




第九章 SQL 子查询
子查询是一个可以在总共四种SQL数据语句中使用的强大工具。在本章中,我将向你展示如何使用子查询来过滤数据、生成值和构造临时数据集。经过实验之后,你应该就能认识到子查询是SQL语言最强大的特性之一了。
1. 什么是子查询
子查询(subquery)是包含在另一个SQL语句(后文中我用包含语句 containing statement代称)中的查询。子查询总是用括号括起来,并且通常在包含语句之前执行。与其他查询一样,子查询返回的结果集类型包括:
• 单列单行;
• 单列多行;
• 多列多行。
子查询返回的结果集的类型决定了它是如何被使用以及包含语句可以使用哪些操作符来处理子查询返回的数据。当执行完包含语句后,所有子查询返回的数据都将被丢弃,这使得子查询像一个具有语句作用域的临时表(这意味着在SQL语句完成执行后,服务器将释放用于存储子查询结果的内存)。
其实你在前面的章节中已经看到过一些子查询的示例了,不过现在还是以一个简单的示例开始:
mysql> SELECT customer_id, first_name, last_name-> FROM customer-> WHERE customer_id = (SELECT MAX(customer_id) FROM customer);+-------------+------------+-----------+| customer_id | first_name | last_name |+-------------+------------+-----------+| 599 | AUSTIN | CINTRON |+-------------+------------+-----------+1 row in set (0.27 sec)
在本例中,子查询返回customer表中customer_id列的最大值,然后包含语句返回关于该客户的数据。如果你搞不清楚子查询是如何工作的,那么可以尝试单独运行子查询(不带括号)看看它返回的内容。下面是上一个例子中子查询的示例:
mysql> SELECT MAX(customer_id) FROM customer;+------------------+| MAX(customer_id) |+------------------+| 599 |+------------------+1 row in set (0.00 sec)
子查询返回单行单列结果,所以它可以被用作相等条件中的表达式之一(如果子查询返回两行或更多行数据,则可以将其与某个行进行比较,但不能进行判等操作,我在后面会介绍这一点的)。在这种情况下,你可以用子查询返回的值替换包含查询中过滤条件的右侧表达式,如下所示:
mysql> SELECT customer_id, first_name, last_name-> FROM customer-> WHERE customer_id = 599;+-------------+------------+-----------+| customer_id | first_name | last_name |+-------------+------------+-----------+| 599 | AUSTIN | CINTRON |+-------------+------------+-----------+1 row in set (0.00 sec)
在这种情况下,子查询很有用,因为它允许你在单个查询中检索有关最大customer_id的信息,而不是先使用一个查询检索最大的ID,然后再编写一个查询从customer表中获取所需的数据。你将看到,子查询在许多其他情况下也很有用,并且可能成为SQL工具包中最强大的工具之一。
2. 子查询类型
除了前面提到的关于子查询返回的结果集类型的差异(单行/单列、单行/多列或多行多列)之外,你也可以按照其他标准给子查询分类:有些子查询是完全独立的(称为非关联子查询),而另有些查询则引用包含语句中的列(称为关联查询)。接下来的几节将探讨这两个子查询类型,并演示可以用来与它们交互的操作符示例。
3. 非关联子查询
本章前面的示例是一个非关联子查询,它可以单独执行并且不需要引用包含语句中的任何内容。除非你编写的是update语句或delete语句(通常使用关联子查询),否则你遇到的大多数子查询都是这种类型的非关联子查询。前面的示例除了是非关联子查询,它也是一个返回单行单列结果集的子查询,像这样的子查询叫做标量子查询(scalar subquery)并且可以出现在条件中常用操作符号(=,<>,<,>,<=,>=)的任意一侧。下面的示例演示如何在不等条件中使用标量子查询:
mysql> SELECT city_id, city-> FROM city-> WHERE country_id <>-> (SELECT country_id FROM country WHERE country = 'India');+---------+----------------------------+| city_id | city |+---------+----------------------------+| 1 | A Corua (La Corua) || 2 | Abha || 3 | Abu Dhabi || 4 | Acua || 5 | Adana || 6 | Addis Abeba |...| 595 | Zapopan || 596 | Zaria || 597 | Zeleznogorsk || 598 | Zhezqazghan || 599 | Zhoushan || 600 | Ziguinchor |+---------+----------------------------+540 rows in set (0.02 sec)
此查询返回所有不在印度的城市。这个子查询基于查询语句的最后一行,这行返回了印度城市的ID,然后包含语句返回所有和印度城市ID不等的城市信息。尽管这是个十分简单的例子,但是实际上的子查询可能也会很复杂,并且也可能和所有可用的查询子句(select、from、where、group by、having和order by)结合使用,这些都是根据需求决定的。
如果在相等条件中使用子查询,但子查询返回多行结果,则会报错。例如,如果修改上一个查询,使得子查询返回除印度以外的所有国家,则会产生以下错误:
mysql> SELECT city_id, city-> FROM city-> WHERE country_id <>-> (SELECT country_id FROM country WHERE country <> 'India');ERROR 1242 (21000): Subquery returns more than 1 row
如果单独运行子查询,将看到结果如下:
mysql> SELECT country_id FROM country WHERE country <> 'India';+------------+| country_id |+------------+| 1 || 2 || 3 || 4 |...| 106 || 107 || 108 || 109 |+------------+108 rows in set (0.00 sec)
包含查询失败,这是因为表达式(country_id)不能等同于一组表达式(包括country_id为1、2、3、…、109)。换句话说,单个事物不能等于一组事物的集合。在下一节中,我会介绍如何使用不同的操作符来解决问题。
3.1 多行,单列子查询
正如上一个例子所示,如果子查询返回多行数据,则无法在相等条件的一侧使用它,但是你也可以使用另外四个操作符来为这种类型的子查询构建条件。
3.1.1 in和not in操作符
虽然不能对单个值与一个值集进行判等操作,但你可以检查某个值集中是否存在某一个值。下一个示例虽然没用子查询,但演示了如何构造用in操作符在一组值中查找某个值的条件:
mysql> SELECT country_id-> FROM country-> WHERE country IN ('Canada','Mexico');+------------+| country_id |+------------+| 20 || 60 |+------------+2 rows in set (0.00 sec)
条件左侧的表达式是country列,而条件右侧是一组字符串。in操作符检查是否可以在country列中找到字符串集合中的任意一个值,如果能则满足条件,该行会被添加到结果集中。你也可以使用使用两个相等条件获得相同的结果,如:
mysql> SELECT country_id-> FROM country-> WHERE country = 'Canada' OR country = 'Mexico';+------------+| country_id |+------------+| 20 || 60 |+------------+2 rows in set (0.00 sec)
当集合只包含两个表达式时,这种方法似乎是合理的,但是当集合包括很多(成百上千)值,那么就很好理解为什么最好使用in操作符了。
你可能偶尔会创建一组字符串、日期或数字集合并将它用于条件的某一侧,但是你更可能会通过执行子查询生成这个集合。下面的查询使用in操作符并在过滤条件的右侧使用子查询返回加拿大或墨西哥的所有城市集合:
mysql> SELECT city_id, city-> FROM city-> WHERE country_id IN-> (SELECT country_id-> FROM country-> WHERE country IN ('Canada','Mexico'));+---------+----------------------------+| city_id | city |+---------+----------------------------+| 179 | Gatineau || 196 | Halifax || 300 | Lethbridge || 313 | London || 383 | Oshawa || 430 | Richmond Hill || 565 | Vancouver |...| 452 | San Juan Bautista Tuxtepec || 541 | Torren || 556 | Uruapan || 563 | Valle de Santiago || 595 | Zapopan |+---------+----------------------------+37 rows in set (0.00 sec)
除了查看某组值集中是否存在某个值外,还可以使用not in操作符检查相反的情况。下面是使用not in代替in实现上一个查询的例子:
mysql> SELECT city_id, city-> FROM city-> WHERE country_id NOT IN-> (SELECT country_id-> FROM country-> WHERE country IN ('Canada','Mexico'));+---------+----------------------------+| city_id | city |+---------+----------------------------+| 1 | A Corua (La Corua) || 2 | Abha || 3 | Abu Dhabi || 5 | Adana || 6 | Addis Abeba |...| 596 | Zaria || 597 | Zeleznogorsk || 598 | Zhezqazghan || 599 | Zhoushan || 600 | Ziguinchor |+---------+----------------------------+563 rows in set (0.00 sec)
此查询查找不在加拿大或墨西哥的所有城市。
3.1.2 all操作符
in操作符用于检查是否可以在一组表达式集合中找到某个表达式,而all操作符则允许将某个值与集合中的每个值进行比较。要构建这样的条件,通常需要将比较操作符(=,<>,<,>等)与all操作符结合使用。例如,下面的查询查找从来没享受过免费租赁电影服务的客户:
mysql> SELECT first_name, last_name-> FROM customer-> WHERE customer_id <> ALL-> (SELECT customer_id-> FROM payment-> WHERE amount = 0);+-------------+--------------+| first_name | last_name |+-------------+--------------+| MARY | SMITH || PATRICIA | JOHNSON || LINDA | WILLIAMS || BARBARA | JONES |...| EDUARDO | HIATT || TERRENCE | GUNDERSON || ENRIQUE | FORSYTHE || FREDDIE | DUGGAN || WADE | DELVALLE || AUSTIN | CINTRON |+-------------+--------------+576 rows in set (0.01 sec)
子查询返回免费租赁过电影的客户的ID集,包含查询返回ID不在子查询返回的集合中所有客户的名称。你可能会觉得这种方法很笨拙,其实大多数人也是这么想的,所以他们宁愿使用不同的查询短语以避免使用all操作符。为了说明这一点,下面的示例使用not in操作符实现上一个查询的例子如下:
SELECT first_name, last_nameFROM customerWHERE customer_id NOT IN(SELECT customer_idFROM paymentWHERE amount = 0)
其实采用哪种方法只是一种偏好问题,但是我认为大多数人会觉得使用not in版本的查询更好理解。
注意:使用not in或<> all将值与值集进行比较时,必须确保值集不包含null值,因为服务器会将表达式左侧的值与集合的每个成员进行判等操作,而任何试图将值与null值进行比较的操作都会产生未知的结果。因此,以下查询返回一个空集:
mysql> SELECT first_name, last_name-> FROM customer-> WHERE customer_id NOT IN (122, 452, NULL);Empty set (0.00 sec)
下面是另一个使用all操作符的示例,但这次子查询位于having子句中:
mysql> SELECT customer_id, count(*)-> FROM rental-> GROUP BY customer_id-> HAVING count(*) > ALL-> (SELECT count(*)-> FROM rental r-> INNER JOIN customer c-> ON r.customer_id = c.customer_id-> INNER JOIN address a-> ON c.address_id = a.address_id-> INNER JOIN city ct-> ON a.city_id = ct.city_id-> INNER JOIN country co-> ON ct.country_id = co.country_id-> WHERE co.country IN ('United States','Mexico','Canada')-> GROUP BY r.customer_id-> );+-------------+----------+| customer_id | count(*) |+-------------+----------+| 148 | 46 |+-------------+----------+1 row in set (0.01 sec)
本例中的子查询返回北美所有客户的电影租赁总数,包含查询返回电影租赁总数超过任何北美客户的所有客户。
3.1.3 any操作符
与all操作符一样,any操作符允许将一个值与一组值集中的成员进行比较,但是与all不同的是,使用any操作符时,只要有一个比较是成立的,则结果为true。下面的示例查询电影租金总额超过玻利维亚、巴拉圭或智利所有客户总付款的所有客户:
mysql> SELECT customer_id, sum(amount)-> FROM payment-> GROUP BY customer_id-> HAVING sum(amount) > ANY-> (SELECT sum(p.amount)-> FROM payment p-> INNER JOIN customer c-> ON p.customer_id = c.customer_id-> INNER JOIN address a-> ON c.address_id = a.address_id-> INNER JOIN city ct-> ON a.city_id = ct.city_id-> INNER JOIN country co-> ON ct.country_id = co.country_id-> WHERE co.country IN ('Bolivia','Paraguay','Chile')-> GROUP BY co.country-> );+-------------+-------------+| customer_id | sum(amount) |+-------------+-------------+| 137 | 194.61 || 144 | 195.58 || 148 | 216.54 || 178 | 194.61 || 459 | 186.62 || 526 | 221.55 |+-------------+-------------+6 rows in set (0.03 sec)
子查询返回玻利维亚、巴拉圭和智利所有客户的电影租金总额,包含查询返回至少超过这三个国家中一个国家的所有客户(如果你发现自己的花费超过了整个国家的总花费,那么你可以考虑取消订阅Netflix并订阅玻利维亚、巴拉圭或者智利了)。
注意:使用=any和in等效,不过大多数人还是喜欢使用in操作符。
3.2 多列子查询
到目前为止,本章中的子查询示例返回单行单列或多行结果。但是某些情况下你也可能使用返回不止一列数据的子查询。为了展示多列子查询的实用性,下面首先看一个使用多重单列子查询的示例:
mysql> SELECT fa.actor_id, fa.film_id-> FROM film_actor fa-> WHERE fa.actor_id IN-> (SELECT actor_id FROM actor WHERE last_name = 'MONROE')-> AND fa.film_id IN-> (SELECT film_id FROM film WHERE rating = 'PG');+----------+---------+| actor_id | film_id |+----------+---------+| 120 | 63 || 120 | 144 || 120 | 414 || 120 | 590 || 120 | 715 || 120 | 894 || 178 | 164 || 178 | 194 || 178 | 273 || 178 | 311 || 178 | 983 |+----------+---------+11 rows in set (0.00 sec)
此查询使用两个子查询来检索姓为Monroe的所有演员和分级为PG的所有电影,而包含查询使用子查询返回的信息检索姓为Monroe的演员出现在分级为PG的电影中的所有情况。但你也可以将两个单列子查询合并到一个多列子查询中,并将结果与film_actor表中的两列进行比较。为此,你的过滤条件必须命名film_actor表中的两列,并用括号括起来,使其顺序与子查询返回的顺序相同,如下所示:
mysql> SELECT actor_id, film_id-> FROM film_actor-> WHERE (actor_id, film_id) IN-> (SELECT a.actor_id, f.film_id-> FROM actor a-> CROSS JOIN film f-> WHERE a.last_name = 'MONROE'-> AND f.rating = 'PG');+----------+---------+| actor_id | film_id |+----------+---------+| 120 | 63 || 120 | 144 || 120 | 414 || 120 | 590 || 120 | 715 || 120 | 894 || 178 | 164 || 178 | 194 || 178 | 273 || 178 | 311 || 178 | 983 |+----------+---------+11 rows in set (0.00 sec)
该查询的功能与上一个实例的功能相同,但是它使用返回两列的单一查询代替了两个只返回单列的子查询。此版本中的子查询使用一种称为交叉连接(cross join)的连接类型,我们会在下一章中讨论它。本查询的基本思想是返回所有叫Monroe的演员(2个)与所有分级为PG的电影(194)的组合,总共388行,其中11行可以在film_actor表中找到。
4. 关联子查询
到目前为止,所有的子查询示例都是独立于包含语句的,这意味着你可以单独执行它们并查看结果。此外关联子查询依赖于包含语句并且引用其一列或多个列。与非关联子查询不同,关联子查询在执行包含语句之前不会一次执行完毕,而是对每个候选行(可能包含在最终结果中的行)执行一次。例如,下面的查询使用一个关联子查询来统计每个客户的电影租赁数量,然后包含查询将检索正好租赁了20部电影的客户:
mysql> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE 20 =-> (SELECT count(*) FROM rental r-> WHERE r.customer_id = c.customer_id);+------------+-------------+| first_name | last_name |+------------+-------------+| LAUREN | HUDSON || JEANETTE | GREENE || TARA | RYAN || WILMA | RICHARDS || JO | FOWLER || KAY | CALDWELL || DANIEL | CABRAL || ANTHONY | SCHWAB || TERRY | GRISSOM || LUIS | YANEZ || HERBERT | KRUGER || OSCAR | AQUINO || RAUL | FORTIER || NELSON | CHRISTENSON || ALFREDO | MCADAMS |+------------+-------------+15 rows in set (0.01 sec)
子查询末尾对c.customer_id的引用使子查询具有相关性,也就是说,它的执行必须依赖于包含查询提供的c.customer_id的值。在本例中,包含查询从customer表中检索所有599行数据,并为每个客户执行一次子查询,为每次执行传递相应的的客户ID。如果子查询返回值20,则满足过滤条件,并将该行添加到结果集中。
注意:由于关联子查询对包含查询的每一行执行一次,因此如果包含查询返回的行数太多,那么使用关联子查询可能会导致性能问题。
除了相等条件外,你还可以在其他类型的条件中使用相关子查询,如下是使用范围条件的例子:
mysql> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE-> (SELECT sum(p.amount) FROM payment p-> WHERE p.customer_id = c.customer_id)-> BETWEEN 180 AND 240;+------------+-----------+| first_name | last_name |+------------+-----------+| RHONDA | KENNEDY || CLARA | SHAW || ELEANOR | HUNT || MARION | SNYDER || TOMMY | COLLAZO || KARL | SEAL |+------------+-----------+6 rows in set (0.03 sec)
在上一个查询的基础上,这个变体示例检索所有电影租金总额在180美元到240美元之间的客户。同样地,关联子查询也执行599次(每个客户行一次),每次执行子查询都返回给定客户的总帐户余额。
注意
上面查询与先前查询的微妙区别是子查询位于条件的左侧,这看起来可能有点奇怪,但非常有效。
4.1 exists操作符
虽然你经常会看到应用于等式和范围条件中的关联子查询,但其实用于构建包含关联子查询的条件的最常见操作符是exists操作符。如果只考虑关系的存在性而不考虑数量问题,则可以使用exists操作符。例如,以下查询将查找在2005年5月25日之前至少租用一部影片的所有客户(不考虑租用了多少部影片):
mysql> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE EXISTS-> (SELECT 1 FROM rental r-> WHERE r.customer_id = c.customer_id-> AND date(r.rental_date) < '2005-05-25');+------------+-------------+| first_name | last_name |+------------+-------------+| CHARLOTTE | HUNTER || DELORES | HANSEN || MINNIE | ROMERO || CASSANDRA | WALTERS || ANDREW | PURDY || MANUEL | MURRELL || TOMMY | COLLAZO || NELSON | CHRISTENSON |+------------+-------------+8 rows in set (0.03 sec)
使用exists操作符,子查询可以返回零行、一行或多行结果,条件只是检查子查询是否返回一行或多行。如果你查看子查询的select子句,你将看到它由单个文本(1)组成,因为包含查询中的条件只需要知道返回了多少行,所以与子查询返回的实际数据是无关的。其实你的子查询可以返回你喜欢的任何内容,如下所示:
mysql> SELECT c.first_name, c.last_name-> FROM customer c-> WHERE EXISTS-> (SELECT r.rental_date, r.customer_id, 'ABCD' str, 2 * 3 7 nmbr-> FROM rental r-> WHERE r.customer_id = c.customer_id-> AND date(r.rental_date) < '2005-05-25');+------------+-------------+| first_name | last_name |+------------+-------------+| CHARLOTTE | HUNTER || DELORES | HANSEN || MINNIE | ROMERO || CASSANDRA | WALTERS || ANDREW | PURDY || MANUEL | MURRELL || TOMMY | COLLAZO || NELSON | CHRISTENSON |+------------+-------------+8 rows in set (0.03 sec)
但是,一般约定使用exists时指定select 1 or select *。
但你也可以使用not exists检查子查询返回行数是否是0,如下所示:
mysql> SELECT a.first_name, a.last_name-> FROM actor a-> WHERE NOT EXISTS-> (SELECT 1-> FROM film_actor fa-> INNER JOIN film f ON f.film_id = fa.film_id-> WHERE fa.actor_id = a.actor_id-> AND f.rating = 'R');+------------+-----------+| first_name | last_name |+------------+-----------+| JANE | JACKMAN |+------------+-----------+1 row in set (0.00 sec)
这个查询检索所有从未在R级电影中出现过的演员。
4.2 使用关联子查询操纵数据
到目前为止,本章中所有的示例都是select语句,但这并不意味着子查询在其他SQL语句中毫无用处。其实子查询在update、delete和insert语句中也有大量应用,特别是在update和delete语句中有频繁出现。下面的关联子查询示例修改customer表中的last_update列:
UPDATE customer cSET c.last_update =(SELECT max(r.rental_date) FROM rental rWHERE r.customer_id = c.customer_id);
此语句通过查找rental表中每个客户的最新租赁日期来修改customer表中的每一行(因为没有指定where子句)。虽然认为每个客户至少与一个电影租赁交易相关联是合情合理的,但是最好还是在运行这个update语句之前检查一下是否每个客户都有租赁过电影,否则会因为子查询不返回任何行导致last_update列的值为空值null。下面是update语句的另一个版本,但这次使用带有第二个关联子查询的where子句:
UPDATE customer cSET c.last_update =(SELECT max(r.rental_date) FROM rental rWHERE r.customer_id = c.customer_id)WHERE EXISTS(SELECT 1 FROM rental rWHERE r.customer_id = c.customer_id);
除了select子句外,这两个关联子查询是相同的。但是,set子句中的子查询仅在update语句的where子句中的条件的计算结果为true时执行(这意味着至少为客户找到了一个租赁记录),从而保护last_update列中的数据不被空值覆盖。
关联子查询在delete语句中也很常见。例如,你可以在每个月末运行一个数据维护脚本以删除无用数据。脚本可能包含以下语句,该语句从customer表中删除过去一年中没有租过电影的用户行:
DELETE FROM customerWHERE 365 < ALL(SELECT datediff(now(), r.rental_date) days_since_last_rentalFROM rental rWHERE r.customer_id = customer.customer_id);
请注意,在MySQL中使用带有delete语句的关联子查询时,不论如何都不能使用表别名,这就是为什么我在子查询中使用了表全名的原因。但是在其他大多数数据库服务器中,是可以为customer表提供别名的,例如:
DELETE FROM customer cWHERE 365 < ALL(SELECT datediff(now(), r.rental_date) days_since_last_rentalFROM rental rWHERE r.customer_id = c.customer_id);
5. 用到子查询的情况
现在你已经学习过不同类型的子查询,以及可以与子查询返回的数据进行交互的各种操作符,接下来就可以探讨使用子查询构建强大SQL语句的多种方法了。接下来的三小节将演示如何使用子查询来构造自定义表、构造条件以及在结果集中生成列值。
5.1 子查询作为数据源
我在第三章中就说过select语句中from子句的作用是包含需要查询的表。由于子查询生成的结果集包含行数据和列数据,所以完全可以在from子句中包含子查询以及表。乍一看,这似乎是一个有趣但是没什么实用价值的特性,但事实上这可能是编写查询时可用的最强大的工具之一。下面是一个简单的例子:
mysql> SELECT c.first_name, c.last_name,-> pymnt.num_rentals, pymnt.tot_payments-> FROM customer c-> INNER JOIN-> (SELECT customer_id,-> count(*) num_rentals, sum(amount) tot_payments-> FROM payment-> GROUP BY customer_id-> ) pymnt-> ON c.customer_id = pymnt.customer_id;+-------------+--------------+-------------+--------------+| first_name | last_name | num_rentals | tot_payments |+-------------+--------------+-------------+--------------+| MARY | SMITH | 32 | 118.68 || PATRICIA | JOHNSON | 27 | 128.73 || LINDA | WILLIAMS | 26 | 135.74 || BARBARA | JONES | 22 | 81.78 || ELIZABETH | BROWN | 38 | 144.62 |...| TERRENCE | GUNDERSON | 30 | 117.70 || ENRIQUE | FORSYTHE | 28 | 96.72 || FREDDIE | DUGGAN | 25 | 99.75 || WADE | DELVALLE | 22 | 83.78 || AUSTIN | CINTRON | 19 | 83.81 |+-------------+--------------+-------------+--------------+599 rows in set (0.03 sec)
在本例中,子查询生成一个客户ID列表,以及电影租赁数量和总付款额。下面是子查询生成的结果集:
mysql> SELECT customer_id, count(*) num_rentals, sum(amount) tot_payments-> FROM payment-> GROUP BY customer_id;+-------------+-------------+--------------+| customer_id | num_rentals | tot_payments |+-------------+-------------+--------------+| 1 | 32 | 118.68 || 2 | 27 | 128.73 || 3 | 26 | 135.74 || 4 | 22 | 81.78 |...| 596 | 28 | 96.72 || 597 | 25 | 99.75 || 598 | 22 | 83.78 || 599 | 19 | 83.81 |+-------------+-------------+--------------+599 rows in set (0.03 sec)
子查询的名称为pymnt,并通过customer_id列连接到customer表。然后包含查询从customer表中检索客户的名称,以及pymnt子查询中的租赁数量和总付款额。
from子句中使用的子查询必须是非关联的,它们首先执行,其数据会一直保存在内存中直到包含查询的执行完毕。子查询为查询的编写提供了极大的灵活性,因为你可以远远超出可用表的范围,几乎可以用于创建所需数据的任何视图,然后将结果连接到其他表或子查询。如果你正在为外部系统编写报告或生成数据源,则可以使用一个查询来完成任务,而这个查询通常需要多重查询或使用过程语言来完成。
5.1.1 数据加工
除了使用子查询汇总现有数据外,还可以使用子查询生成数据库中不存在的数据。例如,你可能希望按电影租金总额对客户进行分组,但希望使用数据库中未存储的组定义。例如,假设你想将客户分为下表(9-1)所示的组:
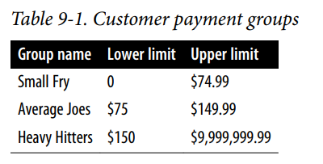
要在单个查询中生成这些组,你首先需要定义一个用于生成组定义的查询:
mysql> SELECT 'Small Fry' name, 0 low_limit, 74.99 high_limit-> UNION ALL-> SELECT 'Average Joes' name, 75 low_limit, 149.99 high_limit-> UNION ALL-> SELECT 'Heavy Hitters' name, 150 low_limit, 9999999.99 high_limit;+---------------+-----------+------------+| name | low_limit | high_limit |+---------------+-----------+------------+| Small Fry | 0 | 74.99 || Average Joes | 75 | 149.99 || Heavy Hitters | 150 | 9999999.99 |+---------------+-----------+------------+3 rows in set (0.00 sec)
上面的查询中,我使用集合操作符union all将三个独立查询的结果合并到一个结果集中。每个查询检索三个文本,三个查询的结果放在一起生成一个包含三行三列的结果集。现在你有了用于生成组的查询,接下来将它添加到另一个查询的from子句中即可:
mysql> SELECT pymnt_grps.name, count(*) num_customers-> FROM-> (SELECT customer_id,-> count(*) num_rentals, sum(amount) tot_payments-> FROM payment-> GROUP BY customer_id-> ) pymnt-> INNER JOIN-> (SELECT 'Small Fry' name, 0 low_limit, 74.99 high_limit-> UNION ALL-> SELECT 'Average Joes' name, 75 low_limit, 149.99 high_limit-> UNION ALL-> SELECT 'Heavy Hitters' name, 150 low_limit, 9999999.99 high_limit-> ) pymnt_grps-> ON pymnt.tot_payments-> BETWEEN pymnt_grps.low_limit AND pymnt_grps.high_limit-> GROUP BY pymnt_grps.name;+---------------+---------------+| name | num_customers |+---------------+---------------+| Average Joes | 515 || Heavy Hitters | 46 || Small Fry | 38 |+---------------+---------------+3 rows in set (0.03 sec)
from子句包含两个子查询:第一个子查询pymnt返回每个客户的电影租赁总数和总付款额,而第二个子查询pymnt_grps生成三个客户分组。通过查找每个客户所属的三个组中的哪一个来连接这两个子查询,然后按组名称对行进行分组,以便统计每个组中的客户数。
当然,你也可以不使用子查询,而是简单地构建一个永久(或临时)表来保存组定义。使用这种方法,你可能会在一段时间后发现数据库中到处都是这种小型专用表,并且你会忘了为什么会创建这些表。然而通过使用子查询,你就能遵守这样的原则:只有出于明确的业务目的,指明需要存储新数据时,才将表添加到数据库中。
5.1.2 面向任务的子查询
假设你希望生成一个报告,显示每个客户的姓名、所在城市、租赁总次数和总付款金额。要实现这一点,你可以使用payment、customer、address和city表,然后根据客户的名字和姓氏进行分组:
mysql> SELECT c.first_name, c.last_name, ct.city,-> sum(p.amount) tot_payments, count(*) tot_rentals-> FROM payment p-> INNER JOIN customer c-> ON p.customer_id = c.customer_id-> INNER JOIN address a-> ON c.address_id = a.address_id-> INNER JOIN city ct-> ON a.city_id = ct.city_id-> GROUP BY c.first_name, c.last_name, ct.city;+-------------+------------+-----------------+--------------+-------------+| first_name | last_name | city | tot_payments | tot_rentals |+-------------+------------+-----------------+--------------+-------------+| MARY | SMITH | Sasebo | 118.68 | 32 || PATRICIA | JOHNSON | San Bernardino | 128.73 | 27 || LINDA | WILLIAMS | Athenai | 135.74 | 26 || BARBARA | JONES | Myingyan | 81.78 | 22 |...| TERRENCE | GUNDERSON | Jinzhou | 117.70 | 30 || ENRIQUE | FORSYTHE | Patras | 96.72 | 28 || FREDDIE | DUGGAN | Sullana | 99.75 | 25 || WADE | DELVALLE | Lausanne | 83.78 | 22 || AUSTIN | CINTRON | Tieli | 83.81 | 19 |+-------------+------------+-----------------+--------------+-------------+599 rows in set (0.06 sec)
该查询返回所需的数据,但如果仔细看一下该查询,你会发现customer、address和city表仅起到描述的作用,而payment表包含生成分组(customer_id和amount)所需的所有内容。因此,你可以将生成分组的任务分离到子查询中,然后将其他三个表连接到子查询生成的表中,以获得所需的最终结果。下面是分组子查询:
mysql> SELECT customer_id,-> count(*) tot_rentals, sum(amount) tot_payments-> FROM payment-> GROUP BY customer_id;+-------------+-------------+--------------+| customer_id | tot_rentals | tot_payments |+-------------+-------------+--------------+| 1 | 32 | 118.68 || 2 | 27 | 128.73 || 3 | 26 | 135.74 || 4 | 22 | 81.78 |...| 595 | 30 | 117.70 || 596 | 28 | 96.72 || 597 | 25 | 99.75 || 598 | 22 | 83.78 || 599 | 19 | 83.81 |+-------------+-------------+--------------+599 rows in set (0.03 sec)
上面正是查询的核心。其他表(customer、address和city表)只需要提供有意义的字符串来代替customer_id值。下一个查询将上一个表连接到其他三个表:
mysql> SELECT c.first_name, c.last_name,-> ct.city,-> pymnt.tot_payments, pymnt.tot_rentals-> FROM-> (SELECT customer_id,-> count(*) tot_rentals, sum(amount) tot_payments-> FROM payment-> GROUP BY customer_id-> ) pymnt-> INNER JOIN customer c-> ON pymnt.customer_id = c.customer_id-> INNER JOIN address a-> ON c.address_id = a.address_id-> INNER JOIN city ct-> ON a.city_id = ct.city_id;+-------------+------------+-----------------+--------------+-------------+| first_name | last_name | city | tot_payments | tot_rentals |+-------------+------------+-----------------+--------------+-------------+| MARY | SMITH | Sasebo | 118.68 | 32 || PATRICIA | JOHNSON | San Bernardino | 128.73 | 27 || LINDA | WILLIAMS | Athenai | 135.74 | 26 || BARBARA | JONES | Myingyan | 81.78 | 22 |...| TERRENCE | GUNDERSON | Jinzhou | 117.70 | 30 || ENRIQUE | FORSYTHE | Patras | 96.72 | 28 || FREDDIE | DUGGAN | Sullana | 99.75 | 25 || WADE | DELVALLE | Lausanne | 83.78 | 22 || AUSTIN | CINTRON | Tieli | 83.81 | 19 |+-------------+------------+-----------------+--------------+-------------+599 rows in set (0.06 sec)
正所谓情人眼里出西施,我认为这个版本的查询比先前那个大而平的版本的查询更令人满意。该版本查询的执行速度也更快,因为分组是在单个数字列(customer_id)而不是在多个冗长的字符串列(customer.first_name,customer.last_name,city.city)上进行的。
5.1.3 公用表表达式
公用表表达式(Common table expressions,又称CTEs)是MySQL 8.0版的新特性,但其实在其他数据库服务器上已经有一段时间的历史了。CTE是出现在with子句中查询顶部的命名子查询,相互之间由逗号分隔。除了使查询更容易理解外,该特性还允许每个CTE引用在同一with子句中定义的任何其他CTE。以下示例包括三个CTE,其中第二个CTE引用第一个CTE,第三个CTE引用第二个CTE:
mysql> WITH actors_s AS-> (SELECT actor_id, first_name, last_name-> FROM actor-> WHERE last_name LIKE 'S%'-> ),-> actors_s_pg AS-> (SELECT s.actor_id, s.first_name, s.last_name,-> f.film_id, f.title-> FROM actors_s s-> INNER JOIN film_actor fa-> ON s.actor_id = fa.actor_id-> INNER JOIN film f-> ON f.film_id = fa.film_id-> WHERE f.rating = 'PG'-> ),-> actors_s_pg_revenue AS-> (SELECT spg.first_name, spg.last_name, p.amount-> FROM actors_s_pg spg-> INNER JOIN inventory i-> ON i.film_id = spg.film_id-> INNER JOIN rental r-> ON i.inventory_id = r.inventory_id-> INNER JOIN payment p-> ON r.rental_id = p.rental_id-> ) -- end of With clause-> SELECT spg_rev.first_name, spg_rev.last_name,-> sum(spg_rev.amount) tot_revenue-> FROM actors_s_pg_revenue spg_rev-> GROUP BY spg_rev.first_name, spg_rev.last_name-> ORDER BY 3 desc;+------------+-------------+-------------+| first_name | last_name | tot_revenue |+------------+-------------+-------------+| NICK | STALLONE | 692.21 || JEFF | SILVERSTONE | 652.35 || DAN | STREEP | 509.02 || GROUCHO | SINATRA | 457.97 || SISSY | SOBIESKI | 379.03 || JAYNE | SILVERSTONE | 372.18 || CAMERON | STREEP | 361.00 || JOHN | SUVARI | 296.36 || JOE | SWANK | 177.52 |+------------+-------------+-------------+9 rows in set (0.18 sec)
此查询计算级别为PG且演员包括姓氏以S开头的演员的电影的租赁操作所产生的总收入。第一个子查询(actors_S)查找姓氏以S开头的所有演员,第二个子查询(actors_s_pg)将该结果表连接到film表,并对分级为PG的电影进行过滤,第三个子查询(actors_s_pg_revenue)将该结果表连接到payment表,以检索为租用这些电影而支付的租金。最后一个查询只是将来自actors_s_pg_revenue的数据按名字/姓氏分组,并对收入进行求和操作。
注意
那些倾向于使用临时表来存储查询结果以便在后续查询中使用的人可能会发现CTE是一个有吸引力的替代方法。
5.2 子查询作为表达式生成器
这是本章的最后一节,我会继续讲解本章刚开始提到的内容:单行单列的标量子查询。除了可以用于过滤条件中,标量子查询还可以用于表达式可以出现的任何位置,包括查询中的select和order by子句以及insert语句中的values子句。
在179页的“面向任务的子查询”中,我展示了如何使用子查询将分组机制从其他查询中分离出来。下面是同一查询的另一个版本,它使用子查询实现相同的目的,但方法不同:
mysql> SELECT-> (SELECT c.first_name FROM customer c-> WHERE c.customer_id = p.customer_id-> ) first_name,-> (SELECT c.last_name FROM customer c-> WHERE c.customer_id = p.customer_id-> ) last_name,-> (SELECT ct.city-> FROM customer c-> INNER JOIN address a-> ON c.address_id = a.address_id-> INNER JOIN city ct-> ON a.city_id = ct.city_id-> WHERE c.customer_id = p.customer_id-> ) city,-> sum(p.amount) tot_payments,-> count(*) tot_rentals-> FROM payment p-> GROUP BY p.customer_id;+-------------+------------+-----------------+--------------+-------------+| first_name | last_name | city | tot_payments | tot_rentals |+-------------+------------+-----------------+--------------+-------------+| MARY | SMITH | Sasebo | 118.68 | 32 || PATRICIA | JOHNSON | San Bernardino | 128.73 | 27 || LINDA | WILLIAMS | Athenai | 135.74 | 26 || BARBARA | JONES | Myingyan | 81.78 | 22 |...| TERRENCE | GUNDERSON | Jinzhou | 117.70 | 30 || ENRIQUE | FORSYTHE | Patras | 96.72 | 28 || FREDDIE | DUGGAN | Sullana | 99.75 | 25 || WADE | DELVALLE | Lausanne | 83.78 | 22 || AUSTIN | CINTRON | Tieli | 83.81 | 19 |+-------------+------------+-----------------+--------------+-------------+599 rows in set (0.06 sec)
此查询与前面那个在from子句中使用子查询的早期查询的两个主要区别如下:
• 在select子句中使用关联标量子查询来查找客户的名字/姓氏和城市,而不是将customer、address和city表连接到payment数据。
• 三次访问customer表(三个子查询各一次),而不是一次。
customer表被访问了三次,因为标量子查询只能返回单行单列,所以如果我们需要与customer表相关的三列数据,就必须使用三个不同的子查询。
如前所述,标量子查询也可以出现在order by子句中。以下查询检索演员的名字和姓氏,并按演员参演的电影数量多少进行排序:
mysql> SELECT a.actor_id, a.first_name, a.last_name-> FROM actor a-> ORDER BY-> (SELECT count(*) FROM film_actor fa-> WHERE fa.actor_id = a.actor_id) DESC;+----------+-------------+--------------+| actor_id | first_name | last_name |+----------+-------------+--------------+| 107 | GINA | DEGENERES || 102 | WALTER | TORN || 198 | MARY | KEITEL || 181 | MATTHEW | CARREY |...| 71 | ADAM | GRANT || 186 | JULIA | ZELLWEGER || 35 | JUDY | DEAN || 199 | JULIA | FAWCETT || 148 | EMILY | DEE |+----------+-------------+--------------+200 rows in set (0.01 sec)
该查询在order by子句中使用一个关联标量子查询,只返回电影数量,该值仅用于排序目的。
除了在select语句中关联相关标量子查询外,还可以使用非关联标量子查询为insert语句生成值。例如,假设你将在film_actor表中插入新一行数据,数据如下已给出:
• 演员的名字和姓氏
• 影名
你有两个选择:一个是先执行两个查询从film和actor中检索主键值,然后将这些值放入insert语句中,另一个就是使用子查询从insert语句中直接检索这两个主键值。下面是后一种方法的示例:
INSERT INTO film_actor (actor_id, film_id, last_update)VALUES ((SELECT actor_id FROM actorWHERE first_name = 'JENNIFER' AND last_name = 'DAVIS'),(SELECT film_id FROM filmWHERE title = 'ACE GOLDFINGER'),now());
使用一条SQL语句,就可以在film_actor表中新建一行数据,同时查询两个外键值了。
6. 子查询总结
本章涉及了很多内容,所以最好回顾一下我们学习的知识。本章示例演示了子查询的以下知识点:
• 可以返回单行单列、单行多列以及多行多列
• 可以独立于包含语句(非关联子查询)
• 可以引用包含语句中的一个或多个列(关联子查询)
• 可以用在条件中,这些条件使用比较操作符以及用于特殊目的的操作符in、not in、exists和not exists
• 可以出现在select、update、delete和insert语句中
• 可以生成结果集与其他表(或子查询)连接
• 可以生成值以填充表或查询结果集中的列
• 可以用于查询的select、from、where、having和order by子句
显然,子查询是一个用途广泛的工具,因此,如果你将本章读完一遍之后还没有了解全部的概念,也请别灰心。如果你坚持尝试使用子查询的各种用法,那么你很快就能发现自己在每次编写非平凡的SQL语句时都会思考如何使用子查询来实现。


