




MySQL 数百万行数据条件查询优化
最近在公司实习做到一个项目,要在一个包含数百万行数据表(如果以日期来分类,大概是同一天里又十多万行数据)之中查询出日期在某个日期查询出与之相邻日期的那些行的结果,其中只有日期包含索引,然后还有多个条件查询。在刚开始的时候,需要花费2秒多才能查询出想要的结果,这个速度肯定对于用户查询很不友好,于是我被要求将查询出结果的时间降到300ms之内。然后经过多种方法优化,最终将查询时间减少到200多ms。速度快了仅10倍。
这篇博客就是基于此背景之下产生的,这里顺便将自己的优化方法记录下来以防以后遗忘。
MySQL 数百万行以上的数量多条件查询一般都会很浪费时间,这里提供了几种方法及思路进行优化,尽量优化到能够应用的场景。
首先创建一个百万数据量的数据表
这里使用了mysql的存储过程来插入数据,我通过改变存储过程CONCAT('2018-06-0',i)
中的2018-06-0
的月份的值从而得到不同日期的多行数据。
例子表格建立sql语句
-- PS: 这个表和存储过程是我从网上随便找的,可能建表方面不太规范,大家忽略,只要看字段值即可
-- 创建MyISAM模式表方便批量跑数据
CREATE TABLE `logs_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY comment '主键id',
`dt` VARCHAR(20) NOT NULL comment '记录日期',
`logtype` VARCHAR(255) DEFAULT NULL comment '日志类型',
`logurl` VARCHAR(255) DEFAULT NULL comment '日志url',
`logip` VARCHAR(255) DEFAULT NULL comment 'ip地址',
`logdz` VARCHAR(255) DEFAULT NULL comment '其他字段',
`ladduser` VARCHAR(255) DEFAULT NULL comment '其他字段',
`lfadduser` VARCHAR(255) DEFAULT NULL comment '其他字段',
`laddtime` DATETIME DEFAULT NULL comment '其他字段',
`htmlname` VARCHAR(255) DEFAULT NULL comment '页面名称'
) ENGINE=MYISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='日志表';
-- 创建索引
CREATE INDEX dtIndex ON cfile.logs_info(dt);
-- 添加表字段
ALTER TABLE cfile.logs_info ADD (ctime DATETIME DEFAULT '1991-01-01 10:10:10' NOT NULL);
ALTER TABLE cfile.logs_info ADD ( mtime DATETIME DEFAULT NOW() NOT NULL);
-- 创建存储过程
DROP PROCEDURE IF EXISTS my_insert;
DELIMITER $$
CREATE
/*[DEFINER = { user | CURRENT_USER }]*/
PROCEDURE `cfile`.`my_insert`()
/*LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'*/
BEGIN
DECLARE n INT DEFAULT 1;
DECLARE i INT DEFAULT 1;
loopname:LOOP
INSERT INTO `logs_info`(`dt`,`logtype`,`logurl`,`logip`,`logdz`,`ladduser` ,`lfadduser`,`laddtime`,`htmlname`) VALUES ( CONCAT('2018-06-0',i),2+n, '/index', '0:0:0:0:0:0:0:1', n, n+1, 'null', '2018-05-03 14:02:42', '首页');
SET n=n+1;
IF n%300000=0 THEN
SET i=i+1;
END IF;
IF n=3000000 THEN
LEAVE loopname;
END IF;
END LOOP loopname;
END$$
DELIMITER ;
-- 执行存储过程
CALL my_insert();
-- 数据插入成功后修改表模式InnoDB 时间稍微久点
ALTER TABLE `logs_info` ENGINE=INNODB;
建完表后和自定义一些插入数据后,数据量有两百多万行数据。这里需要说一下,多次统计数量的速度count(*)比较快,之前了解过count(*)会统计每行中特定某个标志行的id来统计的,而且会保留缓存,所以比较比count(id)快一点
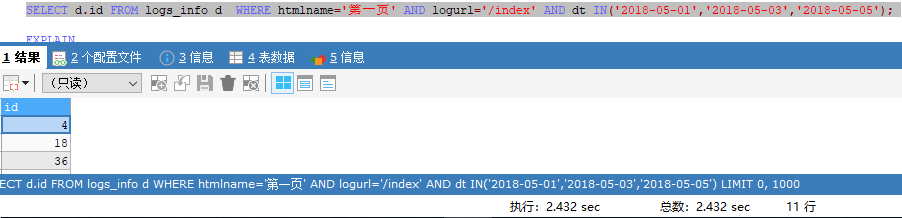
方法一,使用in, 查询
EXPLAIN
SELECT d.id FROM logs_info d WHERE htmlname='第一页' AND logurl='/index' AND dt IN('2018-05-01','2018-05-03','2018-05-05');
执行多次,发现使用时间大约为2.432秒。如果使用explain
做分析,可以看出是使用了全表扫描,共扫描两百多万行。in
查询结果
in的执行情况

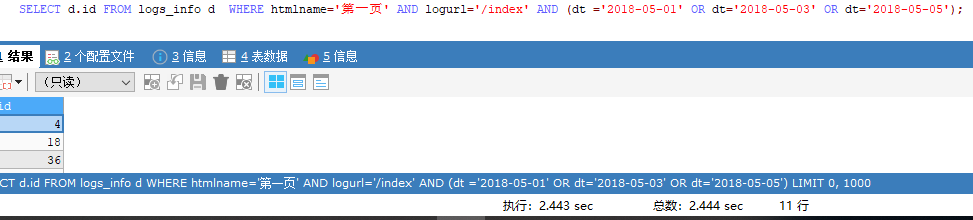
方法二,使用or, 查询
EXPLAIN
SELECT d.id FROM logs_info d WHERE htmlname='第一页' AND logurl='/index' AND (dt ='2018-05-01' OR dt='2018-05-03' OR dt='2018-05-05');
执行多次,发现使用时间大约为2.44秒。如果使用explain
做分析,可以看出也是使用了全表扫描,共扫描两百多万行。or
执行结果
or执行情况

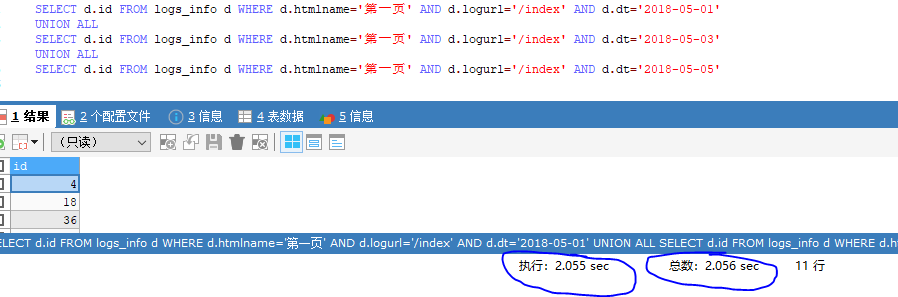
方法三,使用union all, 查询
EXPLAIN
SELECT d.id FROM logs_info d WHERE d.htmlname='第一页' AND d.logurl='/index' AND d.dt='2018-05-01'
UNION ALL
SELECT d.id FROM logs_info d WHERE d.htmlname='第一页' AND d.logurl='/index' AND d.dt='2018-05-03'
UNION ALL
SELECT d.id FROM logs_info d WHERE d.htmlname='第一页' AND d.logurl='/index' AND d.dt='2018-05-05'
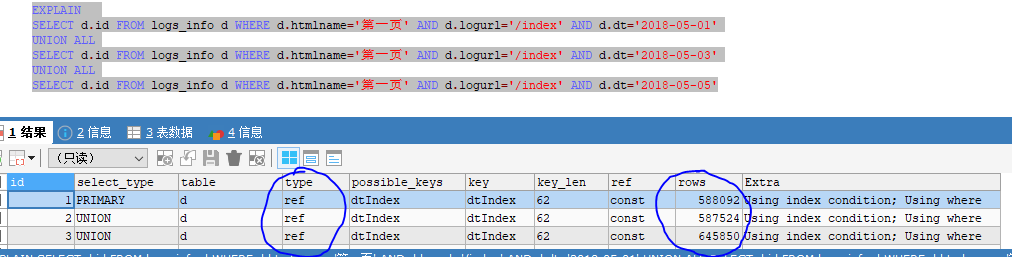
用union all进行查询,发现所用时间为2.05秒左右,比上两种情况都要快一点,然后通过explain
查看其执行情况,可以看出其使用了索引进行查询,然后查询的行数一共是60万*3 =180万行左右,比上两种的全表扫描行数少,所以速度会快一点。
union all
执行结果,
union all执行情况
方法四,代码解决,多线程执行再合并
EXPLAIN
SELECT d.id FROM logs_info d WHERE d.htmlname='第一页' AND d.logurl='/index' AND d.dt='2018-05-01'
大约1秒左右
这里看github项目中的代码,后面也会贴出代码。
代码:
/**
* 使用方法四,多线程得到数据,
*
* @param request 条件实体类
* @return 日志数据集合
**/
public List<LogPO> getData4(LogRequest request) throws InterruptedException, ExecutionException {
this.commonSetDt(request);
CountDownLatch latch = new CountDownLatch(3);
//设置新的条件
LogRequest[] requests = new LogRequest[2];
for (int i = 0; i < requests.length; i++) {
requests[i] = new LogRequest();
requests[i].setHtmlname(request.getHtmlname());
requests[i].setLogurl(request.getLogurl());
}
requests[0].setDt(getDateStr(request.getDt(), 2));
requests[1].setDt(getDateStr(request.getDt(), 4));
//异步执行
List<LogPO> list = new ArrayList<>(16);
Future<List<LogPO>> list1 = asyncService.execMapper(request, latch);
Future<List<LogPO>> list2 = asyncService.execMapper(requests[0], latch);
Future<List<LogPO>> list3 = asyncService.execMapper(requests[1], latch);
//等待5秒还没执行完,直接返回
latch.await(5, TimeUnit.SECONDS);
list.addAll(list1.get());
list.addAll(list2.get());
list.addAll(list3.get());
return list;
}
异步方法类
/**
* 异步方法操作类
*
* @author zhangcanlong
* @since 2019/5/8 9:22
**/
@Component
public class AsyncService {
@Autowired
private LogMapper logMapper;
/**
* 异步执行mapper
*
* @param request 条件
* @return 执行返回的实体类
**/
@Async("taskExecutor")
public Future<List<LogPO>> execMapper(LogRequest request, CountDownLatch latch) {
Long time1 = System.currentTimeMillis();
AsyncResult<List<LogPO>> asyncResult = new AsyncResult<>(this.logMapper.getLogsByCondition4(request));
System.out.println("线程名为:" + Thread.currentThread().getName());
System.out.println("花费时间为:" + (System.currentTimeMillis() - time1));
latch.countDown();
return asyncResult;
}
}
方法五,建立复合索引
暂时还没测试,速度会快很多,但是要修改数据库表,这里就不测试了
总结
建议如果能修改数据库的话,使用方法五,如果不能使用方法四,然后可以经常用一下explain做一下分析,再确定使用哪一种方法。
遇到的问题:
刚刚开始写的时候,忘记在Spring Boot的启动类上加上@EnableAsync注解了,导致多线程刚开始的时候并没有启作用,后来还测试了很久,一直奇怪为什么多线程还能比其他晚,果然写代码需要仔细。
调用的异步方法,不能为同一个类的方法,简单来说,因为Spring在启动扫描时会为其创建一个代理类,而同类调用时,还是调用本身的代理类的,所以和平常调用是一样的。其他的注解如@Cache等也是一样的道理,说白了,就是Spring的代理机制造成的。参考:https://blog.lqdev.cn/2018/08/17/springboot/chapter-twenty-one/
在默认情况下,未设置TaskExecutor时,默认是使用SimpleAsyncTaskExecutor这个线程池,但此线程不是真正意义上的线程池,因为线程不重用,每次调用都会创建一个新的线程。可通过控制台日志输出可以看出,每次输出线程名都是递增的。参考:https://blog.lqdev.cn/2018/08/17/springboot/chapter-twenty-one/
项目GitHub地址:
https://github.com/KANLON/practice/tree/master/data-optimize
