




工作中,Redis通常会被用作缓存,并不会被用作持久化存储,这样当Redis一旦宕机,那么缓存就全量丢失,需要重新读数据库放入缓存,如果缓存数据比较大,这个成本也是相当大的,好在Redis提供了持久化机制,这样Redis宕机之后,可以通过RDB文件和AOF日志回复数据。
AOF
Redis每次执行命令之后,都会记录一条AOF日志,和MySQL的Redo Log类似,不同的是MySQL的Redo Log是在数据写入之前的日志,而Redis的AOF是在数据写入之后的日志。AOF日志写入操作是在主线程,而磁盘写入又是一个io操作,因此很容易造成Redis阻塞,这对追求性能的Redis来说是不能接受的,幸运的是,Redis提供了不同的写回策略,便于我们 根据不同的场景采取不同的写回策略
1.Always 写命令执行完,立马同步地将日志写回磁盘。
2.Everysec,每秒写回,每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘。
3.No,操作系统控制的写回,每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
不同的策略对应不同的优缺点,同步写会基本不丢数据,但是性能较低,每秒写回最多丢失一秒的数据,但是性能有所提升,No性能最高,但是丢数据最多。
AOF重写
AOF文件会随着日志越来越多导致文件越来越大,在数据恢复的时候日志文件就会过大,举个例子,假如一台Redis运行一个月时间,一直在执行set name joy命令,那么这个AOF将会很大,并且都是同样的命令,而我们的Redis实际上只有一个key,AOF重写机制就是为了避免文件过大。简单来说,AOF 重写机制就是在重写时,Redis 根据数据库创建一个新的 AOF 文件,读取数据库中的所有键值对,然后对每一个键值对用一条命令记录它的写入。AOF重写是由后台子进程 bgrewriteaof子进程完成,因此不会阻塞主进程。这个过程具体一点就是,当开始AOF重写时,主线程fork出一个子进程,子进程拷贝一份数据的引用,当有数据读写时,除了在AOF日志缓存区记录日志之外,还需要在AOF重写缓冲区记录一份日志,这样完成之后,新的AOF就可以取代旧的AOF文件。
RDB
RDB 是 Redis DataBase 的缩写。和 AOF 相比,RDB 记录的是某一时刻的数据,并不是操作,它执行的是全量快照,因此,在做数据恢复时,我们可以直接把 RDB 文件读入内存,很快地完成恢复。生成RDB这个操作,Redis提供了两个命令,save和bgsave,前者会阻塞主线程,很明显是不能接受的,bgsave的过程是,主进程fork出一个子进程,子进程拷贝一份内存的全量引用,当Redis处理写请求时,Linux使用的是Linux的写时复制技术,即当主线程需要写数据时,内核将要写的数据页做一份拷贝,然后主线程的读写都在新的内存地址,而不会影响子进程的快照生成。虽然生成RDB不会阻塞主进程,但是fork一个子进程,和全量引用拷贝是在主进程完成的,因此数据越大也会越耗时。由于这个机制,如果RDB文件是八点整开始生成,那么假如八点半完成后,这个快照就是八点这个时点的数据。频繁的生成RDB势必会占用磁盘带宽,造成io竞争,因此生成频率需要根据对丢数据的容忍性做一个决策。同时,恢复数据有几种方法
1.依靠全量的AOF日志
2.依靠某一时点的RDB,和该时点之后的增量AOF
3.某一时点的RDB(丢部分数据)
主从架构下的数据同步
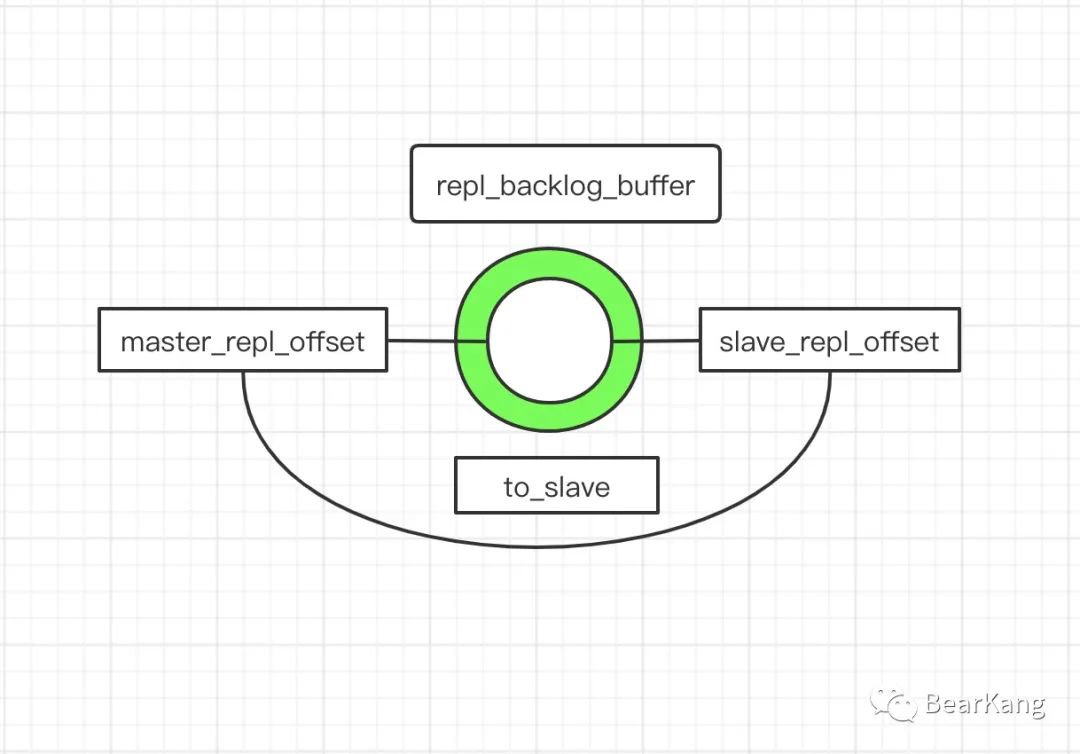
主从模式下,从库只会接受读命令,所有的写命令都是在主库上发生的,而从库想要保持数据一致,需要不断从主库同步最新的日志。具体来说,就是从库启动时,需要指定主库,这样主库根据当前数据生成RDB文件并发送给从库,从库加载RDB文件将数据加载到内存,然后主从库之间维持长连接,不断接受最新的写入命令。这是正常的情况,如果出现异常,比如网络断连之后又重新恢复,从库需要给主库发送同步命令psync命令,将 slave_repl_offset告诉主库,主库根据自己的master_repl_offset和从库的slave_repl_offset比较,只需要将slave_repl_offset到master_repl_offset之间的数据增量同步给从库即可,但是需要注意的是repl_backlog_buffer是一个环形缓冲区,类似MySQL的redo log,因此如果从库断开时间较长,主库可能已经覆盖掉slave_repl_offset,这时候从库就不能不重新进行一次全量复制,为了避免全量复制,可以适当增大repl_backlog_buffer的值。
