




我们再来看下上一节讲到的prometheus的架构图。其中prometheus server 不关注数据源,只会从数据源拉取数据,数据源(图示中的2)包括pushGateway(由业务服务上报)和 exporters 两部分。我们今天就来了解exporter 的工作机制。
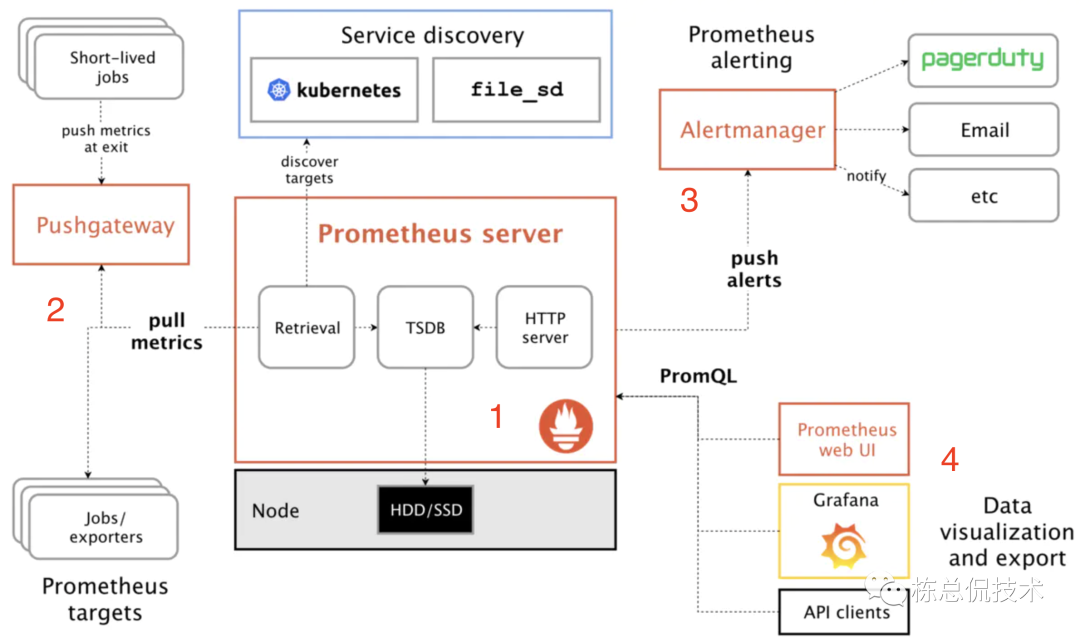
我们首先来关注下 prometheus官方提供的一个exporter: node_exporter (https://github.com/prometheus/node_exporter)。node_exporter获取主机的内存、CPU、磁盘、网络等资源的监控信息。prometheus server通过其提供的 /metrics 接口拉取各项监控指标的数据。
在上一节已经讲解了如何部署 node_exporter 以及通过 metrics 接口查看了其收集的指标项。以下列出一小部分node_exporter收集的指标项:
# HELP node_arp_entries ARP entries by device# TYPE node_arp_entries gaugenode_arp_entries{device="eth0",os="linux"} 1# HELP node_boot_time_seconds Node boot time, in unixtime.# TYPE node_boot_time_seconds gaugenode_boot_time_seconds{os="linux"} 1.611817019e+09# HELP node_context_switches_total Total number of context switches.# TYPE node_context_switches_total counternode_context_switches_total{os="linux"} 2.0079919001e+10# HELP node_cooling_device_cur_state Current throttle state of the cooling device# TYPE node_cooling_device_cur_state gaugenode_cooling_device_cur_state{name="0",os="linux",type="Processor"} 0node_cooling_device_cur_state{name="1",os="linux",type="Processor"} 0node_cooling_device_cur_state{name="2",os="linux",type="Processor"} 0node_cooling_device_cur_state{name="3",os="linux",type="Processor"} 0# HELP node_cooling_device_max_state Maximum throttle state of the cooling device# TYPE node_cooling_device_max_state gaugenode_cooling_device_max_state{name="0",os="linux",type="Processor"} 7node_cooling_device_max_state{name="1",os="linux",type="Processor"} 7node_cooling_device_max_state{name="2",os="linux",type="Processor"} 7node_cooling_device_max_state{name="3",os="linux",type="Processor"} 7# HELP node_cpu_guest_seconds_total Seconds the CPUs spent in guests (VMs) for each mode.# TYPE node_cpu_guest_seconds_total counternode_cpu_guest_seconds_total{cpu="0",mode="nice",os="linux"} 0node_cpu_guest_seconds_total{cpu="0",mode="user",os="linux"} 0node_cpu_guest_seconds_total{cpu="1",mode="nice",os="linux"} 0node_cpu_guest_seconds_total{cpu="1",mode="user",os="linux"} 0node_cpu_guest_seconds_total{cpu="2",mode="nice",os="linux"} 0node_cpu_guest_seconds_total{cpu="2",mode="user",os="linux"} 0node_cpu_guest_seconds_total{cpu="3",mode="nice",os="linux"} 0node_cpu_guest_seconds_total{cpu="3",mode="user",os="linux"} 0# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
通过上面密密麻麻的指标项很难分析出当前监控机器各项性能是否正常,更无法在出现异常时及时告警。
而在上节我们也讲到了使用Grafana来通过可视化页面查看监控数据,通过各种趋势图、统计表能够很直观的查看各项指标。而这些图、表的元数据就是 metrics 接口收集的指标数据通过各种计算得到的。
我们来看一个简单的 node_exporter 的 Grafana 监控dashboard。这个dashboard中包括CPU使用率、内存使用率、磁盘空间、读写IO速度、网速等panel。而每个 panel 都来自于若干个指标项计算的结果。
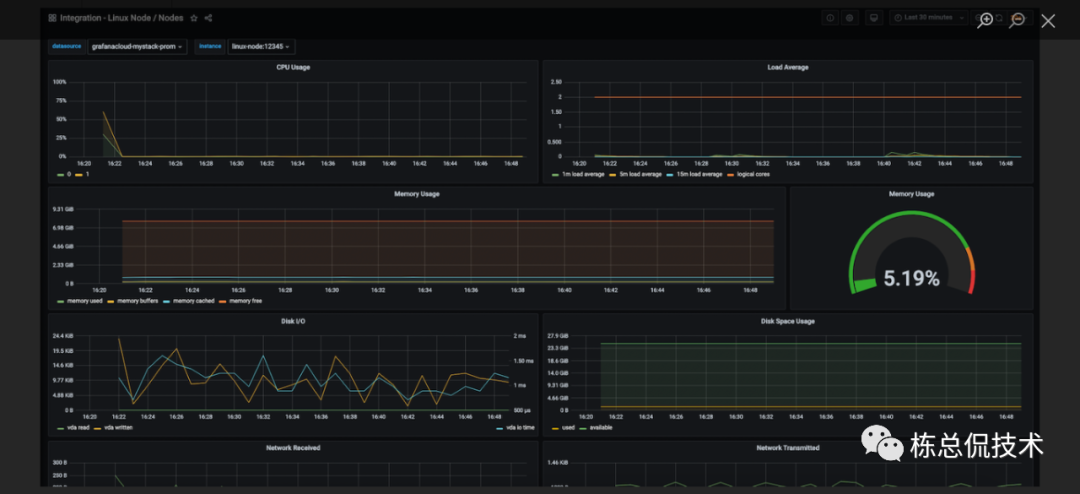
我们先来看下CPU使用率的计算公式:
(1 - avg(rate(node_cpu_seconds_total{origin_prometheus=~\"$origin_prometheus\",job=~\"$job\",mode=\"idle\"}[$interval])) by (instance)) * 100
先不关注语法,粗略的看就是用1 - 去CPU的空闲率,其中用到了指标 node_cpu_seconds_total 。我们在回过头到 metrics接口看看这个指标项的元数据:
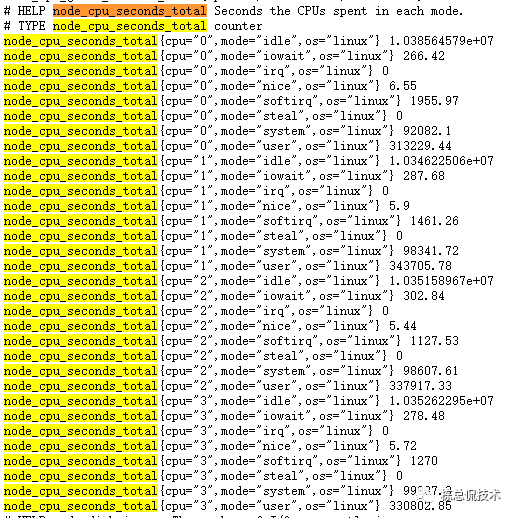
node_cpu_seconds_total 其中包括很多条数据,我们可以看到每条数据包含若干参数(json格式):
cpu:表示第几个cpu,以上截图说明该服务器含有4个cpu,编号分别为0、1、2、3;
mode:表示模式,例如user表示用户使用的cpu,system表示系统使用的cpu,idle表示空闲的cpu;
os:表示操作系统
而紧跟在参数后面的是值,表示使用的cpu比例数值。
可以看到其他的指标也是 指标名称 {参数} 值 格式。
我们再来逐层看下计算公式,其中最里面一层
node_cpu_seconds_total{origin_prometheus=~\"$origin_prometheus\",job=~\"$job\",mode=\"idle\"}[$interval]
表示取 node_cpu_seconds_total 中 mode为 idle 的值的和,记为x。
avg(rate(x))
rate 表示取一分钟以内所有的值的和, avg表示对这一分钟的数据求和后取平均值。
这样就计算出了cpu这一分钟的空闲率,使用 1- 空闲率表示cpu的使用率。
我们再来看下使用内存的占比计算公式:
100 -(avg(node_memory_MemAvailable_bytes{job="node", instance="localhost:8081"})/avg(node_memory_MemTotal_bytes{job="node", instance="localhost:8081"})* 100)
除了node_exporter,prometheus官方提供了许多其他中间件的监控exporter,例如mysql,redis,elasticsearch,kafka等,我们只需要根据自己的需要集成至 prometheus 即可。而后续文章我将带来这些常用的exporter的各项常用指标的讲解。
除了上述官方的exporter,还有许多社区用户贡献的优秀exporter后续也会向大家介绍到。
但是我们的生产实践中难免遇到奇葩或者少见的监控项,需要我们自己开发exporter来满足业务场景。接下来我将使用Go代码来向大家讲解如何实现exporter并集成至 prometheus 。
我们直接看代码:
package mainimport ("fmt""math/rand""net/http""sync""github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promhttp""github.com/shirou/gopsutil/host")type demoCollector struct {desc *prometheus.Descmutex sync.Mutex}var hostname stringfunc init() {//注册自身采集器prometheus.MustRegister(newDemoCollector())}func main() {http.Handle("/metrics", promhttp.Handler())if err := http.ListenAndServe(":8082", nil); err != nil {fmt.Printf("Error occur when start server %v", err)}}func newDemoCollector() prometheus.Collector {host, _ := host.Info()hostname = host.Hostnamereturn &demoCollector{desc: prometheus.NewDesc("request_duration","请求的响应时间",[]string{"dynamic"},prometheus.Labels{"label": "a static label", "HOST_NAME": hostname}),}}func (d *demoCollector) Describe(ch chan<- *prometheus.Desc) {ch <- d.desc}func (d *demoCollector) Collect(ch chan<- prometheus.Metric) {d.mutex.Lock()defer d.mutex.Unlock()ch <- prometheus.MustNewConstMetric(d.desc, prometheus.GaugeValue, rand.Float64(), "dynamic bvalue")}
自己编写 exporter 的关键逻辑为实现 Collector接口:
type Collector interface {Describe(chan<- *Desc)Collect(chan<- Metric)}
定义自己收集指标的结构,并实现该接口的Describe、Collect方法:
Describe:传递定义的描述符给 channel
Collect:将抓取的数据写入channel,开发者主要的实现逻辑均在该接口内完成。
当我们运行起服务并访问 metrics 接口,可以看到有如下的返回(还包含有其他的指标数据,这里没有列出来),则表示 request_duration指标采集成功:
# HELP request_duration 请求的响应时间# TYPE request_duration gaugerequest_duration{HOST_NAME="192.168.0.102",dynamic="dynamic bvalue",label="a static label"} 0.6046602879796196
我们可以把该 exporter 集成至 prometheus ,修改prometheus server 的配置文件 prometheus.yaml 增加以下内容并重启。
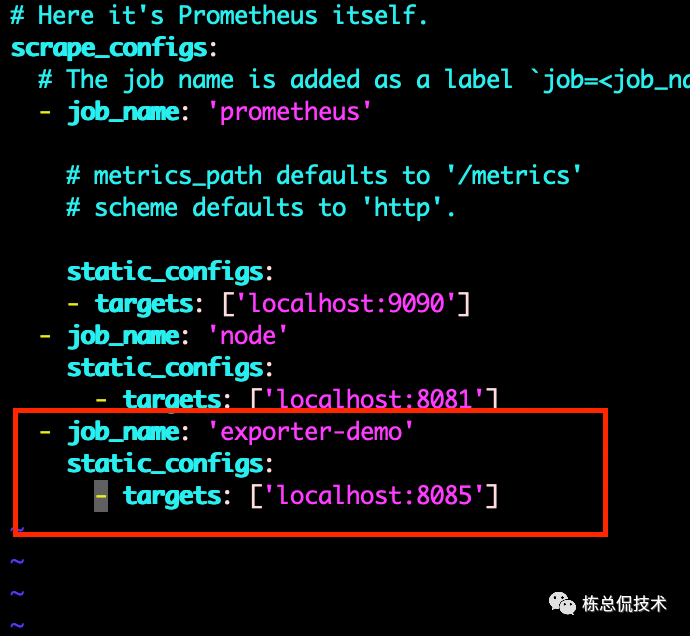
此时,prometheus server会周期性的调用该 exporter 的 /metrics 接口拉取监控指标数据,我们可以在上一节讲解中已经集成了 Grafana 部署的 prometheus 界面中增加 panel,显示该指标项。
如下图,简单的配置收集指标数据(未进行任何计算):
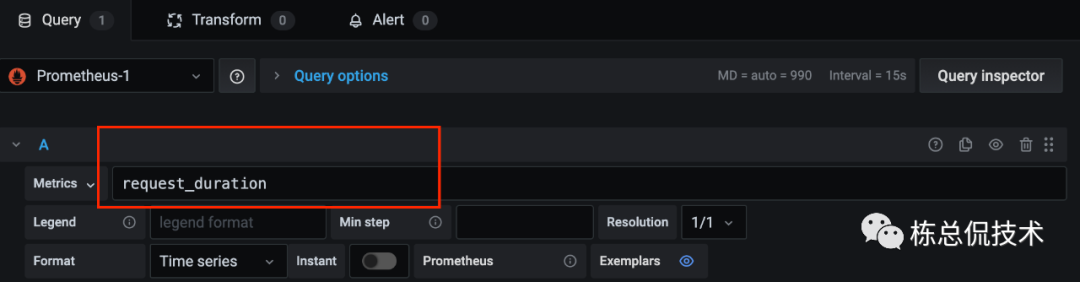
如下图,可在panel中以图形的形式查看指标数据。
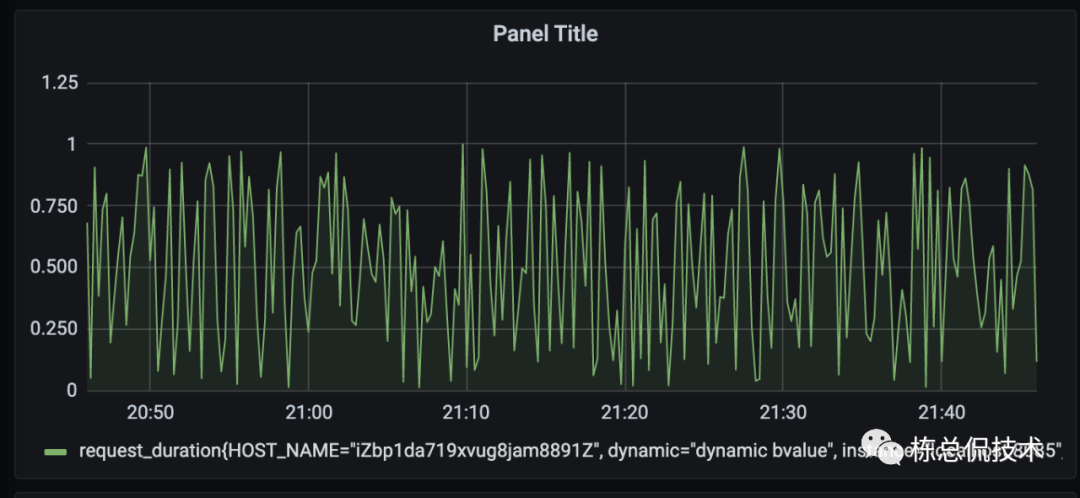
后续章节我将继续带来 exporter 的讲解,会结合着常用的服务以及其各项指标一起解读,来搭建一套完整的监控系统。
