







论文地址:
https://dl.acm.org/doi/abs/10.14778/3342263.3342642
(或点击文末“阅读原文”跳转)
问题定义
在过去几年中,大规模知识图谱越来越多,但知识图谱的构造过程还远不够完美,如知识图谱中可能存在着许多不正确的实例。这个问题虽然重要,但现在却鲜有研究。
知识图谱的正确率是指知识图谱中正确的三元组所占的比例,所谓正确是指三元组表示的关系与真实世界相符。通常,我们只能依靠人工来判断一个三元组是否正确,但这在大规模的知识图谱上的成本代价是极其昂贵的,因此,现在的评估方式往往先对知识图谱进行抽样,然后对抽样样本进行评估,以此近似替代知识图谱的准确率。最简单的抽样方式即简单随机抽样,但以此种方式抽取的样本数量较少,就会导致整体的准确率评估出现较大的偏差,反之,则会带来昂贵的评估成本。
另一方面,现代知识图谱的实时更新性,导致其准确率也在变化,因此如何对知识图谱进行增量评估也是一个较为重要的问题。
问题定义
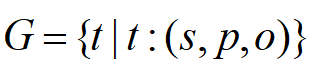 ,其中,(s, p,o)分别代表了三元组中的(主语,谓词,宾语)。
,其中,(s, p,o)分别代表了三元组中的(主语,谓词,宾语)。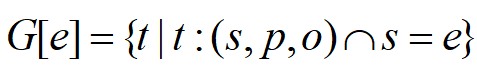 。
。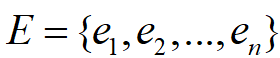 。
。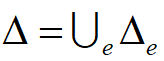 ,其中
,其中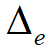 为
为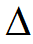 中实体e对应的实体簇:
中实体e对应的实体簇:
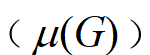 定义为知识图谱中正确三元组所占的比例:
定义为知识图谱中正确三元组所占的比例: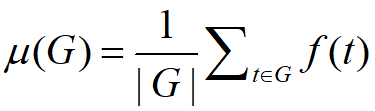 。其中
。其中 
研究方法
(1)灵感来源及整体框架
文章首先从人工评估的过程出发,利用两个具体的评估过程的实例,发现了不同评估实例间的差异及可进行改进的策略。如下图所示:


(2)抽样策略详述
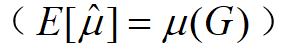 和
和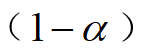 倍的置信区间(
倍的置信区间(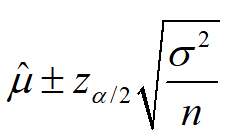 ,假设n个变量是独立同分布的)。其中,
,假设n个变量是独立同分布的)。其中,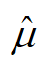 是根据抽样策略 D 得到的关于G的一个子集G’
是根据抽样策略 D 得到的关于G的一个子集G’ 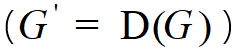 上的准确率的估计量,又将
上的准确率的估计量,又将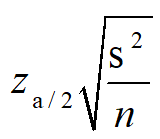 记为MOE 。然后,将静态图谱上的抽样样本的评估成本转换为一个最优化问题:
记为MOE 。然后,将静态图谱上的抽样样本的评估成本转换为一个最优化问题: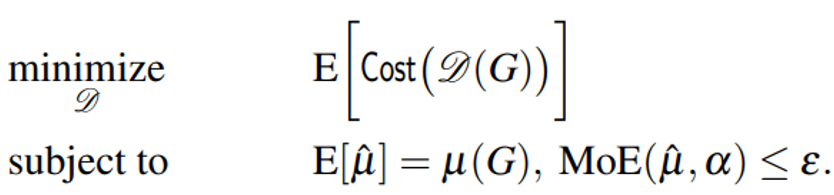

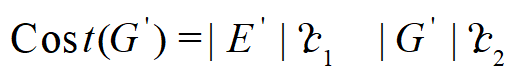 , E’是G’ 上的实体集合,C1、C2 分别是实体识别过程和关系验证过程的平均消耗。
, E’是G’ 上的实体集合,C1、C2 分别是实体识别过程和关系验证过程的平均消耗。2)静态图谱评估
对于静态图谱的评估,文章将抽样策略分为基于三元组的和基于实体的两类。其中前者采用简单随机抽样(SRS)策略,后者则设计了三种不同的聚类抽样(CS)策略。

而三种聚类抽样策略如下表所示(策略无偏性和置信区间的证明请参考论文1):
策略名称 | 策略描述 |
随机聚类抽样(RCS) | 从G中随机选择n个实体簇 |
加权聚类抽样(WCS) | 从G中依概率选择实体簇,概率为每个实体簇大小在G中所占的比例 |
在第一阶段,使用WCS选择实体簇; 在第二阶段,从第一阶段得到的每个实体簇中,随机选取 |



对于演化知识图谱的评估,文章提出了两种增量抽样评估方式,希望能够利用尽可能多的已标注样本对新图谱的准确率进行评估。第一种方法借鉴了经典水塘抽样(RS)的思路,将增量batch中每个实体的所有元组视为整体,根据三元组个数进行加权,计算key值确定选取的样本,并通过理论分析确定新抽取的样本数量不会太多。第二种是分层增量评估(SS),将图谱的增量视为一个单独的层,在其上使用两阶段加权抽样后与之前若干层的结果加权,直到置信区间小于阈值。这种方法的优点在于完全利用了前面所有的评估结果,因而效率更高。


实验验证
文章首先在不同的数据集上对静态图谱评估的四种抽样策略进行了比较,结果如下:

由上图可以看出,所提策略中的两阶段加权聚类抽样(TWCS)策略的性能最好。此外,还将TWCS策略与目前的SOTA方法(KGEval)在两个数据集上进行了对比,结果如下图:

同样可以看出TWCS策略具有优良的性能。
此外,为了验证分层抽样(Stratification)策略优化的有效性,文章对TWCS和应用分层的TWCS策略进行了性能比较,并给出了理论上可以达到的下界,结果如下图所示。

而对于演化图谱的两种增量评估策略(SS,RS),文章同样通过实验验证了其评估质量的有效性,如下图所示:

总结
这篇文章将对知识图谱准确率的抽样评估引入统计学框架,使得不仅能估计kg的准确率,还对抽样应该何时停止有了明确界限,并且使得结果更加可信。理论分析和实验验证部分都很完备,是一篇很有价值的文章。但与此同时,在抽样粒度、人工评测等部分还有很多可以深入研究的点。
 相 关 链 接
相 关 链 接

