




Redis 中的(Hash)类型是一个较为常用的数据类型,一般用于存储用户信息、购物车、商品描述等对象类型的数据结构,Hash 使用方式也较为简单。
本文主要分为以下三部分:
1. 哈希(Hash)数据结构
2. 常用命令
3. 总结
01
Hash 数据结构
Redis 中的(Hash)类型是一个 String 类型与 field 和 field-value 的映射表,本质上是将字符串名称映射到字符串值,适用于存储对象类型,将一个对象类型存储在Hash类型中要比存在 String 类型中占用要更小,更加节省内存空间。
以下是 String 类型和 Hash 类型的结构比较:
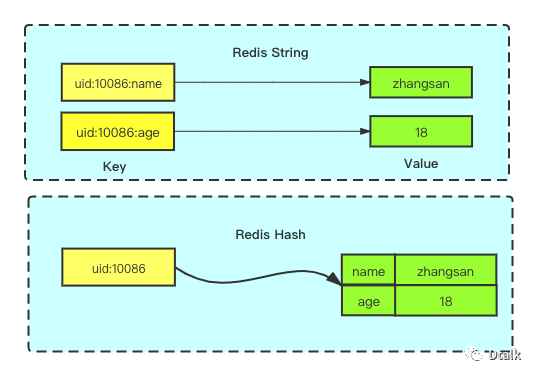
重点看下 Hash 类型的几个重要数据结构。
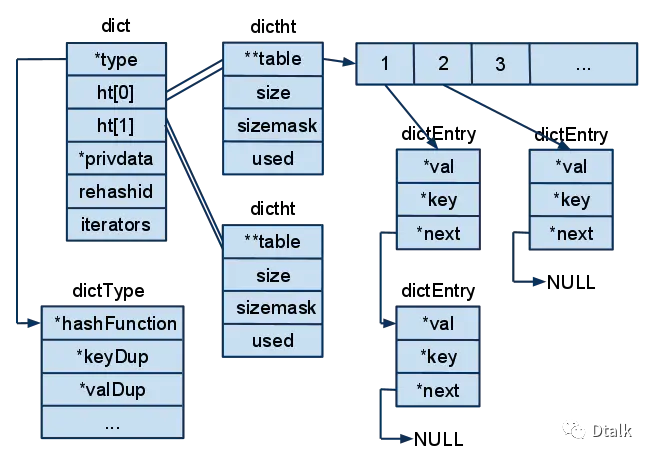
哈希表节点结构定义:
typedef struct dictEntry {// key:键void *key;// v:值union {void *val;uint64_t u64;int64_t s64;} v;// 指向下个哈希表节点,形成链表struct dictEntry *next;} dictEntry;
哈希表节点使用 dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对:
key 属性保存着键值对中的键, 而 v 属性则保存着键值对中的值;
next 属性是指向另一个哈希表节点的指针。
『 参考 Redis设计与实现 』
哈希表结构定义:
typedef struct dictht {// 哈希表数组dictEntry **table;// 哈希表大小unsigned long size;// 哈希表大小掩码,用于计算索引值// 总是等于 size - 1unsigned long sizemask;// 该哈希表已有节点的数量unsigned long used;} dictht;
哈希表由 dictht 结构定义:
table 属性是一个数组, 数组中的每个元素都是一个指向 dictEntry 结构的指针。
size 属性记录了哈希表的大小
used 属性则记录了哈希表目前已有节点(键值对)的数量。
sizemask 属性的值总是等于 size - 1 , 这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面。
『 参考 Redis设计与实现 』
字典结构定义:
typedef struct dict {// 类型特定函数dictType *type;// 私有数据void *privdata;// 哈希表dictht ht[2];// rehash 索引// 当 rehash 不在进行时,值为 -1int rehashidx; /* rehashing not in progress if rehashidx == -1 */} dict;
字典由 dict 结构定义:
type 属性是一个指向 dictType 结构的指针, 每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。
而 privdata 属性则保存了需要传给那些类型特定函数的可选参数。
type 属性和 privdata 属性是针对不同类型的键值对,为创建多态字典而设置的.
『 参考 Redis设计与实现 』
typedef struct dictType {// 计算哈希值的函数unsigned int (*hashFunction)(const void *key);// 复制键的函数void *(*keyDup)(void *privdata, const void *key);// 复制值的函数void *(*valDup)(void *privdata, const void *obj);// 对比键的函数int (*keyCompare)(void *privdata, const void *key1, const void *key2);// 销毁键的函数void (*keyDestructor)(void *privdata, void *key);// 销毁值的函数void (*valDestructor)(void *privdata, void *obj);} dictType;
ht 属性是一个包含两个项的数组, 数组中的每个项都是一个 dictht 哈希表,
一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
除了 ht[1] 之外, 另一个和 rehash 有关的属性就是 rehashidx :它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 -1 。
『 参考 Redis设计与实现 』
普通状态下字典的展示
rehash 机制:
随着业务的增长,或者QPS的增加,哈希表保存的键值对会不断变化,如果节点数量比哈希表的大小要大很多的话,那么哈希表就会退化成多个链表,哈希表本身的性能优势便不复存在。出于对于链表的性能考虑, 会进行 rehash 操作。整个 rehash 过程较为复杂,这里就不展开讲解,在后续的文章中会一一展开,敬请期待。
内部编码:
Hash 类型内部编码有 ziplist 和 hashtable 两种:
ziplist
hashtable

02
常用命令
1. 创建一个 Hash Key
命令
HSET key field value
redis> HSET uid:1 name "zhangsan"(integer) 1redis> HSET uid:1 age 18(integer) 1
2. 获取 Hash Key 对应的 field 的 value
命令
HGET key field
redis> HGET uid:1 name"zhangsan"redis> HGET uid:1 age"18"
3. 删除 Hash Key 的 field [field...]
命令
HDEL key field [field ...]
redis> > HDEL uid:1 name(integer) 1 # 删除成功
4. 判断 Hash Key 是否有指定 field
命令
HEXISTS key field
redis> HEXISTS uid:1 name(integer) 0 # 不存在redis> HEXISTS uid:1 age(integer) 1 # 存在
5. 获取 Hash Key field 的数量
命令
HLEN key
redis> HLEN uid:1(integer) 2
6. 获取 Hash Key 对应所有的 field 和 value
命令
HGETALL key
redis> HGETALL uid:11) "age"2) "18"3) "name"4) "zhangsan"
7. 设置 Hash Key 对应 field 的 value(如果field已经存在,则失败)
命令
HSETNX key field value
redis> HSETNX uid:2 name "wangwu"(integer) 1 # 设置成功redis> HSETNX uid:2 name "zhaoliu"(integer) 0 # 设置失败
8. Hash Key 的 INCR 操作
命令
HINCRBY | HINCRBYFLOAT key field increment
redis> HINCRBY uid:1 age 1(integer) 19redis> HINCRBYFLOAT uid:1 account 200.4"1200.5"
9. 批量获取 Hash Key 的 field 的 value
命令
HMGET key field [field ...]
redis> HMGET uid:1 name age account1) "zhangsan"2) "19"3) "1200.5"
10. 批量设置 Hash Key 的 field 的 value
命令
HMSET key field value [field value ...]
redis> HMSET uid:2 name "wangwu" age 20 account 1000.1OK
03
总结

往期 · 推荐
