的数据来进行测试。假如我们只有100GB的数据,如果我有一个1TB或更大规模的数据怎么办?因此,数据生成器负责生成不同规模的数据。生成数据后,我们使用一个所谓的"Driver"来运行数据库。该驱动程序负责将输入传递给数据库。当然,在这个过程中会涉及很多细节。例如,我以多大的速度向数据库中注入数据,数据库返回结果后,我需要检查请求是否超时。超时对我们的实际系统影响很大。因为我不能说发出一个请求,然后数据库一个小时后才返回给我。这样即使数据库吞吐量很大,也是不可接受的。因此,这个驱动程序的主要任务是向数据库发送请求,然后等待返回结果,然后检查结果是否正确,延迟是否可接受。
在测试,我们需要测试不同的数据库,对不同的数据库进行验证。这就需要一个通用接口,所有的数据库都必须按照这个接口进行实现,以实现相同的逻辑。我们目前也提供了几个不同数据库的参考实现,其中就包含TuGraph。目前,我们的版本0.1中,数据集可以生成不同规模的数据。但目前我们只测试了不大于10GB的数据,我们正在继续增加这个范围,希望能够支持更大规模的数据集。这方面存在一个主要问题,即生成的数据必须符合实际的分布。例如,每个点之间的关联数量,这个关联分布是可以统计出来的,但在生成数据时如何保证生成的数据与该分布一致,本身就是一门学问。而且这只是一维的情况,同时每个点还需要满足其使用的设备也符合一定的规律,这个多维的分布约束更加困难。因此,目前我们仍在不断优化这一部分。目前,我们有12个相对复杂的查询和6个相对简单的查询,以及19个写查询。同时,我们还在测试中包含了ACID测试,以测试数据库本身的原子性和持久性等特性。因为作为一个金融级的系统,这些特性对其非常重要,数据不能丢失,丢失数据将是一个严重的问题。整个项目从去年二月份开始提出提案,一直持续沟通,到今年六月份启动项目,大家开始工作。然后在今年六月份,大约一年的时间开发了第一个版本。参与这个项目的有九家公司。目前,该项目已经发布了第一个版本,但像之前提到的,仍然存在许多问题需要解决。我们也意识到需要持续更新和改进,因为这种标准是随着时间不断演进的。包括之前提到的实时应用和复杂计算,我们在金融场景中经常使用。如何在这个框架下支持不同的离线应用也是未来的工作之一。FinBench这个项目是一个开源项目,这些代码和实现都是公开的。同时,我们还实现了几个不同数据库的参考实现。例如,刚才提到的大量查询和数据库实现的逻辑,因此,如果有新的数据库需要进行测试,可以参考这些实现并在此基础上进行开发。我们也欢迎更多的人来改进这个国际测试标准,并欢迎大家进行讨论。谢谢大家。
欢迎关注 TuGraph 代码仓库
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
最后修改时间:2023-07-11 09:23:20
文章转载自
TuGraph,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。