




Redis主从集群如何保证高可用?如果从库宕机,那么Redis主库可以继续提供写服务,其它从库提供读服务,但是如果主库宕机,那么就会影响业务的写入和从库的同步,集群将处于只可读不可写的状态,并且读的数据无法保证及时性和有效性。因此,主库宕机之后,必须要选择一个新的主库,进行主从切换。这时候就需要用到哨兵。
哨兵是一种特殊的Redis进程,哨兵的主要职责有三个:
1 监控,监控就是不停的ping主库,用心跳机制检测主库是否存活
2 选主,主库宕机之后,选择一个从库作为主库
3 通知,将新主库的信息通知其它从库,让他们执行replicaof命令,同时也要通知给客户端让他们请求新的主库
监控
监控过程就是哨兵判断主库是否下线的过程。下线分为主观下线和客观下线。主观下线,就是哨兵认为主库下线,如果主库对哨兵的ping命令总是超时,那么哨兵就会认为主库主观下线。但是主库有可能是瞬时压力过大或者网络抖动导致没有及时响应哨兵,这时候就会被哨兵误认为下线,如果草率的认为主库下线,开启接下来的选主和通知,就会造成资源浪费,如果频繁误判而频繁进行主从切换,那显然是灾难性的,因此为了减少误判概率,下线不能由一个哨兵做决定,因此就引入了哨兵集群。这时候就可以根据投票结果决定主库是否客观下线。客观下线的标准就是N 2 + 1(可以设置)个实例判断主库为主观下线。
选主
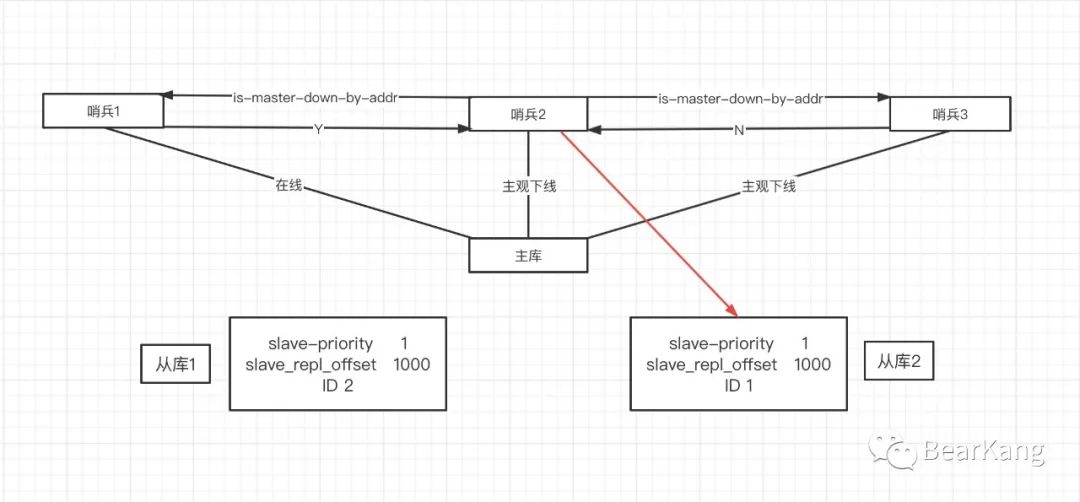
主库的选择需要按照一定的筛选规则。从库必须当前是在线且最近网络状态良好。网络状态可以根据是否经常和主库断连判断,防止某台机器刚选上主库就宕机,导致又需要重新切换主库。可以根据down-after-milliseconds * N,表示down-after-milliseconds是认定主从断连的时间,N是断连次数阈值,如果超过阈值,则认为该从库经常断连,不适合做主库。在符合条件的从库中,按照从库优先级,优先级最高的优先作为主库,如果优先级有并列最高的情况下,那么比较从路同步进度(上一篇中的从库复制偏移量),即数据最全的优先作为主库,如果复制进度仍然还有并列的,那么就是id最小的从库成为主库,id是唯一的,不会有并列的情况。
通知
通知过程哨兵仅仅需要把新的主库信息发送给从库和客户端,通知它们和新主库建立连接就可以了。
完成上述流程,主从切换就完成了。但是在完成上述流程的过程中,还有一个问题,就是为了减少误判以及哨兵的单点故障问题,引入了哨兵集群,那么究竟有哪一个哨兵来执行上述流程呢?哨兵集群挑选哨兵执行主从切换流程的过程,又是一个投票过程。一个实例如果判断主库主观下线后,就会给其他实例发送 is-master-down-by-addr 命令。其他实例会根据自己和主库的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票。一个哨兵获得了足够的赞成票数后,就标记主库为客观下线。这个足够的赞成票数是通过哨兵配置文件中的 quorum 配置项设定的。例如,现在有 5 个哨兵,quorum 配置的是 2,那么,一个哨兵需要2张赞成票,这2张赞成票包括哨兵自己的一张赞成票。将主库标记为为客观下线后,该哨兵就可以给其它哨兵发送命令,自己进行主从切换流程,这时候需要又一轮投票,这个投票过程称为Leader 选举。任何一个哨兵想成为 Leader,要满足两个条件:第一,拿到半数以上的赞成票;第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。以 3 个哨兵为例,假设此时的 quorum 设置为 2,那么,任何一个想成为 Leader 的哨兵至少要拿到 2 张赞成票。一种巧合的情况,假设三个哨兵同时发现主库主观下线,将票投给自己,并希望其它哨兵投票给自己,这时候就会出现票数都是1,导致无法选举出Leader,发生这种情况的概率其实很小,因为不同机器的网络状况等是完全一样,并且哨兵对主从库进行的在线状态检查等操作,是用一个定时器来完成,一般来说每100ms执行一次这些事件。每个哨兵的定时器执行周期都会加上一个小小的随机时间偏移,目的就是让每个哨兵执行上述操作的时间能不相同,也是为了避免它们都同时判定主库下线,同时选举Leader。如果真的巧合出现了都投给自己一票的情况,导致无法选出Leader,哨兵会停一段时间(故障转移超时时间failover_timeout的2倍),然后再可以进行下一轮投票,直到选出Leader。

