




a) if…else…end
第4节:基础函数与表计算函数
导读:本节内容具体包括如下知识点
1.基础函数的使用:
(1)常用简单计算函数:ABS、SQRT、square
(2)常用字符串函数:contains、startswith、endswith、find、left、mid、right、len
lower、upper、replace、split
(3)常用日期函数:isdate、dateadd、datediff、year、month、day、now、today
(4)常用聚合函数:count、countd、sum、avg、median、max、min
(5)常用的两类逻辑句式:if…else…end 和case…when…end
2.表计算函数的使用
(1)index、size、rank函数
(2)running类函数
(3)window类函数
(4)详细级别表达式:数据的聚合度和颗粒度层次不同
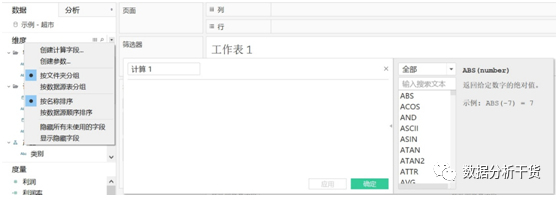
(一)Tableau的函数从哪看得到创建字段——弹出的计算字段设置框中选择向右的箭头,就可看到,然后,在“全部”的下面输入搜索文本,即可找到各种函数的含义及用法,如下图所示
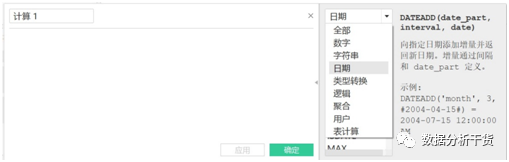
而点击“全部”,会看到函数的分类,如下图所示
(二)常用简单计算函数
1、ABS:取绝对值,如ABS(-7)=7
2、SQRT:取平方根,如SQRT(25)=5
3、square:求平方,如square(5)=25
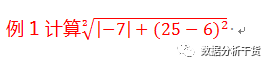
在“行”或“列”内双击两下,即可进里面写入函数进行计算。这里写入
SQRT(ABS(-7)+SQUARE(25-6))
然后点击倒三角,选择“维度”,得到计算结果为19.1833
(二)常用字符串函数
1、contains:若字符串包含子字符串返回true,如contains(“calculation”,”alcu”)为true
true也显示为1,而false则显示为0
2、startswith:字符串以子字符串开头返回true,如startswith(“calculation”,”ca”)为true
3、find:返回子字符串在字符串中的位置,如果没找到,则返回值为0,若定义了起始
数字,则从给定的起始数字开始算。示例find(“calculation”,”a”)=2,表示首个a位于第2个位置;find(“calculation”,”a”,4),表示从第4个字符开始找,找到的a位于第7个位置
4、left:返回字符串从左开始,指定个数的字符,如left(“calculation”,2)=”ca”
5、mid:返回指定的从第几个字符开始截取,截取多少个字符的字符串,若未指定截取
多长,则截取从指定字符开始至字符串结束的所有字符
示例,如mid(“calculation”,2,4)=”alcu”
6、right:返回从结尾起指定数量的字符。如right(“calculation”,4)=”tion”
7、len:返回字符长度。如len(“calculation”)=11
8、lower:返回小写,如lower(“CALCULATION”)= “calculation”
9、upper:返回大写,如upper(“calculation”)= “CALCULATION”
10、replace:将字符串中某些字符替换为另外的字符
如replace(“calculation”,”ion”,”ed”)=”calculated”
11、split:返回字符串中的子字符串,具体返回的是哪个字符串,由从字符串开头(正数)还是结尾(负数)的第几个分隔符决定。如split("a-bcde-ffe-kkf","-",2)=“bcde”
split("a-bcde-ffe-kkf","-",-2)=“ffe”
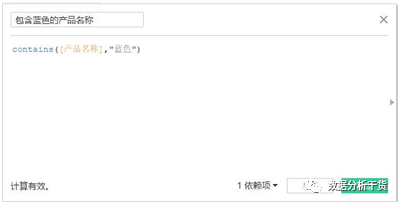
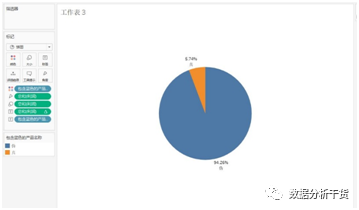
例2,找出“产品名称”中包含“蓝色的”的产品并统计含有“蓝色”的产品与其他产品的利润占比
第一步:计算字段
第二步:制作饼图
将“包含蓝色的产品名称”字段拖入“行”,将“利润”拖入列,智能显示中选择“饼图”,
并将“利润”再次拖入标签内,选择拖入标签内的“利润”的倒三角-快速表计算-合计
百分比,于是得到利润百分比,再次将“包含蓝色的产品名称”拖拽至标签,得到其
产品是否包括“蓝色”的真伪标签,见下图
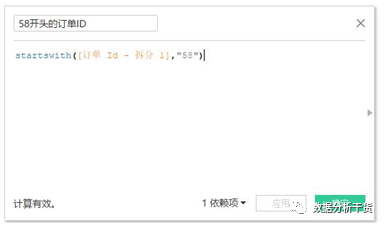
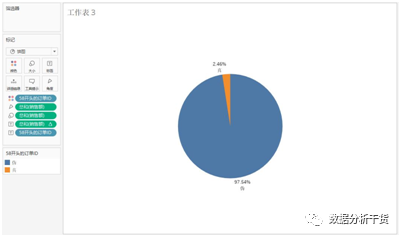
例3:从订单ID中拆分出第三部分(即最后一个“-”后面的数字),该部分为订单号,请统计
订单号前两位为“58”的订单销售额占比
第一步,拆分订单ID,拆分方法见第一节讲义
第二步:创建计算字段,见下图所示
第三步,制作饼图,制作方法同上,制作结果见下图
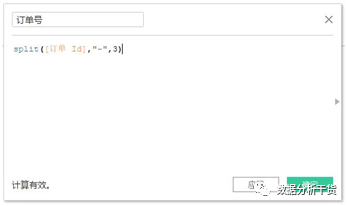
例4:使用split,从订单ID中截取出订单(即最后一个“-”后面的数字),生成“订单号”
的新字段
创建新字段,如下图所示
(三)常用日期函数
1、isdate:判断一个数据是否为有效日期,如isdate(“2004-04-15”)=True
2、dateadd:向指定日期添加增量,形成新的日期
如dateadd(“month”,3,#2004-04-15#)=2004-07-15
3、datediff:返回第二个日期减去第一个日期的差,单位为最先给定的间隔模式
如datediff(“month”,#2004-07-15#,#2004-04-15#)=-3
4、year:返回日期所在的年,如year(#2004-04-15#)=2004
5、month:返回日期所在的月,如month(#2004-04-15#)=4
6、day:返回日期所在的天,如day(#2004-04-15#)=15
7、now:返回当前时间,如now()=2020-2-11 17:48:12 pm
8、 today: 返回当前日期,如today()=2020-2-11
例5:对原有的每个订单日期都增加3个月,得到“调整后的订单日期”新字段
创建字段,如下图所示

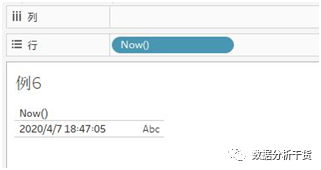
例6:返回当前时间
即在行中双击两下,然后输入“now()”,回车后即可得到当前时间
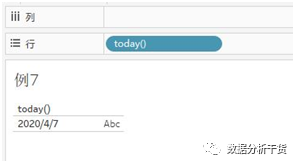
例7:返回当前日期
即在行中双击两下,然后输入“today()”,回车后即可得到当前日期
(四)常用聚合函数
对一组数据进行聚合运算。Tableau自带聚合功能,比如将类别和销售额拖拽至行和列,则自动计算各类别的销售额合计
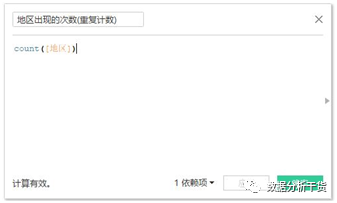
1、 count:计数,返回组的项数,如count([Customer ID])
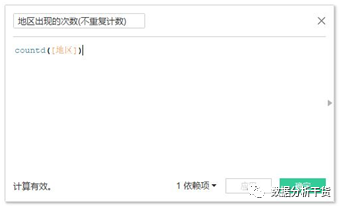
2、 countd:不重复计数,返回组中不同项的数量,每个唯一值仅计数一次,NULL不计入
如countd([region])
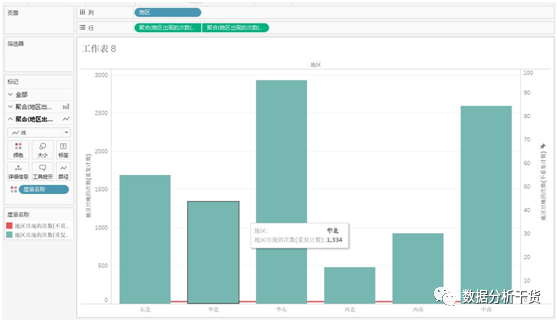
3、 sum:求和 avg:平均值 median:中位数 max:最大值 min:最小值例8:对地区进行计数和不重复计数,并对两个数值进行对比,制作线柱图
第一步:创建两个字段“地区出现的次数(不重复计数)”和“地区出现的次数(重复计数)”
第二步:制作线柱图
将“地区出现的次数(重复计数)”和“地区出现的次数(不重复计数)”依次拖拽至行,将“地区“拖拽至列,选择“地区出现的次数(不重复计数)”的下三角中的“双轴“,并将该字段的坐标轴的刻度改为”0-100“之间,将该字段的左侧”标记“下的”条形图“改为”线“
由此得到下图
 例9:计算利润的合计、平均值、中位数和最大值、最小值,并形成数据表
例9:计算利润的合计、平均值、中位数和最大值、最小值,并形成数据表
第一步:双击行,在行里输入“sum([利润])”,按回车,同理双击行,计算利润的平均值avg([利润])、中位数median([利润])、最大值max([利润])和最小值min([利润])
第二步:选择右上角的“智能显示”中的第一行第一个“工作表”,于是,得到利润在这五项指标上的数值
见下图

(五)常用的两类逻辑句式
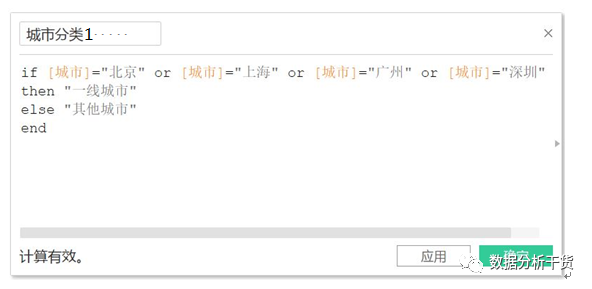
例10,对城市进行分类
北上广深作为一类,起名为“一线城市“,
其他城市作为一类,起名为“其他城市“
操作:创建字段,字段设置如下:
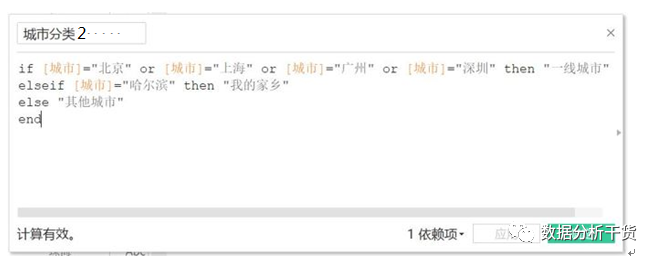
例11,对城市进行分类
北上广深作为一类,起名为“一线城市“,
哈尔滨作为一类,起名为“我的家乡”
其他城市作为一类,起名为“其他城市“
操作:创建字段,字段设置如下:
 b) case…when…end
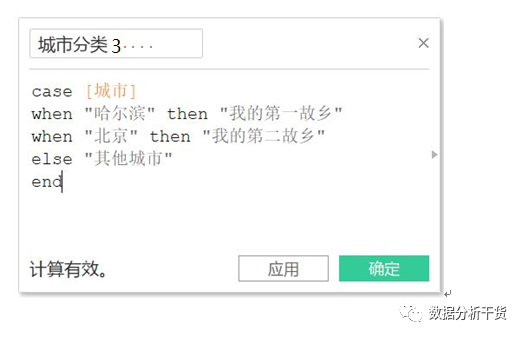
b) case…when…end例12,对城市进行分类
(1)需求:同样的城市分类
(2)操作:创建字段
二、表计算函数的使用
(一)函数介绍
1、index()与size():返回分区中当前行的索引与分区中的总行数
(1)需求:计算客户人数累计占比
(2)操作:详见第4节中帕累托图的制作
2、rank:竞争排名
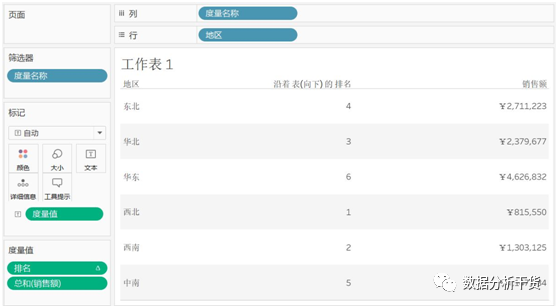
例1:对各地区销售额进行排名
操作:从创建字段的rank函数查询可知,rank是为分区中的当前行返回标准竞争排名,它适用于函数的聚合,比如rank(avg[LapTime])
创建字段,进行如下设置:
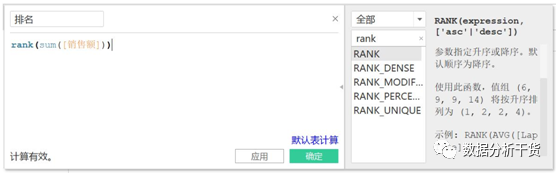
确定后,于是新增了“排名”字段。
在工作表中显示排名:
把“地区”拖拽至行
把“销售额”拖拽至文本,再把“排名”也拖拽至文本,
于是可以看到rank就是对各地区销售额总计的排名,得到结果是降序排列,换句话说rank默认为降序(由高到低,排名为1表示销售额最高,desc)排列
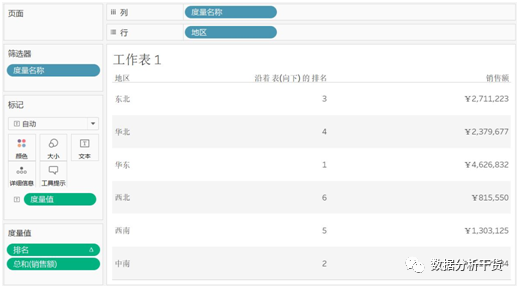
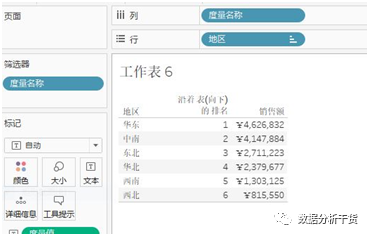
这是一般的理解,表现越好排名越靠前,但从显示来看,排名第1的并没有在前面显示,故选择菜单栏下的快捷键一栏中的按度量值升序排序,见下图

于是,得到显示结果如下
当然,也可以将排序设置为由低到高,即排名为1的表示销售额最小,从该函数的语法中可以见,使用“asc”即可,因为”asc”表示升序,排名越大销售额越高
例如,将排名字段编辑如下:
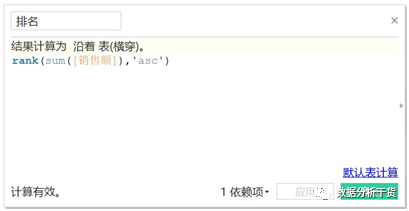
于是,排序结果如下(由低到高,最低的销售额排名为1,排名值越大表明销售额越高):
3、running类函数
包括running_avg、running_count、running_max、running_min、running_sum,
返回给定表达式从分区中的第一行到当前行的运行结果(平均值/计数/最大值/最小值/和)
显然,如果当前行是最后一行,那么得到的就是所有行的运行结果。
所以,avg、count、max、min、sum是running类相应函数的特殊形式。
running类函数适用于计算累计
4、window类函数
包括window_avg、window_count、window_max、window_min、window_sum等等,
表示返回窗口中表达式的值,窗口定义为与当前行的偏移
写作window_avg(聚合值,开始行,结束行)
使用first()+n或last()-n则表示与分区中第一行或最后一行偏移n行
如果省略了开始行和结束行,则表示整个分区。
例如,window_avg(sum[利润],-2,0)表示求出当前行前两行至当前行的sum[利润]的平均值所以,avg、count、max、min、sum也是window类相应函数的特殊形式。总之window类函数可以定义行的起止点;running类函数能定义行的止点,到当前行,而普通函数则包括所有行,起止点都不定义。
(二)函数区别:sum、running_sum、window_sum、total
例2:创建4个工作表,分别命名为sum、running_sum、window_sum和total,并分别在这四个工作表中分别计算分子类别、分地区的销售额sum、销售额running_sum、销售额window_sum和销售额total,理解这四个函数计算结果的区别
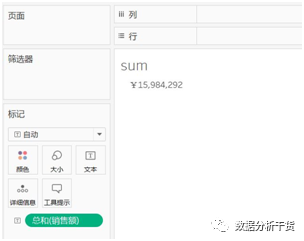
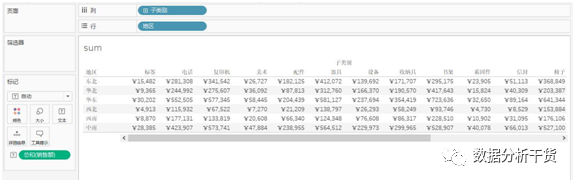
1、sum:返回给定表达式中所有值的总计
只要把一个度量字段,比如“销售额”拖拽到文本,就可以得到sum。见下图
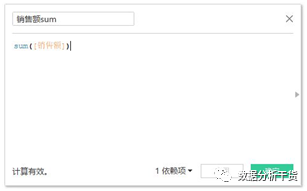
或者我们创建新字段“销售额sum”,创建如下图,也可以得到sum值
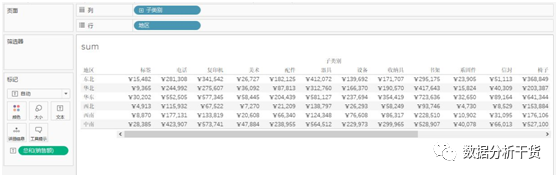
新建一个工作表,在该工作表中,将“地区”拖拽至行,“子类别”拖拽至列,将销售额拖拽至文本,于是得到表格,从该表格中可见,在表格中使用sum所求出的销售额是对应某地区某子类别的销售额。
2、total:返回给定表达式的总计
同理创建销售额total的字段,并在新的工作表构造不同子类别、不同地区的销售额total表
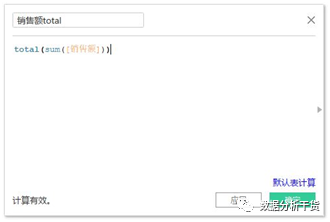
建立各地区、各子类别的销售额表格后发现,total所计算的是所选定的区域(比如本例中选的是横穿,也就是所选区域为行)的合计,因此会发现同一个地区内,所有子类别的销售额都是相同的,是各地区汇总的结果
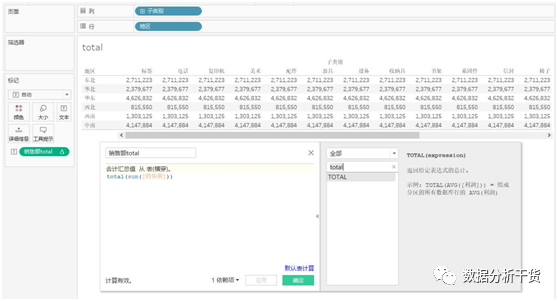
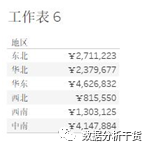
比对各地区汇总结果
同理,选择标记下的“销售额”的下三角的计算依据为“表(向下)”就会得到列(即子类别)上的汇总,见下图
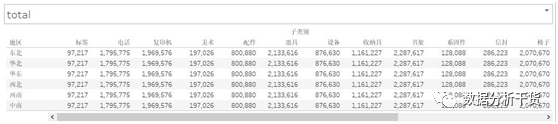
同理,选择标记下的“销售额”的下三角的计算依据为“表(横穿然后向下)”或者是“表(向下然后横穿)”就会得到总计,见下图
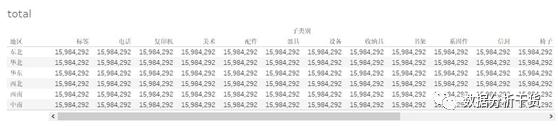
因此,total就是求指定区域的合计的,有三种可能的值:行汇总、列汇总和全部汇总
3、window_sum:返回窗口中表达式的总计。窗口用与当前行的偏移定义。使用first()+n和last()-n表示与分区中第一行或最后一行的偏移
首先创建销售额window_sum,如下图所示
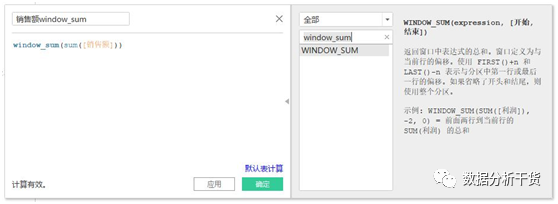
于是得到销售额window_sum的字段,在创建过程中该函数,可见该函数返回的是窗口表达式总和,如果省略了开头和结尾,就是使用了整个分区。
在这里销售额window_sum就省略了开头和结尾,接下来检验一下是否得到的结果就是整个分区的合计。
将“子类别”和“地区”分别拖拽至“列”和“行”,然后将销售额拖拽至“文本”,销售额下三角处选择表(横穿),于是得到结果与销售额total 在表(横穿)的一样,而如果下三角处选择表(向下)或表(横穿然后向下)或表(向下然后横穿)得到的都与销售额total一致,即都有三种可能结果:行汇总、列汇总和全部汇总
但window_sum与total不同的是,total对该分区中所包括的起止计算元素不能设置,而window_sum则可以。
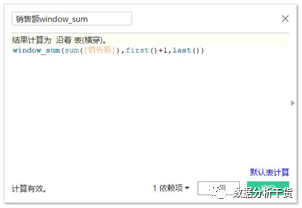
例如对销售额window_sum的字段进行改写,使之从第二项开始计算(即分区中第一行设为first()+1),一直加到最后一项(即分区中的最后一行设为last()),见下图,且下三角处选择的是表(横穿),于是得到的结果如下
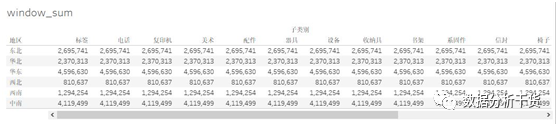
可以看到计算结果虽然也是沿行汇总,但数值变小,比如东北地区的汇总值2695741,比行合计2711223少了15482,由前可知,15482正是第1项“标签”的销售额,由此知,window_sum对分区的合计是可以指定起止点的,要比total更为灵活
4、running_sum:返回给定表达式从分区中第一行到当前行的运行总计,该数值是一个逐渐累加的过程。我们通过以下操作来理解:
首先,创建“销售额running_sum”字段
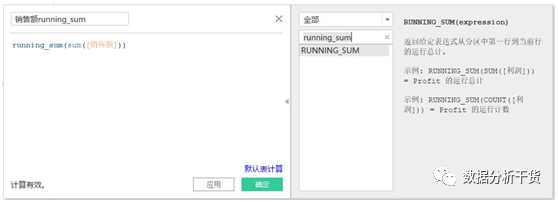
将“子类别”和“地区”分别拖拽至“列”和“行”,然后将销售额拖拽至“文本”,销售额下三角处选择表(横穿),于是得到如下结果:
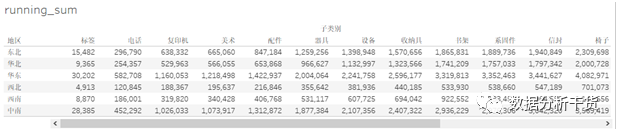
把这个结果,和使用sum计算的各子类别在各地区上的销售额的表现数值(见下图)比较
以东北地区为例,两者在第一项“标签”上的销售额是相同的,都是15482,但“电话”的实际销售额为281308,而running_sum计算的结果却是296790,两者差刚好是15482,“标签”的销售额,由此可知running_sum是在指定的区域内逐渐实现累加的,比如第二项“电话”的running_sum就是标签和电话的销售额的累计,第三项”复印机”的running_sum则是“标签“、
”电话“和”复印机“销售额累计。
由此可知区别如下:
Sum:计算合计,会根据对比维度来进行相应的调整,比如计算了销售额sum,若比较地区,得到的结果就是某地区销售额合计,和其他地区销售额合计的对比Running_sum:计算的是某个指定区域内第一行到当前行的逐渐累加
Total:计算的是某个指定区域内的合计,只有三种情况:行汇总、列汇总、全部汇总,不能对合计的起始点进行设置Window_sum: 计算的是某个指定区域内的合计,可以对合计的起始点进行设置。
(三)详细级别表达式
1、数据的聚合度和颗粒度
所谓详细级别表达式就是LOD(level of detail)表达式,数据聚合度和颗粒度层次不同。
什么是数据聚合度和颗粒度呢?聚合度反映的是汇总程度,而颗粒度反映的是细节程度
举个例子:
例如,现在求销售额的合计,即你把销售额sum拖拽至文本,得到所有产品的销售额合计为15984292 。这个数值把不同时间、不同子类别、不同地区的销售额都汇聚到了一个数值点上,所以它的聚合度很高。但相应的,由于这个数值只有一个数值点,反映的信息太少了,不能反映细节,因此颗粒度很小。但是如果现在统计的是分地区的销售额,显然聚合度降低了,因为没有各地区销售额合计的汇总程度高,但是它却能反映各地区销售额差异的细节,所以颗粒度升高了。
换句话说,聚合度和颗粒度是反向的,聚合度越高则表明综合性越强,那么细节反映就差,颗粒度就小。再比如,大家想我现在统计这个超市的销售额,按年统计,和按天统计,两者的数据聚合度和颗粒度有何区别呢?和按天统计相比,按年统计的综合性,所以数据聚合度更高,但却无法像按天统计那样可以反映销售额的细节变化,因此颗粒度较低。
2、fixed函数的涵义
从创建字段里查找fixed函数,会得到该函数的作用是——使用指定的维度计算聚合。它的语法是{Fixed [指定的维度1],[指定的维度2],…,[指定的维度n]:聚合函数[聚合对象]},其中:{}反映的是数组概念,因为如果指定维度,最后聚合出来的结果不是一个数值,而是一组数值。
例如,想求分年份、分地区、分产品的销售额合计,就可以写成:{Fixed [year],[area],[products]:sum[sales]}再比如,想求分年份、分地区的销售额合计,就可以写成:{Fixed [year],[area]:sum[sales]}再比如,想求分年份的销售额合计,就可以写成{Fixed [year]:sum[sales]}而如果不指定维度,就只想求全局的销售额合计,就可以写成{Fixed:sum[sales]}:可简写为{sum[sales]}
3、fixed函数操作与效果对比
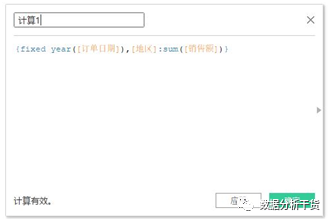
例3:按照订单日期字段中的年的维度和地区维度来聚合销售额的总计
第一步:创建字段,创建方法见下图
第二步:把“计算1“这个字段拖拽到”文本“中,即可得出销售额合计15984292
第三步:继续把“类别“拖到行,发现不管是哪个类别,得到的结果都是销售额合计15984292。这个数值把不同时间、不同子类别、不同地区的销售额都汇聚到了一个数值行统计。这是因为我们在fixed函数中并没有把“类别“作为其指定维度
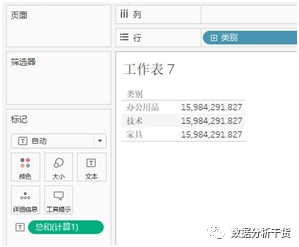
那么如果按照fixed指定维度进行统计会是什么样,因此来做第四步。
第四步:去掉“类别“,将”地区“拖拽至行,于是得到下表
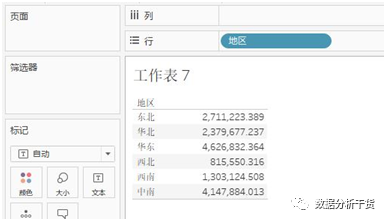
可以看到,此时销售额就按照地区的不同做计算了
由此得出,fixed函数得到的结果,只会按照fixed函数中的指定维度进行自动分区
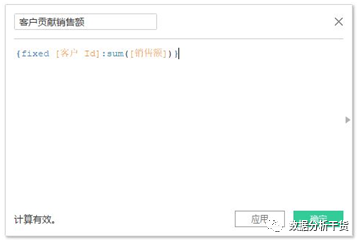
例4:计算不同客户的销售贡献
第一步:创建字段,如下图所示
第二步:将“客户贡献销售额“拖拽至文本,将”客户ID“(若在维度中看不到,右键空白区域“显示“隐藏字段,然后点击”客户ID“后面的下三角,选择”取消隐藏“)拖拽至行,于是得到按客户ID统计的销售额。见下图
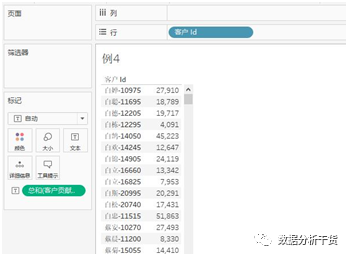
Fixed函数的意义在于计算出指定维度的字段,为后续统计分析奠定基础。
例5:计算客户最近一次下单的时间距离当前时间的间隔R
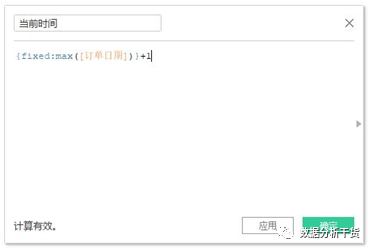
第一步:创建计算字段 #当前时间#={fixed:max([订单日期])}+1,+1是为了避免0值的出现
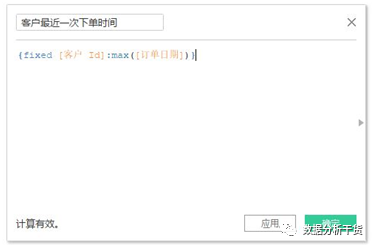
第二步:创建计算字段#客户最近一次下单时间#={fixed[客户ID]:max([订单日期])}
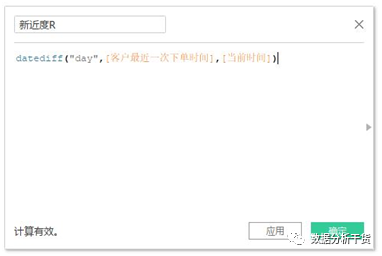
第三步:计算新近度R值:
#新进度R#=DATEDIFF(“day”,#客户最近一次下单时间#, #当前时间#)
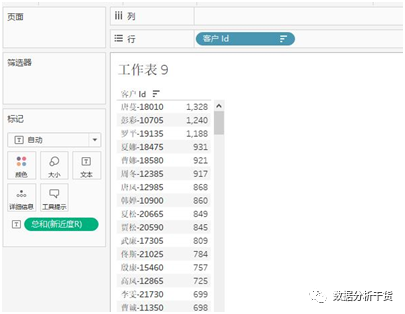
第四步:将“客户ID“拖拽至行,将”新近度“拖拽至文本,于是得到不同的客户最后一次购物时间距离当前时间的间隔,显然间隔越长,表明该客户越久没有光顾了,该客户就越有可能成为流失客户

● SQL从入门到精通
● 想成为数据分析师,这些书必看!
● 不用敲代码,利用它就可以轻松爬取数据
发现更多精彩
关注公众号


你点的每个在看,我都认真当成了喜欢

笔记链接:https://pan.baidu.com/s/1sYW1BUO9GrLYJyz7SGPG1w
提取码:a0fh
