




Redis 有序集合(Sorted Set)类型是一个较为常用的数据结构,和 集合(Set)类型类似,都不允许重复的成员出现在一个集合中。二者之间在的应用上的差别主要是有序集合(Sorted Set)中的每一个成员都会有一个 Score 属性, Redis 正是通过这个 Score 使之有序,值得注意的是集合成员必须是唯一的,但是 Score 是可以重复的。
常见的应用场景有:热门话题、排名系统、权重列表、计数系统、签到系统、统计系统等。
本文主要分为以下三部分:
1. 有序集合(Sorted Set)数据结构
2. 常用命令
3. 总结
01
Sorted Set 数据结构
Redis 有序集合(Sorted Set)内部编码有 ziplist 和 skiplist 两种实现方式,其中 ziplist 编码性能和值的长度以及成员个数相关,Redis也提供了对应的参数用于调整 ziplist 长度和元素大小。
ziplist 数据结构定义:
当集合对象满足以下两个条件时, 有序集合对象使用 ziplist 编码:
有序集合保存的元素数量小于 zset-max-ziplist-entries 设置大小;
有序集合保存的所有元素成员的长度都小于 zset-max-ziplist-value 设置大小;
以下是 ziplist 结构展示的一个有序集合对象:

/*ZIPLIST OVERALL LAYOUT:The general layout of the ziplist is as follows:<zlbytes><zltail><zllen><entry><entry><zlend>/**/
结构定义说明:
zlbytes 用于保存 ziplist 占用内存字节数
zltail 列表中最后一个元素的偏移量
zllen 记录了元素个数
zlend 单字节特殊值 0xFF (十进制 255)
skiplist 数据结构定义:
当 ziplist 编码条件不能满足时,有序集合对象将使用 skiplist 编码。
以下是 skiplist 结构展示的一个集合对象:
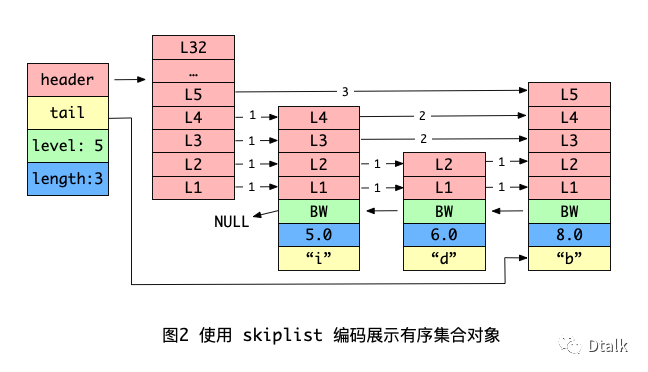
以下是 skiplist 相关数据结构:
#define ZSKIPLIST_MAXLEVEL 32 // 最大层数 32#define ZSKIPLIST_P 0.25 // Ptypedef struct zskiplistNode {// 元素成员robj *obj;// 分值double score;// 后退指针 BWstruct zskiplistNode *backward;// 层struct zskiplistLevel {// 每一层中的前向指针struct zskiplistNode *forward;// 这个层跨越的节点数量,两个相邻节点span为1unsigned int span;} level[];} zskiplistNode;typedef struct zskiplist {// 头节点,尾节点struct zskiplistNode *header, *tail;// 节点总数unsigned long length;// 目前表内节点的最大层数int level;} zskiplist;typedef struct zset {// 字典dict *dict;// 跳跃表zskiplist *zsl;} zset;
其中 zset 结构中的 zsl 跳跃表按照分值有序保存了所有集合元素(从小到大),每个跳跃表的节点中 obj 保存了元素成员,score 保存了元素的分值。
通过这样一个跳跃表设计就可以对有序集合进行范围操作了。
例如:zrank、zrange等命令。
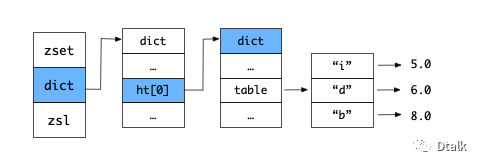
除此之外, zset 结构中的 dict 字典为有序集合创建了一个从成员到分值的映射, 其中字典的键保存了元素的成员, 而字典的值则保存了元素的分值。
通过这个字典,可以用O(1) 复杂度查询给定成员的分值。
例如:zscore 命令。
有序集合只用字典来实现的话,虽然查找成员Score的复杂度为O(1),但是本身无法对已有元素进行排序,如果只用跳跃表来实现,范围型操作效率较好,但是通过成员查找 Score 的操作则不再是O(1)。
为了让有序集合(Sorted Set)的查找和范围型操作都尽可能的高效执行,Redis 选择了使用跳跃表和字典来实现。但是这两种数据结构只是通过指针来共享相同的元素成员和 Score,所以不会出现冗余成员数据的情况。
下图为有序集合同时使用 dict 和 skiplist 编码实现:
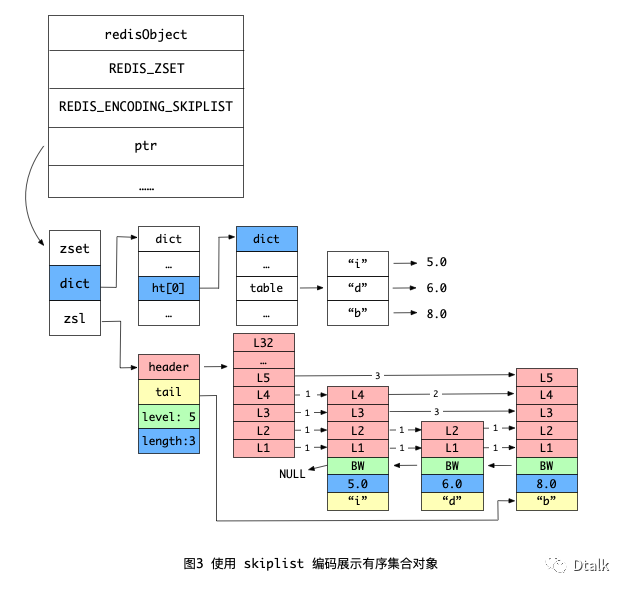
除此之外, zset 结构中的 dict 字典为有序集合创建了一个从成员到分值的映射, 字典中的每个键值对都保存了一个集合元素:字典的键保存了元素的成员, 而字典的值则保存了元素的分值。

02
常用命令
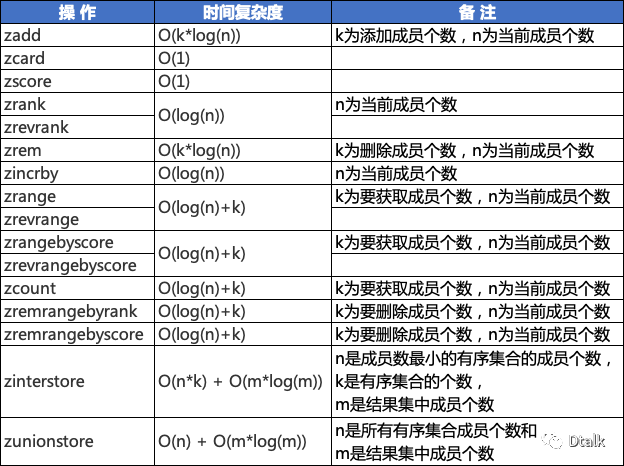
1. 向有序集合添加一个或多个成员,或者更新已存在成员的分数
命令
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
redis> ZADD idb:zset 5.0 zhangsan 6.0 wangwu 8.0 zhaoliu(integer) 3
2. 获取有序集合的成员数
命令
ZCARD key
redis> ZCARD idb:zset(integer) 3
3. 通过索引区间返回有序集合指定区间内的成员
命令
ZRANGE key start stop [WITHSCORES]
ZREVRANGE key start stop [WITHSCORES]
redis> ZRANGE idb:zset 1 21) "wangwu"2) "zhaoliu"# 递增排列redis> ZRANGE idb:zset 0 -1 WITHSCORES1) "zhangsan"2) "5"3) "wangwu"4) "6.5"5) "zhaoliu"6) "8"# 递减排列redis> ZREVRANGE idb:zset 0 -1 WITHSCORES1) "zhaoliu"2) "8"3) "wangwu"4) "6.5"5) "zhangsan"6) "5"
4. 返回有序集合中成员的分数值
命令
ZSCORE key member
redis> ZSCORE idb:zset zhangsan"5"
5. 返回有序集合中指定区间分数的成员数
命令
ZCOUNT key min max
redis> ZCOUNT idb:zset 5.0 7.0(integer) 2
6. 有序集合中对指定成员的分数加上增量
命令
ZINCRBY key increment member
redis> ZINCRBY idb:zset 0.5 wangwu"6.5"redis> ZSCORE idb:zset wangwu"6.5"
7. 返回有序集合中指定成员的索引
命令
ZRANK key member
ZREVRANK key member
redis> ZRANGE idb:zset 0 -1 WITHSCORES1) "zhangsan"2) "5"3) "wangwu"4) "6.5"5) "zhaoliu"6) "8"# 递增排列redis> ZRANK idb:zset zhangsan(integer) 0# 递减排列redis> ZREVRANK idb:zset zhangsan(integer) 2
8. 移除有序集合中的一个或多个成员
命令
ZREM key member [member ...]
redis> ZADD idb:zset 2.0 tmpStr(integer) 1redis> ZREM idb:zset tmpStr(integer) 1
9. 在分值相同的有序集合中计算指定字典区间内成员数量
命令
ZLEXCOUNT key min max
redis> ZADD myzset 0 a 0 b 0 c 0 d 0 e(integer) 5redis> ZADD myzset 0 f 0 g(integer) 2redis> ZLEXCOUNT myzset - +(integer) 7redis> ZLEXCOUNT myzset [b [f(integer) 5
10. 计算给定的一个或多个有序集的交集、并集并将结果集存储在新的有序集合 destination 中。
默认情况下,结果集中某个成员的分数值是所有给定集下该成员分数值之和。
命令
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
// 新建 idb:a_zsetredis> ZADD idb:a_zset 75.2 Tom 80.3 Lucy 92.3 Lilei(integer) 3// 新建 idb:b_zsetredis> ZADD idb:b_zset 65.3 Tom 70.2 Lucy 80.2 Lilei(integer) 3// 交集redis> ZINTERSTORE idb:sum_zset 2 idb:a_zset idb:b_zset(integer) 3// 显示有序集内所有成员及其分数值redis> ZRANGE idb:sum_zset 0 -1 WITHSCORES1) "Tom"2) "140.5"3) "Lucy"4) "150.5"5) "Lilei"6) "172.5"// 新建 idb:c_zsetredis> ZADD idb:c_zset 1 a 2 b(integer) 2// 新建 idb:d_zsetredis> ZADD idb:d_zset 2 b 3 c 4 d(integer) 3// 并集redis> ZUNIONSTORE idb:un_zset 2 idb:c_zset idb:d_zset(integer) 4// 显示有序集内所有成员及其分数值redis> ZRANGE idb:un_zset 0 -1 WITHSCORES1) "a"2) "1"3) "c"4) "3"5) "b"6) "4"7) "d"8) "4"
11. 通过字典区间返回有序集合的成员
命令
ZRANGEBYLEX key min max [LIMIT offset count]
ZREVRANGEBYLEX key max min [LIMIT offset count]
redis> ZADD myzset 0 a 0 b 0 c 0 d 0 e 0 f 0 g(integer) 7redis> ZRANGEBYLEX myzset - [c1) "a"2) "b"3) "c"redis> ZRANGEBYLEX myzset - (c1) "a"2) "b"redis> ZRANGEBYLEX myzset [aaa (g1) "b"2) "c"3) "d"4) "e"5) "f"
12. 通过分数返回有序集合指定区间内的成员
命令
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
# 递增排列redis> ZRANGEBYSCORE idb:zset -inf 7 WITHSCORES1) "zhangsan"2) "5"3) "wangwu"4) "6"# 递减排列redis> ZREVRANGEBYSCORE idb:zset inf 7 WITHSCORES1) "zhaoliu"2) "8"
13. 移除有序集合中给定的字典区间、排名区间、分数区间的所有成员
命令
ZREMRANGEBYLEX key min max
ZREMRANGEBYRANK key start stop
ZREMRANGEBYSCORE key min max
redis> ZADD myzset 0 aaaa 0 b 0 c 0 d 0 e(integer) 5redis> ZADD myzset 0 foo 0 zap 0 zip 0 ALPHA 0 alpha(integer) 5redis> ZRANGE myzset 0 -11) "ALPHA"2) "aaaa"3) "alpha"4) "b"5) "c"6) "d"7) "e"8) "foo"9) "zap"10) "zip"// 移除有序集合中给定的字典区间的所有成员redis> ZREMRANGEBYLEX myzset [alpha [omega(integer) 6redis> ZRANGE myzset 0 -11) "ALPHA"2) "aaaa"3) "zap"4) "zip"// 移除有序集合中给定的排名区间的所有成员redis> ZADD idb:zset 2000 Lilei 3500 Tom 5000 Lucy(integer) 3redis> ZREMRANGEBYRANK idb:zset 0 1(integer) 2redis> ZRANGE idb:zset 0 -1 WITHSCORES1) "Tom"2) "5000"// 移除有序集合中给定的分值区间的所有成员redis> ZADD idb:zset 2000 Lilei 3500 Tom 5000 Lucy(integer) 3redis> ZREMRANGEBYSCORE idb:zset 1500 35001) "Tom"2) "5000"
14. 迭代有序集合中的元素(包括元素成员和元素分值)
命令
ZSCAN key cursor [MATCH pattern] [COUNT count]
redis> ZADD idb:zset 2000 Lilei 3500 Tom 5000 Lucy(integer) 3redis> ZSCAN idb:zset 0 match "L*"1) "0"2) 1) "Lilei"2) "2000"3) "Lucy"4) "5000"
03
总结
END
往期回顾 | |
