




最近,我前后给同一个客户分析了两条存在性能问题的sql语句,昨天无意间看了眼两次的分析报告,发现这两条sql的联系还不小,其中还涉及到很多以前不知道的知识点,于是总结了一下记录下来。
5月7日客户给我发来一条sql语句(sql1),说是每天凌晨都会跑但执行时间一直都在1小时以上,偶尔还会报ora-01555的错误,看能否优化下,sql文本如下:
SELECT 'NOCAR' AS PLATFORMTYPE, 'CLAIM' AS SUBPLATFORMTYPE, CLAIMNO, A.CASENUM AS CASENO, A.RISKCODE, A.CLASSCODE, A.REGISTNO, A.POLICYNO, A.INSUREDCODE, A.INSUREDNAME, A.STARTDATE, A.ENDDATE, A.CURRENCY, A.SUMAMOUNT, A.SUMPREMIUM, A.SUMQUANTITY, TRUNC(B.DAMAGETIME) AS DAMAGESTARTDATE, TO_CHAR(B.DAMAGETIME, 'HH24:MI:SS') AS DAMAGESTARTHOUR, TRUNC(B.DAMAGETIME) AS DAMAGEENDDATE, TO_CHAR(B.DAMAGETIME, 'HH24:MI:SS') AS DAMAGEENDHOUR, A.DAMAGECODE, A.CANCELTIME AS CANCELDATE, A.DAMAGENAME, A.DAMAGETYPECODE, A.DAMAGEAREACODE, A.DAMAGEAREA AS DAMAGEAREANAME, A.DAMAGEADDRESS, A.LOSSNAME, A.CLAIMTIME AS CLAIMDATE, A.SUMCLAIM, A.SUMDEFLOSS, A.SUMPAID, A.SUMREPLEVY, A.REMARK, A.CASETYPE, A.MAKECOM, A.COMCODE, A.HANDLERCODE, A.CREATEUSER AS HANDLER1CODE, A.OPERATORCODE, A.CREATETIME AS INPUTTIME, A.ENDCASEDATE AS ENDCASEDATE, A.ENDCASERCODE, A.CANCELREASON, A.DEALERCODE, A.FLAG, ENDCASEFLAG, CANCELCODE AS CANCELFLAG, DOCCOLLENDTIME AS AFFIXGETDATE, A.LINKRISKCODE, A.REPORTTIME, A.ISSUBROGATION, A.MERCYFLAG, A.SUMESTIPAID, A.SUMESTIFEE, A.SUMCHARGEFEE, A.VALIDFLAG, A.CREATEUSER, A.CREATETIME, A.UPDATEUSER, A.CLAIMFLAG, A.COMPENSATESTATUS, A.ESTITIMES, A.DOCCOLLFLAG, A.DAMAGEDETAIL, A.OPINIONTYPE, A.RELATERESPONSIBLEPARTY, A.RELATERECOVERY, A.RELATECHECK, A.UNDWRTREJECTFLAG, A.ZEROREASONCODE, A.ZEROREMARK, A.ZEROCLAIMFLAG, A.SUMPREPAID, A.SUMOUTSTANDING, A.ESTIDATE, A.ORICURRENCY, A.ORISUMESTIPAID, A.ORISUMCLAIM, A.ORISUMCHARGE, A.CASEDESCRIPTION, A.CLAIMAMOUNT, A.CLAIMAPPLYDATE, A.CLAIMEVALUATION, A.DAMAGETIME, A.LTEXT, A.OPERATORNAME, A.SUMLOSS, A.LOSSCURRENCY, A.DLOSSPERSSUMLOSS, A.DLOSSPERSLOSSCURRENCY, A.NATIONFLAG, A.BUSINESSPLATE, A.AMLFLAG, A.SERIALNO, A.INSERTTIMEFORHIS, A.OPERATETIMEFORHIS, A.GMT_MODIFIED, A.UPDATETIME, SYSDATE LOADTIME FROM PRPLXXXX A LEFT JOIN PRPLREXXXX B ON A.REGISTNO = B.REGISTNO WHERE SUBSTR(A.RISKCODE, 1, 2) NOT IN ('05', '31', '32', '25', '40'); |
sql很长,但逻辑很简单就是A表left join B表,执行计划如下:
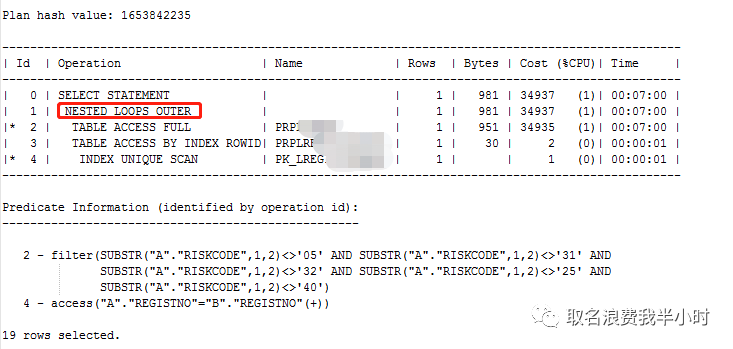

可以看到执行计划走的是nested loops,并且A B两张表的数据量差不多都是97万多。当时看到这个执行计划的时候,我想的是,两张表都不算大,就算都是全表扫描然后走hash join,时间也不至于要1个多小时这么长啊,也就近似是对两张表全表扫描的时间之和。由于当时客户时间比较急,我就匆匆给这条sql加了一个hint(/*+ use_hash(A,B) */),让A B两表强制走hash join,测试了一下,4分多钟就执行完成了。由于效果还不错,客户也比较满意,这个事当时就这样了,也没太细想为什么oracle自己没有选择hash join的执行计划,只是大概查了下,因为A表有过滤条件,那是不是过滤之后返回的结果集很少很少呢?为此我特意查了下A表riskcode列的分布情况如下:

发现riskcode=0915的有94万,基本上占了整张表数据量的的90%以上,但过滤条件中并没有将0915过滤掉,所以过滤之后的结果集至少大于94万,所以B表被重复扫描94万次以上,效率低下。
不过现在回过头来看应该是统计信息的问题,A表最后一次收集统计信息的时间是2021年1月23日,这都几个月过去了,至于oracle为什么没有收统计信息,这里现在就无法查了,并且执行计划中对A表全表扫描,评估的结果是1行,所以oracle错误的认为A表做驱动表走nested loops效率会更高。
5月20日这个客户又给我发来一条sql语句(sql2),是另外一个生产库的,情况和上次差不多,执行时间1小时以上,并且是越来越慢,有时候还会报ora-01555的错误,sql文本如下:
SELECT 'NOCAR' AS platformtype , 'CLAIM' AS subplatformtype , CLAIMNO , '' AS LFLAG , a.CASENUM as CASENO , NVL(c.CLASSCODE_NEW,A.CLASSCODE) AS CLASSCODE , NVL(c.RISKCODE_NEW,A.RISKCODE) AS RISKCODE , a.REGISTNO , a.POLICYNO , '' AS BUSINESSNATURE , '' as LANGUAGE , '' as POLICYTYPE , a.INSUREDCODE , a.INSUREDNAME , a.STARTDATE , '' AS STARTHOUR , a.ENDDATE , '' AS ENDHOUR , a.CURRENCY , a.SUMAMOUNT , a.SUMPREMIUM , a.SUMQUANTITY , trunc(b.DAMAGETIME) AS DAMAGESTARTDATE , to_char(b.damagetime,'hh24:mi:ss') AS DAMAGESTARTHOUR , trunc(b.DAMAGETIME) AS DAMAGEENDDATE , to_char(b.damagetime,'hh24:mi:ss') AS DAMAGEENDHOUR , a.DAMAGECODE , a.canceltime AS CANCELDATE , a.DAMAGENAME , a.DAMAGETYPECODE , '' AS DAMAGETYPENAME , a.DAMAGEAREACODE , a.damagearea AS DAMAGEAREANAME , '' AS DAMAGEADDRESSTYPE , '' AS ADDRESSCODE , a.DAMAGEADDRESS , a.LOSSNAME , ''LOSSQUANTITY , '' AS DAMAGEKIND , a.claimtime AS CLAIMDATE , '' AS INDEMNITYDUTY , '' AS INDEMNITYDUTYRATE , '' AS DEDUCTIBLERATE , a.SUMCLAIM , a.SUMDEFLOSS , a.SUMPAID , a.SUMREPLEVY , a.REMARK , a.CASETYPE , a.MAKECOM , a.COMCODE , '' AS AGENTCODE , a.HANDLERCODE , a.createuser AS HANDLER1CODE , '' AS STATISTICSYM , a.OPERATORCODE , a.createtime AS INPUTTIME , a.endcasedate AS ENDCASEDATE , a.ENDCASERCODE , a.CANCELREASON , a.DEALERCODE , '' AS ESCAPEFLAG , a.FLAG , '' AS THIRDCOMFLAG , '' AS REPLEVYFLAG , '' AS CINDEMNITYDUTYRATE , ENDCASEFLAG , '' AS CATASTROPHECODE1 , '' AS CATASTROPHENAME1 , '' AS CATASTROPHECODE2 , '' AS CATASTROPHENAME2 , '' AS DAMAGEAREAPOSTCODE , '' AS CLAIMTYPE , '' AS LOSSESUNITCODE , '' AS DEATHQUANTITY , '' AS DEATHUNIT , '' AS KILLQUANTITY , '' AS KILLUNIT , '' AS DAMAGEINSURED , '' AS DISASTERAREA , '' AS DISASTERUNIT , '' AS AFFECTEDAREA , '' AS AFFECTEDUNIT , '' AS NOPRODUCTIONAREA , '' AS NOPRODUCTIONUNIT , '' AS CHECKERCODE , '' AS CHECKDATE , '' AS PRPLCOMPENSATEALLLOSS , '' AS SUBROGATETYPE , '' AS EXCESSTYPE , '' AS ACCIDENTTYPE , '' AS RECASENO , '' AS DETAILDAMAGECODE , '' AS SUMEXPAMOUNT , '' AS SUMKINDEXPAMOUNT , '' AS LAWSUITFLAG , '' AS AREAPROVINCE , '' AS AREAPROVINCENAME , '' AS AREACITY , '' AS AREACITYNAME , '' AS AREATOWN , '' AS AREATOWNNAME , '' AS CLAIMHANDLETYPE , cancelcode AS CANCELFLAG , doccollendtime AS AFFIXGETDATE , '' AS POSITIVEFLAG , '' AS REMOTECLAIMFLAG , '' AS COORDINATEFLAG , '' AS SURVEYFLAG , '' AS SURVEYSTARTDATE , '' AS SURVEYENDDATE , '' AS SURVEYCONCLUSION , '' AS MICROCLMFLAG , '' AS CERTIDATE , '' AS CERTIHOUR , '' AS ISHOSPITALFLAG , '' AS AREAVILLAGE , a.Linkriskcode , a.reporttime , a.issubrogation , a.mercyflag , a.sumestipaid , a.sumestifee , a.sumchargefee , a.validflag , a.createuser , a.createtime , a.updateuser , a.claimflag , a.compensatestatus , a.estitimes , a.doccollflag , a.damagedetail , a.opiniontype , a.relateresponsibleparty , a.relaterecovery , a.relatecheck , a.undwrtrejectflag , a.zeroreasoncode , a.zeroremark , a.zeroclaimflag , a.sumprepaid , a.sumoutstanding , a.estidate , a.oricurrency , a.orisumestipaid , a.orisumclaim , a.orisumcharge , a.casedescription , a.claimamount , a.claimapplydate , a.claimevaluation , a.damagetime , a.ltext , a.operatorname , --injurydecimal , -- diedecimal , a.sumloss , a.losscurrency , a.dlossperssumloss , a.dlossperslosscurrency , a.nationflag , a.businessplate , a.amlflag , a.serialno , a.inserttimeforhis , a.operatetimeforhis , a.gmt_modified , a.UPDATETIME , SYSDATE LOADTIME FROM PRPLXXXX A left join prplregiXXXX B on a.registno = b.registno LEFT JOIN STAT.DIM_RISK_XXXX@DGTOBI c ON A.RISKCODE = c.RISKCODE_OLD WHERE SUBSTR(A.RISKCODE,1,2) not in('05','31','32','25','40') ; |
可以看到和第一次的sql比较类似,只不过这里多了一个C表,并且C是通过dblink连接到另一个库的表,执行计划如下:
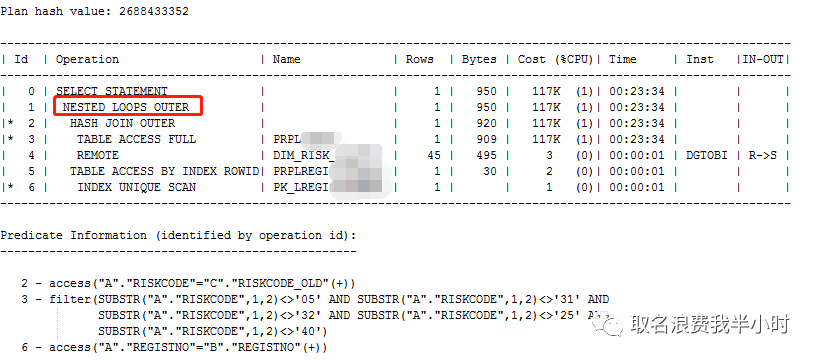


从执行计划中可以看出,先是A表和C表走hash join outer,结果集再和B表走nested loops outer,A B表的数据量差不多都是330多万,C表只有45条记录,那么为什么A C关联时,走hash join问题倒不大,但为什么oracle将一个大表作为驱动表呢?这里其实就需要弄明白left join的原理了,我们后面再说。再看执行计划第一步是nested loops outer,第二步返回的结果集上面已经查出来了是336万,那为什么这个结果集和B表关联时,oracle还选择走nested loops呢?这不就意味着B表要被重复扫描330多万次吗,效率肯定不会高。
到这里的时候,我当时就在想就算全部都是全表扫描,如果都走hash join,执行时间也顶多就是对A B C这三张表进行全表扫描的时间之和,估计10分钟内完成问题不大,但为什么执行了1个多小时呢?于是我给这条sql也加了一个hint(/*+ use_hash(A,B) */),执行计划如下:
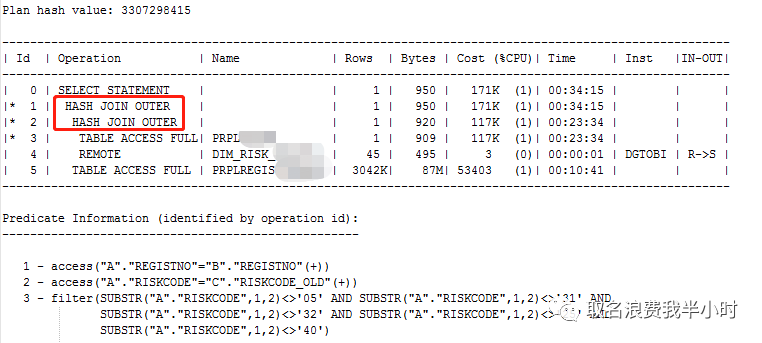
hint确实生效了,我心想着和上次差不多,就算表的数据量从90多万增加到330多万,执行时间估计也不会差太多,可是加了hint,实际执行的时候却用了51分钟,这不科学啊!!!
于是我又仔细的结合sql文本和执行计划排查了一遍,发现A表和C表关联的的时候,关联条件为riskcode,这时候细心的小伙伴估计已经知道问题的所在了。好,不卖关子我们继续,你应该还记得5月7日的时候,我当时查过一次A表riskcode列的分布情况,当时A表97万条记录,但riskcode=0915的值就有94万,并且riskcode等于其他值的少则几个,多的也就几千。紧接着我再次查了一下:
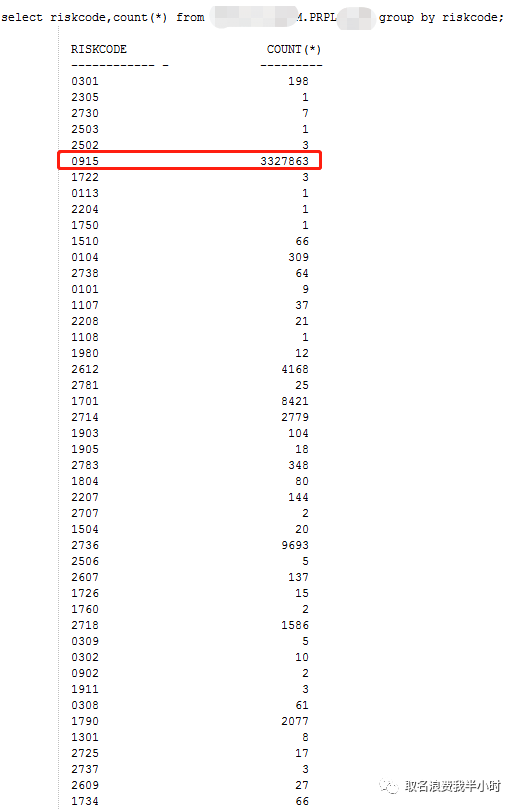
可以看到,5月7日的时候,A表riskcode=0915的值有94万,5月20日A表riskcode=0915的值涨到了332万多,同样riskcode等于其他值的,少则几个,多的也就才几千。这里可以预想到随着业务的增长,A表的数据不断增多,但是进来的数据基本都是riskcode=0915,一般保险公司的表中riskcode的含义就是产品编码,也就是不同的保险种类,那就有可能编号为0915的这个产品卖得最火,或者优惠力度最大,或者最近在做促销等,都会导致这种情况。
分析到这里,接下来不得不再次来回顾一下hash join的原理了,对于下面这条sql在oracle内部的执行过程是怎样的呢?
| select *+ use_hash(A C)*/* from A C where A.riskcode = C.diskcode; |
scan A(扫描A表)
hash(A.riskcode),打散到各个桶中(bucket),待在桶中等别人比对
scan C(扫描C表)
hash(C.riskcode)
到相应的bucket中比较关联字段的值,相同则返回,不同则丢弃
hash的目的是为了打散数据到各个桶中,但是如果数据都集中在一个桶中,那就违背了hash的设计初衷。带来的结果就是riskcode=0915的数据全都进入一个桶中,也就是这个桶中有330多万数据(一般认为每个桶中10条以内的记录会比较好),那么也就意味着C表的数据到这个桶中比对的时候要比对330多万次,这个过程主要是消耗cpu的,并且很耗时。那么我们这条sql耗时长的原因是不是就是这个呢?我们需要进一步验证:
我们首先在窗口1执行这条sql,窗口1的sid为2745,我们再打开一个窗口2,执行如下sql:
| select SOFAR,TOTALWORK from v$session_longops where SOFAR !=TOTALWORK and sid=2754; |
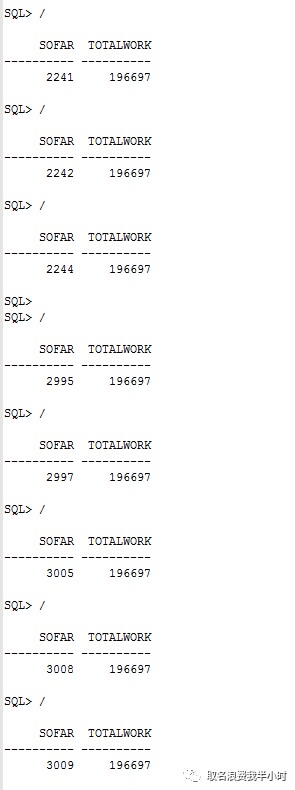
以上的截图我是每隔三秒左右执行一次的,可以看到,sofar基本上两三秒才涨1。
前面我们知道了riskcode=0915的值有330多万,那如果我们将riskcode=0915的数据过滤掉,再来执行这条sql,虽然过滤后的数据量会大量减少,但是观察sofar的增长率还是有意义的,将sql修改如下,再次执行:
................................. a.gmt_modified , a.UPDATETIME , SYSDATE LOADTIME FROM PRPLXXXX A left join prplregistXXXX b on a.registno = b.registno LEFT JOIN STAT.DIM_RISK_XXXX@DGTOBI c ON A.RISKCODE = c.RISKCODE_OLD WHERE SUBSTR(A.RISKCODE,1,2) not in('05','31','32','25','40','09') ; |
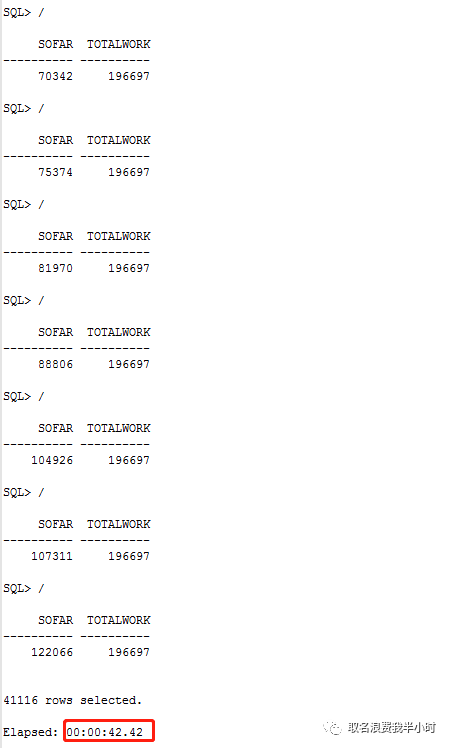
只需42秒就执行完成了,至此基本可以断定这条sql效率低下的原因在于A表riskcode列的数据分布极度不均衡造成的。
总结一下,客户反馈sql1执行时间长是因为统计信息陈旧,oracle错误的选择了大结果集做驱动表,从而导致性能低下,在增加use_hash的hint之后,执行时间由1个多小时降到了4分钟,效率明显提升,但为什么5月7日时A表的riskcode列的分布就已经很不均了,走hash join却没有受到影响呢?那是因为A B表的关联条件不是riskcode。
sql2执行超过1小时,并且执行时间越来越长,是因为随着业务的增长,riskcode=0915的值越来越多,造成riskcode列的分布不均的问题越来越严重,如果不调整这一点,可以预想到未来这条sql的执行时间还会更慢,前面也提到riskcode的含义为产品编码,对于保险公司来说就是不同的保险种类,可能大家都喜欢买0915这款保险产品,从而造成这种情况,至于优化建议你总不能让大家别买0915这款产品而去买别的产品吧 ,或者你总不能建议将0915这款产品涨价吧,所以首要的还是需要开发人员介入,看如何避免riskcode列分布极度不均衡的问题。另外哈,如果这里加强制nested loop的hint,可能这条sql在未来短时期内还能跑一跑,但不是长久之计,因为A C的连接方式为left join,并且where后面有A表的过滤条件,所以驱动表只能是A这张大表(左表)。
,或者你总不能建议将0915这款产品涨价吧,所以首要的还是需要开发人员介入,看如何避免riskcode列分布极度不均衡的问题。另外哈,如果这里加强制nested loop的hint,可能这条sql在未来短时期内还能跑一跑,但不是长久之计,因为A C的连接方式为left join,并且where后面有A表的过滤条件,所以驱动表只能是A这张大表(左表)。
最后对于这两条sql,基本都是left join ,本来还想着继续分析测试一下left join这种连接方式的(有大坑),篇幅问题(主要是懒),下次吧。
