




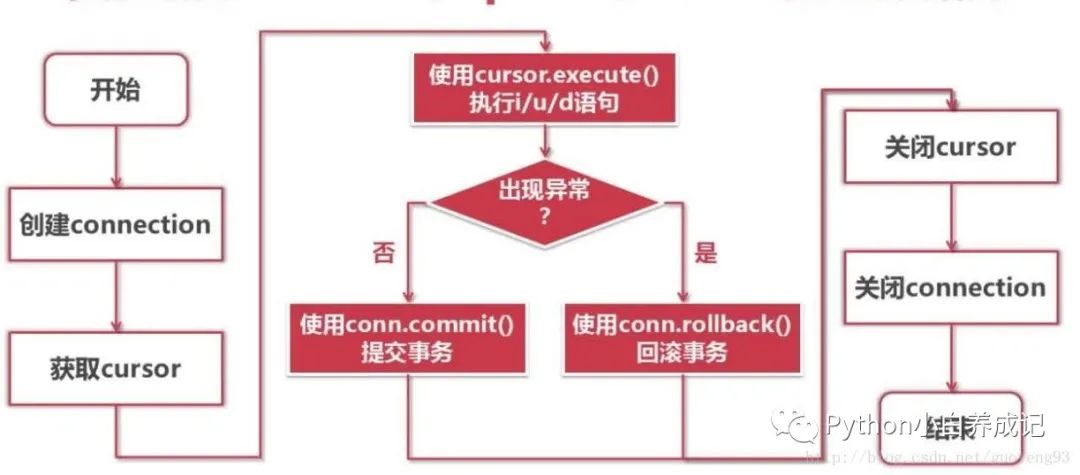
Python调用关系型数据库的基本流程如下:
Oracle数据库,是一种关系型数据库,是甲骨文公司的一款商用数据库,非常稳定,适用于大型数据库。
官方文档见:https://oracle.github.io/python-cx_Oracle/
1. 安装
pip install cx_Oracle
2. 使用
连接对象Connection
构建python与数据库通信的桥梁
创建连接对象
# python连接Oracle数据库的三种方式语法:conn = cx_Oracle.connect('username','password','host:port/dbname')语法:conn = cx_Oracle.connect('username/password@host:port/dbname')语法:conn = cx_Oracle.connect('username','password',cx_Oracle.makedsn('host', port,'dbname'))
连接对象拥有的常用方法
conn.version # 查看数据库版本conn.dsn # 查看监听信息conn.close() # 关闭数据库连接,并释放相关资源conn.cursor() # 返回一个游标对象,该对象用于访问和操作数据库中的数据conn.begin() # 用于开始一个事务,如果数据库的AUTOCOMMIT已经开启就关闭它,直到事务调用commit()和rollback()结束。conn.commit() # 事务提交conn.rollback() # 事务回滚
游标对象Cursor
操作数据库中的数据
游标对象拥有的属性
cur.bindnames() # 查看sql带参数中绑定的名称cur.description # 获取表的列名集合,数据类型为:[('ORDER_ID', <cx_Oracle.DbType DB_TYPE_VARCHAR>, 64, 64, None, None, 0)],第一个元素元祖里的第一个元素就是列名,获取方法:[col[0] for col in cur.description]
游标对象拥有的方法
cur.prepare('sql') # 如果执行的sql语句需要传外部参数,通过此函数加载sql语句,然后再通过execute或executemany加参数执行,可防止sql注入cur.execute('sql',[parameters],keywordParameters) # 执行单条sql,支持绑定位置参数和关键字参数,返回一个游标对象cur.executemany() # 执行多条sql语句,批量操作cur.close() # 关闭指针并释放相关资源# 通过excute*方法执行sql后,从数据库将结果返回给客户端后,数据获取cur.fetchone() # 获取查询的单个结果,响应数据类型为元祖:(,)cur.fetchall() # 获取查询的所有的结果,响应数据类型为列表,元素为元祖:[(,),(,)]cur.fetchmany(num) # 获取结果集的前多少条num数据,响应数据类型为列表,元素为元祖:[(,),(,)]cur.rowcount # 表示执行上面的方法后,查询或更新所发生行数,-1表示还没开始查询或没有查询到数据。注意:从数据库获取结果后,放在缓存,类似于队列queue,fetch了之后原数据集就少了
查询示例:
# 创建游标cur = conn.cursor()语法:cur.execute('sql',[parameters],keywordParameters)# 1. 不带参数查询result = cur.execute("select sysdate from dual")# 2. 带参数查询: 关键字参数1kwargs = {"sysCode": "B20501", "orderStatus_": "20100"}sql = "select * from base_order where syscode=:sysCode and order_status=:orderStatus_"result = cur.execute(sql, kwargs)# 查看sql中绑定的名称print(cur.bindnames()) # ['SYSCODE', 'ORDERSTATUS_']# 3. 带参数查询:关键字参数2sql = "select * from base_order where order_id=:order_idd"result = cur.execute(sql, order_idd="83621051910000370008")# 4. 带参数查询:位置参数sql = "select * from base_order where order_id=:1"result = cur.execute(sql, ["83621051910000370008"])# 查看sql中绑定的名称print(cur.bindnames()) # ['1']# 5. 单参数查询:通过调用prepare方法加载sql,防止sql注入sql = "select * from base_order where order_id=:1"cur.prepare(sql)result = cur.execute(None, ["83621051910000370008"])# # 一般我们通过执行cur.fetch获取的结果都是只有值的,有时希望组成字典让表列名和值一一对应出来,如{order_id:111,age:30}dict(zip([d[0] for d in cur.description], cur.fetchone()))# # 关于结果的获取,可以是execute返回的对象调用fetch*方法,也可以是cursor对象直接调用fetch*方法,本质一样# print(result.fetchone()) or cur.fetchone()
批量操作示例:
# mysql没有批量操作的方法,批量是Oracle特有的,最常使用的就是从文件读取数据批量插入# 批量插入阀值【每批次插入多少量】conn = cx_Oracle.connect('username','password','host:port/dbname')cur = conn.cursor()threshold = 100data = []try:with open('text.txt', 'r', encoding='utf-8') as f:for index, line in enumerate(f):data.append(line)if (index + 1) % threshold == 0:cur.executemany("insert into table_name values (:1,:2)", data)conn.commit()data.clear()continueif len(data) > 0:cur.executemany("insert into table_name values (:1,:2)", data)conn.commit()except Exception as e:print(e)conn.rollback()finally:conn.close()cur.close()
参考:https://blog.csdn.net/guofeng93/article/details/53994112
3. 通过连接池
实际生产中调用数据库是很频繁的,如果每次都重新连接数据库,是非常耗资源的,一般都采用数据池的方式
pip install dbutilsfrom dbutils.pooled_db import PooledDBdb_pool = PooledDB(cx_Oracle,user="username",password="password",dsn="db_name",mincached=1, # 初始化时,最少开启多少个连接maxcached=1,maxconnections=5, # 最多同时存在多少个连接blocking=True, # 当连接超过最大值时,阻塞并等待连接减少,才接受新的请求threaded=True) # 开启线程conn = db_pool.connection()cur = conn.cursor()
文章转载自Python小白养成记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
