




之前文章有介绍过基础的MergeTree的物理存储结构,数据会按分区目录的形式保存到磁盘。本文着重介绍一些二进制文件的格式及内容。
首先按照如下规则创建表,用于后续数据的对照查询
#创建表CREATE TABLE default.ansel(`a` Int32,`b` Int32,`c` Int32,INDEX `idx_c` (c) TYPE minmax GRANULARITY 1)ENGINE = MergeTreePARTITION BY aORDER BY bSETTINGS index_granularity=3, index_granularity_bytes = 0;#插入测试数据insert into default.ansel(a,b,c) values(3,10,4),(3,9,5),(3,8,6),(3,7,7),(3,6,8),(3,5,9),(3,4,10);
[clickhouse@localhost var/lib/clickhouse/data/default/ansel ]$ tree├── 3_1_1_0│ ├── a.bin│ ├── a.mrk│ ├── b.bin│ ├── b.mrk│ ├── c.bin│ ├── checksums.txt│ ├── c.mrk│ ├── columns.txt│ ├── count.txt│ ├── minmax_a.idx│ ├── partition.dat│ ├── primary.idx│ ├── skp_idx_idx_c.idx│ └── skp_idx_idx_c.mrk├── detached└── format_version.txt
table_name #表名├─ partition_{index} DIR #分区目录│ │ # 基础文件│ ├─ checksums.txt BIN #各类文件的尺寸以及尺寸的散列│ ├─ columns.txt TXT #列信息│ ├─ count.txt TXT #当前分区目录下数据总行数│ ├─ primary.idx BIN #稀疏索引文件│ ├─ {column}.bin BIN #经压缩的列数据文件,以字段名命名│ ├─ {column}.mrk BIN #列字段标记文件│ ├─ {column}.mrk2 BIN #使用自适应索引间隔的标记文件│ ││ │ # 分区键文件│ ├─ partition.dat BIN #当前分区表达式最终值│ ├─ minmax_{column}.idx BIN #当前分区字段对应原始数据的最值│ ││ │ # 跳数索引文件│ ├─ skp_idx_{column}.idx BIN #跳数索引文件│ └─ skp_idx_{column}.mrk BIN #跳数索引表及文件│└─ partition_{index} DIR #分区目录
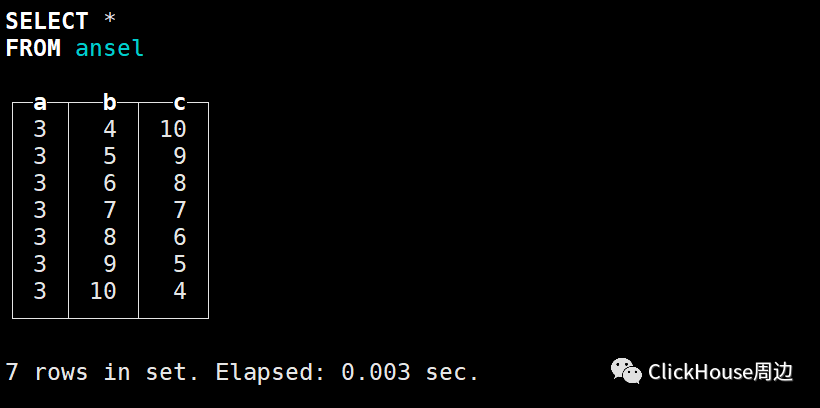
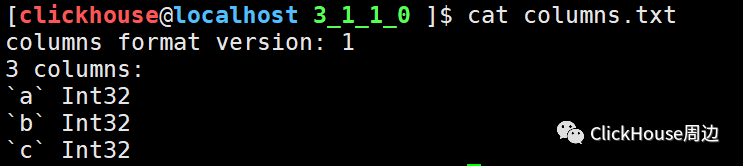
columns.txt
count.txt

primary.idx

{column}.mrk
以b.mrk为例

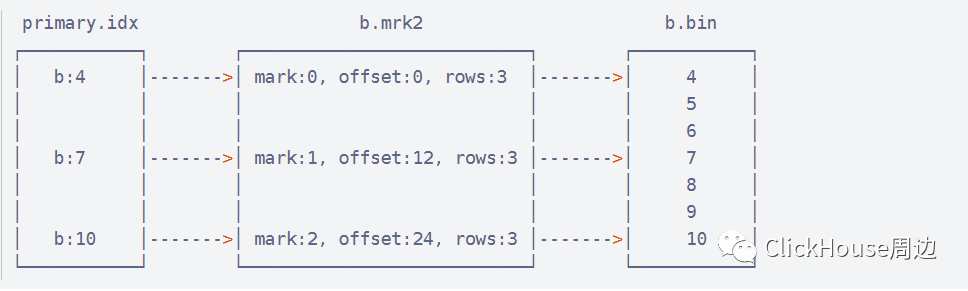
{column}.bin
数据文件,使用压缩格式存储,默认使用LZ4压缩格式,用于存储某一列的数据。
以b.bin为例
一个压缩数据块由头信息和压缩数据两部分组成。头信息固定使用9位字节表示,具体由1个UInt8(1字节)和2个UInt32(4字节)整型组成,分别代表了使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小。
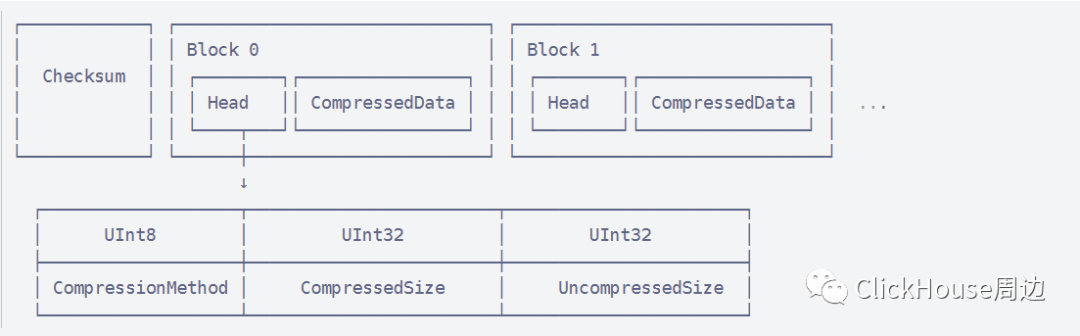
Checksum:该bin文件的校验值,16字节。 Block:数据块,包含Head和CompressedData。 Head:包含CompressionMethod、CompressedSize、UncompressedSize三部分,其中CompressionMethod类型为UInt8占4字节,包含LZ4(0x82)、ZSTD(0x90)、Multipile(0x91)、Delta(0x92),CompressedSize类型为UInt32占4字节,UncompressedSize类型同样为UInt32占4字节。 CompressedData:压缩数据块,默认最小65535字节/64K,最大1048576字节/1M。
clickhouse-compressor --decompress < 3_1_1_0/b.bin | od -An -i -w4

clickhouse-compressor --stat < b.bin

insert into default.ansel(a,b,c) values(4,10,4),(4,9,5),(4,8,6),(4,7,7),(4,6,8),(4,5,9),(4,4,10),(4,4,11),(4,7,12),(4,4,13),(4,8,14),(4,6,15),(4,4,16),(4,6,17);
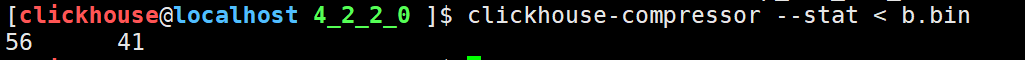


可以看到从04 00 00 00到0a 00 00 00,反过来看也就是4-10
partition.dat
用于保存当前分区下分区表达式最终生成值。

minmax_a.idx

checksums.txt

文章转载自 ClickHouse周边,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
