





如果执行某个查询只需要访问单个分区或少量分区,而不是查询整个表,那么查询性能可以得到显著的提高。
如果将插入和更新路由到单个分区,那么由于是在单个分区上使用了顺序扫描,而不是在整个表上进行索引或随机扫描,性能也可以得到显著提高。
批量加载和删除可以通过添加或删除分区来完成
当数据在逻辑上被划分为多个小表时,可以很方便得管理大表
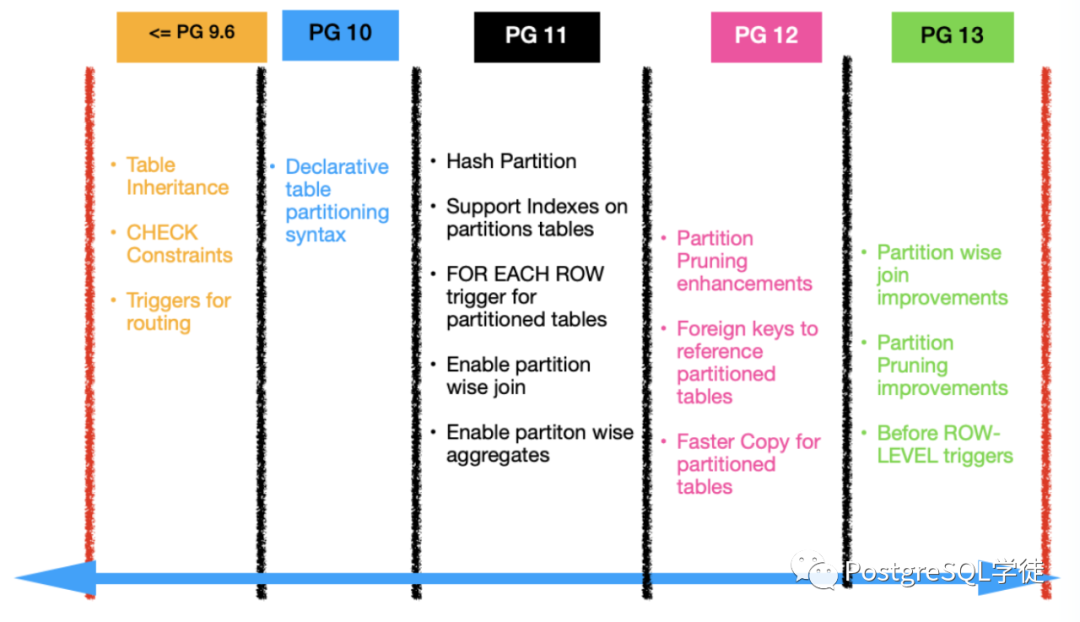
Improve cases where pruning of partitions can happen (Yuzuko Hosoya, Amit Langote, Álvaro Herrera)
Allow partitionwise joins to happen in more cases (Ashutosh Bapat, Etsuro Fujita, Amit Langote, Tom Lane) – For example, partitionwise joins can now happen between partitioned tables even when their partition bounds do not match exactly.
Allow BEFORE row-level triggers on partitioned tables (Álvaro Herrera) – These triggers cannot change which partition is the destination.
Allow partitioned tables to be logically replicated via publications (Amit Langote)
Allow logical replication into partitioned tables on subscribers (Amit Langote) – Previously, subscribers could only receive rows into non-partitioned tables.
Allow ROW values to be used as partitioning expressions (Amit Langote)
可以分区裁剪的case增多
智能分区join增强
支持before trigger(但不允许改变插入数据的目标分区)
之前只能把分区表的各个分区单独做为复制源,现在可以把分区表直接做为复制源。
先前订阅者只能把数据同步到非分区表,现在可以把数据同步到分区表
支持异构分区表逻辑复制: http://www.postgres.cn/v2/news/viewone/1/604
Allow whole-row variables (that is, table.*) to be used in partitioning expressions (Amit Langote)
postgres=# drop table foo;DROP TABLEpostgres=# CREATE TABLE foo (x int, y date, z int) PARTITION BY RANGE(y);CREATE TABLEpostgres=# CREATE TABLE foo_p1 PARTITION OF foo FOR VALUES FROM ('2006-02-01') TO ('2006-03-01');CREATE TABLEpostgres=# CREATE TABLE foo_p2 PARTITION OF foo FOR VALUES FROM ('2006-03-01') TO ('2006-04-01');CREATE TABLEpostgres=# CREATE TABLE foo_p3 PARTITION OF foo FOR VALUES FROM ('2006-04-01') TO ('2006-05-01');CREATE TABLEpostgres=# drop table foo2;DROP TABLEpostgres=# CREATE TABLE foo2 (x int, y int, z date) PARTITION BY RANGE(z);CREATE TABLEpostgres=# CREATE TABLE foo2_p1 PARTITION OF foo2 FOR VALUES FROM ('2006-02-01') TO ('2006-03-01');CREATE TABLEpostgres=# CREATE TABLE foo2_p2 PARTITION OF foo2 FOR VALUES FROM ('2006-03-01') TO ('2006-04-01');CREATE TABLEpostgres=# postgres=# set enable_partitionwise_join TO true;SET
postgres=# explain (costs off)postgres-# select * from foo f1, foo2 f2 where f1.y = f2.z and f2.z between ('2006-02-01') and ('2006-05-01'); QUERY PLAN ---------------------------------------------------------------------------------------Hash Join Hash Cond: (f1.y = f2.z) -> Append -> Seq Scan on foo_p1 f1 -> Seq Scan on foo_p2 f1_1 -> Seq Scan on foo_p3 f1_2 -> Hash -> Append -> Seq Scan on foo2_p1 f2 Filter: ((z >= '2006-02-01'::date) AND (z <= '2006-05-01'::date)) -> Seq Scan on foo2_p2 f2_1 Filter: ((z >= '2006-02-01'::date) AND (z <= '2006-05-01'::date))(12 rows)
postgres=# explain (costs off)postgres-# select * from foo f1, foo2 f2 where f1.y = f2.z and f2.z between ('2006-02-01') and ('2006-05-01'); QUERY PLAN ---------------------------------------------------------------------------------------Append -> Hash Join Hash Cond: (f1_1.y = f2_1.z) -> Seq Scan on foo_p1 f1_1 -> Hash -> Seq Scan on foo2_p1 f2_1 Filter: ((z >= '2006-02-01'::date) AND (z <= '2006-05-01'::date)) -> Hash Join Hash Cond: (f1_2.y = f2_2.z) -> Seq Scan on foo_p2 f1_2 -> Hash -> Seq Scan on foo2_p2 f2_2 Filter: ((z >= '2006-02-01'::date) AND (z <= '2006-05-01'::date))(13 rows)
create table t1(id int) partition by range(id);create table t1_p1 partition of t1 for values from (0) to (100);create table t1_p2 partition of t1 for values from (150) to (200);create table t2(id int) partition by range(id);create table t2_p1 partition of t2 for values from (0) to (50);create table t2_p2 partition of t2 for values from (100) to (175);
explain select * from t1, t2 where t1.id=t2.id;

create table p (a int) partition by list (a);create table p1 partition of p for values in (1);create table p2 partition of p for values in (2);set enable_partitionwise_join to on;

postgres=# create or replace function trigfunc() returns trigger language plpgsql as $$ begin new.y := new.y + 1; return new; end $$;CREATE FUNCTIONpostgres=# postgres=# create trigger brtrig before insert on foo for each row execute function trigfunc();ERROR: "foo" is a partitioned tableDETAIL: Partitioned tables cannot have BEFORE / FOR EACH ROW triggers.
postgres=# create or replace function trigfunc() returns trigger language plpgsql as $$ begin new.y := new.y + 1; return new; end $$;CREATE FUNCTIONpostgres=# create trigger brtrig before insert on foo for each row execute function trigfunc();CREATE TRIGGERThe statement below shows that the trigger causes the row to move to another partition and it results in an error. The before ROW trigger function is called on partition table which causes moving the row to another partition and results in an error.postgres=# insert into foo(y) values ('2006-02-28');ERROR: moving row to another partition during a BEFORE FOR EACH ROW trigger is not supportedDETAIL: Before executing trigger "brtrig", the row was to be in partition "public.foo_p1".
postgres=# create publication pub for table foo;ERROR: "foo" is a partitioned tableDETAIL: Adding partitioned tables to publications is not supported.HINT: You can add the table partitions individually.The publication would be created on the individual partitions :postgres=# create publication pub for table foo_p1, foo_p2;CREATE PUBLICATIONpostgres=# \dRp+ pub Publication pub Owner | All tables | Inserts | Updates | Deletes | Truncates -----------+------------+---------+---------+---------+-----------ahsanhadi | f | t | t | t | tTables: "public.foo_p1" “public.foo_p2"
postgres=# create publication pub_root for table foo with (publish_via_partition_root = true);CREATE PUBLICATIONpostgres=# \dRp+ pub_root Publication pub_root Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root -----------+------------+---------+---------+---------+-----------+----------ahsanhadi | f | t | t | t | t | tTables: "public.foo"
PostgreSQL 14 also introduces the ability to leverage query parallelism when querying remote databases using foreign data wrappers. The PostgreSQL foreign data wrapper, postgres_fdw, added support for this in PostgreSQL 14 when the async_capable flag is set. postgres_fdw also supports bulk inserts and can import table partitions using IMPORT FOREIGN SCHEMA and can now execute TRUNCATE on foreign tables.
This release also has several improvements to the partitioning system, including performance gains when updating or deleting rows on tables where only a few partitions are affected. In PostgreSQL 14, partitions can now be detached in a non-blocking manner using the ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY command.
PostgreSQL 14 makes numerous improvements to VACUUM, with optimizations geared towards indexes. Autovacuum now analyzes partitioned tables and can propagate information about row counts to parent tables. There are also performance gains in ANALYZE that can be controlled with maintenance_io_concurrency parameter.
The REINDEX command can now process all of the child indexes of a partitioned table, and PostgreSQL 14 adds the pg_amcheck utility to help check for data corruption.
更新和删除只涉及到少量分区表时,性能提高
Autovacuum现在analyze分区子表,并将row行统计信息反馈到父表,另外同样可以通过调整maintenance_io_concurrency异步IO参数调优。
支持非阻塞的ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY
支持 reindex concurrently,如下:
=$ CREATE TABLE users ( id int8 generated always AS IDENTITY PRIMARY KEY, username text NOT NULL) partition BY range (id);=$ CREATE INDEX q ON users (username);=$ CREATE TABLE users_0 partition OF users FOR VALUES FROM (0) TO (10);=$ CREATE TABLE users_1 partition OF users FOR VALUES FROM (10) TO (20);=$ CREATE TABLE users_2 partition OF users FOR VALUES FROM (20) TO (30);
$ reindex (verbose) INDEX concurrently q;ERROR: REINDEX IS NOT yet implemented FOR partitioned indexes
$ reindex (verbose) INDEX concurrently users_0_username_idx;INFO: INDEX "z.users_0_username_idx" was reindexedDETAIL: CPU: USER: 0.00 s, system: 0.00 s, elapsed: 0.01 s.REINDEX$ reindex (verbose) INDEX concurrently users_1_username_idx;INFO: INDEX "z.users_1_username_idx" was reindexedDETAIL: CPU: USER: 0.00 s, system: 0.00 s, elapsed: 0.01 s.REINDEX$ reindex (verbose) INDEX concurrently users_2_username_idx;INFO: INDEX "z.users_2_username_idx" was reindexedDETAIL: CPU: USER: 0.00 s, system: 0.00 s, elapsed: 0.01 s.REINDEX
$ reindex (verbose) INDEX concurrently q;INFO: INDEX "public.users_0_username_idx" was reindexedDETAIL: CPU: USER: 0.00 s, system: 0.00 s, elapsed: 0.02 s.INFO: INDEX "public.users_1_username_idx" was reindexedDETAIL: CPU: USER: 0.00 s, system: 0.00 s, elapsed: 0.00 s.INFO: INDEX "public.users_2_username_idx" was reindexedDETAIL: CPU: USER: 0.00 s, system: 0.00 s, elapsed: 0.00 s.REINDEX

Really nice, great work and thanks to all involved. I hope that the next steps will be:Support automatic partition creation for range partitioningSupport automatic partition creation on the fly when data comes in, which requires a new partition. In the thread this is referenced as “dynamic” partitioning and what is implemented here is referenced as “static” partitioning
CREATE TABLE tbl_list (i int) PARTITION BY LIST (i)CONFIGURATION (values in (1, 2), (3, 4) DEFAULT PARTITION tbl_default);
HASH and RANGE partitioning schemes;
目前支持range , hash分区
Partitioning by expression and composite key;
Both automatic and manual partition management;
支持自动分区管理(通过函数接口创建分区,自动将主表数据迁移到分区表),或手工分区管理(通过函数实现,将已有的表绑定到分区表,或者从分区表剥离
Support for integer, floating point, date and other types, including domains;
支持的分区字段类型包括int, float, date, 以及其他常用类型,包括自定义的domain。
Effective query planning for partitioned tables (JOINs, subselects etc);
RuntimeAppend & RuntimeMergeAppend custom plan nodes to pick partitions at runtime;
PartitionFiltert drop-in replacement for INSERT triggers;
PartitionRouter and PartitionOverseer for cross-partition UPDATE queries (instead of triggers);
Automatic partition creation for new INSERTed data (only for RANGE partitioning);
支持自动新增分区,目前仅支持range分区表。
Improved COPY FROM statement that is able to insert rows directly into partitions;
User-defined callbacks for partition creation event handling;
Non-blocking concurrent table partitioning;
FDW support (foreign partitions);
Various GUC toggles and configurable settings.
Partial support of declarative partitioning (from PostgreSQL 10).
CREATE TABLE measurement ( city_id int not null, logdate date not null, peaktemp int, unitsales int ); CREATE OR REPLACE FUNCTION new_partition_creator() RETURNS trigger AS $BODY$ DECLARE partition_date TEXT; partition TEXT; partition_day int; startdate date; enddate date; BEGIN partition_day := to_char(NEW.logdate,'DD'); partition_date := to_char(NEW.logdate,'YYYY_MM'); IF partition_day < 15 THEN partition := TG_RELNAME || '_' || partition_date || '_p1'; startdate := to_char(NEW.logdate,'YYYY-MM-01'); enddate := date_trunc('MONTH', NEW.logdate) + INTERVAL '1 MONTH - 1 day'; ELSE partition := TG_RELNAME || '_' || partition_date || '_p2'; startdate := to_char(NEW.logdate,'YYYY-MM-15'); enddate := date_trunc('MONTH', NEW.logdate) + INTERVAL '1 MONTH - 1 day'; END IF; IF NOT EXISTS(SELECT relname FROM pg_class WHERE relname=partition) THEN RAISE NOTICE 'A partition has been created %',partition; EXECUTE 'CREATE TABLE ' || partition || ' ( CHECK ( logdate >= DATE ''' || startdate || ''' AND logdate <= DATE ''' || enddate || ''' )) INHERITS (' || TG_RELNAME || ');'; EXECUTE 'CREATE INDEX ' || partition || '_logdate ON ' || partition || '(logdate)'; EXECUTE 'ALTER TABLE ' || partition || ' add primary key(city_id);'; END IF; EXECUTE 'INSERT INTO ' || partition || ' SELECT(' || TG_RELNAME || ' ' || quote_literal(NEW) || ').* RETURNING city_id;'; RETURN NULL; END; $BODY$LANGUAGE plpgsql VOLATILECOST 100; CREATE TRIGGER testing_partition_insert_trigger BEFORE INSERT ON measurement FOR EACH ROW EXECUTE PROCEDURE new_partition_creator(); postgres=# insert into measurement values(1,'2017-10-11',10,10); NOTICE: A partition has been created measurement_2017_10_p1 INSERT 0 0
Automatic partitioning script for PostgreSQL v9.1+This single script can automatically add new date range partitions to tables automatically. Supported plans are year, month, week, day, hour.pg_party.sh uses a tables(pg_party_config, pg_party_config_ddl) and a functions(pg_party_date_partition, pg_party_date_partition_native) to add new partitions
PostgreSQL11: 分区表增加哈希分区
PostgreSQL11:分区表支持创建主键、外键、索引、触发器
PostgreSQL11: 分区表支持UPDATE分区键,如果在分区表上创建了一个索引,PostgreSQL 自动为每个分区创建具有相同属性的索引。
PosgtreSQL 11 支持为分区表创建一个默认(DEFAULT)的分区
对于 PostgreSQL 10 中的分区表,无法创建引用其他表的外键约束。PostgreSQL 11 解决了这个限制,可以创建分区表上的外键。
在 PostgreSQL 10 中,分区上的索引需要基于各个分区手动创建,而不能基于分区的父表创建索引。PostgreSQL 11 可以基于分区表创建索引。如果在分区表上创建了一个索引,PostgreSQL 自动为每个分区创建具有相同属性的索引。
PostgreSQL 12后:ALTER TABLE ATTACH PARTITION不会阻塞查询








新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
https://www.postgresqlchina.com
中国PostgreSQL分会生态产品
https://www.pgfans.cn
中国PostgreSQL分会资源下载站
https://www.postgreshub.cn


点击此处阅读原文
↓↓↓
