




01
—
摘要
本文由“以数据之名”分享,“天下武功,唯快不破”一文开始我们介绍了Redis的基本特性以及基本的数据结构,本篇我们继续讨论与交流有关Redis的基础概念剖析。正所谓“鲜衣怒马youth,不负韶华Redis”,亦可知“得Redis者得悍将,携Redis者携天下”。
02
—
Redis 简介
Re di s(Remote Dictionary Server),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value高性能分布式数据库,并提供多种语言的API。Redis 是一种开源(BSD 许可)、内存数据结构存储。官网介绍其QPS每秒超过10w,TPS每秒超过8w。更有大厂加持如阿里巴巴、腾讯、新浪微博、Twitter、Github等
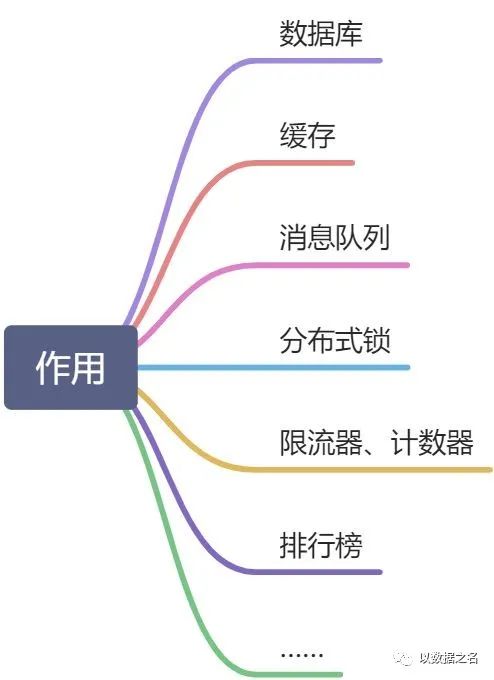
2.1、作用
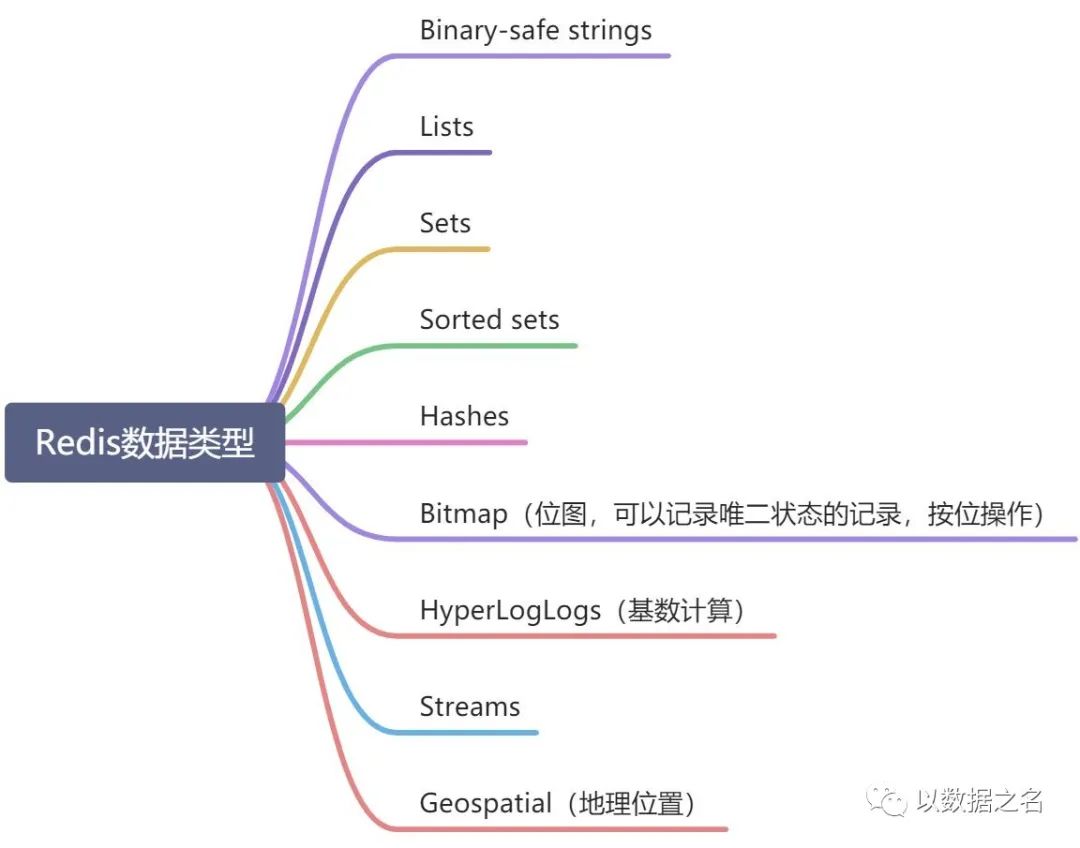
2.2、数据结构
Redis本身支持的数据结构类型,5种基本类型(诸如字符串、散列、列表、集合、带范围查询的排序集合)、4种特殊类型(位图、超级日志、地理空间索引和流)。
03
—
Redis 数据结构
本小节主要介绍五种常用的数据类型的数据结构,具体如下图:
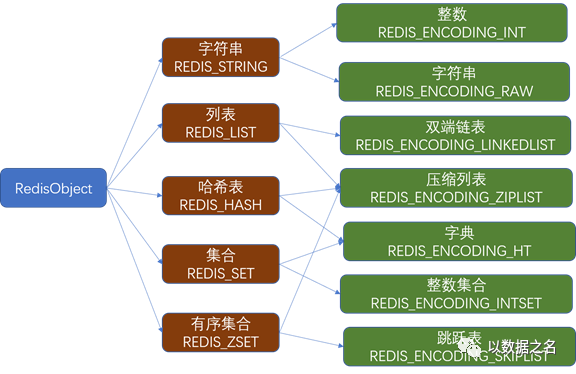
关于上表中的部分释义:
双端链表与单链表十分相似,不同的是第一个链接点与最后一个链接点直接相连。双端链表不是双向链表

压缩列表是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数,要么就是长度比较短的字符串,Redis会使用压缩列表来做列表键的底层实现;
整数集合是集合键的底层实现之一。当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis会使用整数集合作为集合键的底层实现。
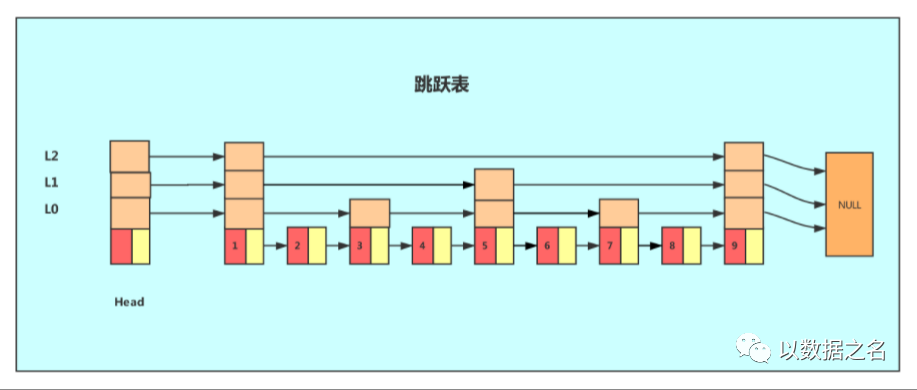
跳跃表是一种链表+多级索引的有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
04
—
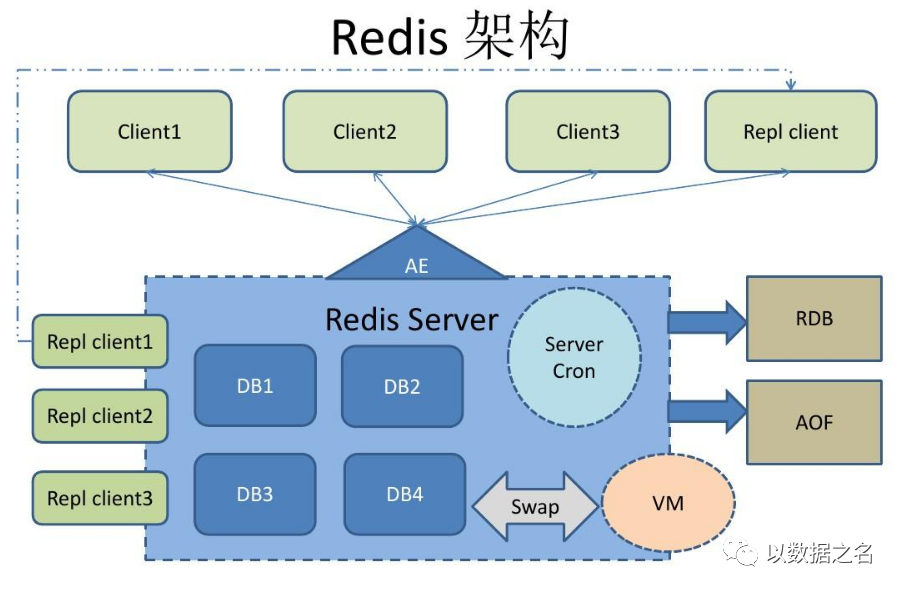
Redis 整体架构
Redis 使用的是 I/O 多路复用功能来监听多 socket 链接的,这样就可以使用一个线程链接来处理多个请求,减少线程切换带来的开销,同时也避免了 I/O 阻塞操作,从而大大提高了 Redis 的运行效率。
05
—
Redis 基础篇
5.1、Redis执行流程
大致流程:客户端发命令->服务端执行->返回结果到客户端

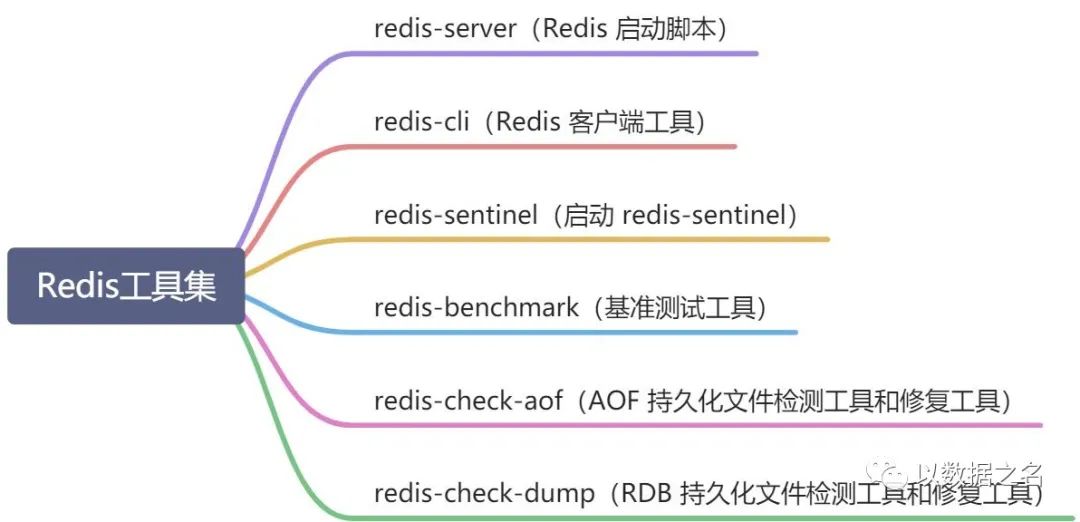
5.2、Redis 工具集
5.3、Redis 持久化
Redis之所以要进行持久化操作,是因为Redis是内存数据库,断电就会丢失所有数据,所以必须有持久化操作。那么持久化的操作方式有三种rdb(默认开启)、aof(默认关闭)和混合持久化方式
5.3.1、快照方式(RDB, Redis DataBase)
基本原理:间隔一定的时间,保存一次快照信息
# RDB 保存的条件 save 900 1 save 300 10 save 60 10000# bgsave 失败之后,是否停止持久化数据到磁盘,yes 表示停止持久化,no 表示忽略错误继续写文件。stop-writes-on-bgsave-error yes# RDB 文件压缩 rdbcompression yes# 写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。rdbchecksum yes# RDB 文件名 dbfilename dump.rdb# RDB 文件目录 dir ./
触发方式
手动触发
save:阻塞主线程,生产慎用
bgsave :fork() 一个子进程来执行持久化
自动触发
① save m n(可设置多个) :在 m 秒内,如果有 n 个键发生改变,则自动触发持久化
② flushall : 清空Redis数据库,生产慎用。会触发自动持久化
③ 主从同步触发:当从节点执行全量复制操作时,主节点会执行 bgsave 命令,
并将 RDB 文件发送给从节点,该过程会自动触发 Redis 持久化
重要的参数① save 参数 :配置触发 RDB 持久化条件的参数② rdbcompression 参数:默认值是 yes 表示开启 RDB 文件压缩,Redis 会采用 LZF 算法进行压缩。(时/空问题)③ rdbchecksum 参数: 默认值为 yes 表示写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
优缺点:
优点:占用小,恢复快,持久化fork子进程
缺点:
1、间隔一定的时间操作一次,如果期间redis宕机,最后一次数据无法保存
2、fork子进程占用一定空间
5.3.2、文件追加方式(AOF, Append Only File)
# 是否开启 AOF,yes 为开启,默认是关闭 appendonly no# AOF 默认文件名 appendfilename "appendonly.aof"# AOF 持久化策略配置# appendfsync always appendfsync everysec# appendfsync no# AOF 文件重写的大小比例,默认值是 100,表示 100%,也就是只有当前 AOF 文件,比最后一次的 AOF 文件大一倍时,才会启动 AOF 文件重写。auto-aof-rewrite-percentage 100# 允许 AOF 重写的最小文件容量 auto-aof-rewrite-min-size 64mb# 是否开启启动时加载 AOF 文件效验,默认值是 yes,表示尽可能的加载 AOF 文件,忽略错误部分信息,并启动 Redis 服务。# 如果值为 no,则表示,停止启动 Redis,用户必须手动修复 AOF 文件才能正常启动 Redis 服务。aof-load-truncated yes
触发方式
手动触发
bgrewriteaof 命令
自动触发:满足 AOF 设置的策略触发和满足 AOF 重写触发
always:每条 Redis 操作命令都会写入磁盘,最多丢失一条数据;everysec:每秒钟写入一次磁盘,最多丢失一秒的数据;no:不设置写入磁盘的规则,根据当前操作系统来决定何时写入磁盘,Linux 默认 30s 写入一次数据至磁盘AOF 重写(解决无效信息/命令)不阻塞auto-aof-rewrite-min-size:允许 AOF 重写的最小文件容量,默认是 64mb 。auto-aof-rewrite-percentage:AOF 文件重写的大小比例,默认值是 100,表示 100%,也就是只有当前 AOF 文件,比最后一次(上次)的 AOF 文件大一倍时,才会启动 AOF文件重写。
优缺点
优点:数据更加完整、持久数据是Redis 键值操作命令
缺点:AOF 文件要大于 RDB 文件(同数据)、负载高时候性能问题
5.3.3、混合持久化方式
基本原理:Redis 4.0支持,结合了 RDB 和 AOF 的优点;Redis 5.0 默认值开启:aof-use-rdb-preamble yes AOF 重写时会把 Redis 的持久化数据,以 RDB 的格式写入到 AOF 文件的开头,之后的数据再以 AOF 的格式化追加的文件的末尾
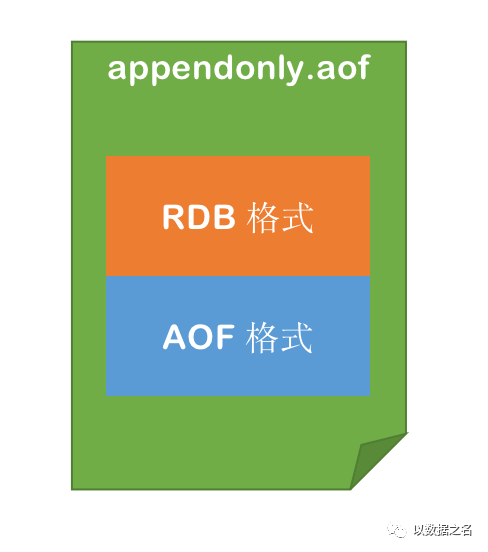
加载流程
判断是否开启 AOF 持久化,开启继续执行后续流程,未开启执行加载 RDB 文件的流程;
判断 appendonly.aof 文件是否存在,文件存在则执行后续流程;
判断 AOF 文件开头是 RDB 的格式, 先加载 RDB 内容再加载剩余的 AOF 内容;
判断 AOF 文件开头不是 RDB 的格式,直接以 AOF 格式加载整个文件。
优缺点
优点:更快启动,更少数据丢失
缺点:文件可读性差、Redis4.0之前版本不支持
注:如果对数据不敏感,则禁用持久化,提升执行效率
5.4、Redis 过期机制
5.4.1、Redis 过期时间
expire:用于设置 key 的过期时间,单位以秒计。
pexpire:设置 key 的过期时间以毫秒计。
expireat:EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。
pexpireat:设置 key 过期时间的时间戳(unix timestamp) 以毫秒计。
5.4.2、字符串的过期处理
set key value ex seconds:设置键值对的同时指定过期时间(精确到秒);
set key value px milliseconds:设置键值对的同时指定过期时间(精确到毫秒);
setex key seconds valule:设置键值对的同时指定过期时间(精确到秒)。
5.4.3、Redis key过期策略
定时删除:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
惰性删除:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
定期删除 : 每隔一段时间执行一次删除(在redis.conf配置文件设置hz,1s刷新的频率)过期key操作
5.5、Redis 内存淘汰策略(maxmemory-policy)
(超过 Redis 设置的最大内存-maxmemory)
noeviction:不淘汰任何数据,当内存不足时,新增操作会报错,Redis 默认内存淘汰策略;
allkeys-lru:淘汰整个键值中最久未使用的键值;
allkeys-random:随机淘汰任意键值;
volatile-lru:淘汰所有设置了过期时间的键值中最久未使用的键值;
volatile-random:随机淘汰设置了过期时间的任意键值;
volatile-ttl:优先淘汰更早过期的键值。
备注:
LRU是Least Recently Used的缩写,即【最近最少使用】LFU(least frequently used (LFU) ),即【最少频率使用】
06
—
Redis 调优小细节
6.1、Redis 性能测试
6.1.1、测试方式
编写代码模拟并发进行性能测试;
使用 redis-benchmark 进行测试。
6.1.2、技术选型
比如测试 Memcached 和 Redis;
对比单机 Redis 和集群 Redis 的吞吐量;
评估不同类型的存储性能,例如集合和有序集合;
对比开启持久化和关闭持久化的吞吐量;
对比调优和未调优的吞吐量;
对比不同 Redis 版本的吞吐量,作为是否升级的一个参考标准。
6.2、Redis 性能优化方案
缩短键值对的存储长度;
使用 lazy free(延迟删除)特性;
设置键值的过期时间;
禁用耗时长的查询命令;
使用 slowlog 优化耗时命令;
使用 Pipeline 批量操作数据;
避免大量数据同时失效;
客户端使用优化;
限制 Redis 内存大小;
使用物理机而非虚拟机安装 Redis 服务;
检查数据持久化策略;
使用分布式架构来增加读写速度。
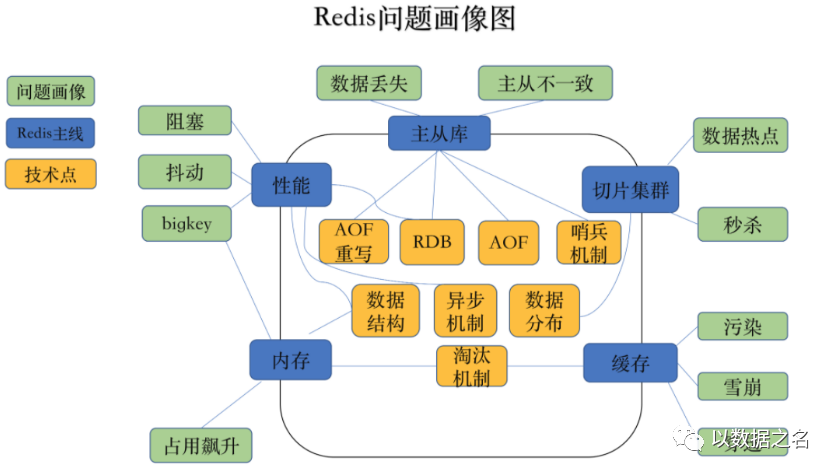
6.3、Redis 问题画像
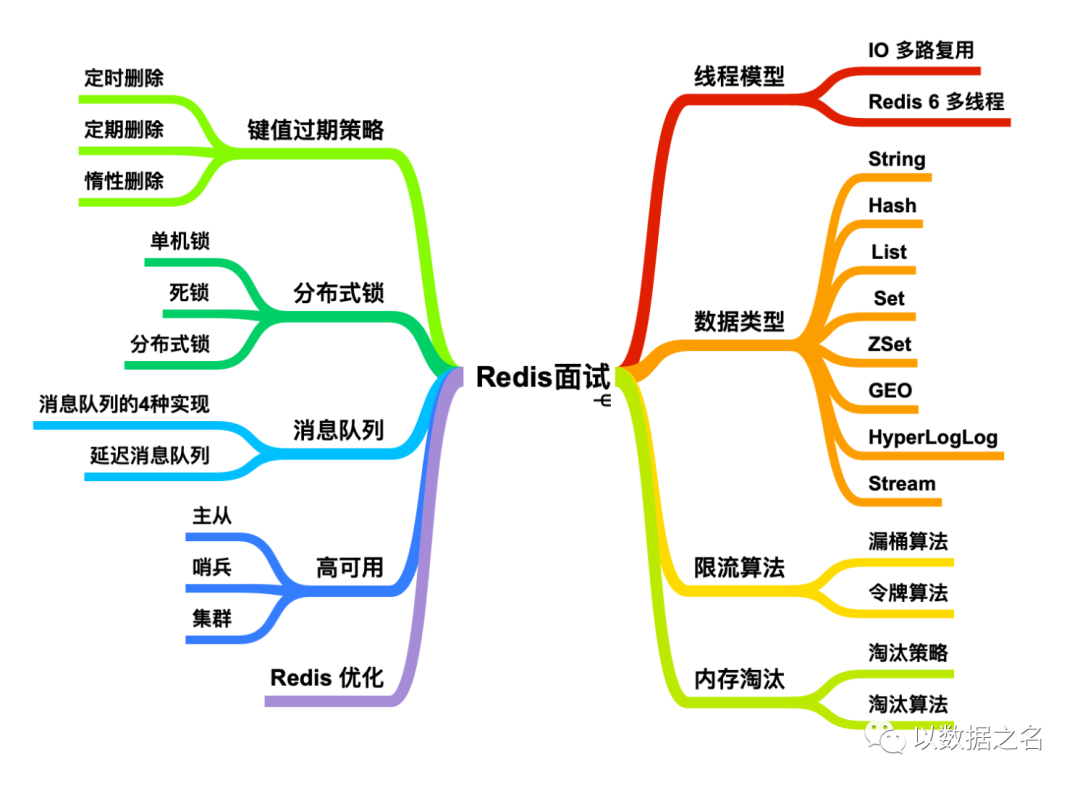
6.4、Redis 面试总结

01|数据库专题
02|Kettle插件专题
Kettle插件开发之KafkaConsumerAssignPartition篇
Kettle插件开发之KafkaConsumerAssignPartition篇
03|方法论专题
04|视频专题
6.1童心未泯,自由翱翔
05|数据湖专题
虽小编一己之力微弱,但读者众星之光璀璨。小编敞开心扉之门,还望倾囊赐教原创之文,期待之心满于胸怀,感激之情溢于言表。一句话,欢迎联系小编投稿您的原创文章!

