




1 什么是嵌套循环NESTED LOOPS
嵌套循环是最常见的表的连接方式,下面我们首先通过一个最简单的例子来理解嵌套循环,其中NESTED LOOPS就是嵌套循环的意思。
在RBO下,默认左表为驱动表,在执行计划看,第一张表是驱动表。

这个执行计划的含义是以table1为驱动表(外表),先扫描该表,对该的每一条数据全表扫描table2(内表),最后返回匹配的数据。
2 如何选择驱动表
驱动表在执行计划中显示为上面的表,如上图中的table1。两个表做嵌套循环,驱动表的选择很重要。我们可以简单计算下哪个表做驱动表好。
假设table2是个大表,有4000万数据,占有100万个块;而table1是个小表,有4000条数据,占有100个块。
(1)以大表table2为驱动表去要访问的数据块:对table2 全表扫描需要访问100万个块,而table2中的每一条数据都需要全表扫描table1一次,需要访问40亿个块(4000万*100),总共访问(40亿+100万)个块。
(2)以小表table1为驱动表去要访问的数据块:对table1全表扫描需要访问100个块,而table1中的每一条数据都需要全表扫描table2一次,需要访问40亿个块(4000*100万),总共访问(40亿+100)个块。
从上面的计算看,当两个表都是全表扫描时,选择小表做驱动表相对好些。不过,两者的查询代价都太大,都是不能接受的,因为内表的数据被访问了N遍(N为驱动表的数据量),这是严重的浪费。
3 内表的关联列上有索引
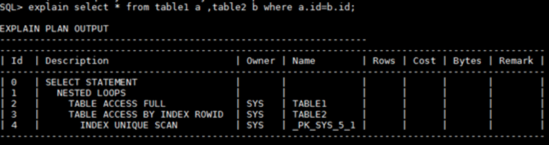
在这个例子中,使用表table1为驱动表,但是对内表的访问不再全表扫描了,而是使用内表的关联列的索引。
此时它的执行步骤是:
(1)全表扫描表table1。
(2)对第一步的每一条数据访问table2的索引_PK_SYS_5_1,使用第一步查询出来的id,到索引页中_PK_SYS_5_1做索引范围扫描。
(3)获取第二步从索引叶子中查询到目标数据的ROWID,分别到table2表中根据ROWID直接获取目标数据页信息。
(4)返回目标数据的信息。
了解了执行过程,下来再来计算下查询的代价。
假设索引的高度是4,最终有4000条数据命中。内表有索引时访问的块数:对table1全表扫描需要访问100个块,而table1中的每一条数据都需要扫描索引_PK_SYS_5_1一次,需要访问4000*4=1.6万个块,使用ROWID到表需要访问4000个块,总共需要访问100+1.6万+4000=20100个块,比前面的计算结果提升了上万倍的性能。
4 带有其他条件的嵌套循环
(1)驱动表其他列有索引

此时驱动表会先根据table1的索引IDX_TABLE1_NAME查出满足条件的数据,再去table2的索引_PK_SYS_5_1循环,此时命中的数据少,所以效率也比较高
(2)内表非关联列上的索引
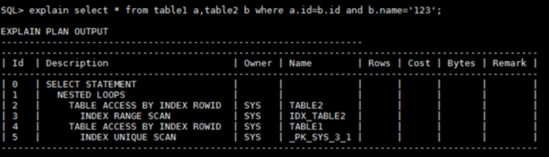
前面我们说过要用小表做驱动表,RBO下默认左表为驱动表,但并不绝对,比如当加上条件b.name=’123’时,此时发现驱动表变成大表table2。这是因为加上条件后,table2的数据较少,所以table2为驱动表。
5 嵌套循环的使用场景总结
嵌套循环是最重要的连接方式,尤其是在实时性比较高的系统中,因为这种系统的查询要求快速返回,不能访问很多的数据块,而这正是嵌套循环适用的场景。
嵌套循环的使用场景:
(1)驱动表的结果集小(应用过自己的查询条件后),选择驱动表非常重要。
(2)内表的连接列上有索引。
(3)驱动表和内表连接匹配的数据量小,即扫描内表连接列的索引的次数少。
