




最近和朋友老刘聊到一个redo日志文件修改大小的问题(不要好奇老刘是谁):
-
Oracle的alert告警日志为啥老报错:Checkpoint not complete?
-
在修改redo日志大小时,v$log表中记录redo日志状的STATUS 在什么场景下会才变成INACTIVE状态,以便对其进行删除后重建更大的redo日志?
大家知道,redo日志记录了Oracle数据库的块改变;Active (Current)和Inactive Redo Log Files Oracle Database每次只使用一个重做日志文件来存储从重做日志缓冲区写入的重做记录。LGWR进程主动写入的重做日志文件称为当前重做日志文件。
Figure 12–1 Reuse of Redo Log Files by LGWR
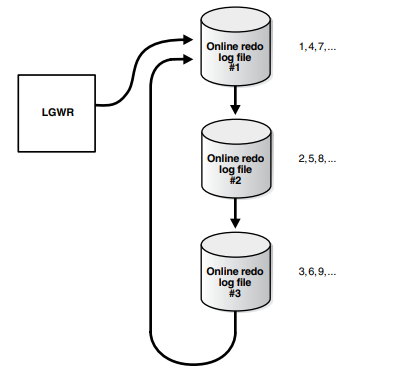
所以第一个问题之所以发生是因为:当业务场景中数据更改比较频繁时,有较多的块改变需要记录到redo日志,如redo日志大小比较小,redo日志满了后会触发log switch,redo切换时也会触发检查点的产生,将被override 的redo log 如这时候仍然处于active 状态(即检查点未完成),就会发生 “Checkpoint not complete” 的错误。
解决方法是调大redo日志。
小结:
redo log的大小可以影响 DBWR 和 checkpoint 。
适当大小的log file可以提供更好的性能;
redo logfile 设置过小会增加checkpoint 和降低性能。
Figure 12–1 Reuse of Redo Log Files by LGWR
官方信息:
larger redo log files provide better performance. Undersized logfiles increase checkpoint activity and reduce performance。A rough guide is to switch log files at most once every 20 minutes.
(推荐日志切换的时间不要超多20分钟).
第二个问题:怎么调整redo日志大小?
在Oracle中更改redo log大小 or 增加redo log组时,由于ORACLE没有提供类似RESIZE的参数来重新调整REDO LOG FILE的大小,故只能先把这个文件删除了,然后再重建。
又因ORACLE要求最少有两组日志文件在用,所以不能直接删(An instance requires at least two groups of redo log files, regardless of the number of members in the groups. (A group comprises one or more members.)。必须要创建中间过渡的REDO LOG日志组。
具体过程不再赘述。
注意:在删除原有redo日志组时,需要保证redo中检查点完成,即Inactive状态对应的redo group才能进行alter database drop logfile group操作。
使用select * from vlog;查看redo日志状态: SYS@test_LY> select * from gvlog;
INST_ID GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME CON_ID
1 1 1 1009535 209715200 512 1 NO CURRENT 1.4620E+10 17-JUN-21 1.8447E+19 0
1 2 1 1009534 209715200 512 1 YES INACTIVE 1.4620E+10 17-JUN-21 1.4620E+10 17-JUN-21 0
1 3 2 1203015 209715200 512 1 YES INACTIVE 1.4620E+10 17-JUN-21 1.4620E+10 17-JUN-21 0
1 4 2 1203016 209715200 512 1 NO ACTIVE 1.4620E+10 17-JUN-21 1.8447E+19 0
解释下status 四个值的含义:
Unused – 表示还没被使用过
Current – 表示正在使用
Active – Log isactive but is not the current log. It is needed for crash recovery
Inactive – Log is nolonger needed for instance recovery
为了删除redo日志对应的group, 此时group对应的redo日志状态必须为inactive。为了尽快完成,会手动执行如下命令:
alter system switch logfile;
那么这条alter system switch logfile到底做了啥操作?
alter system switch logfile 会触发 checkpoint的产生,保证数据库的数据一致性前推;
但 log switch 的完成不依赖于 checkpoint 的完成,只要执行了alter system switch logfile;命令,就会切换redo日志,redo信息将被写到下一个当前redo日志中;
注意:
在log switch 发生时,将被override 的redo log 仍然处于active 状态(即检查点未完成),就会发生 “Checkpoint not complete” 的错误。
报错信息如下:
Thread 1 cannot allocate new log, sequence 21
Checkpoint not complete
Current log# 4 seq# 20 mem# 0: /u01/app/oracle/oradata/TEST/redo04.log
出现这个错误,就表明redo日志的大小设置过小,需要对redo日志进行调大或者增加redo log组。
文章结束。
以下为个人公众号,欢迎扫码关注:

