




清晰的数据结构每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。 将复杂的问题简单化将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的问题,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的地方开始修复。 减少重复开发规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。 屏蔽原始数据的异常屏蔽业务的影响,不必改一次业务就需要重新接入数据。 数据血缘的追踪最终给业务呈现的是一个能直接使用业务表,但是它的来源很多,如果有一张来源表出问题了,借助血缘最终能够快速准确地定位到问题,并清楚它的危害范围。
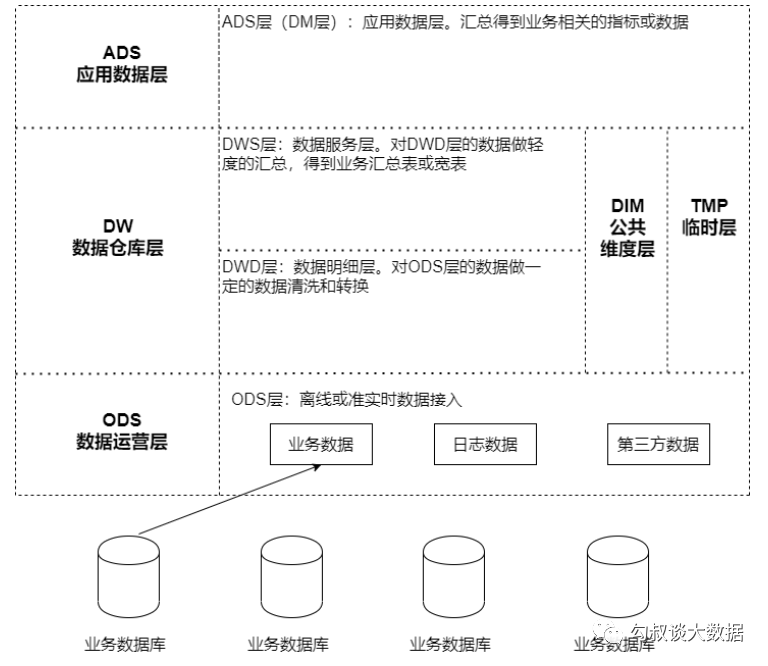
ODS(Operation Data Store 数据准备区)
业务数据库:可使用DataX、Sqoop等工具来抽取,每天定时抽取一次;在实时应用中,可用Canal监听MySQL的 Binlog,实时接入变更的数据。 埋点日志:线上系统会打入各种日志,这些日志一般以文件的形式保存,可以用 Flume 定时抽取。 其他数据源:从第三方购买的数据、或是网络爬虫抓取的数据。
DW(Data Warehouse 数据仓库层)
DWD(Data Warehouse Detail 细节数据层),是业务层与数据仓库的隔离层。以业务过程作为建模驱动,基于每个具体的业务过程特点,构建细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,也即宽表化处理。 DWS(Data Warehouse Service 服务数据层),基于DWD的基础数据,整合汇总成分析某一个主题域的服务数据。以分析的主题为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表。 DIM(公共维度层 ),基于维度建模理念思想,建立一致性维度。 TMP层 :临时层,存放计算过程中临时产生的数据。
ADS(Application Data Store 应用数据层)


文章转载自勾叔谈大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
