




隐式转换(Implicit Conversion)就像他的名字一样,是个隐秘、不容易被发现的问题,但归根结底,还是设计开发中未遵守相关的规范,或者说是不良的设计开发习惯所导致的。
如果在条件中的字段和变量类型不一致,数据库会按照低精度向高精度的顺序进行隐式转换,转换的过程就会消耗资源,例如CPU,但是更关键的是如果隐式转换的字段是索引列,就会导致因使用了函数而不能用到索引,该使用索引扫描的执行计划就变成了全表扫描,这对系统性能来说就是潜在的风险。
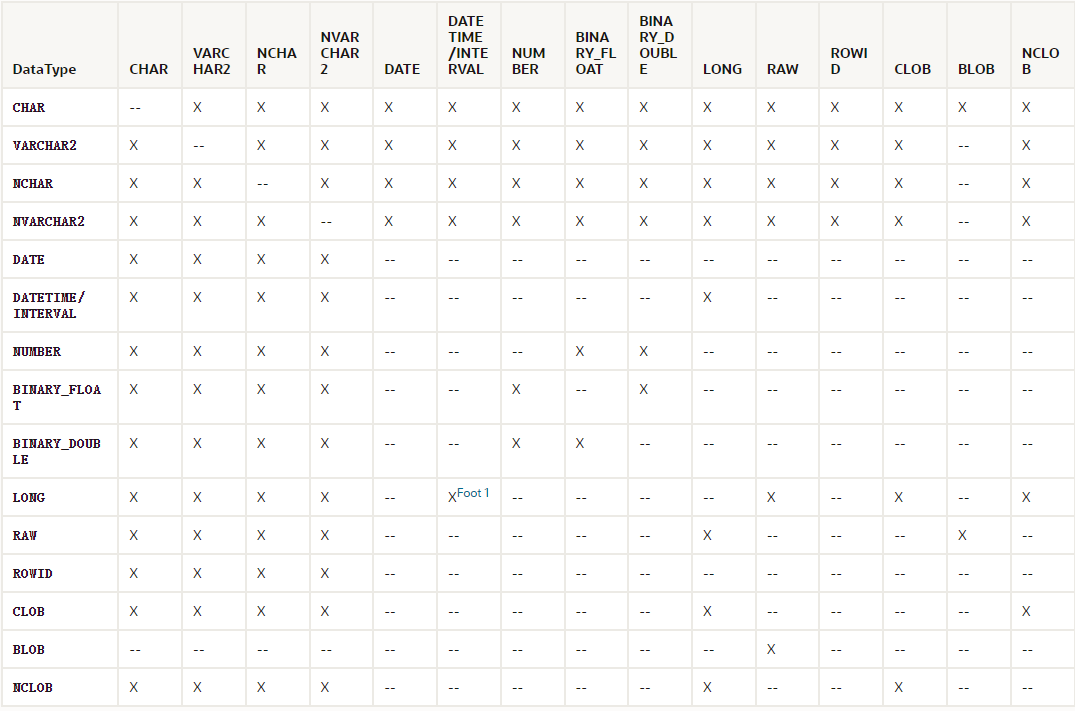
例如在Oracle中,类型转换如下,
P.S.
https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/Data-Type-Comparison-Rules.html#GUID-98BE3A78-6E33-4181-B5CB-D96FD9DC1694
字符串类型转换关系,

测试表test的object_name是varchar2类型,subobject_name是nvarchar2类型,都创建了索引,
SQL> create table test as select * from dba_objects;Table created.SQL> select count(*) from test;COUNT(*)----------97095SQL> create index idx_test_01 on test(object_name);Index created.SQL> alter table test modify subobject_name nvarchar2(30);Table altered.SQL> create index idx_test_02 on test(subobject_name);Index created.SQL> desc testName Null? Type---------------- -------- ----------------------OWNER VARCHAR2(30)OBJECT_NAME VARCHAR2(128)SUBOBJECT_NAME NVARCHAR2(30)...
构造where varchar2=nvarchar2,因为varchar2精度比nvarchar2小,所以需要将varchar2转换为nvarchar2类型,由于varchar2是左值,对索引列做了函数操作(SYS_OP_C2C),导致不能用到这个索引,因此是全表扫描,
SQL> var p nvarchar2(200);SQL> exec :p := 'a';PL/SQL procedure successfully completed.SQL> select * from test where object_name = :p;no rows selected------------------------------------------------------------------------------------------------------------| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |------------------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | | 388 (100)| | 0 |00:00:00.04 | 1396 ||* 1 | TABLE ACCESS FULL| TEST | 1 | 16 | 388 (1)| 00:00:05 | 0 |00:00:00.04 | 1396 |------------------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter(SYS_OP_C2C("OBJECT_NAME")=:P)
构造where nvarchar2=varchar2,因为varchar2精度比nvarchar2小,所以需要将varchar2转换为nvarchar2类型,但此时的varchar2是右值,虽然用了函数,但是并未影响左值的索引字段nvarchar2,因此即使出现了隐式转换,不会影响索引使用,会采用索引扫描,
SQL> var q varchar2(200);SQL> exec :q := 'a';PL/SQL procedure successfully completed.SQL> select * from test where subobject_name = :q;no rows selected-----------------------------------------------------------------------------------------------------------------------------| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |-----------------------------------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | | 1 (100)| | 0 |00:00:00.01 | 2 || 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 1 | 1 (0)| 00:00:01 | 0 |00:00:00.01 | 2 ||* 2 | INDEX RANGE SCAN | IDX_TEST_02 | 1 | 1 | 1 (0)| 00:00:01 | 0 |00:00:00.01 | 2 |-----------------------------------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - access("SUBOBJECT_NAME"=SYS_OP_C2C(:Q))
但是最近碰到了一个SQL Server隐式转换的问题,发现还是有区别。
P.S. SQL Server刚接触,如果操作和原理上讲的不对的,请各位指正。
测试场景1
创建一个SQL_Latin1_General_CP1_CI_AS排序规则的数据库,测试表如下,一个字段是varchar,一个字段是nvarchar,都创建了索引,
create table test(c1 nvarchar(200), c2 varchar(200));insert into test(c1,c2) select cast(a.name as nvarchar(200)), a.name from master.dbo.spt_values a where a.number<10000;create nonclustered index idx_test_01 on test(c1);create nonclustered index idx_test_02 on test(c2);
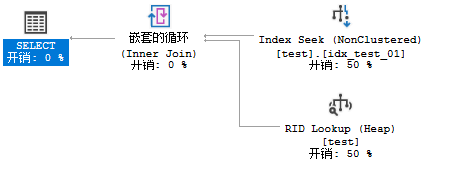
(1) 构造where nvarchar=varchar,
select * from test where c1='a';
此时选择了Index Seek,再回表的操作,
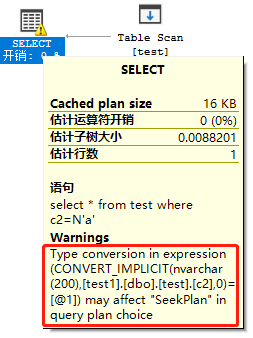
(2) 构造where varchar=nvarchar,
select * from test where c2=N'a';
我们看到执行计划中提醒表达式列出现了类型转换,这会影响执行计划选择“SeekPlan”,执行了CONVERT_IMPLICIT函数的列就是左值c2,强制转换为nvarchar,“SeekPlan”的执行计划,我理解就是Oracle中的Index Unique Scan或Index Range Scan,而且当前确实选择了全表扫描,Table Scan,这就是隐式转换,导致不能使用索引的场景,
测试场景2
创建一个Latin1_General_CP1_CI_AS排序规则的数据库,和场景1相同,测试表如下,一个字段是varchar,一个字段是nvarchar,都创建了索引,
create table test(c1 nvarchar(200), c2 varchar(200));insert into test(c1,c2) select cast(a.name as nvarchar(200)), a.name from master.dbo.spt_values a where a.number<10000;create nonclustered index idx_test_01 on test(c1);create nonclustered index idx_test_02 on test(c2);
(1) 构造where nvarchar=varchar,
select * from test where c1='a';
效果和场景1是相同的,此时选择了Index Seek,再回表的操作,
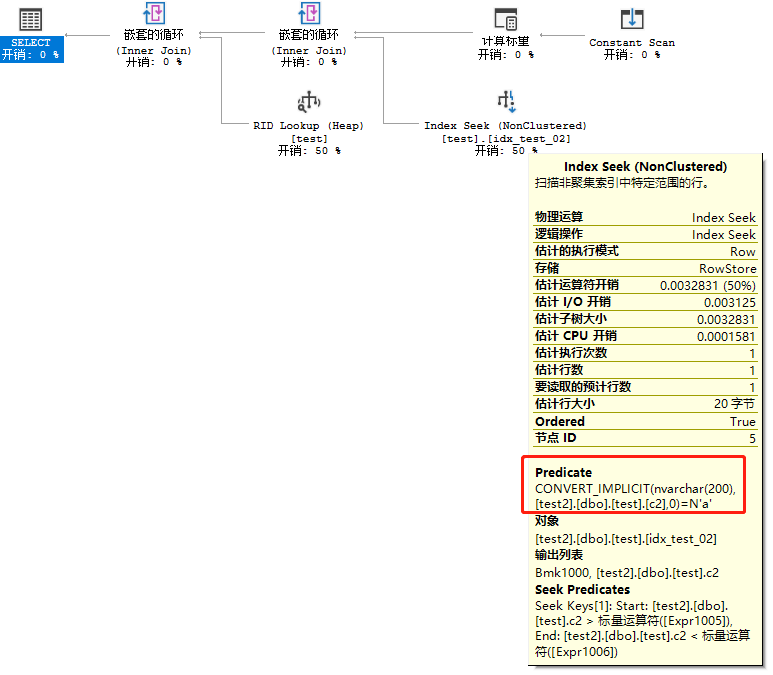
(2) 构造where varchar=nvarchar,
select * from test where c2=N'a';
这时就可以看出一些不同了,场景1中相同语句,因为隐式转换,导致用了Table Scan,而此处,虽然谓词提示CONVERT_IMPLICIT(c2),但未作为Warning,而且执行计划还是使用的Index Seek,路径上和场景1稍有不同,我猜这个是不是因为CONVERT_IMPLICIT的使用导致的?有知道的朋友,可以介绍下,
我看了下,我们的测试库,常用的排序规则,是Chinese_PRC_BIN,效果和场景2是相同的。
Jonathan Kehayias在这篇文章中,提到了SQL_Latin1_General_CP1_CI_AS和Latin1_General_CP1_CI_AS这两种排序规则不同数据类型的转换关系,如下所示,
P.S.
https://www.sqlskills.com/blogs/jonathan/implicit-conversions-that-cause-index-scans/
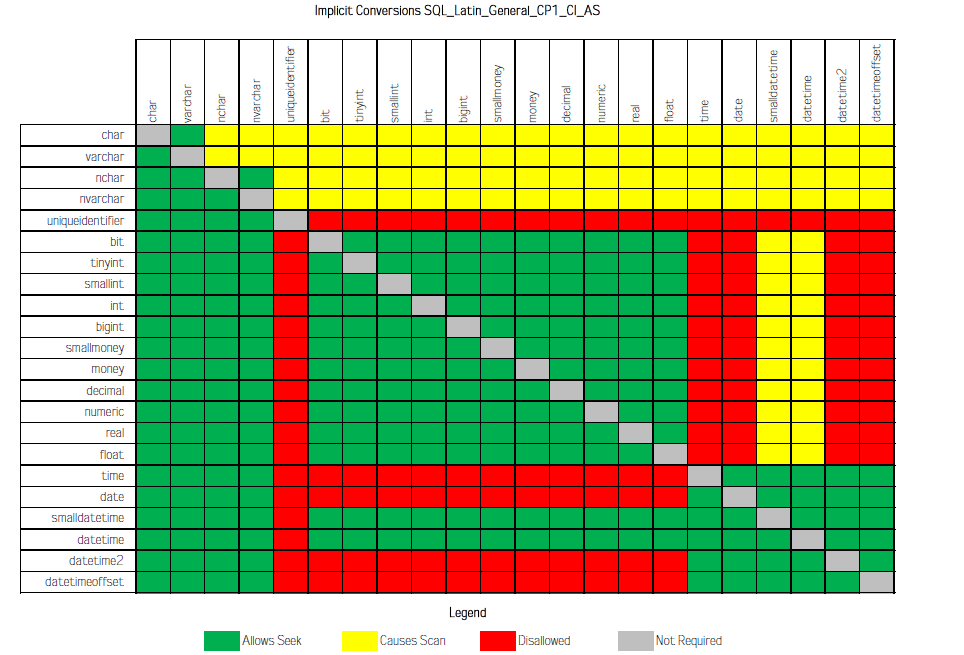
(1) SQL_Latin_General_CP1_CI_AS排序规则,
varchar到nvarchar的隐式转换,是黄色的,意思是Causes Scan,即忽略索引,
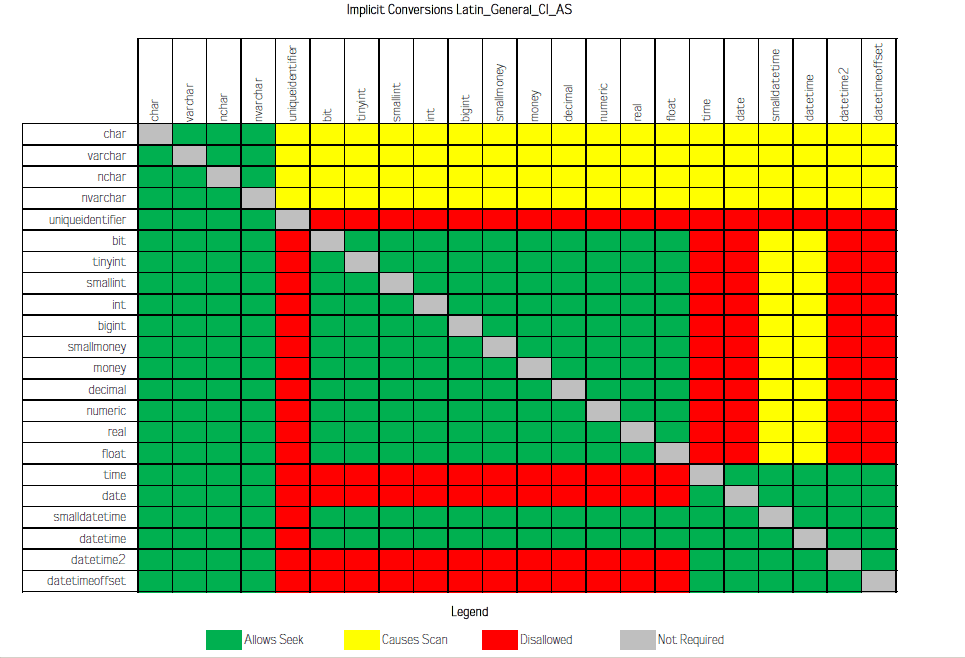
(2) Latin_General_CI_AS排序规则,
varchar到nvarchar的隐式转换,是绿色的,允许用Seek,
因此在SQL Server中,不同的排序规则,隐式转换的影响可能是不同的,有的会影响索引的选择,有的就无影响,我不知道SQL Server为什么这么多排序规则,我也不知道有没有官方文档列出哪些排序规则对隐式转换是敏感的,
因此这就给用了隐式转换的应用带来了风险,尤其是开发、测试、生产数据库环境的排序规则不同的情况下,可能没人注意排序规则,但是隐式转换的影响可能就会不同,这就像定时炸弹,或许测试环境,隐式转换没关系,速度杠杠的,但到了生产,隐式转换就开始起作用,将原本能索引扫描的强制改为了全表扫描,对系统的性能就会产生冲击。
其实针对这类的问题,最佳方案就是能规范日常的设计和开发,定义合适的字段类型,程序中的变量使用和定义相同的类型,无论用什么排序规则,可以说就没隐式转换什么事儿了。
退而求其次,如果不能做到规范的设计和开发,至少在开发测试的阶段,或者通过工具,或者通过人肉,检索下当前系统中用了全表扫描的语句,再根据字段是否存在索引,判断是否因为书写不当造成了隐式转换。
隐式转换的历史文章,
P.S. 谢谢潇湘老师在这个问题探索过程中的讨论和交流。
近期更新的文章:
文章分类和索引:
