




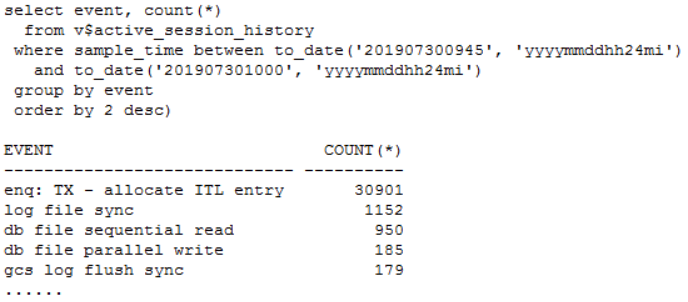
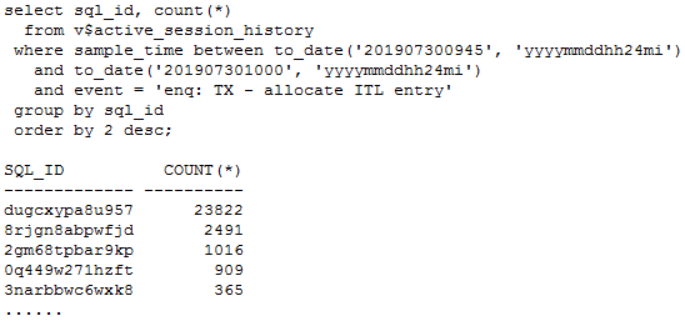
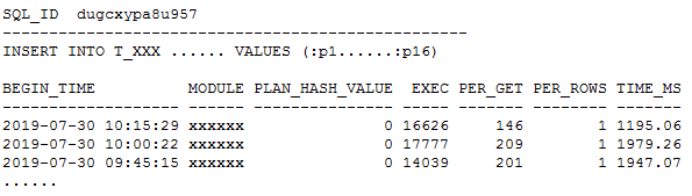
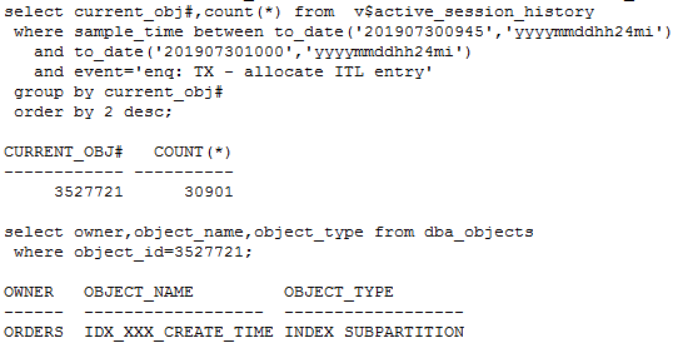
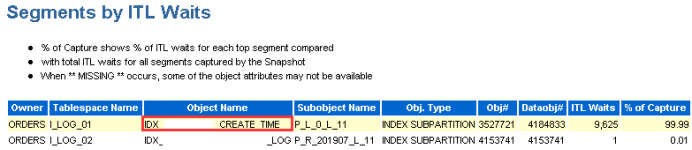
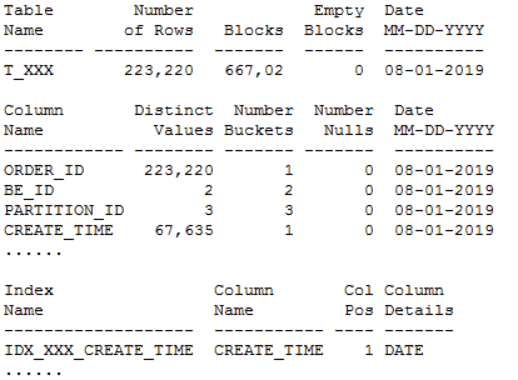
发现问题 生产系统某核心库发生enquence告警,业务反馈对前台影响严重。 1. 查看等待事件 查看当时等待事件主要是enq: TX - allocate ITL entry: 2. 查看TOP SQL 当时主要等待事件是ITL事务槽等待,进一步查看对应的SQL主要是SQL_ID dugcxypa8u957: 对应SQL是往T_XXX表中插入数据,SQL每15分钟执行1万多次,高并发引起了ITL事务槽等待。由于是insert values,对应的plan_hash_value值是0: 3. 查看发生ITL的对象 可以通过ash视图的CURRENT_OBJ#字段查到发生ITL事务槽的对象:T_XXX表的IDX_XXX_CREATE_TIME索引。 从AWR报告中的Segments by ITL Waits部分也可以看出发生ITL事务槽的对象是IDX_XXX_CREATE_TIME索引 查看该索引的initrans值 4. ITL事务槽的概念 在了解ITL事务槽的概念之前,我们先需要了解一下事务表的概念:每个数据块的块头都有一个事务表,事务表中会建立一些条目来描述哪些事务将块上的哪些行/元素锁定。这个事务表的初始大小由参数initrans指定的,事务表会根据需要动态扩展,最大可达到maxtrans个条目。 ITL(Interested Transaction List)就位于数据块头的事务表中,是一个数据块初始预先分配给并行事务的空间,由Xid,Uba,Flag,Lck和Scn/Fsc组成,用来记录所有发生在该数据块的事务。一个ITL可以看作一条事务记录,如果事务已经提交或者回滚,那么ITL的槽位就可以反复使用;如果事务一直没有提交,那么这个事务将一直占用ITL槽位。数据块的initrans为2意味着这个数据块中最多有两个并行的事务可以独立的通过自己的事务槽,实现对共享数据块中的行数据的事务操作。 由于初始分配ITL的大小不能超过数据块大小的50%,也就是说一个8192字节的数据块,ITL的大小不能超过4096,而一个ITL占用24个字节,也就是最多可以分配169个事务槽,,超过该值的设置会被忽略。即一个8192字节的数据块,即使initrans设置为200,也只会有169个事务槽被分配,这点可以通过dump数据块验证。 DUMP数据块可以看到具体的事务槽信息: Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0026.01e.00000049 0x04802ad5.0013.3a --U- 3 fsc 0x0000.013f5d04 0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000 · Xid:事务ID,回滚段事务表中有一条记录和这个事务对应 · Uba:事务对应的回滚段地址 · Flag:事务标志位。标志位记录了这个事务的操作,各个标志的含义分别是: ----- = 事务是活动的,或者在块清除前提交事务 C--- = 事务已经提交并且清除了行锁定 -B-- = this undo record contains the undo for this ITL entry --U- = 事务已经提交(SCN已经是最大值),但是锁定还没有清除(快速清除) ---T = 当块清除的SCN被记录时,该事务仍然是活动的,块上如果有已经提交的事务, 那么在clean ount的时候,块会被进行清除,但是这个块里面的事务不会被清除。 · Lck:影响的记录数 · Scn/Fsc:快速提交的SCN或者Commit SCN。 5. ITL等待事件处理方式 5.1数据库层面 索引事务槽的根本原因是并发量过高,导致的索引块的ITL不够用,数据库层面我们需要做的就是打散数据,可以考虑以下几种处理方式: · 对于ITL事务槽等待,通常的方法是增大initrans,但是该参数的修改只针对新块生效,建议修改后重建索引 · 创建反转索引,反转索引对于单向增长字段效果非常好。缺点是索引会越来越大,可能到最后buffer cache都放不下,访问该索引的时候将会产生大量的IO;而且反向索引无法实现范围查询 · 创建为global hash索引,优点是数据可以进一步打散,缺点是对表进行DDL操作可能会导致索引经常失效 · 智能建索引,一般智能主键的组成是:实例ID-进程号取余-序列号,后面跟上索引字段,这种方式创建的索引可以非常好的打散数据,在不影响性能的情况下实现业务需求。但是实际情况中很少有通过序列号去查询数据的。 Ø 增大initans 发生事务槽等待的索引IDX_XXX_CREATE_TIME的initrans是200,上面讲过一个8k的数据块最多可分配169个ITL槽位,即使initrans设置为200也会被忽略,调整initrans后重建了该索引。通过增大initrans的方式解决ITL事务槽等待这条路已经走不通了。 Ø 反转索引 索引字段create_time经常需要范围查询,而反转索引无法用于范围查询,排除该方法。 Ø Global hash索引 T_XXX表经常需要分区维护,global索引可能会频繁的失效,需要更多的维护成本,排除该方法。 5.2业务层面 Ø 降低并发 对于ITL,如果initrans应该足够大,索引也已经重建,不考虑反转索引、global hash索引等方式,我们还可以要求业务降低并发,这也是一种解决方式。 Ø 改造表 总结一下问题:往表中插入数据的时候需要维护单边增长的索引IDX_XXX_CREATE_TIME,并发太高加上热块导致部分索引块的ITL事务槽不够。单边增长的索引极容易产生热块,如果可以进一步打散表中的数据,问题就能得到缓解。 解决问题 6. 对象信息收集 6.1表和索引信息 IDX_XXX_CREATE_TIME索引字段CREATE_TIME是单边增长的字段,新插入的数据都在索引块最右端,高并发的插入下肯定会产生热块。如果我们可以把CREATE_TIME字段通过某种方式打散,那么所有的并发访问就不会集中在最右端的某些数据块,那么这些热点数据块发生ITL事务槽不够的概率也会大大降低。 如何打散索引数据块呢?我们知道索引和表的分区规则一般都是一致的, 如果我们调整表的分区方式进一步打散数据,索引数据也就可以打散。 6.2表分区方式 T_XXX表的分区方式是PARTITION_ID+BE_ID两级LIST分区,其中PARTITION_ID的默认值是mod(to_char(sysdate,'DD'),3),业务需要按照该字段清理数据,只保留前一天的数据,BE_ID是地市编码。PARTITION_ID只会有0、1、2三个值,他的最大的作用就是数据清理,对于打散数据效果并不明显。 Oracle的分区方式一般是range、list和hash,其中打散数据效果最好的首选hash分区,hash分区是通过一定的规则打散表中数据使数据均匀分布。我们可以选取表中的特别好的某个字段用来做hash分区,观察表中的字段,选择了选择性很好的ORDER_ID字段做hash分区字段。 7.分区改造 对于T_XXX表的改造,我们有两种选择: ① 改造表的分区方式为list(be_id) + hash(order_id),去掉原有PARTITION_ID分区方式,hash分区建议一般建议2的n次方,这里分为4或者8个即可。PARTITION_ID字段分区主要是为了清理数据方便,OM_ORDERS表数据量20多万并不是很多,改造后可以通过delete table where partition=0,1,2这样的方式清理数据,抛弃原有的按照partition_id字段分区truncate数据的方式。而且对于核心业务表,并不建议频繁的DDL,会造成跟该表相关的SQL全部重新硬解析,可能造成大量的library cache lock等待。 ② 改造为range(partition_id+be_id) + hash(order_id)分区方式。但是对于这种改造,由于是两个字段的range,所以需要特别考虑range分区数据落入的范围,查看表中be_id最大值是99,那我们第二个字段be_id可以设为100。建议参照下面的测试进行range分区的划分: 创建一个partition_id+be_id字段的range分区表,这里最重要是values less than后面的数据取值范围 两个字段range分区数据的比较规则: Ø 比对第一个字段:如果比第一个字段大,肯定不落在这个分区; Ø 如果小于等于第一个字段,继续比较第二个字段: Ø 第二个字段小于第二个字段的分区规则则落入该分区。 我们用下面几个数据作进一步说明: (0,0)这条数据: 第一个字段0:小于等于P1分区的第一个字段0; 第二个字段0:小于P1分区的第二个字段100,这条数据落入P1分区。 (0,99)这条数据: 第一个字段0:小于等于P1分区的第一个字段0; 第二个字段99:小于P1分区的第二个字段100,这条数据落入P1分区。 (1,99)这条数据: 第一个字段1:大于P1分区的第一个字段0,肯定不落入P1分区; 第二个字段99:小于P2分区的第二个字段100,这条数据落入P2分区。 (2,99)这条数据: 第一个字段2:大于P1的第一个字段0,不落入P1、大于P2的第一个字段1,不落入P2; 第二个字段99:小于P3分区的第二个字段100,这条数据落入P3分区。 查看表分区中数据验证: 总结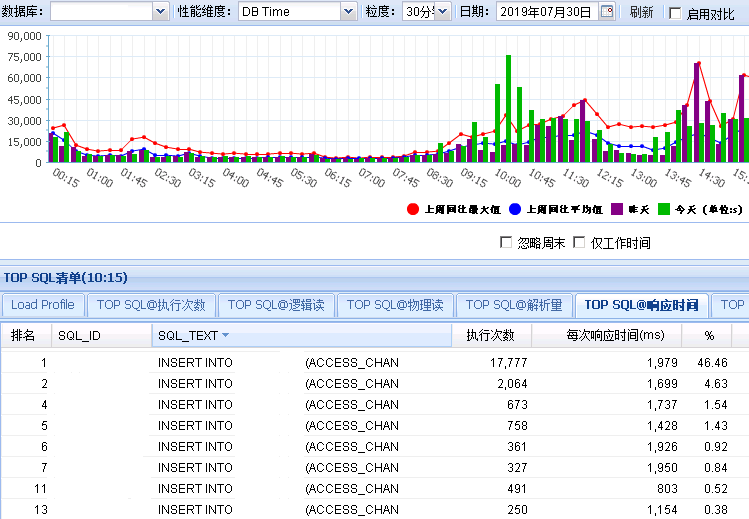
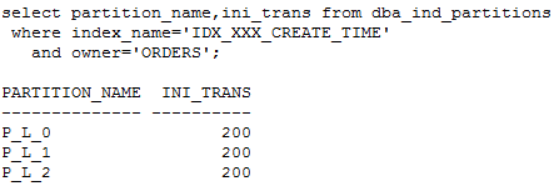



第一个字段1:小于等于P2分区的第一个字段1,继续比对第二个字段;
第一个字段2:小于等于P3分区的第一个字段2,继续比对第二个字段;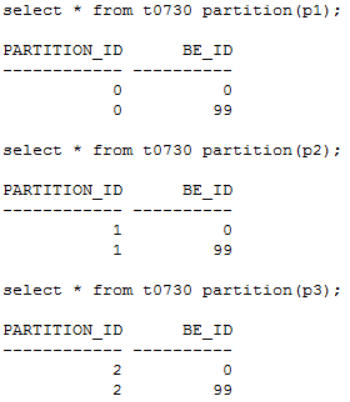
数据库层面的优化不是很多问题的唯一解决途径,我们更希望把问题上升到应用层去解决,数据模型设计阶段的一个好的表设计可以避免很多SQL问题,相反一个不合理的设计可能会引起非常多的SQL问题。我们希望优化可以前置,在表设计阶段就需要考虑的更全面,这样可以避免很多SQL问题,而不是在一个不合理的设计后持续去优化相关SQL。
