




Redis 集合(Set)类型和数学中的集合类似,数学集合的概念是指具有某种特定性质的具体的或抽象的对象汇总而成的集体。简而言之,Redis集合就是一些不重复值的组合。利用集合(Set)这个数据结构,Redis 可以存储一些集合类型的数据,Redis也通过一些简便的命令很好的支持了交集、并集和差集等集合的基本运算。
常见的应用场景有:投票系统、标签系统、共同好友、共同关注、共同爱好、抽奖、商品筛选栏,访问IP统计等。
本文主要分为以下三部分:
1. 集合(Set)数据结构
2. 常用命令
3. 总结
01
Set 数据结构
Redis 中的集合(Set)内部编码是 intset 和 hashtable 两种实现方式,其中 intset 编码会使用更少的内存,查询效率较快,但是仅能存储整型数据,而 hashtable 则可以存储更多类型的数据,应用场景更加通用。
当集合对象满足以下两个条件时, 对象使用 intset 编码:
集合所有成员类型都是整型;
集合大小 (成员数量)不能超过 set-max-intset-entries, 默认 512。
以下是 intset 结构展示的一个集合对象:
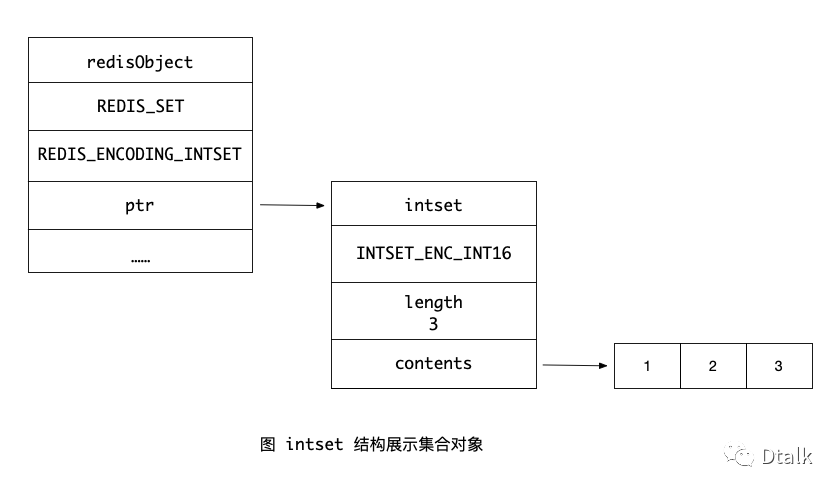
intset 节点结构定义:
typedef struct intset {uint32_t encoding;uint32_t length;int8_t contents[];} intset;
结构定义说明:
encoding 编码方式
length 集合中包含的元素数量
contents 保存元素的数组
当 intset 编码条件不能满足时,集合对象的编码会执行转换操作,原本的 intset 的所有元素会被保存到 hashtable 编码中。
以下是 hashtable 结构展示的一个集合对象:
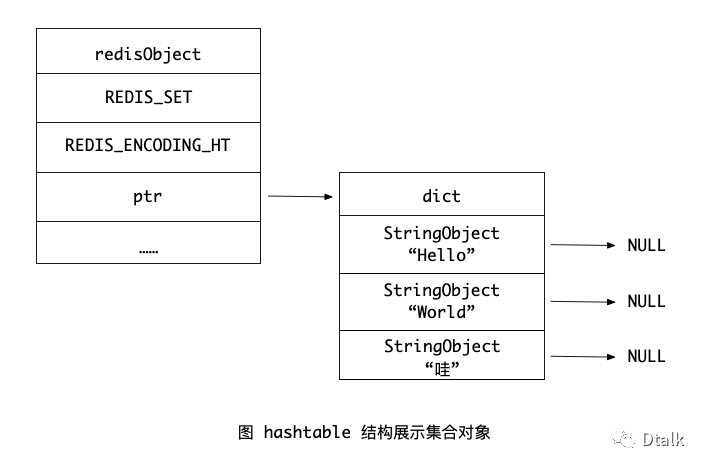
具体 hashtable 数据结构可以参考文章:
Redis 集合(Set)编码设计:对于少量整型数据可以使用 intset,对于其他类型的数据可以使用 hashtable,可以有效的减少内存开销,并且加快查询效率。同时丰富的操作命令降低了用户构建业务系统的学习开发成本,通过这样的灵活的数据结构,构建更加多样的业务场景。

02
常用命令
1. 向集合添加一个或多个成员
命令
SADD key member [member ...]
redis> SADD idbset i d b(integer) 3
2. 获取集合的成员数
命令
SCARD key
redis> SCARD idbset(integer) 3
3. 返回集合中的所有成员
命令
SMEMBERS key
redis> SMEMBERS idbset1) "b"2) "i"3) "d"
4. 判断 member 元素是否是集合 key 的成员
命令
SISMEMBER key member
redis> SISMEMBER idbset "i"(integer) 1 # 存在成员 iredis> SISMEMBER idbset "x"(integer) 0 # 不存在成员 x
5. 移除并返回集合中的一个或多个随机元素
命令
SPOP key [count]
redis> SADD idbset i d b 1 2 3 4(integer) 7redis> spop idbset 31) "3"2) "b"3) "4"
6. 移除集合中一个或多个成员
命令
SREM key member [member ...]
redis> SADD idbset i d b 1 2 3 4(integer) 7redis> SREM idbset 1 2 3 4(integer) 4redis> SMEMBERS idbset1) "b"2) "d"3) "i"
7. 将 member 元素从 source 集合移动到 destination 集合
命令
SMOVE source destination member
redis> sadd oldset 1 2 3(integer) 3redis> SMOVE oldset newset 1(integer) 1redis> SMOVE oldset newset 2(integer) 1redis> SMEMBERS newset1) "1"2) "2"redis> SMEMBERS oldset1) "3"
8. 返回集合中一个或多个随机成员(不移除成员)
命令
SRANDMEMBER key [count]
redis> SMEMBERS idbset1) "b"2) "d"3) "i"redis> SRANDMEMBER idbset"b"redis> SRANDMEMBER idbset"i"redis> SRANDMEMBER idbset"d"redis> SRANDMEMBER idbset"d"
9. 返回或保存第一个集合与其他集合之间的差异
命令
SDIFF key [key ...]
SDIFFSTORE destination key [key ...]
redis> SADD aset 1 2 3 4(integer) 4redis> SADD bset 3 4 5 6(integer) 4# aset 和 bset 的差异redis> SDIFF aset bset1) "1"2) "2"# bset 和 aset 的差异redis> SDIFF bset aset1) "5"2) "6"# 返回 aset 和 bset 的差异并存储在 cset 中redis> SDIFFSTORE cset aset bset(integer) 2redis> SMEMBERS cset1) "1"2) "2"
10. 返回或保存给定所有集合的交集
命令
SINTER key [key ...]
SINTERSTORE destination key [key ...]
redis> SADD aset 1 2 3 4(integer) 4redis> SADD bset 3 4 5 6(integer) 4# 返回 aset 与 bset 的交集redis> SINTER aset bset1) "3"2) "4"# 返回 aset 与 bset 的交集并保存到 dsetredis> SINTERSTORE dset aset bset(integer) 2redis> SMEMBERS dset1) "3"2) "4"
11. 返回或保存所有给定集合的并集
命令
SUNION key [key ...]
SUNIONSTORE destination key [key ...]
redis> SUNION aset bset1) "1"2) "2"3) "3"4) "4"5) "5"6) "6"redis> SUNIONSTORE cset aset bset(integer) 6redis> SMEMBERS cset1) "1"2) "2"3) "3"4) "4"5) "5"6) "6"
12. 迭代集合中的元素
命令
SSCAN key cursor [MATCH pattern] [COUNT count]
redis> SADD idbset a b c d e f g h(integer) 8redis> SSCAN idbset 0 match h* count 11) "4"2) (empty list or set)redis> SSCAN idbset 4 match h* count 11) "1"2) (empty list or set)redis> SSCAN idbset 1 match h* count 11) "5"2) 1) "h"redis> SSCAN idbset 5 match h* count 11) "3"2) (empty list or set)redis> SSCAN idbset 3 match h* count 11) "7"2) (empty list or set)redis> SSCAN idbset 7 match h* count 11) "0"2) (empty list or set)
03
总结
往期 · 推荐
