




点击蓝字 关注我们
大家好,来自恒生电子的马骋原。我在大数据相关的基础研发方面工作,是 Apache SeaTunnel 的贡献者。之前还是阿里开源组件 Canal 的 Committer 。
文|马骋原
编辑整理| 曾辉
讲师介绍

马骋原
社区贡献者
SeaTunnel Transform Plugin
今天我要分享的是 Apache SeaTunnel 的 SQL transform 插件实现。主要讲解几个方面,首先是介绍 Apache SeaTunnel 的 transform 插件原理,然后是 SQL transform 插件的实现,以及 transform 插件和 UDF 的实现。
之后,我会进一步扩展两个主题,一个是基于 SQL 的 Join transform 的扩展,另一个是 CDC 场景下维表更新的扩展。
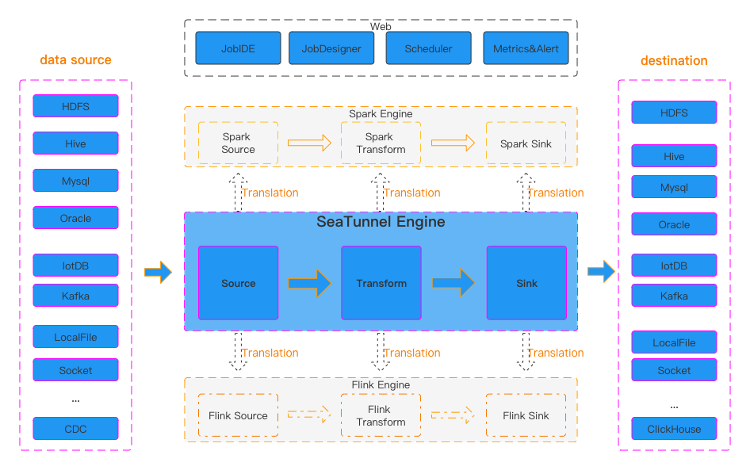
这是官网上的 Apache SeaTunnel 架构图,左边是 Apache SeaTunnel 的源端,右边是目标端,中间是 Apache SeaTunnel 的引擎。数据从源端读取,经过中间的 transform 层,最后写入目标端的 Sink。它支持 Spark 和 Flink 等外部引擎提交读写和转换任务,因此在 Spark 和 Flin k中也有相应的 Source 和 Sink 转换层,用于数据的读写和转换。
在旧版本中,读写是基于外部引擎端的 Connect 能力进行的,因此旧版本支持 SQL 转换。然而,旧版本的 SQL 转换与 Spark SQL 和 Flink SQL 紧密耦合。为了解耦,从2.3版本开始,将 Transform、Sink 和 Source 的 Connect 集成到自身的引擎中,并通过转换层将任务提交给 Spark 或 Flink 引擎进行计算和数据读写。
因此,从2.3版本开始,SQL能力被移除。

Plugin实现
要实现自己的 Transform 插件扩展,需要实现几个接口。其中一个是 SetConfig 接口,还有一个是 TransformType 接口,还有一个是 TransformRow 接口。
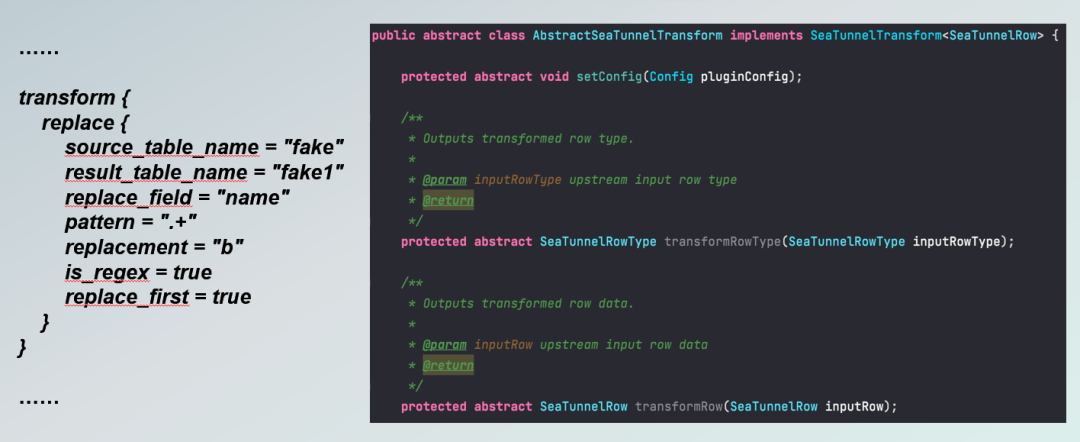
左侧是扩展实现的配置示例,输入表是上游的输出表,输出表可以作为下游的输入表。这是一个 replace 插件转换的示例。它还需要实现这些接口,其中 Transform type 是主要的,它的输入是输入行的每个字段类型,包括所有输入行的字段类型,输出是转换后输出行的所有字段类型。
TransformRow 是转换数据的核心接口,它接收上游的输入行数据,一行输入数据,按照定义的转换规则进行转换,并将转换结果与目标类型一起输出到下游。接下来介绍一下SQL transform插件的实现。
SQL transform 插件的配置比较简单,如图所示。

上游输入是从上游输入的表名,输出是输出的表名。下面直接写了一行 SQL ,进行 Select 操作,我在示例中加入了一些行数和计算逻辑。例如,Select id+1,然后 as id ;name 再拼接一个下划线 as name ;
还有 Dateadd(sys_time, 1) 即时间戳加日期加1。表名应该与 Source table name 保持一致,即与fake要保持一致,否则会报错。它还支持过滤条件。例如,只转换过滤id>10的数据。
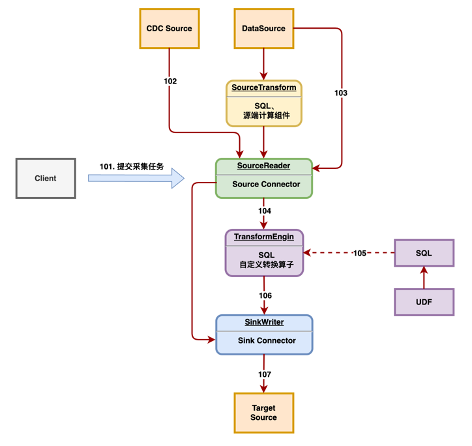
这是一个实现逻辑框图,上层是 Connector,Source 连接读取上游数据,上游数据可以是离线数据或实时数据源,下游是 Sink 层,主要在中间添加了 SQL 转换逻辑,并支持 UDF。
然后是扩展 Transform 层,将 SQL 能力包含进来。这是整体的 SQL 实现逻辑,在2.3.1版本中,SQL 仅支持简单的 SQL,就像我刚才展示的那个 SQL一样,类似于 Select 某些字段,然后加上相应的函数处理,还支持过滤条件。
因此,需要针对 SQL 进行解析,生成抽象语法树,然后生成物理执行计划。同时,它还内置了大量的函数库,包括常用的函数,如数字型、字符型和时间型函数等。还支持UDF,通过SPI插件的方式将自己开发的UDF集成到函数库中进行调用。
通过SQL的抽象语法树和物理执行计划解析后,会有两个步骤,一个是类型转换,一个是数据转换,即前面提到的两个接口方法。类型转换是根据输入类型转换为输出类型。不仅仅是字段的简单类型,类型转换可能还涉及到函数和常量.
例如,如果直接 Select 1,那么这里的1实际上是一个常量,因此需要对一些常量和函数进行类型转换。而函数通常有指定的返回类型,如数字函数和字符串函数都有固定的返回类型。但是在某些情况下,返回类型可能是不确定的,可能需要根据输入字段的类型来确定输出类型,因此需要递归处理函数以获取最终的返回类型。
下一层是数据转换器,通过物理执行计划、函数库和过滤条件对数据进行转换。它的输入是每个字段的值,即每行的每个字段的值,通过物理执行计划进行计算后,得到输出行的每个字段的值。
目前 SQL transform 插件仅支持基本的 map 端 Transform 能力,即小T能力,就像示例的 SQL 一样。目前仅支持对单行数据进行 Select 和条件过滤的语法。SQL 执行引擎内置了丰富的函数库,下面是 SQL 执行引擎内置的函数库示例,就像我之前写的函数示例一样:
SELECT id as id, upper(name) as name, dateadd(systime, 1) as systime FROM tuser
例如,ID 拼接下划线,然后 as ID ,upper 将 name 转换为大写,然后 as name,还可以对日期进行加减操作。这个函数库提供了非常多的函数,我大致统计了四五十种函数,并且支持嵌套,标准的SQL写法都支持。
下面我来介绍UDF的实现方式。如果我们基于原生的 Transform 插件进行扩展,相对来说会比较繁琐。
首先需要实现 TableTransformFactory 接口,这个接口是用来实现工厂类的,还需要实现 CheckTableTransform 抽象类。此外,还需要关注 Apache SeaTunnel transform 的配置项逻辑,需要手动关注和开发相应的处理逻辑。因此,在 SQL transform插件 中,我们支持了 UDF ,并提供了一套全新的自定义函数接口。在 SQL transform 插件的 UDF 中,只需要实现以下 SPI 接口即可。
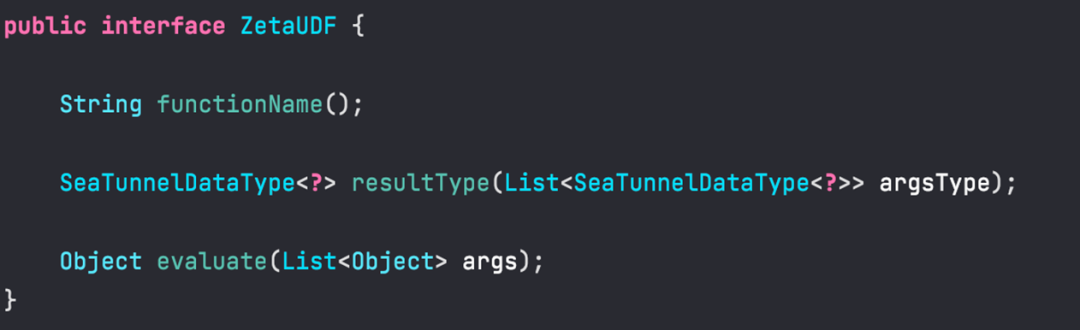
我们提供了一个名为 ZetaUDF 的 UDF 接口,它主要有三个方法。首先是getFunctionName(),这个方法返回函数的名称。然后是 getResultType(),用于指定函数的返回类型。前面提到,函数都有返回类型,大部分函数都指定了返回类型,但有些情况下返回类型是根据输入类型来确定的。最后是evaluator(),用于进行函数计算。它的输入参数是对应函数的输入参数值,经过计算后,返回确定的结果。

上图是针对 SQL transform 插件 UDF 的一个实现示例,这里是一个自定义的 DES 加密函数,只需要实现这三个方法。
可以看出,自定函数非常。第一个方法是定义函数的返回名称,这里函数名为desEncrypt。第二个方法是指定返回的结果类型,因为是针对字符串加密,所以返回的是字符串类型。最后是函数的计算逻辑,这里是针对输入值进行加密。函数的输入有两个值,一个是密码,另一个是对应的数据。
根据这个数据和密码进行加密,这里使用了DES加密库进行加密操作。通过实现这三个方法即可完成UDF的开发。
可以明显看到,相对于我们之前提到的对于 Transform 的扩展,UDF 的开发更加方便,因为我们只需要关注对应函数的输入参数值和类型,而不需要关注整行数据。
03
扩展规划
接下来是两个议题,一个是关于 SQL transform 扩展的规划,一个是关于 Join 的规划。
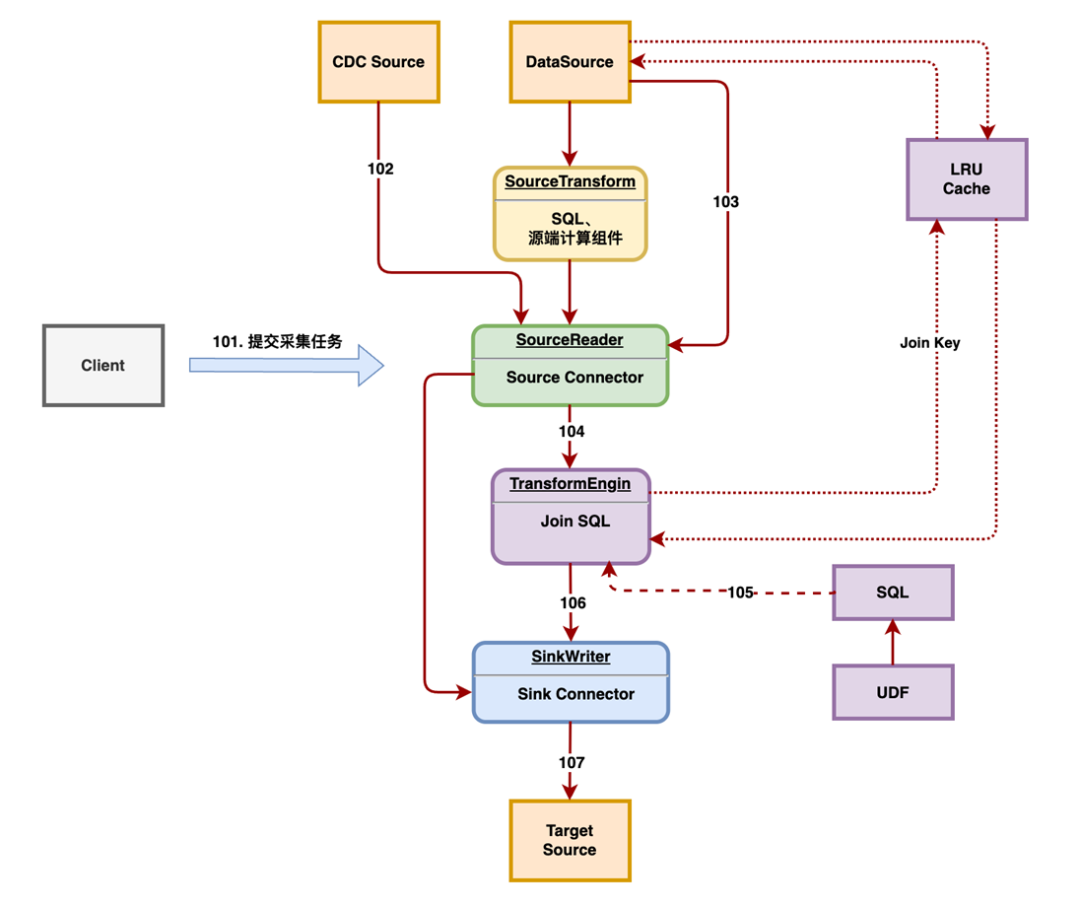
目前我们只支持了简单的 SQL 能力,接下来的规划是将 Join 能力加入进来,即图中的扩展。
当我们需要拼接 Join 信息时,在这里获取数据时,每行数据有一个主表,然后租户表会从缓存中读取 Join 信息,如果缓存中不存在,可能会从数据源中查询原表中对应的维表信息,或者将维表信息查询出来后缓存到 LRU 缓存中,然后进行 Join 的物理执行计划拼接,最后将数据拼接成一行框表的数据,并写入到相应的目标库中。
在 SQL transform 插件的 Join 功能中,类似于 Flink 中的 SQL 的维表关联能力。通过定义 Join source 的 Connector ,并加载 Source 的配置,从源端根据 Join key 获取数据,将数据进行全量加载到缓存中,并有 LRU 缓存和不缓存等缓存策略。
如果主表数据进行了分片执行,推荐使用 Join key 进行分片,确保主表数据和维表数据落在同一分片中。此外,对于 SQL 引擎的扩展,还需要执行支持 Join 的物理执行计划的解析和运行。
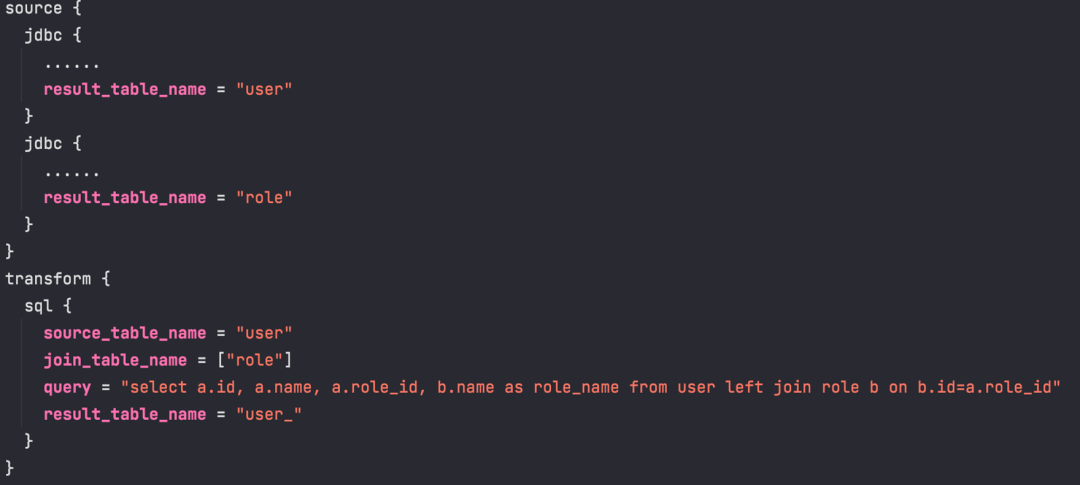
下面是关于join in的配置示例。上面是源表,然后下面会添加一个 join_table_name 的数组,表示维表的数组。以用户表user为例,进行了 left join 角色表 role。join key 是角色表的 id,等于主表的 roleId。
然后返回的是角色表的 name。这样形成了一张宽表,包含了用户的 ID、用户的 name,以及角色的 ID 和角色的 name,然后将数据输出。由于我们规划了 Join 功能的实现,所以不可避免地需要考虑维表更新的情况。
04
CDC-维表更新展规划
在CDC的场景下,维表更新是比较常见的情况。

这里简单规划了一下维表更新的逻辑。假设我们对 user 表和 low 表进行了 Join ,例如有三个字段,这边是一个类目字段。进行 Join 后形成了四个字段,前面三个字段来自 user 表,后面的 low name 来自 low 表。
当对维表进行更新后,历史数据如何处理呢?特别是在CDC场景中,因为新的数据如果我们更新了表,那么关联肯定是关联到新的数据。例如,如果我更新了 ID 等于1的 name,那么会产生一个 CDC 事件,然后通过这个事件,我们批量地进行更新操作。
更新操作是对 role_name 进行批量计算。设计思路是通过 Join key 批量更新目标表中的维表字段。但是这个方案可能有一定的局限性。主要包括以下三点。首先,维表必须支持 CDC 的库,例如 MySQL、Oracle 或者 PG 等。否则无法监听到维表更新的事件。其次,目标表中必须包含join key字段,因为我需要通过目标表的 row_id 进行更新,因为没有主表的 ID 信息,只有维表的 ID 信息,而维表中的 ID 信息对应目标表中的 role_id 字段,所以目标表中必须包含维表的组件或者关键信息。
还有一个条件是,目标表必须支持通过 Join key 进行批量更新或批量查询,而不仅仅是通过组件进行批量更新或批量查询。例如,目标表可以支持关系型数据库,或者是ES,通过其他字段进行查询或更新对应的 Role_name 数据。
以上是我的分享内容,欢迎感兴趣的小伙伴一起来共建 Apache SeaTunnel!
Apache SeaTunnel
精彩推荐
点击阅读原文,点亮Star⭐️!

