





文章转载自公众号:PostgreSQL学徒
作者:熊灿灿
前言
锁在生活中随处可见,电子锁、挂锁、门锁等等。在数据库中,同样也存在着各式各样的锁,表级锁、行级锁、页锁等等,数据库的并发能力除了和它的并发控制机制有关, 还和数据库的锁粒度控制息息相关,粒度越细冲突范围就越小,并发能力就越强。锁的最终目的无外乎是为了保证数据的一致性和完整性。
锁
为了确保复杂的事务可以安全地同时运行,PostgreSQL提供了各种级别的锁来控制对各种数据对象的并发访问,使得对数据库关键部分的更改序列化。事务并发运行,直到它们尝试获取互相冲突的锁为止(比如两个事务更新同一行时)。当多个事务同时在数据库中运行时,并发控制是一种用于维持一致性和隔离性的技术,在PostgreSQL中,使用快照隔离Sanpshot Isolation (简称SI) 来实现多版本并发控制,同时以两阶段锁定 (2PL) 机制为辅。在执行DDL时使用2PL,在执行DML时使用SI。
PostgreSQL uses SSI for DML (Data Manipulation Language, e.g, SELECT, UPDATE, INSERT, DELETE), and 2PL for DDL (Data Definition Language, e.g., CREATE TABLE, etc).
2PL (两阶段锁定)算法是关系数据库系统用来保证数据完整性的最古老的并发控制机制之一。
The 2PL protocol splits a transaction into two sections:
expanding phase (locks are acquired, and no lock is allowed to be released)
shrinking phase (all locks are released, and no other lock can be further acquired).
两阶段的含义是指在同一个事务内,对所涉及的所有数据项进行先加锁,然后才对所有的数据项解锁。但两阶段封锁第一阶段加共享锁后影响了其他事务的写操作、加排它锁后影响了其他事务的读操作 (读受影响更不用提写),所以较大地影响了其他事务的运行 (如果不操作相同数据项则互不影响)。只有第二阶段释放了所有的数据项上的锁之后,才能运行其他要操作相同数据项的事务。
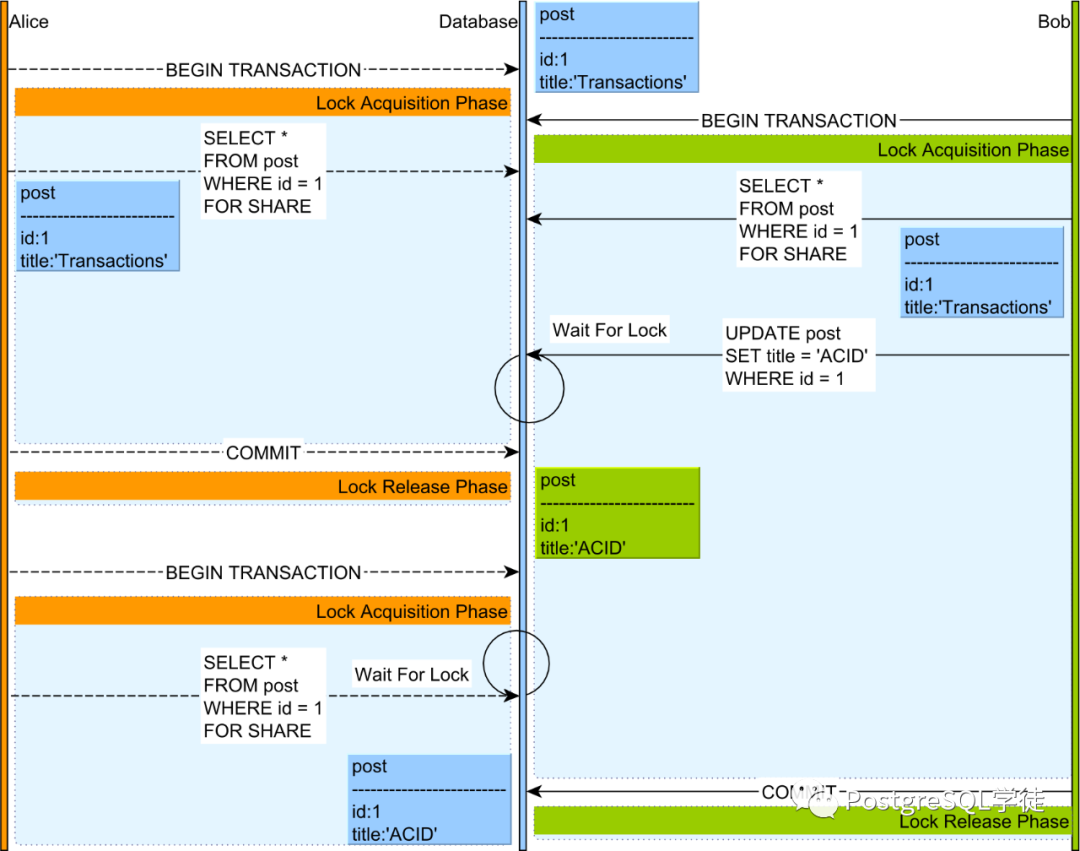
Alice 和 Bob 都通过 SELECT FOR SHARE 的子句获取给定 post 记录的读锁。
当 Bob 尝试在 post 条目上执行 UPDATE 语句时,他的语句会被锁管理器阻塞,因为 UPDATE 语句需要在 post 行上获取写锁,而 Alice 仍然持有对该数据库记录的读锁。
只有当 Alice 的事务结束并且她的所有锁都被释放后,Bob 才能恢复他的 UPDATE 操作。
Bob 的 UPDATE 语句会产生一个锁升级,所以他之前获取的读锁被一个排他锁取代,这将阻止其他事务在同一个 post 记录上获取读或写锁。
Alice 启动一个新事务并发出一个 SELECT FOR SHARE 查询,并为同一个 post 条目发出一个读锁获取请求,但该语句被锁管理器阻止,因为 Bob 拥有该记录的排他锁。
Bob 的事务提交后,他的所有锁都被释放,Alice 的 SELECT 查询可以恢复。
在PostgreSQL中,最主要的是表级锁与行级锁,此外还有页锁、咨询锁和死锁等。
锁根据是否对用户可见可以进一步划分,Regular Locks、Advisory Locks和Dead Locks属于可见的锁,而Spin Lock、LWLock和SIRead属于不可见的锁。
Table-Level Locks
在PostgreSQL中,表级锁分为8种,如下:
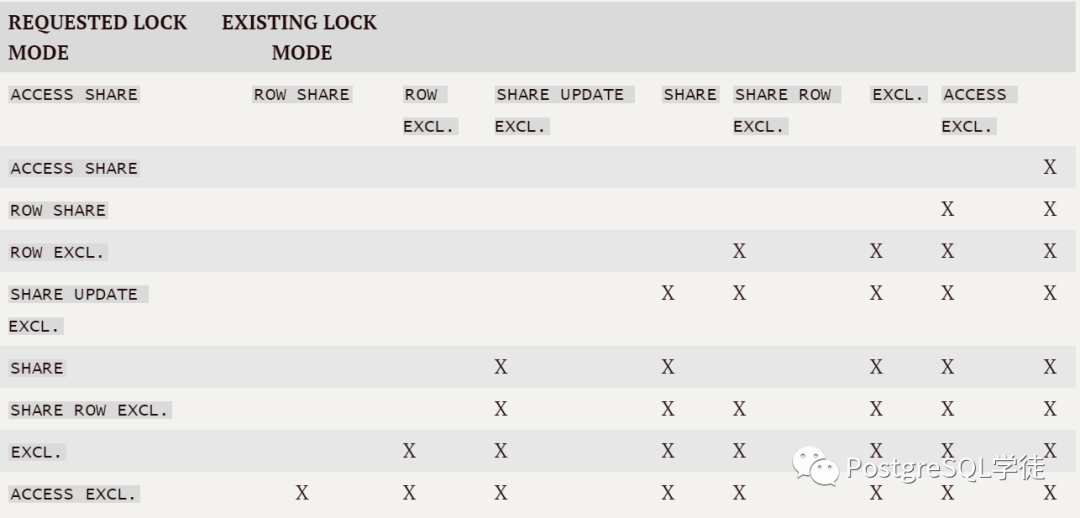
上图不方便理解和记忆,将对应的锁转换成常见的SQL就明了了,如下:

快速记忆法:
ACCESS SHARE和ACCESS EXCLUSIVE可以理解为多版本读/写,SELECT会在查询的表上获取ACCESS SHARE,而那些很硬的操作,诸如TRUNCATE、DROP TABLE等都会获取ACCESS EXCLUSIVE。
ROW SHARE和ROW EXCLUSIVE可以理解为意向读/写锁,意向锁根据名字,就是意向做一件事,但并非实际执行,所以可以看到ROW SHARE和ROW EXCLUSIVE之间互不冲突。当要更新插入时,需要先在对应的表上获取ROW EXCLUSIVE锁。
SHARE和EXCLUSIVE为传统的读写锁,在PostgreSQL中有点变化,EXCLUSIVE锁出现频率很低,SHARE锁用在了创建索引的时候,因为SHARE锁不自斥,所以也就意味着在一张表上可以同时创建多个索引,但是会堵塞插入更新等(和ROW EXCLUSIVE冲突)。
而SHARE UPDATE EXCLUSIVE和SHARE ROW EXCLUSIVE两种锁比较难记忆,SHARE UPDATE EXCLUSIVE在VACUUM和ALTER TABLE SET(XXX)等操作时会获取,因为SHARE UPDATE EXCLUSIVE是自斥的,所以目前PostgreSQL无法做到表级的并行VACUUM,但可以做到库级的并行VACUUM(好消息是,在刚刚发布不久的POSTGRESQL13中,对索引的清理支持并行了);SHARE ROW EXCLUSIVE出现的概率较低,一般常见的是创建触发器。
Row-Level Locks
表级锁存在于PostgreSQL的shared buffers中,所以可以很直观的通过pg_locks查看。但是行级锁不一样,PostgreSQL不会将已获得的行级锁信息存储在内存中,如果在pg_locks中查看到了行锁信息,并不代表行锁信息存储在内存中,这种情况往往出现在行锁等待,比如后文会介绍的“tuple锁”,行锁通常只在tuple的header中设置标记位来标识此行记录已经被锁。这两个关键的标记为xmax和infomask(HEAP_UPDATED)。xmax放置当前事务的xid,infomask放置标记位,可能还有HOT
postgres=# create table test_lock(id int primary key,info text);CREATE TABLEpostgres=# insert into test_lock values(1,'test1'),(2,'test2');INSERT 0 2
会话1
postgres=# begin;BEGINpostgres=*# select pg_backend_pid(),txid_current();pg_backend_pid | txid_current ----------------+-------------- 19138 | 14635(1 row)postgres=*# update test_lock set info = 'mytest_lock' where id = 1;UPDATE 1
会话2
postgres=# begin;BEGINpostgres=*# select txid_current(),pg_backend_pid();txid_current | pg_backend_pid --------------+---------------- 14636 | 19140(1 row)postgres=*# update test_lock set id = 100 where id = 1;此处夯住
通过pageinspect查看,这里就很清晰了,老的tuple的xmax存放了14635事务ID,infomask2变成了HEAP_ONLY_TUPLE,表示是使用的HOT更新的,注意观察Tuple3的infomask,是UPDATED,代表是更新的行
postgres=# select lp,lp_off,t_xmin,t_xmax,t_ctid,t_infomask2,t_infomask,infomask(t_infomask, 1) as infomask,infomask(t_infomask2, 2) as infomask2 from heap_page_items(get_raw_page('test_lock',0));lp | lp_off | t_xmin | t_xmax | t_ctid | t_infomask2 | t_infomask | infomask | infomask2 ----+--------+--------+--------+--------+-------------+------------+-----------------------------------------+----------------- 1 | 8152 | 14634 | 14635 | (0,3) | 16386 | 258 | XMIN_COMMITTED|HASVARWIDTH | HOT_UPDATED 2 | 8112 | 14634 | 0 | (0,2) | 2 | 2306 | XMAX_INVALID|XMIN_COMMITTED|HASVARWIDTH | 3 | 8072 | 14635 | 0 | (0,3) | 32770 | 10242 | UPDATED|XMAX_INVALID|HASVARWIDTH | HEAP_ONLY_TUPLE(3 rows)
那么既然xmax还要当行锁,怎么判断这个xmax到底是行锁还是来判断可见性呢?还是老样子t_infomask这个标志位登场!
#define HEAP_XMAX_EXCL_LOCK0x0040/* xmax is exclusive locker */#define HEAP_XMAX_LOCK_ONLY0x0080/* xmax, if valid, is only a locker */
postgres=# create table test_lock(id int,info text);CREATE TABLEpostgres=# insert into test_lock values(1,'test1');INSERT 0 1postgres=# insert into test_lock values(2,'test2');INSERT 0 1postgres=# begin;BEGINpostgres=*# select txid_current(),pg_backend_pid();txid_current | pg_backend_pid --------------+---------------- 14653 | 19442(1 row)postgres=*# select * from test_lock where id = 1 for update;id | info ----+------- 1 | test1(1 row)postgres=*# SELECT '(0,'||lp||')' AS ctid,postgres-*# CASE lp_flagspostgres-*# WHEN 0 THEN 'unused'postgres-*# WHEN 1 THEN 'normal'postgres-*# WHEN 2 THEN 'redirect to '||lp_offpostgres-*# WHEN 3 THEN 'dead'postgres-*# END AS state,postgres-*# t_xmin as xmin,postgres-*# t_xmax as xmax,postgres-*# (t_infomask & 64) > 0 AS HEAP_XMAX_EXCL_LOCK,postgres-*# (t_infomask & 128) > 0 AS HEAP_XMAX_LOCK_ONLY,postgres-*# (t_infomask & 256) > 0 AS xmin_commited,postgres-*# (t_infomask & 512) > 0 AS xmin_aborted,postgres-*# (t_infomask & 1024) > 0 AS xmax_commited,postgres-*# (t_infomask & 2048) > 0 AS xmax_aborted,postgres-*# t_ctidpostgres-*# FROM heap_page_items(get_raw_page('test_lock',0));ctid | state | xmin | xmax | heap_xmax_excl_lock | heap_xmax_lock_only | xmin_commited | xmin_aborted | xmax_commited | xmax_aborted | t_ctid -------+--------+-------+-------+---------------------+---------------------+---------------+--------------+---------------+--------------+--------(0,1) | normal | 14651 | 14653 | t | t | t | f | f | f | (0,1)(0,2) | normal | 14652 | 0 | f | f | t | f | f | t | (0,2)(2 rows)postgres=*# select xmin,xmax from test_lock ;xmin | xmax -------+-------14651 | 1465314652 | 0(2 rows)
可以看到,heap_xmax_lock_only列为true,且xmax列为14653这个事务。
假设每个行锁都在内存有一条记录的话,全表更新时,表有多少行,就在内存中有多少条行锁信息,那么内存会吃不消。设置infomask的目的是为了与正常的dead tuple区别开来,xmax是用来标识被删除的记录。基于这点,理论上一次可以锁定的行数没有限制。另外这里可以衍生出一个经典PG系面试题,select是否会产生写?除了较为熟知的设置标志位(后面的DML或者DQL,VACUUM等SQL扫描到对应的TUPLE时,会触发对前面扫描到的行set bits的操作),还有这里的行级锁也会有写IO。当然,行级锁也并非不能观察,可以通过pgrowlocks和pageinspect插件来观察。
行级锁的冲突矩阵如下:
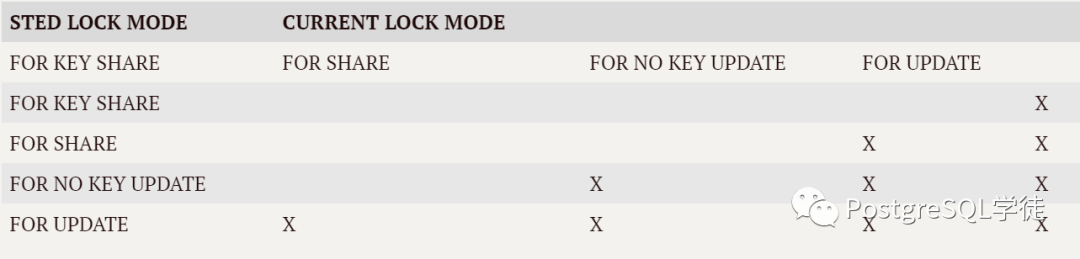
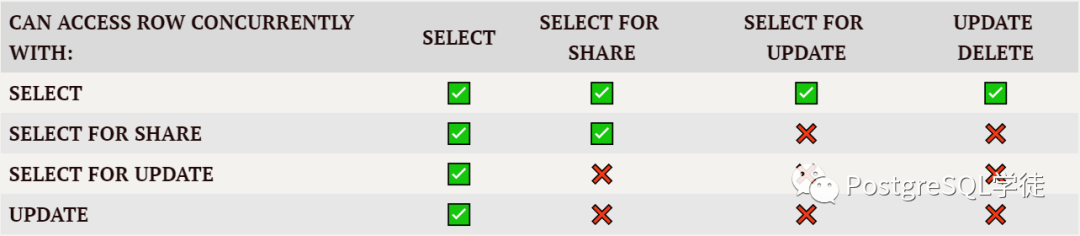
FOR UPDATE:对整行进行更新,包括删除行
FOR NO KEY UPDATE:对除主(唯一)键外的字段更新
FOR SHARE:读该行,不允许对行进行更新
FOR KEY SHARE:读该行的键值,但允许对除键外的其他字段更新。在外键检查时使用该锁
Page-Level Locks
PostgreSQL中,有对于表的数据页的共享/互斥锁,一旦这些行读取或者更改完成后,相应的页锁就被释放。比较常见的有:
WalInsertLock,wal buffer是固定大小的,向wal buffer中写wal record需要竞争的锁,如果把synchronous_commit关闭,这个锁的竞争会更加激烈;
WALWriteLock:一般都是同步提交,要保证commit时,wal是刷盘的,那么刷盘就会竞争这个锁。将页面写入磁盘会受WALWriteLock锁保护,一次只能有一个进程可以执行此操作。
ProcArrayLock,对于每一个连接,在shared buffer中都有一个结构体PGPROC用于追踪正在运行的后端进程和事务,每个backend在事务在commit或abort时,都要对其PGPROC和PGXACT中关于事务状态的属性进行设置,标记对应的事务不再运行。

一般不怎么需要关心页锁,但是假如在pg_stat_activity视图里面看到了大量相关的等待事件,也需要特别注意。比如出现了大量的BufferMapping,说明buffer发生了频繁替换导致了锁等待,可能存在大量表扫描,buffer太小了或io存在瓶颈、磁盘太烂了等原因。
目前PostgreSQL13.3定义了这么多LWLock:
/* autogenerated from src/backend/storage/lmgr/lwlocknames.txt, do not edit *//* there is deliberately not an #ifndef LWLOCKNAMES_H here */#define ShmemIndexLock (&MainLWLockArray[1].lock) //共享内存锁#define OidGenLock (&MainLWLockArray[2].lock)//生成Oid的值的锁#define XidGenLock (&MainLWLockArray[3].lock)//生成Xid(事务号)的值的锁#define ProcArrayLock (&MainLWLockArray[4].lock)///进程锁(PostgreSQL是多进程体系结构,用于进程间互斥),在9.6中对PROCARRAY锁竞争优化,每个backend在事务在commit/abort时,都要对其PGPROC和PGXACT中关于事务状态的属性进行设置,标记对应的事务不再运行,此时需要对ProcArray加一把LWLock排他锁进行保护#define SInvalReadLock (&MainLWLockArray[5].lock)//共享cache的读锁(SI: shared cache invalidation data manager)#define SInvalWriteLock (&MainLWLockArray[6].lock)//共享cache的写锁#define WALBufMappingLock (&MainLWLockArray[7].lock)//预先日志(WAL)缓存区锁,把数据写入缓存区#define WALWriteLock (&MainLWLockArray[8].lock)//预先日志(WAL)写锁,把数据从缓存区刷出到持久化存储#define ControlFileLock (&MainLWLockArray[9].lock)//控制文件锁#define CheckpointLock (&MainLWLockArray[10].lock)//CheckPoint锁,用于创建CheckPoint#define XactSLRULock (&MainLWLockArray[11].lock)//事务日志(CLog)锁#define SubtransSLRULock (&MainLWLockArray[12].lock)//子事务锁#define MultiXactGenLock (&MainLWLockArray[13].lock)//多事务生成锁#define MultiXactOffsetSLRULock (&MainLWLockArray[14].lock)//多事务偏移控制锁#define MultiXactMemberSLRULock (&MainLWLockArray[15].lock)//多事务成员控制锁#define RelCacheInitLock (&MainLWLockArray[16].lock)//RelationCache初始化锁#define CheckpointerCommLock (&MainLWLockArray[17].lock)//CheckPoint常规锁,用于创建CheckPoint之外的CheckPoint操作#define TwoPhaseStateLock (&MainLWLockArray[18].lock)//2阶段提交状态锁,用于分布式事务#define TablespaceCreateLock (&MainLWLockArray[19].lock)//创建、删除表空间时以排他模式加的锁#define BtreeVacuumLock (&MainLWLockArray[20].lock) //在BTree上执行Vacuum操作清理无用元组时加的锁#define AddinShmemInitLock (&MainLWLockArray[21].lock)//共享内存初始化锁#define AutovacuumLock (&MainLWLockArray[22].lock)//自动执行Vacuum的进程执行操作时的锁#define AutovacuumScheduleLock (&MainLWLockArray[23].lock)//自动执行Vacuum的进程执行do_autovacuu()函数时的锁#define SyncScanLock (&MainLWLockArray[24].lock) //....#define RelationMappingLock (&MainLWLockArray[25].lock) //....#define NotifySLRULock (&MainLWLockArray[26].lock)#define NotifyQueueLock (&MainLWLockArray[27].lock)#define SerializableXactHashLock (&MainLWLockArray[28].lock)#define SerializableFinishedListLock (&MainLWLockArray[29].lock)#define SerializablePredicateListLock (&MainLWLockArray[30].lock)#define SerialSLRULock (&MainLWLockArray[31].lock)#define SyncRepLock (&MainLWLockArray[32].lock)#define BackgroundWorkerLock (&MainLWLockArray[33].lock)#define DynamicSharedMemoryControlLock (&MainLWLockArray[34].lock)#define AutoFileLock (&MainLWLockArray[35].lock)#define ReplicationSlotAllocationLock (&MainLWLockArray[36].lock)#define ReplicationSlotControlLock (&MainLWLockArray[37].lock)#define CommitTsSLRULock (&MainLWLockArray[38].lock)#define CommitTsLock (&MainLWLockArray[39].lock)#define ReplicationOriginLock (&MainLWLockArray[40].lock)#define MultiXactTruncationLock (&MainLWLockArray[41].lock)#define OldSnapshotTimeMapLock (&MainLWLockArray[42].lock)#define LogicalRepWorkerLock (&MainLWLockArray[43].lock)#define XactTruncationLock (&MainLWLockArray[44].lock)#define WrapLimitsVacuumLock (&MainLWLockArray[46].lock)#define NotifyQueueTailLock (&MainLWLockArray[47].lock)#define NUM_INDIVIDUAL_LWLOCKS48
Spin Lock
编程中常听说的自旋锁,PostgreSQL中同样也有,SpinLock主要用于对于临界变量的并发访问控制,所保护的临界区通常是简单的赋值语句,读取语句等。另外,自旋锁的显著特点就是死等,占着茅坑不拉屎,SpinLock没有等待队列、死锁检测机制,在事务结束之后不会自动释放,需要每次显式释放。在PostgreSQL中,使用CPU指令集test-and-set或者信号量来实现自旋锁。
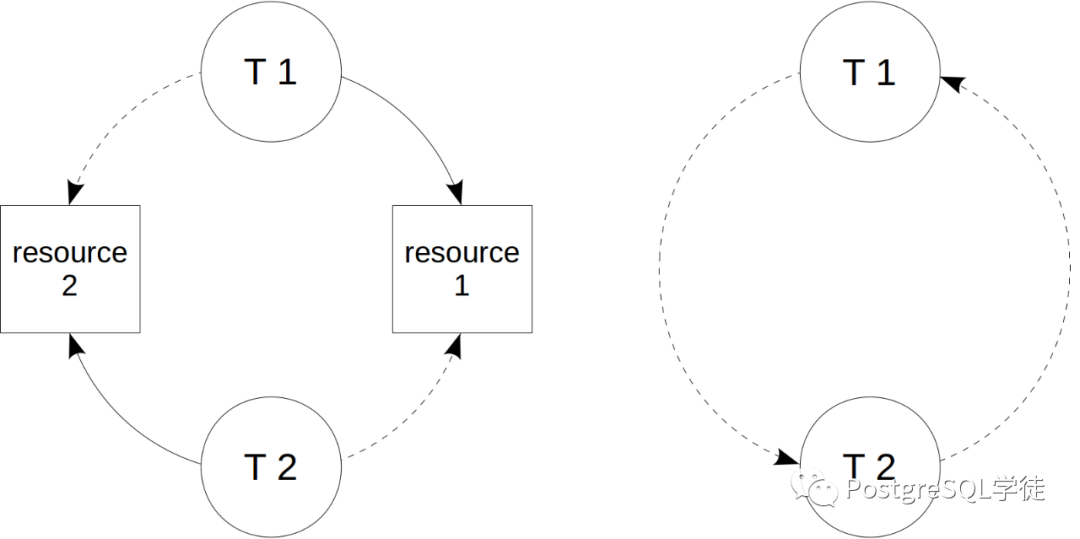
Deadlocks
死锁在各大主流数据库中都有,当一个事务试图获取另一个事务已在使用的资源,而第二个事务又试图获取第一个事务在使用的资源时,就会发生死锁,在PostgreSQL中,有lock_timeout、deadlock_timeout、log_lock_waits(日志记录)等参数控制。死锁检测是一件十分耗费资源的事情,大多数时候,一旦检测到死锁,则其中一个事务(大多数情况下是发起检查的事务)将被迫中止。
advisory Locks
当MVCC模型和锁策略不符合应用时,采用咨询锁。PostgreSQL允许用户创建咨询锁,该锁与数据库本身没有关系,比如多个进程访问同一个数据库时,如果想协调这些进程对一些非数据库资源的并发访问,就可以使用咨询锁。咨询锁是提供给应用层显示调用的锁方法,在表中存储一个标记位能够实现同样的功能,但是咨询锁更快;并且避免表膨胀,且会话(或事务)结束后能够被自动清理。
Once acquired at session level, an advisory lock is held until explicitly released or the session ends. Unlike standard lock requests, session-level advisory lock requests do not honor transaction semantics: a lock acquired during a transaction that is later rolled back will still be held following the rollback, and likewise an unlock is effective even if the calling transaction fails later. A lock can be acquired multiple times by its owning process; for each completed lock request there must be a corresponding unlock request before the lock is actually released.
Transaction-level lock requests, on the other hand, behave more like regular lock requests: they are automatically released at the end of the transaction, and there is no explicit unlock operation. This behavior is often more convenient than the session-level behavior for short-term usage of an advisory lock.
以下内容引自德哥:
某些业务会利用数据库来作为一种可靠的锁,例如任务调度系统,或者其他需要可靠的锁机制的系统。通常他们可能会使用数据库的一条记录来实现锁的SLOT和状态信息。比如:
create table lock_test ( tid int primary key, -- 任务ID state int default 1, -- 任务状态,1表示初始状态,-1表示正在处理, 0表示处理结束 retry int default -1, -- 重试次数 info text, -- 其他信息 crt_time timestamp -- 时间 );
任务处理系统到数据库获取任务,例如
update lock_test set state=-1 , retry=retry+1 where tid=? and state=1;
处理失败
update lock_test set state=1 where tid=? and state=-1;
处理成功
update lock_test set state=0 where tid=? and state=-1;
当多个客户端并行获得同一个任务时,就会引发冲突,导致等待(虽然等待时间可能不长,但是在大型任务调度系统中,一点点的等待都无法忍受)。如何解决这个冲突等待呢?advisory lock登场,实际上在秒杀业务中我们也看到了它的踪影。
像我们熟知的redis中的setnx和del实现了分布式锁。
SQL改造如下:
开始处理任务
update lock_test set state=-1 , retry=retry+1 where tid=? and state=1 and pg_try_advisory_xact_lock(?) returning *;
处理失败
update lock_test set state=1 where tid=? and state=-1 and pg_try_advisory_xact_lock(?);
处理成功
update lock_test set state=0 where tid=? and state=-1 and pg_try_advisory_xact_lock(?);
Here are some of the provided functions for session level locks:
pg_advisory_lock(key bigint) obtains exclusive session level advisory lock. If another session already holds a lock on the same resource identifier, this function will wait until the resource becomes available. Multiple lock requests stack, so that if the resource is locked three times it must then be unlocked three times.
pg_try_advisory_lock(key bigint) obtains exclusive session level advisory lock if available. It's similar to pg_advisory_lock, except it will not wait for the lock to become available - it will either obtain the lock and return true, or return false if the lock cannot be acquired immediately.
pg_advisory_unlock(key bigint) releases an exclusive session level advisory lock.
And here are some for transaction level locks:
pg_advisory_xact_lock(key bigint) obtains exclusive transaction level advisory lock. It works the same as pg_advisory_lock, except the lock is automatically released at the end of the current transaction and cannot be released explicitly.
pg_try_advisory_xact_lock(key bigint) obtains exclusive transaction level advisory lock if available. It works the same as pg_try_advisory_lock, except the lock is automatically released at the end of the transaction and cannot be released explicitly.
性能压测对比
为了体现冲突的问题,我们使用一条记录来表示一个任务,大家都来抢一个任务的极端场景。
create table lock_test ( tid int primary key, -- 任务ID state int default 1, -- 任务状态,1表示初始状态,-1表示正在处理, 0表示处理结束 retry int default -1, -- 重试次数 info text, -- 其他信息 crt_time timestamp -- 时间 ); insert into lock_test values (1, 1, -1, 'test', now());
传统模式压测
vi test1.sql update lock_test set state=-1 , retry=retry+1 where tid=1 and state=1; update lock_test set state=1 where tid=1 and state=-1; pgbench -M prepared -n -r -P 1 -f ./test1.sql -c 64 -j 64 -T 120 query mode: prepared number of clients: 64 number of threads: 64 duration: 120 s number of transactions actually processed: 966106 latency average = 7.940 ms latency stddev = 6.840 ms tps = 8050.081170 (including connections establishing) tps = 8054.812052 (excluding connections establishing) script statistics: - statement latencies in milliseconds: 3.978 update lock_test set state=-1 , retry=retry+1 where tid=1 and state=1; 3.962 update lock_test set state=1 where tid=1 and state=-1;
advisory lock模式压测
vi test2.sql update lock_test set state=-1 , retry=retry+1 where tid=1 and state=1 and pg_try_advisory_xact_lock(1) returning *; update lock_test set state=1 where tid=1 and state=-1 and pg_try_advisory_xact_lock(1); pgbench -M prepared -n -r -P 1 -f ./test2.sql -c 64 -j 64 -T 120 query mode: prepared number of clients: 64 number of threads: 64 duration: 120 s number of transactions actually processed: 23984594 latency average = 0.320 ms latency stddev = 0.274 ms tps = 199855.983575 (including connections establishing) tps = 199962.502494 (excluding connections establishing) script statistics: - statement latencies in milliseconds: 0.163 update lock_test set state=-1 , retry=retry+1 where tid=1 and state=1 and pg_try_advisory_xact_lock(1) returning *; 0.156 update lock_test set state=1 where tid=1 and state=-1 and pg_try_advisory_xact_lock(1);
8000 TPS提升到20万 TPS
实战
首先创建一张test_lock的测试表:
postgres=# create table test_lock(id int primary key,info text);CREATE TABLEpostgres=# insert into test_lock values(1,'test1'),(2,'test2');INSERT 0 2postgres=# begin;BEGINpostgres=*# select pg_backend_pid(),txid_current();pg_backend_pid | txid_current ----------------+-------------- 18846 | 14609(1 row)postgres=*# update test_lock set info = 'mytest_lock' where id = 1;UPDATE 1
此处未提交,同时再开启一个会话,进行更新
postgres=# begin;BEGINpostgres=*# select pg_backend_pid(),txid_current();pg_backend_pid | txid_current ----------------+-------------- 18896 | 14610(1 row)postgres=*# update test_lock set info = 'mytest_lock2' where id = 1;此处夯住
再开一个进程查看锁
postgres=# select pid,pg_blocking_pids(pid) as blocked,state,query,wait_event,wait_event_type from pg_stat_activity where query like '%update%' and pid <> pg_backend_pid();pid | blocked | state | query | wait_event | wait_event_type -------+---------+---------------------+----------------------------------------------------------+---------------+-----------------18846 | {} | idle in transaction | update test_lock set info = 'mytest_lock' where id = 1; | ClientRead | Client18896 | {18846} | active | update test_lock set info = 'mytest_lock2' where id = 1; | transactionid | Lock(2 rows)
通过pg_stat_activity视图可以看到,18896这个进程被18846阻塞住,18846进程处于idle in transaction的状态,也就是还未提交,18896进程正在等待某一个事务结束。pg_stat_activity视图可以看一个大概,具体锁信息还需要结合pg_locks查看,SQL如下:
select relation::regclass as relname,locktype,'('||page||','||tuple||')' as ctid,transactionid,virtualtransaction,virtualxid,pid,mode,granted from pg_locks where pid in (18896,18846) order by pid;
postgres=# select relation::regclass as relname,locktype,'('||page||','||tuple||')' as ctid,transactionid,virtualtransaction,virtualxid,pid,mode,granted from pg_locks where pid in (18896,18846) order by pid; relname | locktype | ctid | transactionid | virtualtransaction | virtualxid | pid | mode | granted ----------------+---------------+-------+---------------+--------------------+------------+-------+------------------+--------- | virtualxid | | | 3/26911 | 3/26911 | 18846 | ExclusiveLock | ttest_lock | relation | | | 3/26911 | | 18846 | RowExclusiveLock | t | transactionid | | 14609 | 3/26911 | | 18846 | ExclusiveLock | ttest_lock_pkey | relation | | | 3/26911 | | 18846 | RowExclusiveLock | ttest_lock | tuple | (0,1) | | 4/1443 | | 18896 | ExclusiveLock | t | transactionid | | 14610 | 4/1443 | | 18896 | ExclusiveLock | t | transactionid | | 14609 | 4/1443 | | 18896 | ShareLock | ftest_lock_pkey | relation | | | 4/1443 | | 18896 | RowExclusiveLock | ttest_lock | relation | | | 4/1443 | | 18896 | RowExclusiveLock | t | virtualxid | | | 4/1443 | 4/1443 | 18896 | ExclusiveLock | t(10 rows)
可以看到,18846这个进程持有两个ExclusiveLock,分别是事务ID和虚拟事务ID,virtualxid是虚拟事务ID,每产生一个事务ID,都会在commit log(CLOG)文件中占用2bit。但有些事务没有产生任何实质的变更,比如只读事务或空事务,这样给它们也分配一个事务ID就很浪费。因此对这类没有实质变更的事务只分配虚拟事务ID,比如查询。另外也可以防止事务ID快速回卷(大约每满21亿就会发生回卷)。
在整个事务运行过程中,服务器进程对虚拟事务ID持有排他锁。如果分配了永久性事务ID,它还将对永久性事务ID持有排他锁,直到结束。所以印证了上面的说法。同时18846这个进程对test_lock表加上了RowExclusiveLock,这个仍然是表级锁。当18846进程想要修改表上的某一行时,会在这一行上加上行级锁。但在加行级锁之前,还需要先在这张表上加上一把意向锁,表示自己将会在表中的若干行上加锁,这样其他事务来了就可以知道,表上还有意向锁,说明已经有某些行上持有了锁。因此,RowExclusiveLock是行级锁(对应级别低的资源)的上面资源的锁(对应级别高的资源,此处为表),换言之,给表加上了RowExclusiveLock也就意味着自己准备在表内的某些行上加锁。
18896这个进程,同样可以看到持有两个RowExclusiveLock锁,因为还涉及到了主键索引;同时也对事务ID和虚拟ID持有ExclusiveLock,当某个进程发现需要等待另一笔事务结束时,它还会通过尝试获取另一笔事务ID (可能是虚拟ID也可能是永久事务ID)上的共享锁 -> share锁。仅当另一个事务终止并释放锁时,该操作才会成功。所以此处可以看到,18896进程在申请14609事务的共享锁,由于18846进程已经持有对14609事务的ExclusiveLock,所以会阻塞住。其实换个角度思考也不难理解,因为第一个14609事务对test_lock表进行了更改,但未提交,所以也就可能提交也可能回滚,然后14610事务也需要对表的同一行进行更改,并且依赖于14609事务的“结果”,所以会等待14609事务。
而看到的locktype = tuple的这一行,注意不要和行级锁混淆,此处的tuple代表tuple锁,tuple锁可以保证多个修改事务加锁的顺序问题,原则是先来先拿锁,修改完tuple后,tuple锁会立即释放,而事务锁不会释放。所以并未看到18846进程的tuple锁,原因是更改成功并立即释放了。假设有3个事务,A、B、C依次对同一行修改,均未提交。那么这个时候,A处于idle in transaction状态,B持有tuple锁但是等待A的事务锁,C等待B持有的tuple锁。
再开一个会话,更新同一行
postgres=# begin;BEGINpostgres=*# select pg_backend_pid(),txid_current();pg_backend_pid | txid_current ----------------+-------------- 19049 | 14611(1 row)postgres=*# update test_lock set info = 'mytest_lock' where id = 1;此处夯住
可以看到,新来的19049进程被18896阻塞,18896进程被18846阻塞,位于一个锁队列中,同时可以看到19049进程在等待给tuple加锁,但18896进程已经持有了tuple锁,但在等待18846进程的事务锁。
postgres=# begin;postgres=# select pid,pg_blocking_pids(pid) as blocked,state,query,wait_event,wait_event_type from pg_stat_activity where query like '%update%' and pid <> pg_backend_pid();pid | blocked | state | query | wait_event | wait_event_type -------+---------+---------------------+----------------------------------------------------------+---------------+-----------------18846 | {} | idle in transaction | update test_lock set info = 'mytest_lock' where id = 1; | ClientRead | Client18896 | {18846} | active | update test_lock set info = 'mytest_lock2' where id = 1; | transactionid | Lock19049 | {18896} | active | update test_lock set info = 'mytest_lock' where id = 1; | tuple | Lock(3 rows)postgres=# select relation::regclass as relname,locktype,'('||page||','||tuple||')' as ctid,transactionid,virtualtransaction,virtualxid,pid,mode,granted from pg_locks where pid in (18896,18846,19049) order by pid; relname | locktype | ctid | transactionid | virtualtransaction | virtualxid | pid | mode | granted ----------------+---------------+-------+---------------+--------------------+------------+-------+------------------+---------test_lock | relation | | | 3/26911 | | 18846 | RowExclusiveLock | t | transactionid | | 14609 | 3/26911 | | 18846 | ExclusiveLock | t | virtualxid | | | 3/26911 | 3/26911 | 18846 | ExclusiveLock | ttest_lock_pkey | relation | | | 3/26911 | | 18846 | RowExclusiveLock | t | transactionid | | 14609 | 4/1443 | | 18896 | ShareLock | ftest_lock_pkey | relation | | | 4/1443 | | 18896 | RowExclusiveLock | ttest_lock | relation | | | 4/1443 | | 18896 | RowExclusiveLock | t | virtualxid | | | 4/1443 | 4/1443 | 18896 | ExclusiveLock | ttest_lock | tuple | (0,1) | | 4/1443 | | 18896 | ExclusiveLock | | transactionid | | 14610 | 4/1443 | | 18896 | ExclusiveLock | t | virtualxid | | | 6/704 | 6/704 | 19049 | ExclusiveLock | ttest_lock | tuple | (0,1) | | 6/704 | | 19049 | ExclusiveLock | ftest_lock_pkey | relation | | | 6/704 | | 19049 | RowExclusiveLock | ttest_lock | relation | | | 6/704 | | 19049 | RowExclusiveLock | t | transactionid | | 14611 | 6/704 | | 19049 | ExclusiveLock | t(15 rows)
至此,锁分析清楚了。再通过pgrowlocks插件观察一下
postgres=# begin;BEGINpostgres=# select txid_current(),pg_backend_pid();txid_current | pg_backend_pid --------------+---------------- 545 | 10698(1 row)postgres=# update test_lock set id = 100 where id = 1;UPDATE 1
session 2更新同一行
postgres=# begin;BEGINpostgres=# select txid_current(),pg_backend_pid();txid_current | pg_backend_pid --------------+---------------- 547 | 10903(1 row)postgres=# update test_lock set id = 100 where id = 1;此处夯住
通过pgrowlocks查看行级锁,很明了,10698进程的545这个事务,持有No Key Update的行级锁,因为没有多个事务,所以此处的multi为f
postgres=# select * from test_lock as t,pgrowlocks('test_lock') as lc where t.ctid = lc.locked_row;id | locked_row | locker | multi | xids | modes | pids ----+------------+--------+-------+-------+-------------------+--------- 1 | (0,1) | 545 | f | {545} | {"No Key Update"} | {10698}(1 row)
如果是多个事务同时去上锁一行记录,那么就会使用multixact。继续在会话1中执行:
postgres=# select * from test_lock where id = 2 for update;id ---- 2(1 row)postgres=# select * from test_lock where id = 3 for share;id ---- 3(1 row)
查看行锁
postgres=# select * from test_lock as t,pgrowlocks('test_lock') as lc where t.ctid = lc.locked_row;id | locked_row | locker | multi | xids | modes | pids ----+------------+--------+-------+-------+-------------------+--------- 1 | (0,1) | 545 | f | {545} | {"No Key Update"} | {10698} 2 | (0,2) | 545 | f | {545} | {"For Update"} | {10698} 3 | (0,3) | 545 | f | {545} | {"For Share"} | {10698}(3 rows)
新开一个会话,并且也获取for share的行级锁
postgres=# begin;BEGINpostgres=# select pg_backend_pid(),txid_current();pg_backend_pid | txid_current ----------------+-------------- 17936 | 551(1 row)postgres=# select * from test_lock where id = 3 for share;id ---- 3(1 row)
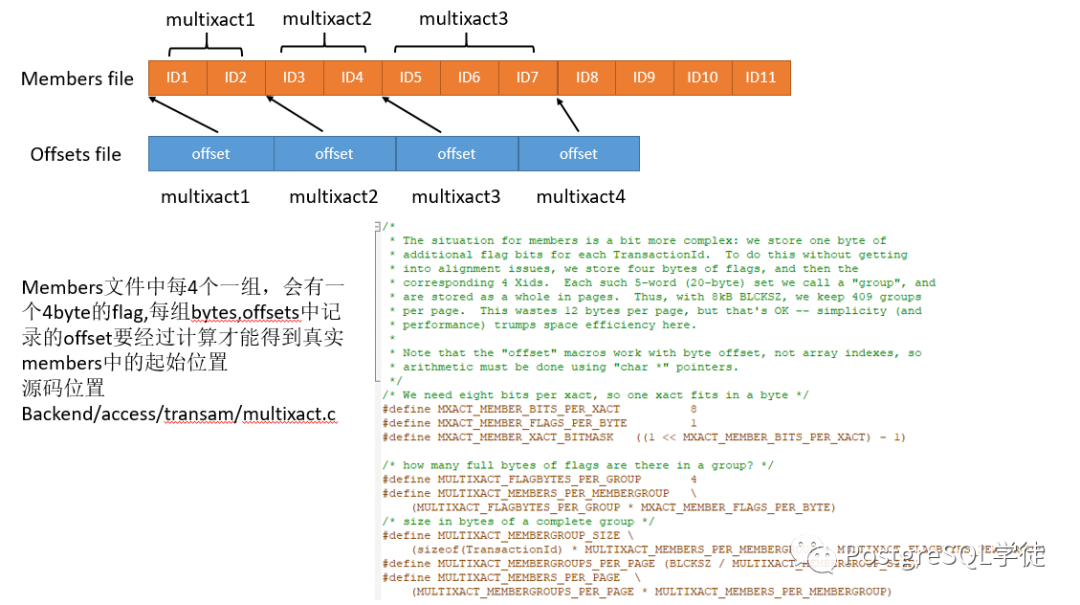
再次查看行锁,这次可以看到使用了multixact。因为对于FOR SHARE和FOR KEY SHARE,一行上面可能会被多个事务加锁,Tuple上动态维护这些事务代价很高,为此引入了multixact机制,将多个事务记录到MultiXactId,再将MultiXactId记录到tuple的xmax中。
postgres=# select * from test_lock as t,pgrowlocks('test_lock') as lc where t.ctid = lc.locked_row;id | locked_row | locker | multi | xids | modes | pids ----+------------+--------+-------+-----------+-------------------+--------------- 1 | (0,1) | 545 | f | {545} | {"No Key Update"} | {10698} 2 | (0,2) | 545 | f | {545} | {"For Update"} | {10698} 3 | (0,3) | 1 | t | {545,551} | {Share,Share} | {10698,17936}(3 rows)
还可以通过pg_get_multixact_members()函数获取MultiXactId。
postgres=# select * from pg_get_multixact_members('1');xid | mode -------+------545 | sh551 | sh(2 rows)
此外,对于锁,可以使用如下SQL快速观察,也可以创建成视图
postgres=# SELECT blocked_locks.pid AS blocked_pid, blocked_activity.usename AS blocked_user, blocking_locks.pid AS blocking_pid, blocking_activity.usename AS blocking_user, blocked_activity.query AS blocked_statement, blocking_activity.query AS current_statement_in_blocking_process FROM pg_catalog.pg_locks blocked_locks JOIN pg_catalog.pg_stat_activity blocked_activity ON blocked_activity.pid = blocked_locks.pid JOIN pg_catalog.pg_locks blocking_locks ON blocking_locks.locktype = blocked_locks.locktype AND blocking_locks.database IS NOT DISTINCT FROM blocked_locks.database AND blocking_locks.relation IS NOT DISTINCT FROM blocked_locks.relation AND blocking_locks.page IS NOT DISTINCT FROM blocked_locks.page AND blocking_locks.tuple IS NOT DISTINCT FROM blocked_locks.tuple AND blocking_locks.virtualxid IS NOT DISTINCT FROM blocked_locks.virtualxid AND blocking_locks.transactionid IS NOT DISTINCT FROM blocked_locks.transactionid AND blocking_locks.classid IS NOT DISTINCT FROM blocked_locks.classid AND blocking_locks.objid IS NOT DISTINCT FROM blocked_locks.objid AND blocking_locks.objsubid IS NOT DISTINCT FROM blocked_locks.objsubid AND blocking_locks.pid != blocked_locks.pid JOIN pg_catalog.pg_stat_activity blocking_activity ON blocking_activity.pid = blocking_locks.pid WHERE NOT blocked_locks.granted;blocked_pid | blocked_user | blocking_pid | blocking_user | blocked_statement | current_statement_in_blocking_process -------------+--------------+--------------+---------------+---------------------------------------------+--------------------------------------------- 27592 | postgres | 27574 | postgres | update test_lock set id = 100 where id = 1; | update test_lock set id = 100 where id = 1;
可以看到,27592进程被27574进程阻塞,被阻塞语句是update test_lock set id = 100 where id = 1;
以及德哥的锁检测SQL:
with t_wait as ( select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.granted, a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,a.transactionid,a.fastpath, b.state,b.query,b.xact_start,b.query_start,b.usename,b.datname,b.client_addr,b.client_port,b.application_name from pg_locks a,pg_stat_activity b where a.pid=b.pid and not a.granted ), t_run as ( select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.granted, a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,a.transactionid,a.fastpath, b.state,b.query,b.xact_start,b.query_start,b.usename,b.datname,b.client_addr,b.client_port,b.application_name from pg_locks a,pg_stat_activity b where a.pid=b.pid and a.granted ), t_overlap as ( select r.* from t_wait w join t_run r on ( r.locktype is not distinct from w.locktype and r.database is not distinct from w.database and r.relation is not distinct from w.relation and r.page is not distinct from w.page and r.tuple is not distinct from w.tuple and r.virtualxid is not distinct from w.virtualxid and r.transactionid is not distinct from w.transactionid and r.classid is not distinct from w.classid and r.objid is not distinct from w.objid and r.objsubid is not distinct from w.objsubid and r.pid <> w.pid ) ), t_unionall as ( select r.* from t_overlap r union all select w.* from t_wait w ) select locktype,datname,relation::regclass,page,tuple,virtualxid,transactionid::text,classid::regclass,objid,objsubid, string_agg( 'Pid: '||case when pid is null then 'NULL' else pid::text end||chr(10)|| 'Lock_Granted: '||case when granted is null then 'NULL' else granted::text end||' , Mode: '||case when mode is null then 'NULL' else mode::text end||' , FastPath: '||case when fastpath is null then 'NULL' else fastpath::text end||' , VirtualTransaction: '||case when virtualtransaction is null then 'NULL' else virtualtransaction::text end||' , Session_State: '||case when state is null then 'NULL' else state::text end||chr(10)|| 'Username: '||case when usename is null then 'NULL' else usename::text end||' , Database: '||case when datname is null then 'NULL' else datname::text end||' , Client_Addr: '||case when client_addr is null then 'NULL' else client_addr::text end||' , Client_Port: '||case when client_port is null then 'NULL' else client_port::text end||' , Application_Name: '||case when application_name is null then 'NULL' else application_name::text end||chr(10)|| 'Xact_Start: '||case when xact_start is null then 'NULL' else xact_start::text end||' , Query_Start: '||case when query_start is null then 'NULL' else query_start::text end||' , Xact_Elapse: '||case when (now()-xact_start) is null then 'NULL' else (now()-xact_start)::text end||' , Query_Elapse: '||case when (now()-query_start) is null then 'NULL' else (now()-query_start)::text end||chr(10)|| 'SQL (Current SQL in Transaction): '||chr(10)|| case when query is null then 'NULL' else query::text end, chr(10)||'--------'||chr(10) order by ( case mode when 'INVALID' then 0 when 'AccessShareLock' then 1 when 'RowShareLock' then 2 when 'RowExclusiveLock' then 3
when 'ShareUpdateExclusiveLock' then 4
when 'ShareLock' then 5
when 'ShareRowExclusiveLock' then 6
when 'ExclusiveLock' then 7
when 'AccessExclusiveLock' then 8
else 0
end ) desc,
(case when granted then 0 else 1 end)
) as lock_conflict
from t_unionall
group by
locktype,datname,relation,page,tuple,virtualxid,transactionid::text,classid,objid,objsubid ;
小结
本篇主要介绍了PostgreSQL中常见的锁,其中最为常见的是RegularLock,RegularLock又可以分为表级锁和行级锁,由于行级锁不在内存中,一般行级锁的等待表现为等待另一个会话的transacitonid Exclusive Lock的释放,显示的形式通常是一个事务等待另一个事务,而不是等待某个具体的行锁。相比于SpinLock、LWLock,RegularLock加锁的开销更大,但是提供更加丰富的锁模式,为数据库不同的操作场景提供了更细粒度的锁冲突控制,尽可能地提供了数据库的高并发访问。而LWLock主要提供对共享内存变量的互斥访问,比如Clog buffer(事务提交状态缓存)、Shared buffers(数据页缓存)、Substran buffer(子事务缓存)等等,所以backend进程独有的buffer是不需要锁的,因为它只被本backend进程独享,是local的。如临时表等。SpinLock主要用于对于临界变量的并发访问控制,另外PostgreSQL中的咨询锁对于应用来说也是一个福音,可以避免争用数据库资源,至于死锁,在任何数据库中都是需要特别注意的DB Killer。
参考
https://habr.com/en/company/postgrespro/blog/504498/
https://www.postgresql.org/docs/12/explicit-locking.html
https://wiki.postgresql.org/wiki/Lock_Monitoring
https://www.postgresql.org/docs/current/monitoring-stats.html#WAIT-EVENT-ACTIVITY-TABLE
https://github.com/digoal/blog/blob/master/201707/20170720_01.md
https://www.citusdata.com/blog/2018/02/15/when-postgresql-blocks/





新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
https://www.postgresqlchina.com
中国PostgreSQL分会生态产品
https://www.pgfans.cn
中国PostgreSQL分会资源下载站
https://www.postgreshub.cn


点击此处阅读原文
↓↓↓
