




去o一直是很热的话题,但是在去o的开始阶段我们遇到了很多疑惑,比如技术架构选型,数据迁移方案,工作量,哪些注意事项等问题。我也参与了全部的去o过程,目前应用上已经从oracle 迁移到mysql,redis,hbase,mongodb等多个开源数据库上。在迁移的过程的一些思考,分享出来。
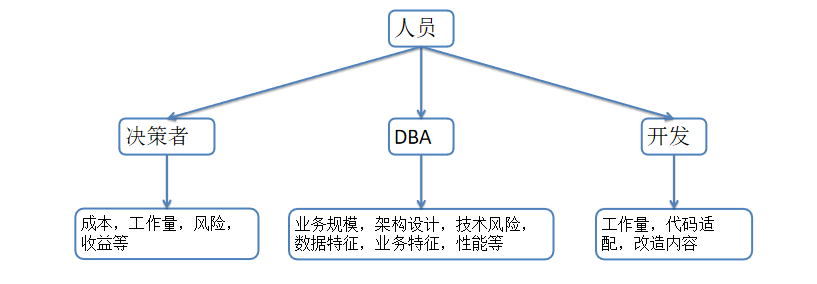
1:人员关注点:
2:数据库关注点

如果已经确认下来要进行数据库去o迁移改造,那么每个角色的关注点肯定不同,但是不管是何种业务或者业务特征,或者数据特点。在当下的数据库中都已经有所体现。可以从数据库的物理信息,数据库运行态信息,sql信息中读取到。那么在数据库中具体的从哪几个方面入手,才能帮助我们对去o的成本,工作量,技术风险等有个明确的预评估呢。
在这里我从数据库画像,数据库基础组件选型,数据库迁移三个方面来说明。
数据库画像:
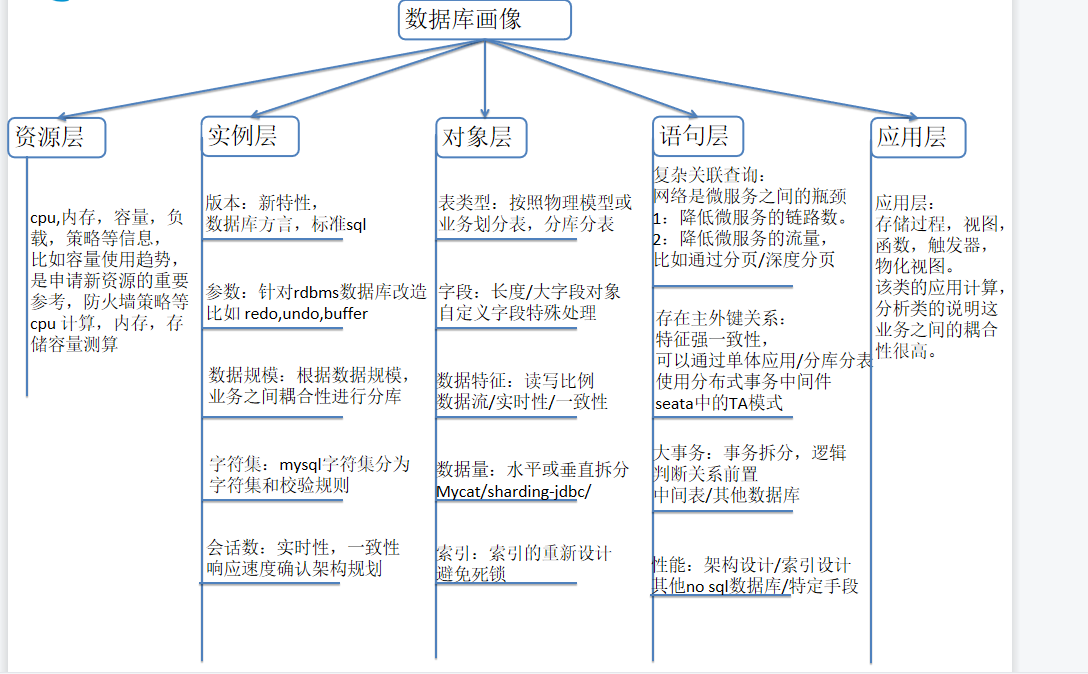
资源层
不管是数据库还是应用,都要涉及到的资源申请。比较重要的几个物理资源,比如cpu,内存,存储,带宽。在这里进行一个简单的说明
cpu
cpu资源申请,需要结合业务类型,并发量,响应时间,cpu上下文切换,系统预留等因素。原则上cpu个数为:(并发量*(响应时间+cpu切换时间))2,
系统预留cpu资源50%
比如响应时间0.5s,常规并发量为10,cpu切换时间由于很小可以忽略,cpu=0.510*2=10,结合实际情况,数据库对于应用的要求是短平快,因此很多情况下sql执行时间远远小于0.5,该情况可以设置cpu 个数为8C
上面只是一个简单的cpu 资源的计算,当然还要结合其他因素。
内存
:测算方法一:服务器内存主要包括操作系统占用内存,应用连接消耗的内存,数据库内存和系统预留内存,总体来说 数据库内存约占整个物理内存的60%
在mysql中数据库内存=key_buffer_size + innodb_buffer_pool_size + buffer_cache_size+ innodb_log_buffer_size+ max_connections * (read_buffer_size + read_rnd_buffer_size+ sort_buffer_size+ join_buffer_size+ tmp_table_size + thread_stack)。
测算方法二:按照标准设计,物理内存和cpu核数按照比例分配4:1分配
由于内存和sql运行状态息息相关,并不能完全设置准确,需要在运行一段时间按后,观察数据库负载,在进行调整。
容量
:系统存储系统和备份系统容量,在进行容量计算时,可以根据当下数据库中的容量大小进行评估结合最近几年的容量增长。比如在进行自建mysql 容量评估中,需要考虑到业务类型存储空间,binlog日志,备份,在加上系统预留。
总之资源层评估需要对系统架构设计有着深刻理解,但是如果我们没有具体的信息,oracle awr中的Load Profile 可以帮助我们提供cpu,io,存储,内存等相关的信息。
实例层
在数据库实例层方面也有很多需要注意的东西,在这里我列举了迁移过程中,比较重要的几个方面。
版本
oracle数据库版本,每次oracle版本的发布都代表着新特性的产生,因此oracle 新特性使用的越多,对后期去o的影响越大,比如间隔分区特性,19c 中的自动索引管理等新特性的使用。
参数
在进行关系型数据库时候改造时,有一些共性的参数需要关注,比如oracle to mysql中的innodb buffer 该参数可以设置成实际的物理内存50-60%。redo 大小需要关注特别是日志切换频率,undo 空间的大小决定着mysql 需要创建几个undo 文件。
字符集
不同的数据库,可能字符集支持不同,该问题在后期的数据迁移过程中有着重要影响。在mysql中字符集分为数据库字符集和校验字符集。一般情况下都要求为utf8mb4. 请特别注意。
会话
该会话包含多个维护:用户活跃会话数,用户的并发会话数,最大并发会话数,热点用户会话类型。该参数具有重要意义,具体着后期数据库基础组建的选型,比如大量的配置数据库的查询,大量的权限,菜单类的查询等都可以使用redis 进行缓存,当然该类型也和业务类型有关。
数据规模
在进行数据迁移改造过程中,经常会提到分库分表,该分库分表的的很重要的影响因素就是业务之间的耦合性和数据规模。如果把这两个因素拿到数据库中就是规划好每个schema的数据量大小,以及schema的业务类型。
总之:数据库实例的分析不只是包含上面的一些影响因素,但是在oracle的awr已经给我们提供了详细的参考。
对象层
在对象层上涉及到具体的表改造,此过程给我们带来了很多的问题。数据库的数据存储类型主要就是表和索引。按照表的大小分为:大表和小表。按照表字段类型:常规字段和大对象字段。按照表类型:常见的堆表和分区表。
表的大小
表的大小可以按照数据量和物理大小来区分。从原则上来说不管是物理上还是数据量上的大表都应该进行拆分,但是可要考虑到当前表访问类型或者说是数据特征。如果是大量的复杂关联查询可以通过架构设计,比如es,hbase 进行优化。如果是没有实时性要求,可以通过mysql读库分担压力,但是需要还是需要弄清表大小供后续分析使用
表字段类型
在迁移过程中表字段类型会变化比较大。比如从oracle 迁移到mysql中,字段改变会比较大。常用字段迁移比较简单。但是大字段的迁移需要注意或者重新设计,可能会经常出现图片类型,大文本字段需要进行特殊处理。在这里针对大字段图片提供一些思路:
方法1:图片数据存储在文件系统中如果是入云可以放在oss存储中,数据库中只保留图片路径。
方法2:图片数据建议压缩后存储在数据库中,并且放在独立的实例上,压缩方法为:把blob 字段压缩,压缩成varchar存储(先gzip压缩,然后用base64将压缩后的byte编码 ) 读取。
方法3:表拆分,把blob字段从表中拆分独立出一个新表中。
因此针对大字段,自定义的等非常见字段需要进行特殊备注和说明。
表类型
常见的表类型就是分区表和非分区表,一旦涉及到分区表,往往代表这个表的数据量很大。针对大表的改造,正如上面的表大小说的,可能会涉及到分库分表,导致整个架构或者基础组件都需要进行调整。开源hbase列式存储数据库,中间件sharding-jdbc或者mycat的引用,也可能出现一致性的问题,引用seata中间件,也包括可能sql代码的改造,因此针对大表的改造需要慎重,需要重点关注。
索引设计
在云数据库rds中数据库的默认隔离级别是repeatable read该隔离级别比较高,经常会出现锁问题,特别是组合索引上出现的概率更高,因此针对表的设计,索引的设计要重新审视。在这里专门列出。
数据特征
数据特征:主要是该表的读写比例,是否静态数据。不同的业务类型的数据,可以采用不同的方法。
语句层
语句层和业务类型关系非常紧密,很多架构设计是由业务主导。但是如果落实到数据库上就是具体的sql语句。在这里我列出了几个常见的sql问题,并给出一些解决思路
复杂关联查询
如果涉及到微服务:降低微服务之间的链路数或者降低微服务之间的流量,可以通过分页解决。当然也可以通过架构设计比如读库执行。或者优化sql和表结构。
强一致性
强一致性在oracle数据库中比较明显的一条是通过主外键或者触发器表现,但是拆分到开源数据库中,可以通过单体应用来解决或者引用分布式事务的seata组件,请注意seata组件的三种模式tcc,ta,saga
大事务
大事务往往是一个事务中包含很多sql语句,很多的业务逻辑判断。可以通过拆分把逻辑关系判断前置,不放在事务中运行或者引用其他数据库。如果出现单条sql语句需要更新大量的数据,实际上并没有很好的办法,如果可以的话,可以转换为主键更新。
热点会话
热点会话,比如出现大量的登陆,查询某个会话,权限或者菜单类,需要引入其他缓存数据库redis 来降低对mysql 的冲击。
应用层
实际上也算是逻辑计算层,有大量的存储过程,视图等,该类型的出现在数据库层面并没有很好的办法,说明业务之间的耦合性很高。可以引入kafka尝试解决,但是代码改造量会很大。也可以在数据库实例划分时把业务耦合性很高且不容易拆分的业务划分到一个实例中
以上是我的数据库画像分析的一些想法。也会继续分析更新。也请大家一起探讨
