示例SQL
mysql> CREATE TABLE `tradelog` (`id` int(11) NOT NULL,`tradeid` varchar(32) DEFAULT NULL,`operator` int(11) DEFAULT NULL,`created_at` datetime DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_tradeid` (`tradeid`),KEY `idx_created_at` (`created_at`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
条件字段函数操作
这个是什么意思呢。举个例子
select * from tradelog where month(created_at) = 7;
假如说 created_at 这个字段上有索引, 于是你就放心的在生产环境执行了这条语句,但是却发现执行很久,才返回结果。
如果说这个时候你问公司的DBA同事,为什么会出现这种情况。他大概会给你说:如果对字段做了函数操作,就用不上索引了,这是MySQL的规定。
这个时候他这么回答肯定是一头雾水的,我想知道是因为什么?
这是因为,B+树提供的这个快速定位的能力,来源于同一层兄弟节点的有序性。如果说索引字段做函数操作的话,可能会破坏掉索引的有序性,导致优化器放弃走搜索树功能,遍历索引树。
所以在索引字段上做函数操作, 会无法使用索引的快速定位功能, 只能全索引扫描,这时你在Extra 中看到的可能是 Using index,表示走了覆盖索引。优化器在这个问题上确实有“偷懒” 的行为,即使对不改变有序性的函数,也不会考虑使用索引。
比如下面这个SQL语句:
select * from tradelog where id + 1 = 100;
这个加1的操作并不会改变有序性,但是MySQL优化器还是不能用id索引来进行快速定位到99这一行。
所以,将SQL改写成 where id = 100 - 1 就可以走索引了。
隐式类型转换
这个情况我感觉会有很多同学应该经历过,看下SQL:
mysql> select * from tradelog where tradeid = 110717;
tardeid 的字段类型为 varchar(32), tradeid字段上是有索引的,但是使用explain 之后查看, 这条语句需要走全表扫描。
此时你可能就会发现,字段类型是varchar,而输入查找的是整型,中间应该做了类型转换。那么问题来了,数据类型转换的规则是什么呢?为什么数据类型转换就不走索引,而是全盘扫描了呢?
规则有一个简单方法,看 select “10” > 9的结果:
1、如果规则是“将字符串转换成为数字”,那么就是做数字比较,结果应该为1;
2、如果规则是“将数字转换成为字符串”,那么就是做字符串比较,结果应该为0。
tips: 字符串比较大小是逐位从高到低比较(ASCII码),那么“10” 中 “1” 的 ASCII码比“9” 的小,所以结果为0。
在MySQL 中, 字符串和数字进行比较的话, 是将字符串转换为数字。
所以看上面的语句,两边要保证统一的数据类型才可以比较。是在索引字段上进行了隐式转换,将隐式转换的语句写出来,你就会神奇的发现,居然和第一种情况一样。
mysql> select * from tradelog where CAST(tradid AS signed int) = 110717;
这也就是说,对索引字段做函数处理,优化器会放弃走树搜索功能。
那如果是主键id的话,会不会导致全表扫描呢?
mysql> select * from tradelog where id="83126";
答案是并不会的, 因为字符串要转换成整型,要转换的字符串并不在索引字段上,所以是会走索引的。如果反过来的话,就不会走索引了。
隐式字符编码转换
这个情况是在我开发一个功能时遇到的问题,由于项目时间久,经过多次“换血”,系统里什么操作都可能会有。表结构大概如下:
mysql> CREATE TABLE `trade_detail` (`id` int(11) NOT NULL,`tradeid` varchar(32) DEFAULT NULL,`trade_step` int(11) DEFAULT NULL, /*操作步骤*/`step_info` varchar(32) DEFAULT NULL, /*步骤信息*/PRIMARY KEY (`id`),KEY `tradeid` (`tradeid`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into tradelog values(1, 'aaaaaaaa', 1000, now());insert into tradelog values(2, 'aaaaaaab', 1000, now());insert into tradelog values(3, 'aaaaaaac', 1000, now());insert into trade_detail values(1, 'aaaaaaaa', 1, 'add');insert into trade_detail values(2, 'aaaaaaaa', 2, 'update');insert into trade_detail values(3, 'aaaaaaaa', 3, 'commit');insert into trade_detail values(4, 'aaaaaaab', 1, 'add');insert into trade_detail values(5, 'aaaaaaab', 2, 'update');insert into trade_detail values(6, 'aaaaaaab', 3, 'update again');insert into trade_detail values(7, 'aaaaaaab', 4, 'commit');insert into trade_detail values(8, 'aaaaaaac', 1, 'add');insert into trade_detail values(9, 'aaaaaaac', 2, 'update');insert into trade_detail values(10, 'aaaaaaac', 3, 'update again');insert into trade_detail values(11, 'aaaaaaac', 4, 'commit');
发现明明有索引的,为什么就是不走索引呢?
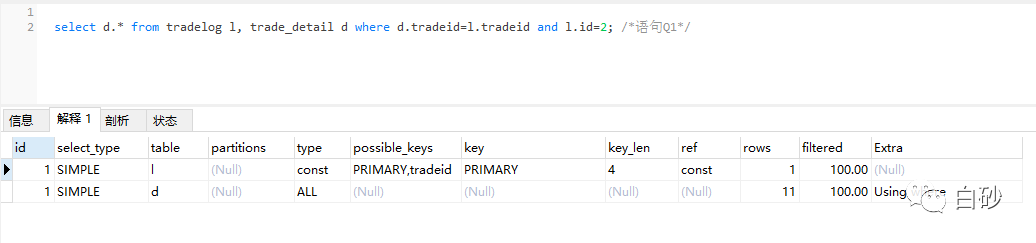
这个时候, 我请教了搜索引擎。由于两张表的字符集不一致,一个是utf8,一个是utf8mb4,所以在进行表连接的时候用不上关联字段索引了。
这里是因为什么用不上索引了呢?
把语句改写一下, 你看下原因就知道了:
SELECT`test`.`d`.`id` AS `id`,`test`.`d`.`tradeid` AS `tradeid`,`test`.`d`.`trade_step` AS `trade_step`,`test`.`d`.`step_info` AS `step_info`FROM`test`.`tradelog` `l`JOIN `test`.`trade_detail` `d`WHERE CONVERT( `test`.`d`.`tradeid` USING utf8mb4) = 'aaaaaaab' ;
这就再次触发了我们上面说到的原则:对索引字段做函数操作,优化器会放弃走树搜索功能。
这个时候需要将转换函数放到右边去或者将两张表的字符集调成一致的就能解决这个问题了。
今天的分享,就到这了,对你有帮助的话,请三连哟~~~
让我知道你在看