




DG offline with error ORA-15130
- SYMPTOMS
下班时间收集邮件收到集群告警,提示一个盘data02offline
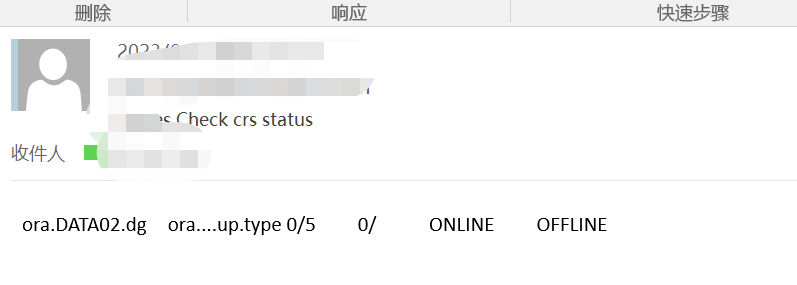
上线检查集群状态发现,整个集群已经crash,两个节点alert log都在报归档错误(data02 为归档盘); OS 中查看磁盘信息的命令会卡死,asm 实例卡死,无法查询
DB alert log
ARCH: Archival stopped, error occurred. Will continue retrying
ORACLE Instance mycim4 - Archival Error
ORA-16038: log 8 sequence# 18498 cannot be archived
ORA-00254: error in archive control string ''
ORA-00312: online log 8 thread 4: '+DATA/mycim/onlinelog/group_8.286.1014478071'
ORA-00312: online log 8 thread 4: '+FRA/mycim/onlinelog/group_8.45441.1014478071'
ORA-15001: diskgroup "DATA02" does not exist or is not mounted
ORA-15001: diskgroup "DATA02" does not exist or is not mounted
Fri Jun 30 18:20:22 2023
ARCH: Archival stopped, error occurred. Will continue retrying
ORACLE Instance mycim4 - Archival Error
ORA-16014: log 8 sequence# 18498 not archived, no available destinations
ORA-00312: online log 8 thread 4: '+DATA/mycim/onlinelog/group_8.286.1014478071'
ORA-00312: online log 8 thread 4: '+FRA/mycim/onlinelog/group_8.45441.1014478071'
ASMlog中有也有大量的ORA报错, data02 dismounted
ASM alert log
ERROR: ORA-15130 in COD recovery for diskgroup 4/0x1159902d (DATA02)
ERROR: ORA-15130 thrown in RBAL for group number 4
Errors in file /oracle/app/oracle/diag/asm/+asm/+ASM4/trace/+ASM4_rbal_167160.trc:
ORA-15130: diskgroup "DATA02" is being dismounted
Fri Jun 30 16:35:21 2023
NOTE: cache dismount of group 4/0x1159902D (DATA02) is waiting for SMON
ERROR: ORA-15130 in COD recovery for diskgroup 4/0x1159902d (DATA02)
ERROR: ORA-15130 thrown in RBAL for group number 4
Errors in file /oracle/app/oracle/diag/asm/+asm/+ASM4/trace/+ASM4_rbal_167160.trc:
ORA-15130: diskgroup "DATA02" is being dismounted
ERROR: ORA-15130 in COD recovery for diskgroup 4/0x1159902d (DATA02)
ERROR: ORA-15130 thrown in RBAL for group number 4
Errors in file /oracle/app/oracle/diag/asm/+asm/+ASM4/trace/+ASM4_rbal_167160.trc:
ORA-15130: diskgroup "DATA02" is being dismounted
Fri Jun 30 16:35:27 2023
Trace file中也有大量报错
2023-06-30 08:00:01.304: [ default]a_init: Unable to get log name. Retval:[-4]
2023-06-30 08:00:01.331: [ GPNP]clsgpnp_dbmsGetItem_profile: [at clsgpnp_dbms.c:313] Result: (0) CLSGPNP_OK. got ASM-Profile.DiscoveryString='/dev/asm*'
ORA-15130: diskgroup "DATA02" is being dismounted
*** 2023-06-30 15:51:04.228
ORA-15130: diskgroup "DATA02" is being dismounted
*** 2023-06-30 15:51:07.230
ORA-15130: diskgroup "DATA02" is being dismounted
*** 2023-06-30 15:51:10.233
ORA-15130: diskgroup "DATA02" is being dismounted
*** 2023-06-30 15:51:13.236
ORA-15130: diskgroup "DATA02" is being dismounted
*** 2023-06-30 15:51:16.239
ORA-15130: diskgroup "DATA02" is being dismounted
+OS log show a series of events related to the qla2xxx driver, which is the driver for QLogic Fibre Channel Host Bus Adapters (HBAs) in Linux.
task lvs was stuck on IO call stack.
Jun 30 15:04:45 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:05:54 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:06:05 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:06:05 csithrac04 kernel: qla2xxx [0000:3b:00.1]-8009:16: DEVICE RESET ISSUED nexus=16:1:9 cmd=ffff88050d0a5280.
Jun 30 15:06:05 csithrac04 kernel: qla2xxx [0000:3b:00.1]-800e:16: DEVICE RESET SUCCEEDED nexus:16:1:9 cmd=ffff88050d0a5280.
Jun 30 15:07:50 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:08:01 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:08:01 csithrac04 kernel: qla2xxx [0000:3b:00.1]-8009:16: DEVICE RESET ISSUED nexus=16:1:9 cmd=ffff88074ea11880.
Jun 30 15:08:01 csithrac04 kernel: qla2xxx [0000:3b:00.1]-800e:16: DEVICE RESET SUCCEEDED nexus:16:1:9 cmd=ffff88074ea11880.
Jun 30 15:28:46 csithrac04 kernel: INFO: task lvs:348528 blocked for more than 120 seconds.
Jun 30 15:28:46 csithrac04 kernel: Tainted: P W -- ------------ 2.6.32-642.el6.x86_64 #1
Jun 30 15:28:46 csithrac04 kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Jun 30 15:28:46 csithrac04 kernel: lvs D 0000000000000010 0 348528 348507 0x00000080
Jun 30 15:28:46 csithrac04 kernel: ffff880385fa7a18 0000000000000086 ffff88086f6c1428 ffff88086bbcf008
Jun 30 15:28:46 csithrac04 kernel: ffff880385fa79c8 ffffffffa037d6c8 0000000000000000 00000000000000d0
Jun 30 15:28:46 csithrac04 kernel: ffff880385fa79d8 ffff8805b97312c0 ffff880844301ad8 ffff880385fa7fd8
Jun 30 15:28:46 csithrac04 kernel: Call Trace:
Jun 30 15:28:46 csithrac04 kernel: [<ffffffffa037d6c8>] ? emcp_native_strategy_request_fn+0x108/0x3d0 [emcp]
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff81547cf3>] io_schedule+0x73/0xc0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811dabdd>] __blockdev_direct_IO_newtrunc+0xb7d/0x1270
Jun 30 15:28:46 csithrac04 kernel: [<ffffffffa037813a>] ? PowerDispatchX+0x29a/0x4d0 [emcp]
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6540>] ? blkdev_get_block+0x0/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811db347>] __blockdev_direct_IO+0x77/0xe0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6540>] ? blkdev_get_block+0x0/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d75c7>] blkdev_direct_IO+0x57/0x60
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6540>] ? blkdev_get_block+0x0/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811304ab>] generic_file_aio_read+0x6bb/0x700
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d8110>] ? blkdev_get+0x10/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d8120>] ? blkdev_open+0x0/0xc0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff81196f67>] ? __dentry_open+0x257/0x380
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6ab1>] blkdev_aio_read+0x51/0x80
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff81199c8a>] do_sync_read+0xfa/0x140
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff810a6ac0>] ? autoremove_wake_function+0x0/0x40
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d68dc>] ? block_ioctl+0x3c/0x40
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811af742>] ? vfs_ioctl+0x22/0xa0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811af8e4>] ? do_vfs_ioctl+0x84/0x580
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8123ac26>] ? security_file_permission+0x16/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8119a585>] vfs_read+0xb5/0x1a0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8119b336>] ? fget_light_pos+0x16/0x50
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8119a8d1>] sys_read+0x51/0xb0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff810ee47e>] ? __audit_syscall_exit+0x25e/0x290
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8100b0d2>] system_call_fastpath+0x16/0x1b
File Name or Source
-------------------------
messages-20230702
Description
--------------
Relevant Information Collection
---------------------------------------
Jun 30 15:04:45 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:05:54 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:06:05 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:06:05 csithrac04 kernel: qla2xxx [0000:3b:00.1]-8009:16: DEVICE RESET ISSUED nexus=16:1:9 cmd=ffff88050d0a5280.
Jun 30 15:06:05 csithrac04 kernel: qla2xxx [0000:3b:00.1]-800e:16: DEVICE RESET SUCCEEDED nexus:16:1:9 cmd=ffff88050d0a5280.
Jun 30 15:07:50 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:08:01 csithrac04 kernel: qla2xxx [0000:3b:00.1]-801c:16: Abort command issued nexus=16:1:9 -- 1 2002.
Jun 30 15:08:01 csithrac04 kernel: qla2xxx [0000:3b:00.1]-8009:16: DEVICE RESET ISSUED nexus=16:1:9 cmd=ffff88074ea11880.
Jun 30 15:08:01 csithrac04 kernel: qla2xxx [0000:3b:00.1]-800e:16: DEVICE RESET SUCCEEDED nexus:16:1:9 cmd=ffff88074ea11880.
Jun 30 15:28:46 csithrac04 kernel: INFO: task lvs:348528 blocked for more than 120 seconds.
Jun 30 15:28:46 csithrac04 kernel: Tainted: P W -- ------------ 2.6.32-642.el6.x86_64 #1
Jun 30 15:28:46 csithrac04 kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Jun 30 15:28:46 csithrac04 kernel: lvs D 0000000000000010 0 348528 348507 0x00000080
Jun 30 15:28:46 csithrac04 kernel: ffff880385fa7a18 0000000000000086 ffff88086f6c1428 ffff88086bbcf008
Jun 30 15:28:46 csithrac04 kernel: ffff880385fa79c8 ffffffffa037d6c8 0000000000000000 00000000000000d0
Jun 30 15:28:46 csithrac04 kernel: ffff880385fa79d8 ffff8805b97312c0 ffff880844301ad8 ffff880385fa7fd8
Jun 30 15:28:46 csithrac04 kernel: Call Trace:
Jun 30 15:28:46 csithrac04 kernel: [<ffffffffa037d6c8>] ? emcp_native_strategy_request_fn+0x108/0x3d0 [emcp]
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff81547cf3>] io_schedule+0x73/0xc0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811dabdd>] __blockdev_direct_IO_newtrunc+0xb7d/0x1270
Jun 30 15:28:46 csithrac04 kernel: [<ffffffffa037813a>] ? PowerDispatchX+0x29a/0x4d0 [emcp]
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6540>] ? blkdev_get_block+0x0/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811db347>] __blockdev_direct_IO+0x77/0xe0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6540>] ? blkdev_get_block+0x0/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d75c7>] blkdev_direct_IO+0x57/0x60
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6540>] ? blkdev_get_block+0x0/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811304ab>] generic_file_aio_read+0x6bb/0x700
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d8110>] ? blkdev_get+0x10/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d8120>] ? blkdev_open+0x0/0xc0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff81196f67>] ? __dentry_open+0x257/0x380
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d6ab1>] blkdev_aio_read+0x51/0x80
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff81199c8a>] do_sync_read+0xfa/0x140
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff810a6ac0>] ? autoremove_wake_function+0x0/0x40
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811d68dc>] ? block_ioctl+0x3c/0x40
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811af742>] ? vfs_ioctl+0x22/0xa0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff811af8e4>] ? do_vfs_ioctl+0x84/0x580
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8123ac26>] ? security_file_permission+0x16/0x20
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8119a585>] vfs_read+0xb5/0x1a0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8119b336>] ? fget_light_pos+0x16/0x50
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8119a8d1>] sys_read+0x51/0xb0
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff810ee47e>] ? __audit_syscall_exit+0x25e/0x290
Jun 30 15:28:46 csithrac04 kernel: [<ffffffff8100b0d2>] system_call_fastpath+0x16/0x1b
2.CAUSE
从数据库端和OS端的log看均是指向data02共享磁盘的问题,查看存储,但是在存储端看不到任何报错;后来给DELL开了case也没有查到问题。
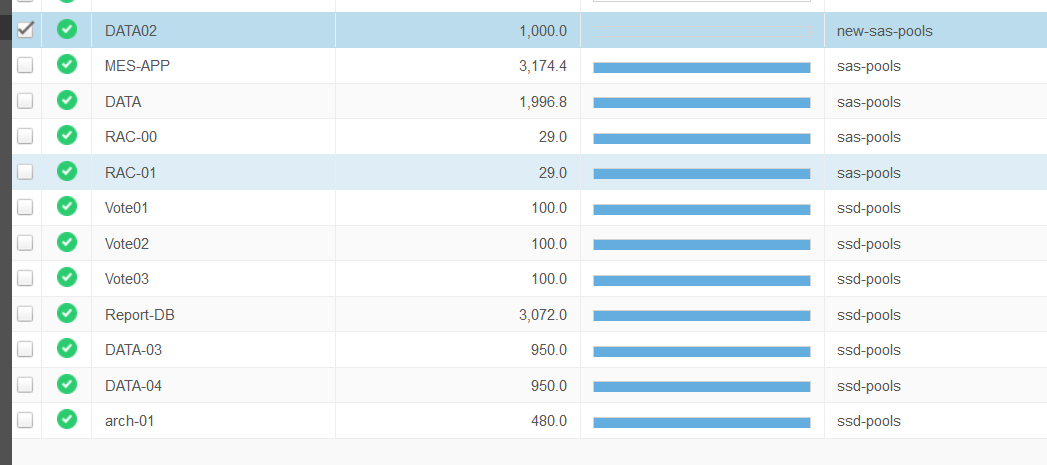
尝试重启其中一个节点来修复IO 问题,结果关机后无法启动
系统报错
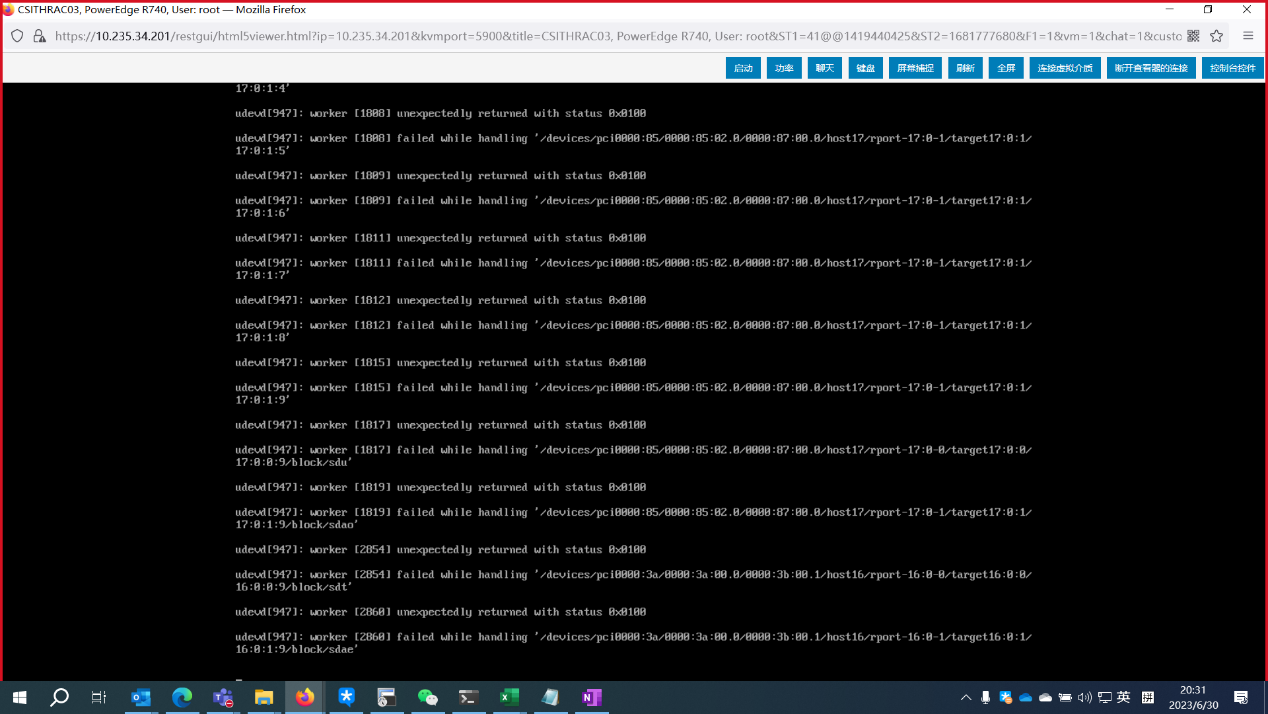
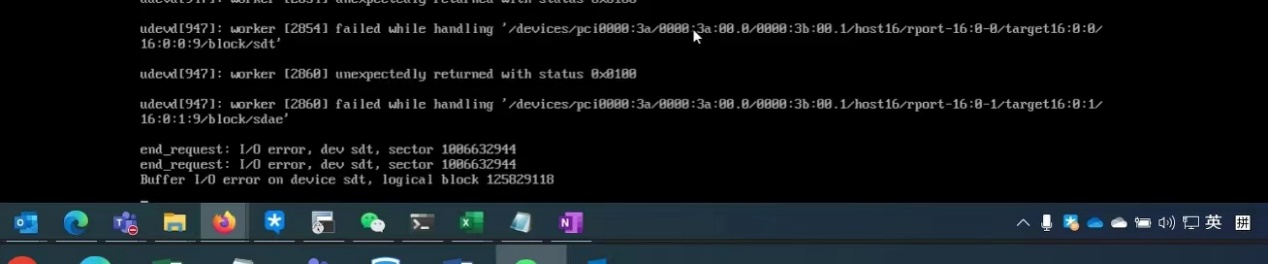
尝试udev中拿掉故障的盘,udev reload时也报错
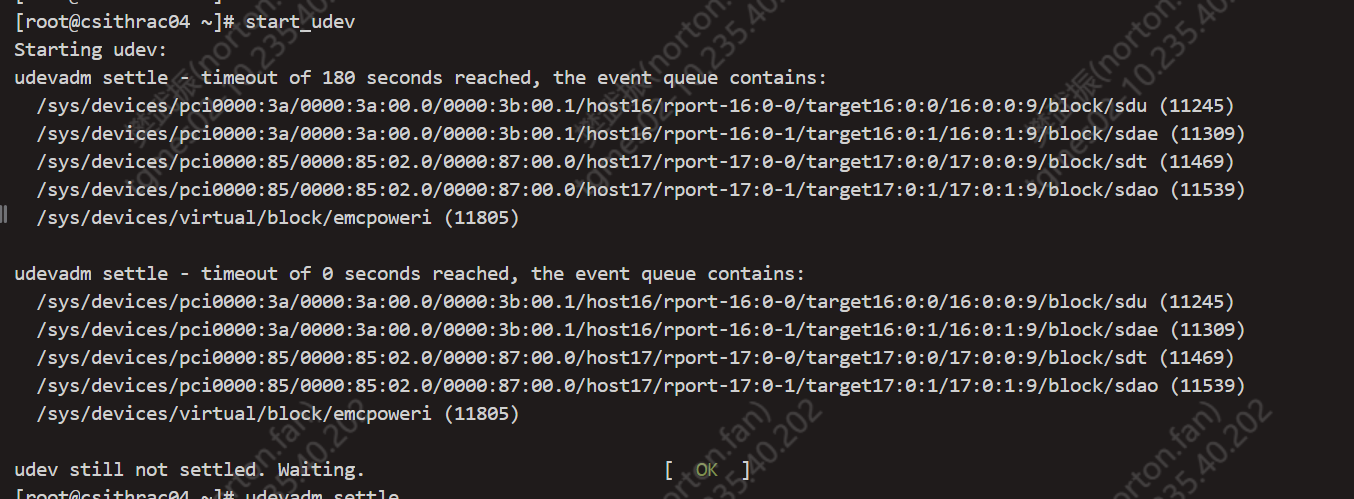
以上的报错均指向如下两个udev相关的bug
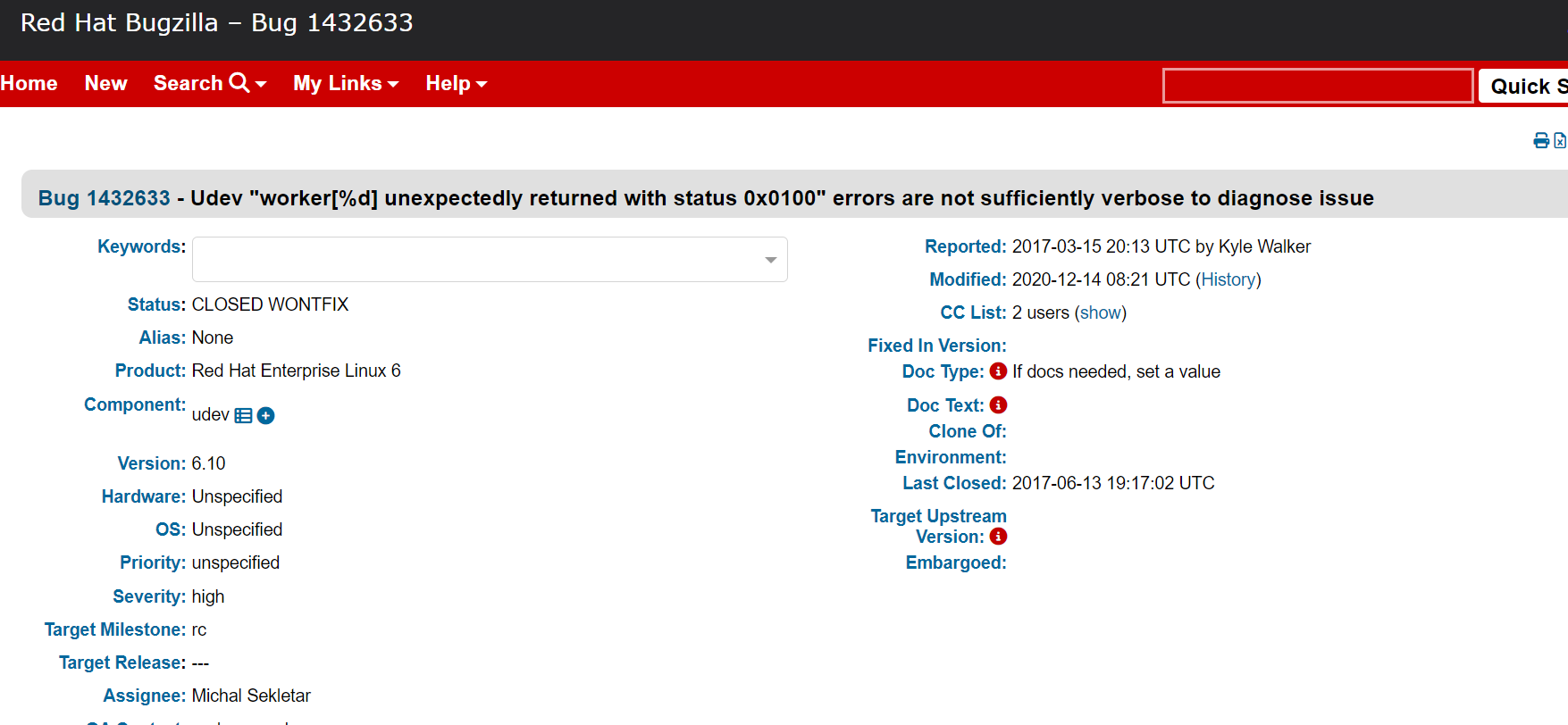

结合以上信息基本可以判定是因为某些原因触发了udev的bug 导致共享磁盘data02
不可用,从而导致数据库集群crash
3.SOLUTION
3.1 出现集群崩溃,并判定为磁盘故障时,尝试重启节点1来修复磁盘故障
结果重启后节点1无法启动;后续尝试很多办法 均无法启动!
3.2 节点1down后,尝试修复节点二,幸运的是data02盘是归档盘,不实际保存数据,
尝试修改归档存放路径;
ALTER SYSTEM SET log_archive_dest_1='location=+data' SCOPE=BOTH;
但是一直无法成功,重启后归档还是在data02,怀疑后crs盘出现问题,导致无法修改
利用 spfile创建pfile
Create pfile=’/tmp/xxpfile.ora’ from spfile;
修改pfile文件中的log_archive_dest_1
log_archive_dest_1 = "location=+DATA02" 原来
修改为
log_archive_dest_1 = "location=+DATA"
利用pfile 启动
Startup mount pfile=’/tmp/xxpfile.ora’
检查规定路径是否修改成功
Show parameter log_archive_dest_1
然后将数据库打开
Alter database open;
3.3 后续操作
后面尝试过很多方法均无法启动OS,包括拿掉存储路径,修改udev都不能启动;
为了解决这个风险,新建一台主机配置好数据库,利用DSG做同步,将全量数据库同步后开启实时同步,后面有找个30分的停机窗口做了主备切割!
这个集群最后被干掉重新安装,搜索过网上的类似案例也基本都是要重建DG或者集群才能解决;
后记
此次事故有两点侥幸
- 出问题的磁盘是arch盘,如果是data盘或者crs盘,那么短时间内肯定无法修复,而且一定会有数据丢失
- 出问题的时间为月底工厂停产期间,没有对生产造成影响。
如果不是以上两点 那么一定会造成业务停顿或数据丢失,所以如有DSG实时同步的备机,或者ADG那么就不会有这种担心!standby真的非常重要,仅仅有备份是不够的。
