




6月9日下午五点多,收拾东西准备下班了,突然有个客户联系我说他们的一个批量存在性能问题,现在已经卡死了,客户反馈说这个批量包含多个存储过程,平时是每天早上6点左右开始跑,一般到下午1点左右能完成,但今天已经下午五点了,卡在了第二个存储过程上,一直跑不完,需要排查下是什么原因。
远程连上,开始排查:
先看看当前数据库正在干什么:
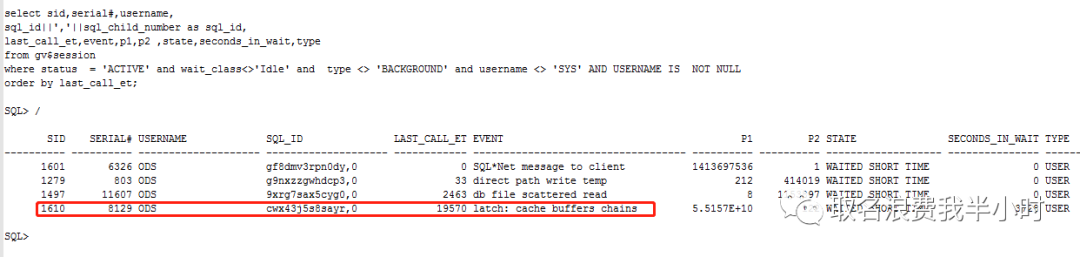
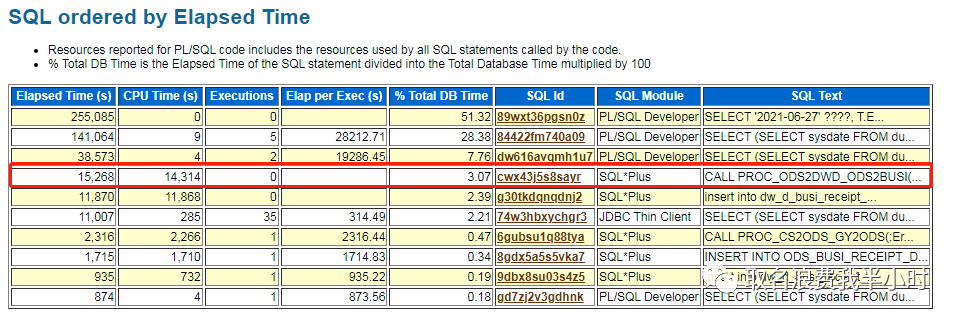
可以看到cwx43j5s8sayr这条sql已经执行了19570秒,也就是快6个小时了,然后我们再结合11点-16点的awr报告,发现这条sql正是客户说的第二个存储过程PROC_ODS2DWD_XXXXXX。再回到存储过程性能问题的排查上了,心想着简单啊,通过dba_objects查出存储过程的object_id,然后用object_id关联v$active_session_history视图中的plsql_entry_object_id字段,再结合sql_exec_start,max(sample_time),最后再框一个时间范围做个简单的计算就能知道这个存储过程下面所有sql的执行时间,排个序不就知道哪条sql最耗时吗。
嗯,就是这样,然而当我写好sql语句查询的时候,傻眼了,客户的这个数据库是10.2.0.4单实例,10g的v$active_session_history是没有sql_exec_start列的,当时我查了一下结果是这样的:
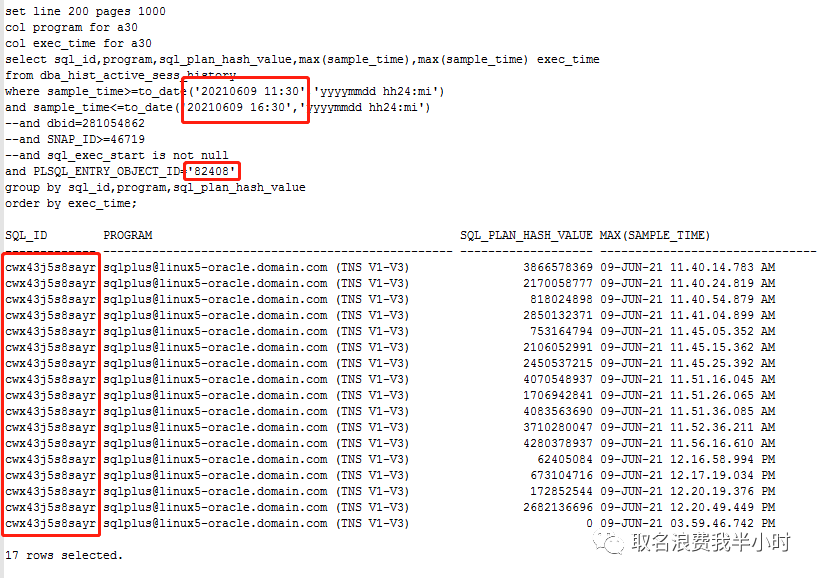
没有任何卵用,这个方法不可行,然后我又跟客户沟通,能不能把存储过程的文本给发过来,我直接从文本中找到问题sql,但客户说存储过程文本实在太长了没法看,并且里面都是各种语句的拼接,根本看不到一个完整的sql语句,想想还是算了吧。
到这里咋办呢?现在可以猜测到是这个存储过程中当前正在跑的sql存在性能问题,但是如果拿不到当前正在跑的sql,就进行不下去了啊。
到这里总结一下,一个存储过程在执行过程中卡死了,原因未知,现在已经掌握的信息有存储过程的名字和这个会话的sid,以及serial#,根据这些信息我怎么知道当前正在跑什么sql语句呢?答案是做一个进程的dump。
select spid from v$process where addr=(select paddr from v$session where sid=1610); ---查出来结果为2957 oradebug setospid 2957 oradebug dump errorstack 3 oradebug tracefile_name |
然后查看trace文件,如下:
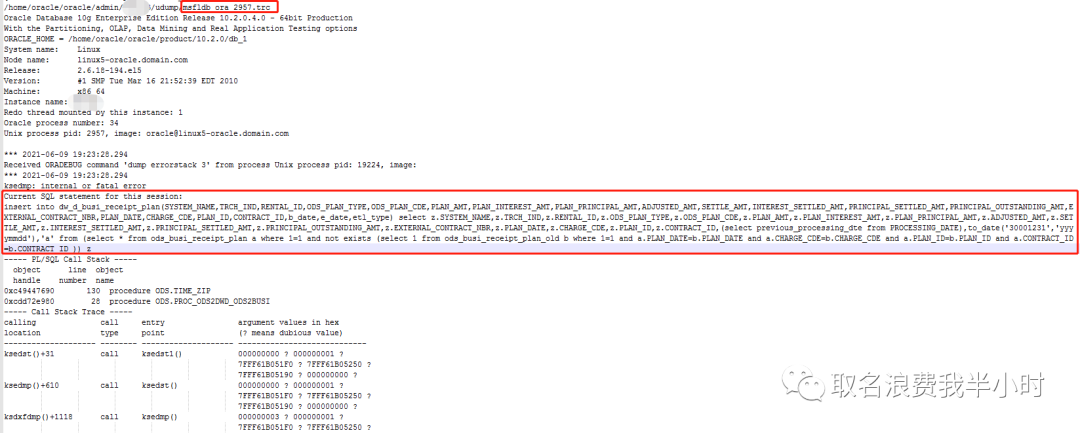
可以看到trace文件中有Current SQL statement for this session,至此定位到了当前正在跑的sql语句,具体文本如下:
insert into dw_d_busi_xxxxxx (SYSTEM_NAME, TRCH_IND, RENTAL_ID, ODS_PLAN_TYPE, ODS_PLAN_CDE, PLAN_AMT, PLAN_INTEREST_AMT, PLAN_PRINCIPAL_AMT, ADJUSTED_AMT, SETTLE_AMT, INTEREST_SETTLED_AMT, PRINCIPAL_SETTLED_AMT, PRINCIPAL_OUTSTANDING_AMT, EXTERNAL_CONTRACT_NBR, PLAN_DATE, CHARGE_CDE, PLAN_ID, CONTRACT_ID, b_date, e_date, etl_type) select z.SYSTEM_NAME, z.TRCH_IND, z.RENTAL_ID, z.ODS_PLAN_TYPE, z.ODS_PLAN_CDE, z.PLAN_AMT, z.PLAN_INTEREST_AMT, z.PLAN_PRINCIPAL_AMT, z.ADJUSTED_AMT, z.SETTLE_AMT, z.INTEREST_SETTLED_AMT, z.PRINCIPAL_SETTLED_AMT, z.PRINCIPAL_OUTSTANDING_AMT, z.EXTERNAL_CONTRACT_NBR, z.PLAN_DATE, z.CHARGE_CDE, z.PLAN_ID, z.CONTRACT_ID, (select previous_processing_dte from PROCESSING_DATE), to_date('30001231', 'yyyymmdd'), 'a' from (select * from ods_busi_xxxxxx a where 1 = 1 and not exists (select 1 from ods_busi_xxxxxx_old b where 1 = 1 and a.PLAN_DATE = b.PLAN_DATE and a.CHARGE_CDE = b.CHARGE_CDE and a.PLAN_ID = b.PLAN_ID and a.CONTRACT_ID = b.CONTRACT_ID)) z; |
查询sql_id:
| select sql_id,sql_text from v$sqlarea where sql_text like '%insert into dw_d_busi_xxxxxx(SYSTEM_NAME%'; ---g30tkdqnqdnj2 |
查看执行计划,如下:
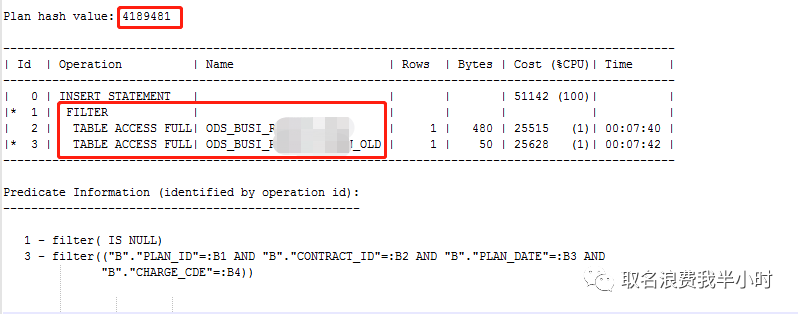
执行计划中相关表的信息如下:
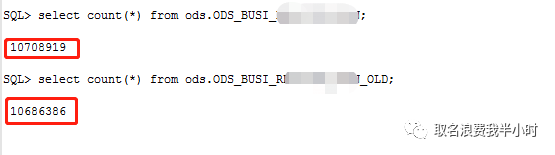
两张表的数据量都在1000万出头,但却走了filter类型的执行计划,这就意味着执行计划第二步返回10708919条记录,执行计划第三步要被执行10708919次,也就是说要对ODS_BUSI_XXXXXX_OLD表(1000多万条记录)全表扫描1000多万次,走了这么个执行计划不卡就怪了。
接下来我们去掉insert,再来看看执行计划,如下:
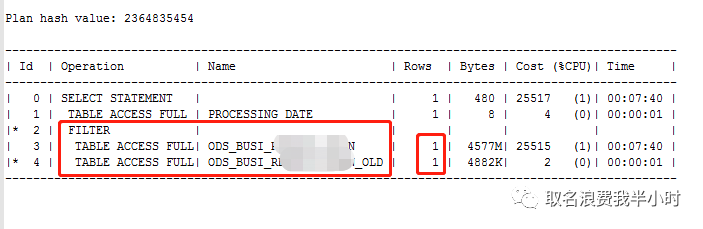
以前就讨论过虽然filter有时候性能特别差,但也不总是一无是处,比如这里执行计划第三步oracle评估的是一行,如果真是这样,那么这里走filter类型的执行计划完全没问题,但是ODS_BUSI_XXXXXX表明明有1000多万条记录,oracle为什么只评估一行呢?接下来我们来看看ODS_BUSI_XXXXXX表的统计信息收集情况:
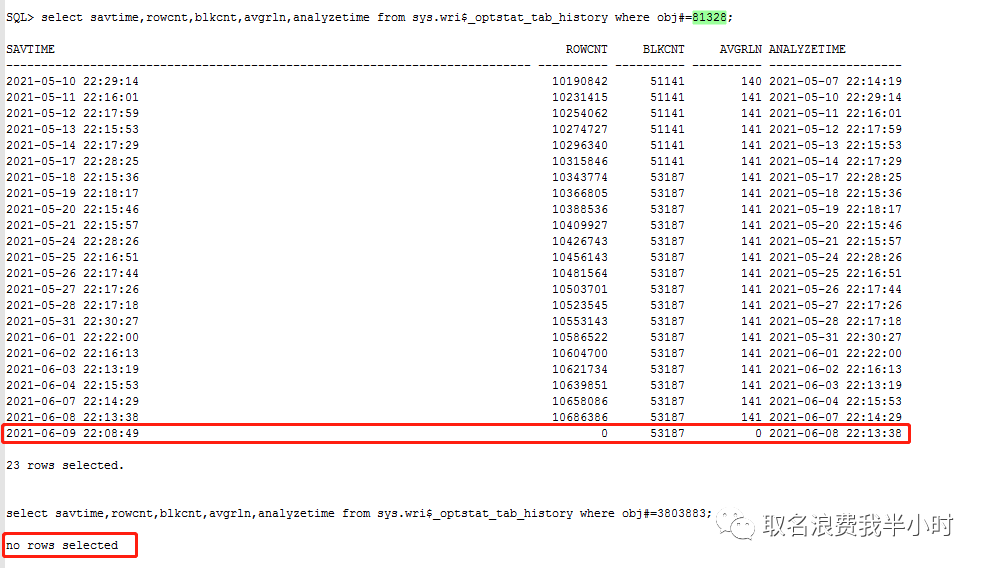
奇怪的现象出现了,6月8日晚上22:13:38(问题发生的前一天)对ODS_BUSI_XXXXXX表收集的统计信息为0。而ODS_BUSI_XXXXXX_OLD表就没收过统计信息。
进行到这里,又得和客户沟通了,为什么8号晚上收集统计信息之后ODS_BUSI_XXXXXX的统计信息为0呢?难道业务上有什么特殊操作?果然客户说这张表每天跑批的逻辑是先清空这张表再插入数据。问题由来了,客户说以前跑批都是下午1点多就结束了,所以按理说8号晚上跑批的时候ODS_BUSI_XXXXXX表里应该是有1000多万条记录的啊,怎么统计信息收集的是0条呢?继续追问,客户说8号白天跑批的时候,有地方出错了,后来改了字段的长度,再重新跑的,这就导致了在8号那天,整个批量的执行往后延了很长时间,结果到晚上10点开始收集统计信息的时候批量还未执行完,也就很巧合的将ODS_BUSI_XXXXXX表的统计信息收集成了0条,然后第二天也就是9号跑批的时候,oracle评估ODS_BUSI_XXXXXX表只有1条记录,从而选择了错误的执行计划。
至此问题基本已经明确了。但是现在这条sql已经卡了很长时间了,只能重跑了,但是考虑到以后要是再出现这种情况,就算今天手动收集统计信息,这条sql跑过去了,那以后再遇到怎么办呢?能不能通过加hint的方式固定执行计划呢?答案是可以的。
通过分析sql文本:使用了not exists,但是由于统计信息收集错误,oracle错误的评估了ODS_BUSI_XXXXXX表的数据量,最终导致走了filter类型的执行计划,那如果我们让子查询展开和主查询进行hash join,效率会不会更好呢?这里说明一下,对于这条sql正常情况下我觉得oracle也会进行子查询展开的,只不过这里因为统计信息的异常,导致oracle认为走filter的cost小于走子查询展开然后hash join的cost。验证一下:
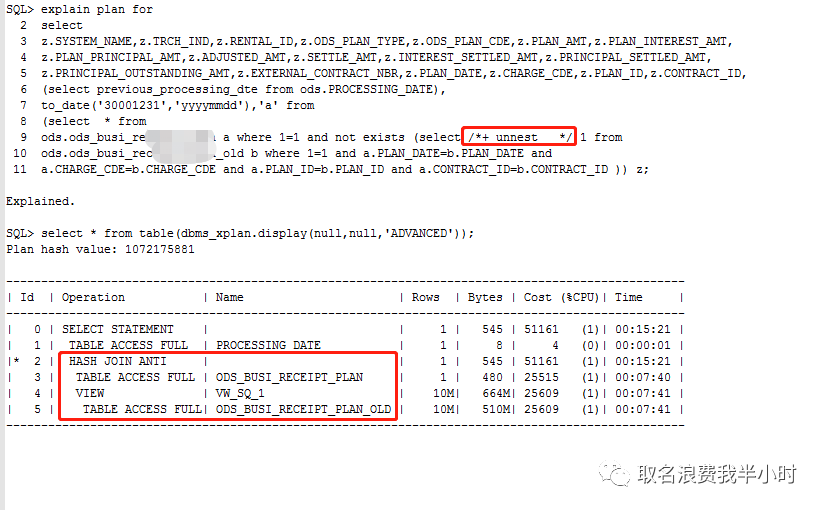
加了unnest的hint之后,执行计划已经发生了变化,虽然仍然是对这两张表全表扫描,但现在这个执行计划的执行时间是可控的了。
接下来让客户找到存储过程中这条sql的位置,虽然是拼接的语句,但通过一些关键词还是能定位到的,加hint,如下:

之后批量就重跑了,由于整个批量的执行时间很长,所以只能等第二天看效果了。9号上午客户反馈批量跑过去了。然后我再次登录环境检查了一下,发现ODS_BUSI_XXXXXX表的统计信息已经被收集成1000多万,正常了。然后我又做了如下测试:
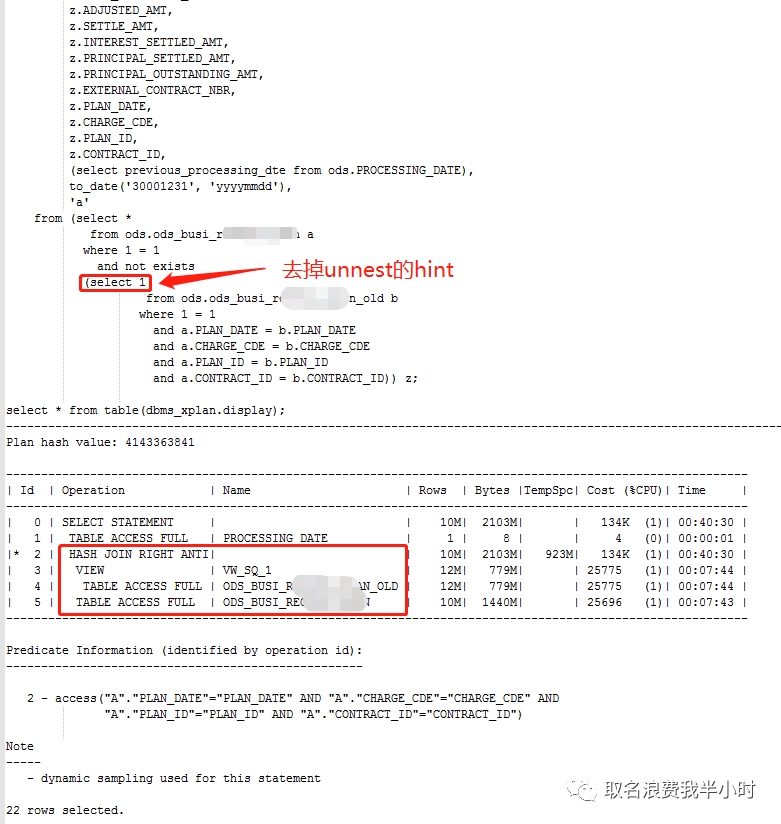
可以看到去掉昨天加的unnest的hint之后,走的执行计划也是没问题的,最后对于昨天存储过程中加的hint就保留吧,因为这种对大表清空再插入的业务逻辑,保不准哪天又出现因为统计信息错误导致走错执行计划的问题。
最后总结一下,这个问题本身并不难,但如果是自己闷头查,还真就有很多地方可能会想不明白,所以跟客户多沟通真的很重要啊,不能放过任何细节。
