




DW架构:
1. 请你谈谈 INMON 和 KIMBALL 数据仓库架构的特点
Inmon数据仓库(Data Warehouse) 是一个面向主题的(SubjectOri2ented) 、集成的( Integrate ) 、相对稳定的(Non -Volatile ) 、反映历史变化( TimeVariant) 的数据集合用于支持管理决策。Inmon 的方法包含了更多上述工作而减少了对于信息的初始访问,这个集中式的体系结构持续下去将提供更强的一致性和灵活性,并且从长远来看将真正节省资源和工作。该方案建立数据仓库的速度极慢; Kimball数据仓库理论认为:数据仓库仅仅是构成它的数据集市的联合,可以通过一系列维数相同的数据集市递增地构建数据仓库”。每个数据集市将联合多个数据源来满足特定的业务需求。通过使用“一致的”维,能够共同看到不同数据集市中的信息,这表示它们拥有公共定义的元素,该方法建立数据仓库速度快。
2. 在数据仓库架构中,STAGE AREA 层 作用是什么?
STAGE AREA作用 (1)用来降低与外部数据源之间的偶会度,保证数据仓库系统的外部数据源的稳定性;(2)用于数据仓库中的数据查源。
3. 谈谈你参加过的项目的整体架构和你对这些架构的理解?
4. 什么是缓慢变化维,代理键是什么?
缓慢变化维是指:随着时间的推移存储在数据仓库中的数据值发生变化的而导致数据维度发生变化的现象。代理健是指:没有任何业务含义的用于连接事实表和维度表的键值,通常由维度表中的顺序(序列)分配的整数值组成。
DataStage架构
1. DataStage ADMINISTATOR ,DataStage MANAGER 作用各是什么?
DS ADMINISTRATOR用于工程参数的配置和管理。DS MANAGER用于DS的工程管理,如工程的导入和导出工作等PRJECT的管理工作。
2. 客户端中三个组件的功能
Design :JOB的开发, Director :JOB日志的监控和查看 Manager: JOB的管理 Administrator : JOB变量的配置
3. DataStage 常用架构组成
DS常用架构组成: Design,Director,Manager,Administrator
组件功能
1. DataStage 采用并行处理,这样的好处是什么?
(1)DS 采用并行数据处理的好处在于提高数据的抽取速度 (2)充分利用DS 服务器资源,减少数据抽取消耗的时间。
2. Transformer的常用函数有哪些,举一两个出来说明一下使用方法
常使用的函数 TRIM() 和IF THEN ELSE: IF IsNull(DSLink5.**) THEN SetNull() Else TRIM(DSLink5.**)
3. Transformer的哪些功能可以用哪些Stage来代替(性能调优方面的问题)
过滤功能可以使用FILETER组件来代替, CASE WHEN语句可以用SWITH组件来代替
常用Stage及特性
1. 你常用那些Stage,并简要说说他们的特性
常用组件: FILE 组件 ,数据连接组件,数据处理组件,具体每一类下的各种组建可以通过课件加深了解
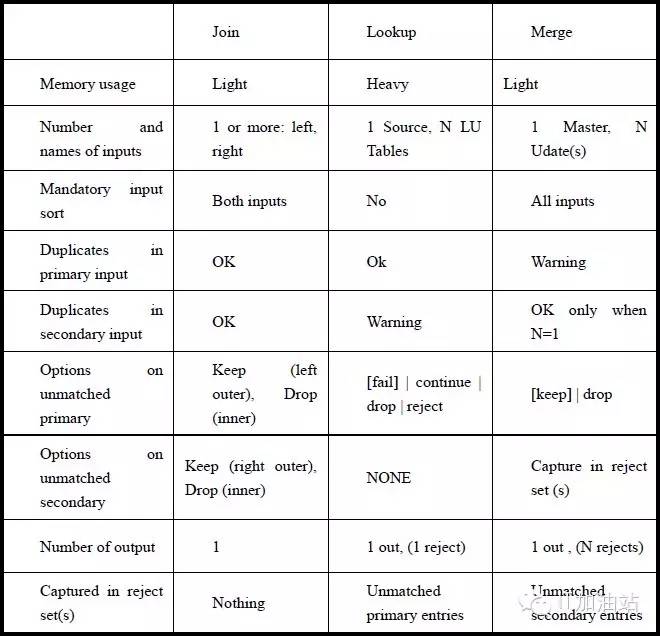
2. MERGE stage,JOIN stage ,LOOKUP stage 的区别是什么?
3. DataStage 默认的数据类型是什么类型
DS中默认的数据类型: ORACLE数据库中的NUMBER为: DECIMAL, VARCHAR2和 VARCHAR为VARCHAR, Data为: TIMESTAMP(38) ,TIMESTAMP为TIMESTAMP(6)
4. UPSET方式中如何选择使用INSERT&UPDATE还是UPDATE&INSERT方式导入数据?
当20%或更大的数据需要更新时应选择UPDATE&INSERT ,低于20%的数据需要进行更新的时候可以选择INSERT&UPDATE方式。
5. Compare,Diifferent Change Capture组件的相同点和不同点
相同点均用于数据比较:Compare指定一个或多个关键字段,用于进行比较,只有选择了的字段才进行比较并确定返回结果,并且需要占用比较大的内存。Different输入结果用于指明输入的差异性是全字段比较,占用较大内存。ChangeCpture设置某个字段为Key Column,设置另一个字段为Value作为比较的依据,结果的展示通过“Properties”中的“Options”设置,因 此结果集合Properties中的Options选择项有关相对Compare占用比较少内存
6. 你常用那些STAGE控件?
常用组件: FILE 组件 ,数据连接组件,数据处理组件,具体每一类下的各种组建可以通过课件加深了解
7. 常用的参数有哪些,用途是什么
常用参数: PROJECT级参数($FILEPATH)在工程内使用, JOB级参数在JOB中使用。
8. Oracle Stage里使用load方式,一般报什么错误
报sqlldr的错误; SQL Load方式通过 Oracle SQL Load来进行插入,因此需要在服务器端安装一个 SQLLOAD工具。
分区原理
1. 在设计数据模型中,你对表分区是怎样考虑的?
(1)表分区的建立是由存储的数据使用的频率决定的; (2) 表分区的建立应该能有利于数据提高数据的查询速率 (3) 在设计表分区的时候应该考虑到表的维护和管理 (4) 表分区的大小要有益于大表操作的性能和大表的数据维护
2. 常用的表分区有哪些?
Oracle 8i有两种类型分区,范围分区(Range Partition)和散列分区(Hash Partition),到Oracle 9i又增加了列表分区(List Partition)和复合分区。
分区的优点:
1. 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快;
2. 减少关闭时间:如果系统故障只影响表的一部分分区,那么只有这部分分区需要修复,故能比整个大表修复花的时间更少;
3. 维护轻松:如果需要重建表,独立管理每个分区比管理单个大表要轻松得多;
4. 均衡I O : 可以把表的不同分区分配到不同的磁盘来平衡I O 改善性能;
5. 增强可用性:如果表的一个分区由于系统故障而不能使用,表的其余好的分区仍然可以使用;
6. 分区对用户透明,最终用户感觉不到分区的存在。
分区表可以创建局部索引和全局索引。当分区中出现许多事务并且要保证所有分区中的数据记录的唯一性时采用全局索引。
数据模型
1.常用的数据模型:星型模型、雪花模型等。
ETL开发
1. Datastage的内部处理机制
DS内部处理机制: 数据抽取和插入均通过与数据库建立SESSION后将JOB的语句翻译成可在数据库内部执行的SQL在数据库中执行,TRANSFORM中使用到的DS函数将通过XLR_C 编译器(C语音编译器)编译成可执行的C代码在DS SERVER中的C编译器中执行。
2. 中间数据落地的处理方式
中间数据落地方式:落地文件(.DS ,.TXT等),临时表,XML数据文件
问题解决
1. 在数据抽取过程中,一张表只有100W和2张 20W的表关联,但是跑了1天数据还没有出来,你是怎样排查问题的,说说你的步骤
PL SQL优化方式。
2. 通过DS如何实现横表和竖表的转换(Transform控件使用IF THEN ELSE)
在JOB中使用Transform控件 ,在该控件中使用IF THEN ELSE这样的语法
3. 使用SQLLOEAD方式导分区表数据的时候会出现大量的临时文件如何解决出现大量临时文件产生的问题?
分区表在进行分区的时候INDEX也会进行分区,因此这样也会导致INDEX也产生大
量临时文件,因此需要在插入前线删除INDEX然后在,插入完成数据的时候在重新建立INDEX(INDEX MODULE选择REBULD,或者使用SHELL 脚本进行该动作
4. 如何在DS中实现条件循环控制?
首先要看是怎样的循环,是等待某种特定标志生成结束或开始循环还是条件式循环,或者为定值循环(如循环10次等)如果是特定标志循环,如生成标志性文件等,则可以使用SEQ中的WAIT FOR FILE组建设置。如果是定值循环则可以通过 CONTRANL JOB代码中编写 FOR语句然后再FOR循环体中使用CALL语句调度JOB实现。
5. 如何通过个字段的值来进行分流,让某个字段符合某些值的数据插入到不同的表中?
6. 如何查看及处理datastage错误
查看错误: DS Director中有详细的JOB错误信息。DS SERVER中也存在大量的JOB LOG文件。
7. 开发过程中使用相关控件时碰到过什么问题,如何解决的?
8. DS是如何连接SQL SERVER数据库的?可能会出现怎么样的错误?
9. DS可以连接那些数据库?通过什么方式去连接?
连接ORALCE通过 ORALCE客户端走TNS,连接DB2和SQL SERVER等通过ODBC进行连接。可能会因为ODBC数据源需要不同的驱动而报错。
10. 并行数据处理和并发数据处理的区别 是什么?怎样设计并行数据处理
并行数据时指在同一时间段内,由多个进程(数据库连接SESSION等)进行数据的处理工作。并发数据指在同一个启动多个线程进行数据的处理工作。设计并行数据处理通常的方法有:DS中使用一个SEQUNCE将JOB设计成并发执行;在PL SQL中在一个脚本运行窗口中运行多个脚本使得多个脚本在同一个时间内执行。
Job Sequence
1. Job Sequence 用来做什么的?
JOB SEQUENCE的作用是将JOB按照一定的依赖关系和业务逻辑串起来使JOB形成一个数据流。
2. JOB SEQUENCE里的Sequencer 控件的ALL和ANY分别代表什么含义
ALL表示所有的组件均运行成功才结束SEQ,ANAY如果有任何一个组件成功运行则停止SEQ
Moia调度器
你了解Moia调度器 吗?如果你了解,说说Moia调度器 的特点
相关ETL技能
1. 你在数据仓库开发中使用的优化工具和方法是什么?
数据仓库开发过程中使用的优化方法有:流程优化,数据库优化,集成开发工具组件优化,作业调度优化;优化工具:PL SQL分析器,流程分析图/表。
2. 并行数据处理和并发数据处理的区别 是什么?怎样设计并行数据处理
并行数据时指在同一时间段内,由多个进程(数据库连接SESSION等)进行数据的处理工作。并发数据指在同一个启动多个线程进行数据的处理工作。设计并行数据处理通常的方法有:DS中使用一个SEQUNCE将JOB设计成并发执行;在PL SQL中在一个脚本运行窗口中运行多个脚本使得多个脚本在同一个时间内执行。
3. 在PL/SQL 中你采用那种编程方式加快数据处理
PLSQL第一步:查看使用SQL分析器进行SQL语句分析查看是否有全表扫描如果有则在对应的表中添加索引避免全表扫描的出现。 步骤二,查看运行过程中是否别的SESSION在执行并且占用了大量的数据库资源,同时查看是否有别的数据库进程占用了同样的表是否有死锁现象产生。 步骤3查看插入过程看看是否使用批量提交数据的方式进行数据提交,并且在数据提交后有无COMMIT动作。
4. 你经常在PL/SQL 开发中使用那些提示?
常用的提示 : 数据分析器提示如: /*+INDEX() */ 强制使用索引 /*+PRALLER() */使用并发 等提示方式。
5. DataStage 常用优化方法,如何提高性能
(1) 在对源数据抽取,目标数据的插入工作时DataStage采用的是PL SQL对源数据进行抽取操作及PL SQL语句对目标数据进行插入操作。因此常使用SQL优化方式对源数据抽取过,及目标数据的插入过程进行优化。
(2) DataStage在数据处理的过程中使用到大量的数据处理STAGE,因此可以对STAGE控件进行优化,常用的控件优化方式:增加空间缓冲大小,尽量避免使用占内存较大的控件如TRANSFORM组件,LOOKUP组件等。
(3) 将DataStage服务器配置成DataStage 服务器集群,使用负载均衡的充分利用服务器资源。
6. 调度原理,并行调度方法介绍
调度原理将DS SERVER配置成不同的NODE节点,使用不同的NODE节点资源运行JOB。并行调度方法: 在SEQ中将JOB设置成并行启动,在MOAI调度器中将JOB设置成使用SERVER集群通过负载均衡来并发执行JOB
7. 如何实现全部依赖或部分依赖的调度?
实现部分依赖和全部依赖的调度可以在DataStage SEQ中的Triggers来客户化定制JOB运行结束或开始的条件来实现。
