




openGauss NUMA适配之线程绑核
1、多核NUMA结构
NUMA(Non-uniform memory access,非统一内存访问架构)出现前,CPU通过内存控制器访问内存,随着CPU核的增加,内存控制器成为评价。内存控制器一般拆分内存平均分配到各个node节点上,CPU访问本地内存速度快,跨片访问慢。NUMA距离定义为:NUMA node的处理器和内存块的物理距离。通过numactl工具可以查看到CPU访问的距离信息。
2、NUMA绑核优化思路
避免线程在运行中在不同核上漂移,从而引起访问NUMA远端内存。Openguass通过配置参数thread_pool_attr控制CPU绑核分配,该参数仅在enable_thread_pool打开后生效。参数分为3部分:’thread_num,group_num,cpubind_info’。
其中thread_num:线程池中线程总数,取值0-4096。0表示根据CPU核数量自动配置线程池中线程数。如果大于0,线程池中线程数等于该值
group_num:线程池中线程分组个数。0-64。0表示根据NUMA组个数自动配置线程池中分组个数,否正为group_num个数。
cpubind_info:线程池是否绑核的配置参数。可以配置:
1(nobind),线程不绑核
2(allbind),利用当前系统所有能查询到的CPU核做线程绑核;
3 (nodebind:1,2),利用NUMA组1,2中CPU核进行绑核;
4 (cpubind:0-30),利用0-30号CPU核进行绑核。
默认值‘16,2,(nobind)’
为充分利用CPU,线程数略大于核数。因为可能由线程等待,此时切换大其他线程进行。
3、源码解析
操作流程
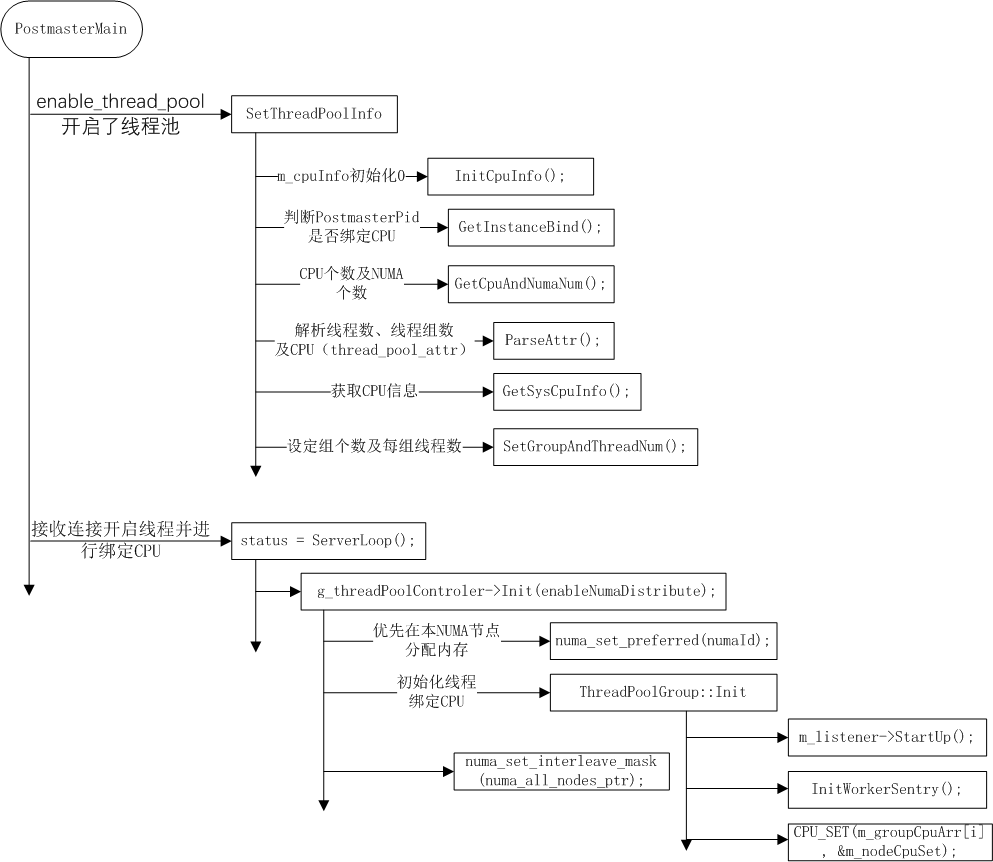
1) 在PostmasterMain中开始设置线程绑定动作
2) 如果设置enable_thread_pool,才会调用SetThreadPoolInfo函数
(1) 首先InitCpuInfo将CPU信息结构m_cpuInfo初始化
(2) 判定是否已有CPU进行了绑定GetInstanceBind
(3) GetCpuAndNumaNum计算CPU个数及NUMA节点个数
(4) ParseAttr函数解析thread_pool_attr字符串
(5) GetSysCpuInfo函数获取CPU信息
(6) SetGroupAndTreadNum设定组个数及每个组中线程数
3) 在ServerLoop函数中接收用户端连接,并进行CPU绑定
(1) 由函数g_threadPoolControler->Init完成
(2) 完成线程创建及CPU绑定的函数是TreadPoolGroup::Init完成
GetCpuAndNumaNum
通过lscpu命令来计算CPU核、NUMA个数。
void ThreadPoolControler::GetCpuAndNumaNum()
{
char buf[BUFSIZE];
FILE* fp = NULL;
if ((fp = popen("lscpu", "r")) != NULL) {
while (fgets(buf, sizeof(buf), fp) != NULL) {
if (strncmp("CPU(s)", buf, strlen("CPU(s)")) == 0 &&
strncmp("On-line CPU(s) list", buf, strlen("On-line CPU(s) list")) != 0 &&
strncmp("NUMA node", buf, strlen("NUMA node")) != 0) {
char* loc = strchr(buf, ':');
m_cpuInfo.totalCpuNum = pg_strtoint32(loc + 1);
} else if (strncmp("NUMA node(s)", buf, strlen("NUMA node(s)")) == 0) {
char* loc = strchr(buf, ':');
m_cpuInfo.totalNumaNum = pg_strtoint32(loc + 1);
}
}
pclose(fp);
}
GetSysCpuInfo
1) 通过fp = popen(“lscpu -b -e=cpu,node”, “r”);执行lscpu命令获取cpuid和numaid
2) 通过CPU_ISSET判断CPU是否绑定,最后计算出活跃未绑定的CPU个数m_cpuInfo.activeNumaNum
SetGroupAndThreadNum
1) 进行线程绑定,默认情况下线程组个数2,每组里面线程个数16
2) ConstrainThreadNum限定线程池大小m_maxPoolSize为min(4096,max_connection,),线程个数m_threadNum = Min(m_threadNum, m_maxPoolSize);
ThreadPoolGroup::Init
m_listener->StartUp();//开启一个新线程
InitWorkerSentry();
|-- AddWorker
|-- AttachThreadToNodeLevel:: pthread_setaffinity_np
CPU_SET(m_groupCpuArr[i], &m_nodeCpuSet);//循环将CPU加入CPU集合
NUMA优化相关函数
Opengauss中所有numa相关函数都可以通过宏定义ifdef __USE_NUMA找到其定义及调用的地方。
int numa_available(void):NUMA的API是否可以在平台上正常使用
int numa_max_node(void):当前系统上最大NUMA节点号
void * numa_alloc_onnode(size_t size,int node):在一个指定NUMA节点分配内存
void numa_free(void *start,size_t size):释放起始地址指定的内存
int numa_run_on_node(int node):运行当前任务在指定NUMA节点上
void numa_set_localalloc(void):设置当前的任务内存分配策略为本地化分配
void numa_set_preferred(int node):为当前任务设置偏好NUMA节点
void numa_set_interleave_mask(struct bitmask*nodemask):在一系列numa节点上分配交叉内存
int pthread_getaffinity_np(pthread_t thread,size_t cpusetsize,cpu_set_t *cpuset):设置线程在某个CPU上运行。
1)sched_getaffinity和pthread_getaffinity_np都是绑核的函数。
2)numa_set_preferred设置当前线程优先分配内的结点。内存分配器先尝试从这个结点上分配内存。如果这个结点没有足够的空间,它会尝试其他结点。
3)numa_set_interleave_mask函数可以让当前线程以交错(interleaving)方式分配内存。未来所有的内存,将会从掩码给定的结点上轮询(round robing)分配。numa_all_nodes将内存分配交错(interleaving)在所有的node上。numa_no_nodes将会关闭交错分配内存。numa_get_interleave_mask函数返回当前的交错掩码。这可以将当前的内存分配策略保存到文件中,在策略修改后,再次恢复。
参考
}https://www.bilibili.com/video/BV1gD4y1o7qB?from=search&seid=11985947230954507904
