




第五章 使用集合
1. 集合理论入门
2. 集合理论实践
3. 集合操作符
3.1 union 操作符
3.2 intersect 操作符
3.3 except 操作符
4. 集合操作规则
4.1 对复合查询结果进行排序
4.2 集合操作符的优先级
尽管每次与数据库交互的时候可以只处理一行数据,但是关系数据库实际上处理的都是集合。本章探讨如何使用各种集合操作符联合多个结果集。在简要介绍集合论之后,我将演示如何使用集合操作符union、intersect和except联合使用多个数据集。
1. 集合理论入门
在世界上许多地方,基础集合理论都有包含在小学数学课程中。也许看到下图(6-1)能唤起你的一些回忆:
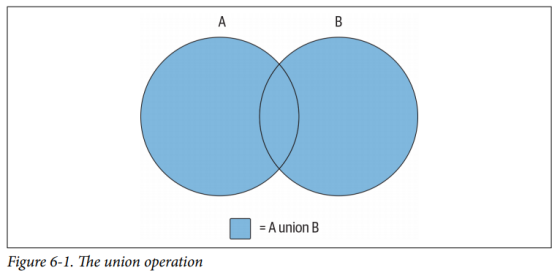
上图(6-1)中的阴影区域表示集合A和B的并集,这是两个集合的联合(重叠部分只包含一次)。是不是觉得很眼熟?是的话,那么你学过的知识现在就能派上用场了,如果觉得不熟悉也没关系,因为根据该图表也能很好地理解这个概念。
使用圆圈来表示两个数据集(A和B),想象两个集合共用的数据子集由图中所示的重叠部分所代表。由于集合论毫不关心没有重叠部分的数据集,所以下面我会使用同样的图表来说明集合操作。另一种集合操作只涉及两个数据集之间的重叠,被称为交集(intersection),如图(6-2)所示:
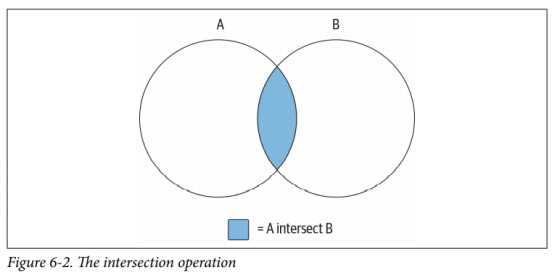
由集合A和B的交集操作生成的数据集只是两个集合之间的重叠部分。如果这两个集合没有重叠,则交集操作产生空集。
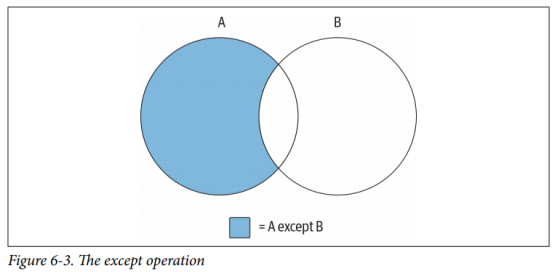
下图(6-3)所示的第三个也是最后一个集合操作称为差操作(except)。
下图(6-3)显示了A except B的结果,即完整的集合A中减去它与集合B重叠的部分。如果两个集合没有重叠,则运算A except B的结果是整个集合A:
使用这三种操作,或者联合使用不同的操作,可以产生所需的任何结果。例如,假设你想要构建一个如图(6-4)所示的集合:
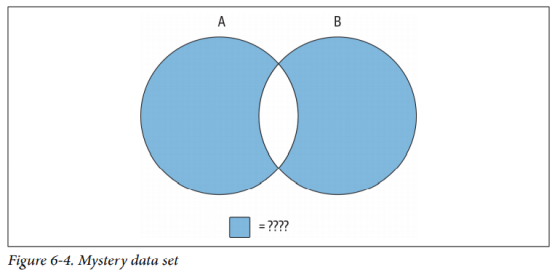
该数据集包括集合A和B非重合区域的部分。仅用一种集合操作显然是无法产生该结果的,所以你先得构建一个包含集合A与B所有元素的数据集,再使用第二种操作移除重复部分。如果使用A union B描述并集,使用A intersect B描述交集,则可以使用下面的方法生成上图(6-4)所示的数据集:
(A union B) except (A intersect B)
当然,通常获得结果的方法不止一种,你也可以使用以下操作获得类似的结果:
(A except B) union (B except A)
使用图示是很容易理解这些概念的,下一节中会介绍如何在关系数据库中使用SQL集合操作符来实现它们。
2. 集合理论实践
上一节的图示中用于表示数据集的圆并不代表数据集所包含的数据内容。然而,在处理实际数据时,如果要合并数据集,还需要了解数据集结构。例如,想象一下当你试图生成customer表和city表的并集时会发生的情况,这两个表的定义如下:
mysql> desc customer;+-------------+----------------------+------+-----+-------------------+| Field | Type | Null | Key | Default |+-------------+----------------------+------+-----+-------------------+| customer_id | smallint(5) unsigned | NO | PRI | NULL || store_id | tinyint(3) unsigned | NO | MUL | NULL || first_name | varchar(45) | NO | | NULL || last_name | varchar(45) | NO | MUL | NULL || email | varchar(50) | YES | | NULL || address_id | smallint(5) unsigned | NO | MUL | NULL || active | tinyint(1) | NO | | 1 || create_date | datetime | NO | | NULL || last_update | timestamp | YES | | CURRENT_TIMESTAMP |+-------------+----------------------+------+-----+-------------------+mysql> desc city;+-------------+----------------------+------+-----+-------------------+| Field | Type | Null | Key | Default |+-------------+----------------------+------+-----+-------------------+| city_id | smallint(5) unsigned | NO | PRI | NULL || city | varchar(50) | NO | | NULL || country_id | smallint(5) unsigned | NO | MUL | NULL || last_update | timestamp | NO | | CURRENT_TIMESTAMP |+-------------+----------------------+------+-----+-------------------+
合并完这两个表之后,结果集中的第一列将包含customer.customer_id以及city.city_id列,第二列将是customer.store_id以及city.city列,诸如此类。其中有些列对是容易组合的(比如两个数字列),另外一些列是难以组合的,比如数字列与字符串列或字符串列与日期列。此外,合并表的第五列到第九列将只包含来自customer表的第五列到第九列,因为city表只有四列。显然,我们期望合并的两个数据集之间最好是有一些共性的。
因此,在对两个数据集执行集合操作时,必须遵循以下准则:
遵循这些规则,在实践中就能更容易理解“重叠数据”的含义了,对于两个集合中对应的数据列,它们需要有相同的字符串、数字或日期,才能被视为相同的行。
可以通过在两个select语句之间使用一个集合操作符来执行集合操作,如下所示:
mysql> SELECT 1 num, 'abc' str-> UNION-> SELECT 9 num, 'xyz' str;+-----+-----+| num | str |+-----+-----+| 1 | abc || 9 | xyz |+-----+-----+2 rows in set (0.02 sec)
每个单独的查询产生一个数据集,该数据集由一行组成,该行有一个数字列和一个字符串列。集合操作符(在本例中是union)告诉数据库服务器合并两个集合中的所有行。因此,最终的集合将包括两个两列的行。此查询称为复合查询(compound query),因为它将多个独立的查询合并到一起。本书后面你会看到更加复杂的复合查询,会组合使用两个以上的查询来获得最终的查询结果。
3. 集合操作符
SQL语言包括三种集合操作符来实现本章前面描述的各种集合操作。另外,每个集合操作符有两种修饰符,一个包含重复项,一个去除重复项(但不一定是所有重复项)。下面各小节定义了每个操作符并演示了它们的使用过程。
3.1 union操作符
union和union all操作符允许组合多个数据集。两者的区别在于union对合并后的集合进行排序并删除重复项,而union all不这样做(会保留重复项)。使用union all时,最终数据集中的行数始终等于被合并的数据集的行数之和。这个操作是最容易执行的集合操作(从服务器的角度来看),因为服务器不需要检查冗余数据。以下示例演示如何使用union all操作符从多个表生成姓名的集合:
mysql> SELECT 'CUST' typ, c.first_name, c.last_name-> FROM customer c-> UNION ALL-> SELECT 'ACTR' typ, a.first_name, a.last_name-> FROM actor a;+------+------------+-------------+| typ | first_name | last_name |+------+------------+-------------+| CUST | MARY | SMITH || CUST | PATRICIA | JOHNSON || CUST | LINDA | WILLIAMS || CUST | BARBARA | JONES || CUST | ELIZABETH | BROWN || CUST | JENNIFER | DAVIS || CUST | MARIA | MILLER || CUST | SUSAN | WILSON || CUST | MARGARET | MOORE || CUST | DOROTHY | TAYLOR || CUST | LISA | ANDERSON || CUST | NANCY | THOMAS || CUST | KAREN | JACKSON |...| ACTR | BURT | TEMPLE || ACTR | MERYL | ALLEN || ACTR | JAYNE | SILVERSTONE || ACTR | BELA | WALKEN || ACTR | REESE | WEST || ACTR | MARY | KEITEL || ACTR | JULIA | FAWCETT || ACTR | THORA | TEMPLE |+------+------------+-------------+799 rows in set (0.00 sec)
该查询返回799个姓名,其中599行来自customer表,其他200行来自actor表。第一列(具有别名typ)不是必需的,但我们添加该列以显示查询返回的每个姓名的源。
为了演示union all操作符不会删除重复项,下面的示例类似于上一个实例,但是对actor表执行两次相同的查询:
mysql> SELECT 'ACTR' typ, a.first_name, a.last_name-> FROM actor a-> UNION ALL-> SELECT 'ACTR' typ, a.first_name, a.last_name-> FROM actor a;+------+-------------+--------------+| typ | first_name | last_name |+------+-------------+--------------+| ACTR | PENELOPE | GUINESS || ACTR | NICK | WAHLBERG || ACTR | ED | CHASE || ACTR | JENNIFER | DAVIS || ACTR | JOHNNY | LOLLOBRIGIDA || ACTR | BETTE | NICHOLSON || ACTR | GRACE | MOSTEL |...| ACTR | BURT | TEMPLE || ACTR | MERYL | ALLEN || ACTR | JAYNE | SILVERSTONE || ACTR | BELA | WALKEN || ACTR | REESE | WEST || ACTR | MARY | KEITEL || ACTR | JULIA | FAWCETT || ACTR | THORA | TEMPLE |+------+-------------+--------------+400 rows in set (0.00 sec)
如你所见,结果中从actor表包含了两次200行数据,总共是400行。
在复合查询中不太可能包含两个重复查询,所以下面是另一个返回重复数据的复合查询的例子:
mysql> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'-> UNION ALL-> SELECT a.first_name, a.last_name-> FROM actor a-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%';+------------+-----------+| first_name | last_name |+------------+-----------+| JENNIFER | DAVIS || JENNIFER | DAVIS || JUDY | DEAN || JODIE | DEGENERES || JULIANNE | DENCH |+------------+-----------+5 rows in set (0.00 sec)
两个查询都返回缩写为JD的人名。结果集的五行中,有一行是重复的(JENNIFER DAVIS)。如果希望合并之后的表排除重复行,则需要使用union操作符而不是union all:
mysql> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'-> UNION-> SELECT a.first_name, a.last_name-> FROM actor a-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%';+------------+-----------+| first_name | last_name |+------------+-----------+| JENNIFER | DAVIS || JUDY | DEAN || JODIE | DEGENERES || JULIANNE | DENCH |+------------+-----------+4 rows in set (0.00 sec)
此查询的结果集中只包含了四个不同的名字,而不是使用union all时返回的五行数据。
3.2 intersect操作符
ANSI SQL规范中包括用于执行交集的intersect操作符。不幸的是,MySQL的8.0版本还没有实现intersect操作符。但若你使用的是Oracle或SQL Server 2008就可以使用这个操作符了。因为本书的所有示例用的都是MySQL,所以本节中示例查询的结果集都是捏造的,不能在8.0及以下的任何版本中执行。我也避免显示MySQL提示符(mysql>),因为这些语句不是在MySQL服务器上执行的。
如果复合查询中的两个查询返回不重叠的数据集,则交集将是一个空集。考虑以下查询:
SELECT c.first_name, c.last_nameFROM customer cWHERE c.first_name LIKE 'D%' AND c.last_name LIKE 'T%'INTERSECTSELECT a.first_name, a.last_nameFROM actor aWHERE a.first_name LIKE 'D%' AND a.last_name LIKE 'T%';Empty set (0.04 sec)
虽然演员和客户都有首字母DT,但这些集合是完全不重叠的,因此这两个集合的交集产生了空集。但是,如果我们使用缩写JD,交集将包含一行数据:
SELECT c.first_name, c.last_nameFROM customer cWHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'INTERSECTSELECT a.first_name, a.last_nameFROM actor aWHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%';+------------+-----------+| first_name | last_name |+------------+-----------+| JENNIFER | DAVIS |+------------+-----------+1 row in set (0.00 sec)
这两个查询的交集产生结果为“Jennifer Davis”,即两个待查询的结果集中唯一重复的值。
除了intersect操作符(删除重叠部分中所有重复行)之外,ANSI SQL规范还允许调用intersect all操作符,该操作符不删除重复行。目前唯一一个实现intersect all操作符的数据库服务器是IBM的DB2 Universal Server。
3.3 except操作符
ANSI SQL规范包括用于执行集合差操作的except操作符。同样不幸的是,MySQL的8.0版本没有实现except操作符,因此本节与上一节一样采用捏造的示例进行演示。
注意
如果你使用的是Oracle Database,则需要改用非ANSI兼容的minus操作符。
except操作符返回第一个结果集减去与第二个结果集重合部分后的结果。以下是上一节中的示例,但使用except而不是intersect,并且查询顺序颠倒:
SELECT a.first_name, a.last_nameFROM actor aWHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'EXCEPTSELECT c.first_name, c.last_nameFROM customer cWHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%';+------------+-----------+| first_name | last_name |+------------+-----------+| JUDY | DEAN || JODIE | DEGENERES || JULIANNE | DENCH |+------------+-----------+3 rows in set (0.00 sec)
在该查询中,结果集由第一个查询的四行数据减去两个查询的结果集中都包含的“Jennifer Davis”组成。在ANSI SQL规范中还指定了一个except all操作符,但是同样只有IBM的DB2 Universal Server实现了该操作符。
except all操作符有点难搞,所以下面的示例演示了如何处理重复数据。假设有两个如下所示的数据集:
Set A+----------+| actor_id |+----------+| 10 || 11 || 12 || 10 || 10 |+----------+Set B+----------+| actor_id |+----------+| 10 || 10 |+----------+
操作A except B产生结果如下:
+----------+| actor_id |+----------+| 11 || 12 |+----------+
如果将操作改为A except all B,结果将如下所示:
+----------+| actor_id |+----------+| 10 || 11 || 12 |+----------+
因此,这两种操作的区别在于,except从集合A中删除所有重复数据,而except all根据重复数据在集合B中出现的次数进行删除。
4. 集合操作规则
下面几节简述了使用复合查询需要注意的一些规则。
4.1 对复合查询结果进行排序
如果希望对复合查询的结果进行排序,可以在最后一个查询之后添加order by子句。在order by子句中指定列名时,需要从复合查询的第一个查询中选择列名。通常在复合查询中,两个查询的列名是相同的(不强制相同),如下所示:
mysql> SELECT a.first_name fname, a.last_name lname-> FROM actor a-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'-> UNION ALL-> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'-> ORDER BY lname, fname;+----------+-----------+| fname | lname |+----------+-----------+| JENNIFER | DAVIS || JENNIFER | DAVIS || JUDY | DEAN || JODIE | DEGENERES || JULIANNE | DENCH |+----------+-----------+5 rows in set (0.00 sec)
在本例中,两个查询中指定的列名不同。如果在order by子句的第二个查询中指定列名,将产生以下错误:
mysql> SELECT a.first_name fname, a.last_name lname-> FROM actor a-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'-> UNION ALL-> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'-> ORDER BY last_name, first_name;ERROR 1054 (42S22): Unknown column 'last_name' in 'order clause'
我建议为两个查询中的列提供相同的列别名,以避免此问题发生。
4.2 集合操作符的优先级
如果复合查询包含两个以上使用不同集合操作符的查询,则需要确定复合语句中查询的执行次序。考虑以下包含三个查询的复合语句:
mysql> SELECT a.first_name, a.last_name-> FROM actor a-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'-> UNION ALL-> SELECT a.first_name, a.last_name-> FROM actor a-> WHERE a.first_name LIKE 'M%' AND a.last_name LIKE 'T%'-> UNION-> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%';+------------+-----------+| first_name | last_name |+------------+-----------+| JENNIFER | DAVIS || JUDY | DEAN || JODIE | DEGENERES || JULIANNE | DENCH || MARY | TANDY || MENA | TEMPLE |+------------+-----------+6 rows in set (0.00 sec)
此复合查询包括三个返回非唯一名字集的查询,第一个和第二个查询用union all操作符分隔,而第二个和第三个查询用union操作符分隔。虽然union和union all操作符放置的位置似乎区别不大,但实际上是有区别的。下面是将两个集合操作符颠倒次序后的复合查询:
mysql> SELECT a.first_name, a.last_name-> FROM actor a-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'-> UNION-> SELECT a.first_name, a.last_name-> FROM actor a-> WHERE a.first_name LIKE 'M%' AND a.last_name LIKE 'T%'-> UNION ALL-> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%';+------------+-----------+| first_name | last_name |+------------+-----------+| JENNIFER | DAVIS || JUDY | DEAN || JODIE | DEGENERES || JULIANNE | DENCH || MARY | TANDY || MENA | TEMPLE || JENNIFER | DAVIS |+------------+-----------+7 rows in set (0.00 sec)
从结果来看,显然当使用不同的集合操作符时,复合查询的排列方式确实会产生不同的结果。通常,包含三个或三个以上查询的复合查询按自顶向下的顺序被解析和执行,但要注意以下几点:
MySQL不允许在复合查询中使用括号,但如果你使用的是其他数据库服务器,则可以将相邻的查询封装在括号中,以改变默认复合查询自顶向下的处理,如下所示:
SELECT a.first_name, a.last_nameFROM actor aWHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'UNION(SELECT a.first_name, a.last_nameFROM actor aWHERE a.first_name LIKE 'M%' AND a.last_name LIKE 'T%'UNION ALLSELECT c.first_name, c.last_nameFROM customer cWHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%')
对于这个复合查询,第二个和第三个查询将使用union all操作符进行组合,然后将它与第一个查询通过union操作符进行连接,以产生最终结果。


