




一、背景介绍
知其然,知其所以然。要开发MQToSQL插件,首先我们要知道什么是MQ?MQ的生产者是谁?MQ的消息体格式是什么类型?
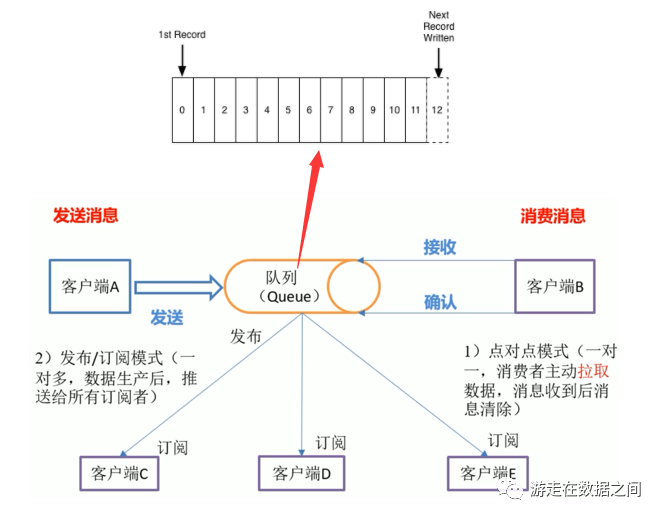
MQ(Message Queue)消息队列,是一种“先进先出”的基础数据结构。一般用来解决应用解耦,异步消息,流量削峰等问题,实现高性能,高可用,可伸缩和最终一致性架构;
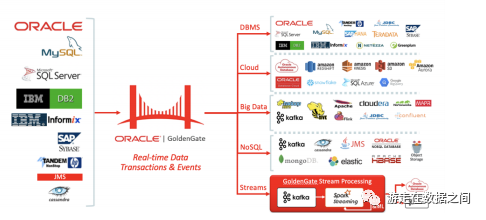
MQ的生产者是Oracle Goldengate For Big Data 12c(OGG实时将事务性数据流式传输到大数据和云系统,而不影响源系统的性能。它将实时数据交付简化为最流行的大数据解决方案,包括Apache Hadoop, Apache HBase, Apache Hive, Confluent Kafka, NoSQL Databases, Elasticsearch, JDBC, Oracle Cloud, Amazon Web Services, Microsoft Azure Cloud, Google Cloud Platform, and Data Warehouses,以提高洞察力和及时行动);
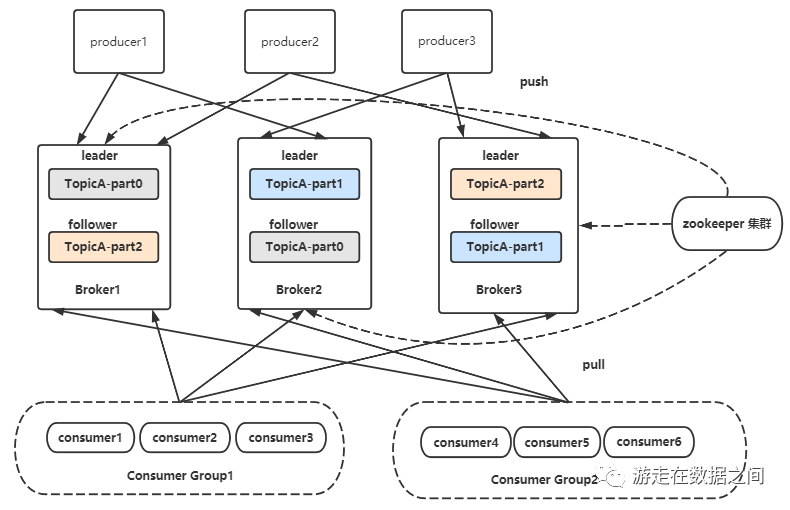
MQ的消息体格式是Json,采用的产品是Apache Kafka(Apache Kafka是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和任务关键型应用程序)。
二、数据结构
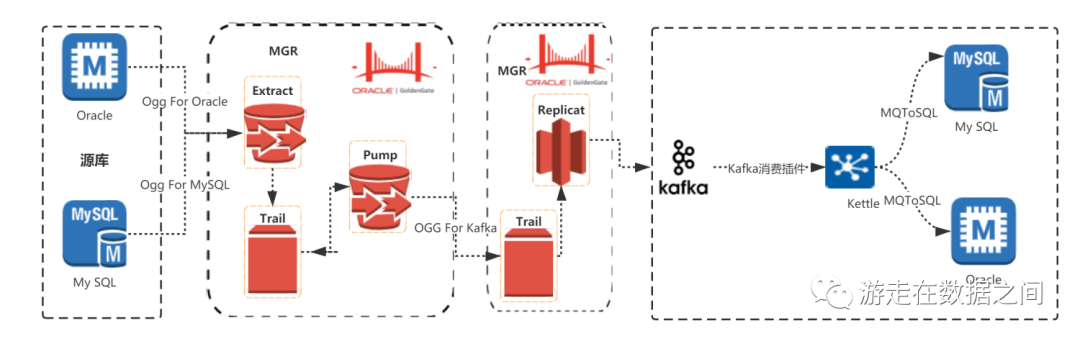
从源端数据库,通过OGG做增量数据捕获,推送增量数据到Kafka
再通过Kettle插件pentaho-kafka-consumer消费消息,获取到增量消息数据流
再通过Kettle插件app-etl-mts(MQToSQL)解析消息数据,根据操作类型及消息字段,动态生成DML语句
把生成后的DML语句,通过kettle插件ExeSqlRow
三、OGG配置
3.1、OGG for MySQL
3.1.1、MySQL数据库准备
A. 开启行模式
数据库必须打开归档模式(OGG重启时需要读取未提交交易开始时的日志)
mysql> show variables like 'binlog_format';+---------------+-------+| Variable_name | Value |+---------------+-------+| binlog_format | ROW |+---------------+-------+1 row in set (0.00 sec)
3.1.2、OGG for MySQL部署
上传软件包到安装目录/u02/ogg/ggs,解压缩安装包,执行GGSCI进入命令行界面,在GGSCI环境下创建GoldenGate子目录
$ cd u01/ogg/ggs$ unzip ***.zip$ ./ggsciGGSCI>create subdirs
该命令会在OGG安装目录下建立若干子目录,其中几个主要目录如下所示:
dirchk:用于存放各个进程的检查点
dirdat:用于存放抽取出来的Trail队列文件
dirprm:用于存放各个进程的参数文件
dirrpt:用于存放各个进程的运行状况报告
dirpcs:存放各个正在运行的进程信息
3.1.3、OGG Trail file
Local Trail file和Remote Trail file全部放置在新建的/u02/ogg/ggs/dirdat下面
3.1.4、OGG MGR配置
--on Source and Target dbGGSCI>edit params mgrPORT 7809AUTOSTART ER *AUTORESTART ER *, RETRIES 12, WAITMINUTES 5, RESETMINUTES 60PURGEOLDEXTRACTS /u02/ogg/ggs/dirdat/*, usecheckpoints, minkeepdays7
OGG同步默认端口号7809,还可以设置如下的动态端口
DYNAMICPORTLIST 7820-7830, 7833, 7835
Manger进程启动时使用AUTOSTART参数自动启动EXTRACT和REPLICAT进程,并使用AUTORESTART参数设置启动失败后的自动重启次数,时间等
--使用PURGEOLDEXTRACTS参数设置过期trail文件执行的删除选项
3.1.5、EXTRACT配置
Extract进程名称定义为:e_******,最大支持8位
Pump进程名称定义为:p_******,最大支持8位
Replicate进程名称定义为:r_******,最大支持8位
On Source DBGGSCI>edit params ekettleextract ekettletranlogoptions altlogdest /home/mysql/mysql/mysql-kettle/mysql-bin.indexsourcedb kettle@127.0.0.1:3306,userid root,password xxxxxxxxxxxexttrail /opt/mysql/ogg/ggs/dirdat/kettle3306/aadynamicresolutiongetUpdateBeforesgettruncatestable test.a;table oggtest.*;
说明:
Altlogdest用来指定binlog的索引文件
Sourcedb用来指定连接的数据源:包括database、IP address和Port,Instance account和password
3.1.6、PUMP配置
On Source DBGGSCI>edit params pkafka02extract pkafka02rmthost 127.0.0.1, mgrport 7809rmttrail /opt/ogg/dirdat/kmpassthrutable oggtest.*;table test.a;
此处使用PASSTHRU参数不检查源数据库和目标数据库的表定义情况
3.1.7、自定义表结构defgen
GGSCI (ogg) 16> edit params defgendefsfile /u02/ogg/ggs/dirdef/defgen.prmsourcedb sourcedb pythondb@127.0.0.1:3306,userid root, password xxxxxxtable pythondb.*;[20:13:20 root@ms01 ~]# cd $GG_HOME[20:13:38 root@ms01 ggs]# ./defgen PARAMFILE ./dirprm/defgen.prm NOEXTATTR
说明:
为防止版本不兼容,可以在自定义表结构时添加NOEXTATTR参数过滤
自定义文件生成后需要复制到目标端指定目录
3.2、OGG for Kafka
3.2.1、REPLICAT配置
--on Target kafkaGGSCI (ellen-m1) 2> view params rkafka02REPLICAT rkafka02TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka2.propsREPORTCOUNT EVERY 1 MINUTES, RATEGROUPTRANSOPS 10000MAP oggtest.oggtest, TARGET myoggtest.oggtest;
--REPLICAT指定源端到目标端之间表的映射关系,建议要同步的表都定义主键
--注意配置环境变量,否则有可能找不到数据库
3.2.2、kafka.props配置
[10:37:08 root@ellen-m1 dirprm]# cat kafka2.propsgg.handlerlist =kafkahandlergg.handler.kafkahandler.type=kafkagg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.propertiesgg.handler.kafkahandler.TopicName=oggtestgg.handler.kafkahandler.format=jsongg.handler.kafkahandler.SchemaTopicName=fafaschemagg.handler.kafkahandler.BlockingSend=truegg.handler.kafkahandler.includeTokens=truegg.handler.name.format.includePrimaryKeys=truegg.handler.name.format.prettyPrintformat.prettyPrint=truegg.handler.hdfs.format.jsonDelimiter=GANgg.handler.name.format.lineDelimiter=||gg.handler.kafkahandler.mode=opgg.handler.kafkahandler.maxGroupSize =100,1Mbgg.handler.kafkahandler.minGroupSize =50,500Kbgg.handler.name.format.pkUpdateHandling=delete-insertgg.handler.name.format.includePosition=truegoldengate.userexit.timestamp=utcgoldengate.userexit.writers=javawriterjavawriter.stats.display=TRUEjavawriter.stats.full=TRUEgg.log=log4jgg.log.level=INFOgg.report.time=30secgg.classpath=/opt/ogg/dirprm/:/opt/soft/kafka_2.12-0.10.2.0/libs/*:/opt/soft/kafka_2.12-0.10.2.0/config/javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=/opt/ogg/ggjava/ggjava.jar
[10:40:28 root@ellen-m1 dirprm]# cat custom_kafka_producer.propertiesbootstrap.servers=192.168.2.1:9092,192.168.2.2:9192,192.168.2.3:9092acks=1reconnect.backoff.ms=1000value.serializer=org.apache.kafka.common.serialization.ByteArraySerializerkey.serializer=org.apache.kafka.common.serialization.ByteArraySerializer100KB per partitionbatch.size=102400linger.ms=10000
Kafka Handler Configuration 的属性 gg.handler.kafkahandler.ProducerRecordClass 里面提到了,默认使用的是oracle.goldengate.handler.kafka.DefaultProducerRecord这个类对表名进行分区的。
如果要自定义的话需要实现CreateProducerRecord这个接口
3.2.3、增量MQ消息
{"table": "oggtest.oggtest","op_type": "U","op_ts": "2021-01-23 15:30:19.357882","current_ts": "2021-01-23T15:30:25.697000","pos": "00000000000000002266","primary_keys": ["ID"],"before": {"ID": 4,"NAME": "test"},"after": {"ID": 4,"NAME": "agileq"}}
四、代码分析
4.1、步骤类
负责处理基础数据流数据,执行Mq To SQL转换
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {meta = (MqToSqlMeta) smi;data = (MqToSqlData) sdi;Object[] r = getRow(); // get row, blocks when needed!if (r == null) // no more input to be expected...{setOutputDone();return false;}RowMetaInterface inputRowMeta = getInputRowMeta();if (first) {first = false;data.outputRowMeta = getInputRowMeta().clone();meta.getFields(data.outputRowMeta, getStepname(), null, null, this);int numErrors = 0;String jsonStr = environmentSubstitute(meta.getJsonStr());if (isEmpty(jsonStr)) {logError(Messages.getString("MqToSqlStep.Log.JsonStrIsNull", jsonStr));numErrors++;}data.jsonStrNr = inputRowMeta.indexOfValue(jsonStr);if (data.jsonStrNr < 0) {logError(Messages.getString("MqToSqlStep.Log.CouldntFindField", jsonStr));numErrors++;}if (!inputRowMeta.getValueMeta(data.jsonStrNr).isBinary()&& !inputRowMeta.getValueMeta(data.jsonStrNr).isString()) {logError(Messages.getString("MqToSqlStep.Log.FieldNotValid", jsonStr));numErrors++;}data.jsonStrMeta = inputRowMeta.getValueMeta(data.jsonStrNr);String tableName = environmentSubstitute(meta.getTableName());if (!isEmpty(tableName)) {logBasic(Messages.getString("MqToSqlStep.Log.TableName", tableName));}String operType = environmentSubstitute(meta.getOperType());if (isEmpty(operType)) {logError(Messages.getString("MqToSqlStep.Log.operTypeIsNull"));numErrors++;}data.operTypeNr = inputRowMeta.indexOfValue(operType);if (data.operTypeNr < 0) {logError(Messages.getString("MqToSqlStep.Log.CouldntFindField", operType));numErrors++;}if (!inputRowMeta.getValueMeta(data.operTypeNr).isBinary()&& !inputRowMeta.getValueMeta(data.operTypeNr).isString()) {logError(Messages.getString("MqToSqlStep.Log.FieldNotValid", operType));numErrors++;}data.operTypeMeta = inputRowMeta.getValueMeta(data.operTypeNr);String jsonDefaultstr = environmentSubstitute(meta.getJsonDefaultStr());if (isEmpty(jsonDefaultstr)) {logError(Messages.getString("MqToSqlStep.Log.JsonDefaultstrIsNull"));numErrors++;}data.jsonDefaultStrNr = inputRowMeta.indexOfValue(jsonDefaultstr);if (data.jsonDefaultStrNr < 0) {logError(Messages.getString("MqToSqlStep.Log.CouldntFindField", jsonDefaultstr));numErrors++;}if (!inputRowMeta.getValueMeta(data.jsonDefaultStrNr).isBinary()&& !inputRowMeta.getValueMeta(data.jsonDefaultStrNr).isString()) {logError(Messages.getString("MqToSqlStep.Log.FieldNotValid", jsonDefaultstr));numErrors++;}data.jsonDefaultStrMeta = inputRowMeta.getValueMeta(data.jsonDefaultStrNr);if (numErrors > 0) {setErrors(numErrors);stopAll();return false;}logBasic("template step initialized successfully");}int jsonStrIndex = getInputRowMeta().indexOfValue(meta.getJsonStr());int operTypeIndex = getInputRowMeta().indexOfValue(meta.getOperType());int jsonDefaultStrIndex = getInputRowMeta().indexOfValue(meta.getJsonDefaultStr());String sbSql = null;try {sbSql = JsonToSqlUtil.jsonToMapSql(r[jsonStrIndex].toString(),data.jsonKeyStrObj, data.jsonValueStrObj,r[operTypeIndex].toString(), meta.getTableName(),r[jsonDefaultStrIndex].toString(), data.primaryKeys);} catch (Exception e) {logError("Failed to process row[" + r[jsonStrIndex].toString() + "].", e);try {throw e;} catch (Exception e1) {e1.printStackTrace();}}Object[] outputRow = RowDataUtil.addValueData(r, data.outputRowMeta.size() - 1, sbSql);putRow(data.outputRowMeta, outputRow);incrementLinesOutput();if (checkFeedback(getLinesRead())) {logBasic("Linenr " + getLinesRead());}return true;}
4.2、plugin配置
<?xml version="1.0" encoding="UTF-8"?><pluginid="MqToSqlPlugin"iconfile="icon.png"description="Mq To Sql"tooltip="Only there for MqToSql purposes"category="游走在数据之间"classname="com.agileq.kettle.mts.plugin.MqToSqlMeta"><libraries><library name="pentaho-kettle-mqtosql-plugin.jar"/><library name="lib/fastjson-1.2.29.jar"/><library name="lib/fel.jar"/><library name="lib/commons-lang3-3.5.jar" /></libraries></plugin>
id:在Kettle插件中必须保证全局唯一
iconfile:Spoon UI中的显示图标,尽量使用png格式图片
description:描述该插件的具体作用
tooltip:树形菜单中,鼠标滑过显示的提示信息
category:插件归属目录
classname:元数据类
libraries:插件依赖Jar包列表
4.3、表达式解析
使用fel表达式解析引擎,来解析配置中需要执行的类型转换和数值聚合操作
public static Object jsonValueFormat(JSONObject jsonObject, String keyObj,Object valueObj) {Object jsonValue = valueObj;String value = jsonObject.getString(keyObj);if (value != null) {if (valueObj instanceof String) {jsonValue = fel.eval(value.replace(keyObj, "'"+ (String) valueObj + "'"));} else {jsonValue = valueObj != null ? fel.eval(value.replace(keyObj,valueObj.toString())) : null;}}return jsonValue;}
4.4、核心代码
根据操作类型、输入字段列表、输出字段列表和增量消息Json等参数,通过核心转换逻辑执行消息的dml语句生成。
/*** json转换成Map,根据操作类型等参数输出要执行的sql语句** @param jsonString* @param jsonKeyString* @param jsonValueString* @param changeOper* @param tableName* @param prmKeyName* @return* @throws JSONException*/public static String jsonToMapSql(String jsonString,JSONObject jsonKeyObject, JSONObject jsonValueObject,String changeOper, String tableName, String jsonDefString,Map<String, String> pramKeys) throws JSONException {JSONObject jsonObject = JSONObject.parseObject(jsonString);Map<String, Object> resultMapSet = new HashMap<String, Object>();Map<String, Object> resultMapWhere = new HashMap<String, Object>();Map<String, Object> resultMapOnDuplicate = new HashMap<String, Object>();String jsonToSql = null;String jsonToSqlWhere = null;String jsonToSqlOnDuplicate = null;if (null != jsonObject) {Iterator<String> iter = jsonObject.keySet().iterator();while (iter.hasNext()) {String key = iter.next();Object value = jsonObject.get(key);// 标准化value输出if (null != jsonValueObject) {value = JsonFormat.jsonValueFormat(jsonValueObject, key,value);}// 标准化key输出if (null != jsonKeyObject) {key = JsonFormat.jsonKeyFormat(jsonKeyObject, key);}if (null != key && !"".equals(key)) {if ("U".equals(changeOper) || "D".equals(changeOper)) {if (isPrimaryKey(pramKeys, key)) {putResultMap(resultMapWhere, key, value);} else {putResultMap(resultMapSet, key, value);}} else {putResultMap(resultMapSet, key, value);if (!isPrimaryKey(pramKeys, key)) {putResultMap(resultMapOnDuplicate, key, value);}}}}jsonToSql = resultMapSet.toString();jsonToSqlOnDuplicate = resultMapOnDuplicate.toString();jsonToSqlWhere = resultMapWhere.toString();jsonToSql = jsonToSql.substring(1, jsonToSql.length() - 1);jsonToSqlOnDuplicate = jsonToSqlOnDuplicate.substring(1,jsonToSqlOnDuplicate.length() - 1);jsonToSqlWhere = jsonToSqlWhere.substring(1,jsonToSqlWhere.length() - 1).replaceAll(",", " and ");}if (null == jsonToSqlWhere || ("").equals(jsonToSqlWhere)) {jsonToSqlWhere = "0=1";}if (("U").equals(changeOper)) {StringBuilder builder = new StringBuilder("update ").append(tableName).append(" set ").append(jsonToSql);if (jsonToSql != null && !jsonToSql.equals("")) {builder.append(", ");}if (jsonDefString != null && !jsonDefString.equals("")) {builder.append(jsonDefString);}jsonToSql = builder.append(" where ").append(jsonToSqlWhere).append(";").toString();} else if (("I").equals(changeOper)) {StringBuilder builder = new StringBuilder("insert into ").append(tableName).append(" set ").append(jsonToSql);if (jsonDefString != null && jsonDefString != "") {builder.append(", ").append(jsonDefString);}builder.append(" on duplicate key update ").append(jsonToSqlOnDuplicate);if (jsonDefString != null && jsonDefString != "") {builder.append(", ").append(jsonDefString);}jsonToSql = builder.append(";").toString();} else if (("D").equals(changeOper)) {jsonToSql = new StringBuilder("delete from ").append(tableName).append(" where ").append(jsonToSqlWhere).append(";").toString();}return jsonToSql;}
五、插件说明
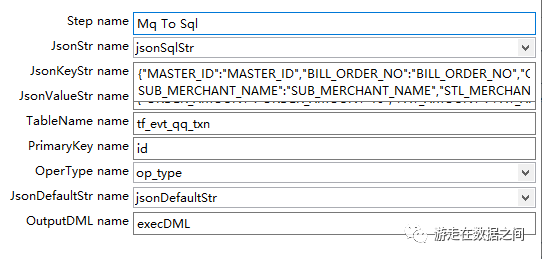
①JsonStr name:动态待解析json字段,从上一步骤数据流动态获取(必选)②JsonKeyStr name:所需Key List列表,此处可做字段名匹配映射(必选)③JsonValueStr name:所需Value List列表,此处可做字段名对应值类型转换和数值做函数运算操作(必选)④TableName name:表名(必选)⑤PrimaryKey name:主键字段,更新必备。分库分表分区键必须配置,多个字段以逗号分隔(必选)⑥OperType name:动态操作类型字段,从上一步骤数据流动态获取(必选)⑦JsonDefaultStr name:默认字段追加,必须更新时追加更新时间、更新人员等(可选)⑧OutputDML name:最终生成的可执行的DML语句(必选)
六、总结
如果你需要源码或者了解更多自定义插件及集成方式,抑或有开发过程或者使用过程中的任何疑问或建议,请关注小编公众号"游走在数据之间",回复2查看源代码,回复3获取入门视频。加入Kettle交流群"话说Kettle"。https://github.com/Jacksn2014/Kettle-Plugin-Master/tree/master
